Indic Wikisource- The Iceberg.
Wikisource, one of the sister project of Wikimedia Foundation, but not known to all, whoever know the wikipedia. It is under-rated rather than wikipedia. After creation of English Wikisource in 2003, Malayalam & Telugu wikisource were created in 2006. Next year in 2007, Bengali & Tamil was created. Step by step other indic language wikisource created Kannada in 2009, Assamese & Sanskrit in 2011,Gujarati & Marathi in 2012, Odia in 2013 and Punjabi in 2017. It is expected that in 2019, Hindi Wikisource will be created. The 11 Indic Language wikisource is growing now rapidly.
Even though 5+ Indic Languages wikisource created before 2009. The development and content generation was not remarkable because, there was no Optical character recognition (OCR) tool in Indic languages script. The main drawback was Indic script OCR development was very slow. The first initiated was found by Bidyut Baran Chaudhuri at Indian Statistical Institute (ISI) in 1994 to develop OCR for Indic script. Centre for Development of Advanced Computing (C-DAC) under of the Ministry of Electronics and Information Technology (MeitY) followed the OCR in 1997 and released OCR e-Aksharayan in 2018.Open Source OCR have been developing as Tesseract (multilingual) from 2006 which have all Indic Script. But no OCR tool had not give us the desirable result of output as editable text for Idic script
In 2015 Google release their OCR utility Google Drive as free. Indic community tested the output result, and they realise this was satisfied. The Community Tech team was implemented Google's Cloud Vision API OCR service to all wikisource as GoogleOCR tool. But all the Google's Cloud Vision API OCR service was not working for all Indic script such as Kannada, Malayalam,Odia,Telugu and Gujarati. Later IndicTechCom was developed one another Tool IndicOCR which is running under Google Drive API and it is working for all Indic Language Script.
Before Google OCR, the Indic Wikisource Community use the workflow to copy paste the content from other website or typed the whole book. During this time many non-proofreaded content was imported. Now we are have no technical difficulties to generate the text and proofread.
After impleaded Google OCR tool , the Indic community follow the true workflow of wikisource except importing content from other source.
Telugu, Tamil, Bengali, Gujarati and Malayalam Wikisource are top five wikisource among the 11 Indic wikisource as proofread page. We have not included the English Wikisource as Indic Language, but User:Rajasekhar1961 and User:Hrishikes have done remarkable work about Indian related books/subject in English language Wikisource. User:Hrishikes published one blog about his experience at Why I contribute to Wikisource. For the developments of Telugu Wikiosurce they published one blog at A ‘couple’ of Telugu-language Wikimedians: T Sujatha and Sri Ramamurthy.
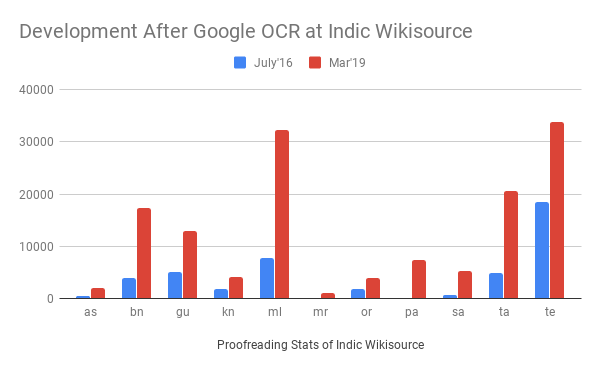
The above graphics shown the development of proofread pages after implementing the GoogleOCR/IndicOCR. Some of the wikisource leader from different Indic wikisource community express their experience at Indic Wikisource community consultation held in Kolkata on 2018 conducted by CIS team. Indic Wikisource Community Consultation 2018 was reported at Asomiya Pratidin ePaper- Highest Circulated Assamese Daily.
Some of the wikisource leader from different Indic Wikisource community contributing at their languages , Gitartha.bordoloi from Assamese community, Sushant savla from Gujarati community, Pankaj Mala Sarangi from Odia community.Bodhisattwa from Bengali community and Balajijagadesh from Tamil Community.

