Infrastructural Needs of Indian Language Wikisource Projects
Read this report on Wikimedia Meta-Wiki here.
Introduction
This research project is an effort to understand some of the infrastructural needs of Wikisource platforms in India. With a focus on technological capacity, resources and training, this short pilot study collected baseline data from Indian language Wikisource communities to identify key knowledge gaps and areas of improvement. The final report here offers an overview of the current challenges in this space, and some learnings and recommendations on potential strategies to address these gaps, including through collaborative intervention and training.
Context
Wikisource projects have been an important part of the open knowledge movement in India, as it is a hub of out of copyright and freely licensed texts in a number of languages from across the world. With a focus on creating a ‘growing free content online library of source texts, as well as translations of source texts in any language', it functions as an important open knowledge repository that supports content development on various sister projects such as Wikipedia, Wikiquote etc. Wikisource projects in Indian languages have seen tremendous growth, especially over the last decade with increased efforts in content donation under free licences, digitization initiatives and availability of source texts. There have also been several advancements in Indic language computing and availability of digital infrastructure, such as more Indian language fonts, many with Unicode support, and increased flexibility in working with texts due to Optical Character Recognition (OCR) technologies. There has also been a general growth in awareness about the need for sourcing and making available more content in Indian languages, and better access to platforms like Wikisource has aided these efforts to a great extent.
However, several Indian language communities also continue to grapple with persistent challenges in this space, across diverse Wikimedia projects. Similarly, with Wikisource, there have been concerns about a lack of active participation and efforts towards bringing more content on the platform, including translations, and encouraging the use of source texts across projects among others. While a majority of the contributors are comfortable with transcribing texts, more technical tasks such as importing new books, creating Index pages and transcluding books are left to a very small number of contributors. These point to a lack of not just awareness and resources, but also a need for capacity-building efforts to address the skill gaps, improvements in digital infrastructures to resolve basic issues with platforms, and diversification of the scope of work undertaken. For instance, the most recent Community Wishlist Survey 2022 highlights some basic fixes that need attention− such as bugs with the search and replace function to improve search and mass uploads −to more advanced work such as expanding existing functionality in indexing, integrating structured data and translation tools and functionalities across Indian languages, to name a few.
A research needs assessment survey conducted by CIS-A2K last year also highlighted the need for better technological support for Wikimedia projects, and capacity-building in important areas of work in the Indian language communities. While this is not specific to Wikisource alone, observations by community members and active Wikisource contributors over the last few years illustrate that many of these concerns and knowledge gaps are prevalent in this community as well. This study was therefore an attempt to identify these challenges, by collecting baseline data on key areas of work in Indian language Wikisource projects, beginning with a focus on selected language communities, and areas of interest. The attempt was also to enable contributors to achieve a more detailed understanding of the requirements of communities, in the contexts of certain languages, and aid in developing potential strategies to address them.
Research objectives
The study had two areas of focus:
- What are the key challenges with working on Indian language Wikisource projects currently? These may include anything from obstacles in Wikisource workflow, policies and open licences, to challenges such as quality of content and lack of community engagement?
- What are gap areas and spaces for improvement in the infrastructure of these platforms, especially related to technological capacity, resources and training?
Research methods
The study adopted a mixed methods approach, comprising a survey and interviews with community members. The survey focussed on key areas of ongoing work, and potential challenges for Wikisource projects in India - including technological support, skill-building, policies on content donation and curation, and open access and licensing. The survey was opened to all Wikisource communities and publicised on relevant mailing lists and community platforms. Simultaneously, a detailed interview questionnaire was also prepared, along with the selection criteria for interviews with community members. The project team worked with one short-term research assistant over a 2–3-month period for the data collection through interviews and surveys. The research assistant also provided translation support as needed and worked closely in coordinating with community members.
The criteria considered for selection of the language communities for the study were language family and size, amount of content on Wikisource (according to bytes/number of proofread pages), recent activity and a good track record/sustained progress and challenges with the same over the last several years. External factors, such as visibility and prevalence of the languages on other online platforms, technical and cultural resources and complexities of working with certain languages etc. were also considered during the selection process. Keeping these in mind, the languages selected for this study were as follows:
- Tamil Wikisource (One of the largest Wikisource communities in India, which has considerable content, is active and has seen steady growth over the last few years)
- Assamese Wikisource (A growing Wikisource community, which has also seen a lot of activity in recent years)
- Malayalam Wikisource (A large and active Wikisource community, which in recent years has some decline in engagement, despite good resources and activity on other Wiki platforms)
Using a purposive sampling technique, the team identified community members for interviews across these three languages and reached out over the course of six months in order to conduct semi-structured interviews. The criteria for selection of interviewees included a mix of senior/experienced and new contributors, those working across several projects and languages, those with expertise in specific/advanced technical areas of Wikisource, licensing and content donation efforts, and keeping in mind gender parity within the sample. There were however several challenges with this exercise, including basic barriers such as bad internet and phone connectivity, digital fatigue and unavailability of people due to the second wave of the pandemic, and limited time on Wikimedia projects. As a result, this method was unsuccessful, as it managed to gather very limited data for the study. The timeline of the survey was also extended as a result, and it received a total of 21 responses. The survey data offers several insights into some of these key areas of work and challenges, and the following is a report based on an analysis of this limited data set and observations on the same. Given the limited sample size and final dataset, it would be important to note that we may need several steps before the observations/findings may be considered to be representative at any scale.
Observations and Learnings
|
As mentioned earlier, the dataset comprised of 21 respondents on the survey, many of them contributors across diverse Wikimedia projects including English and Indian language Wikipedia projects, Wikisource, Wikibooks, Wikidata, Wikiquote, Wiktionary, Wikivoyage, Wikimedia Commons, software such as Media Wiki, and initiatives like Wikimedia in Education. The respondents ranged across nine languages (in alphabetical order) – Assamese, Bengali, English, Hindi, Kannada, Marathi, Malayalam, Punjabi, Telugu and Tamil. Several of them are also part of user groups working in some of these languages. The experience of the contributors’ ranges from 6 months to 12 years. Almost all the respondents note that contributions towards proofreading, and bringing more content on the Wikisource projects (including work on related processes by the Volunteer Response Team, previously known as Open Source Ticket Request System, and OCR) have been key milestones in their work, either as individuals or communities. Some respondents have also pointed out some new work such as audio books, and working on technological aspects, especially with gadgets and best practices shared by other global communities. The data offers some key insights into the kinds of challenges currently faced by Indian language Wikisource contributors, and what could be potential areas of improvement. As noted in Fig.1, an overwhelming percentage of the respondents noted that ‘capacity-building and training’ (81%) is an area that needs the most improvement, followed closely by ‘community engagement’ (66%) and ‘technological infrastructure’ (57%). These are key areas that show repetitive patterns across the data set, in terms of recurring challenges as well. As noted by respondents, training in Wikisource workflows, procedure and guidance, learning to use advanced templates/techniques, recruiting new volunteers etc. have been key challenges. Community engagement has seen a dip, especially over last year with the pandemic and related decline in activity on projects, as well as events and therefore opportunities to meet. There is a need for more contributors and strategies to encourage work and retain them on the projects. Scanning and post-production processing of scans emerged as a significant challenge, given lack of resources and infrastructure, and related issues such as poor quality of scanned work and no uniformity in the book selection criteria. There are also some areas of technical support such as broken tools on Wikisource projects, missing symbols in some language tool bars, and an abundance of formatting tags which could present barriers for new contributors. The following are some of the responses and observations in specific areas mentioned above: |
 |
|---|
Capacity-building and training
As most contributors would be well aware, capacity-building and technological infrastructure are two closely connected aspects of Wikimedia projects. The responses under this thematic reflect the same, in terms of a need for better training in optimising the use of available and advanced technical skills for Wikisource projects. This includes training on specific skills and processes such as scanning, text conversion, formatting, sourcing, transclusion, creating gadgets, writing bots. There is a need for better writing and spelling skills to improve the quality of content generated. The survey also suggested potential ways to address these skill gaps, all of which were seen as relevant by a majority of respondents (66.7%). [See Fig 2]
Community Engagement
Community engagement ranked second in terms of the challenges noted by respondents on the survey. The survey also looked at engagement in comparison with Wikipedia projects, as it has been observed that the latter see more active participation. This was confirmed by some of the responses as well. Some of the main reasons for lack of participation as noted by respondents is that Wikisource is a specialised project, that needs a specific skill-set and demands time and effort, hence may not appeal to all contributors. Also, it has lesser content and visibility compared to some of the Wikipedias or other projects which may be more easily updated. Thus, there is a need for actively recruiting new volunteers, and capacity-building to enable more contributions, as well as targeted outreach efforts in spaces related to literature and books to enhance discoverability. Some respondents also mentioned that a lack of awareness, coordination and interaction among contributors could be potential reasons. Finally, there are also external factors such as balancing volunteer work with other commitments such as family and financial problems, many contributors being students who move on to full-time careers, effects of the pandemic and paucity of time and interaction, and loss of interest over time in the projects.
Again, efforts to address community engagement need some strategic measures, including but not limited to community interaction, incentives and better visibility for work in, as noted in Fig.3.
Technological infrastructure
Technological infrastructure, which is one of the key areas of focus for this study, has also been a persistent challenge for Indian language communities, also given the resource-heavy work any form of computing with Indic languages entails. While some respondents did not notice any specific issues in their communities, there were some patterns or gaps that were reflected across communities. There is a need for basic hardware like scanners and good computers, or rather centralised facilities for scanning and good internet connectivity in order to cover more collections and regional areas. In addition to this, there is also a need for technical improvements such as easy-to-use widgets, gadgets and better tags to enhance formatting work as part of the transcription of texts, incorporating certain signs and symbols within toolbars, spell-checker, full list of syntaxes while proofreading, and stages for fixing mistakes and adding formatting tags. An important observation was that some language communities access and edit Wikisource on mobile phones, so there is a need for a mobile application that can provide a seamless editing experience, and connect more people with the projects. As mentioned earlier, there are also several technical fixes such as a number of pending bugs in projects. A related requirement therefore is for MediaWiki developers with good language skills to work on translation of interfaces. A few respondents also mentioned additional challenges such as improvement of new books, Graphical User Interface (GUI) and page layout, and the functionality to view Wikisource in other formats as well.
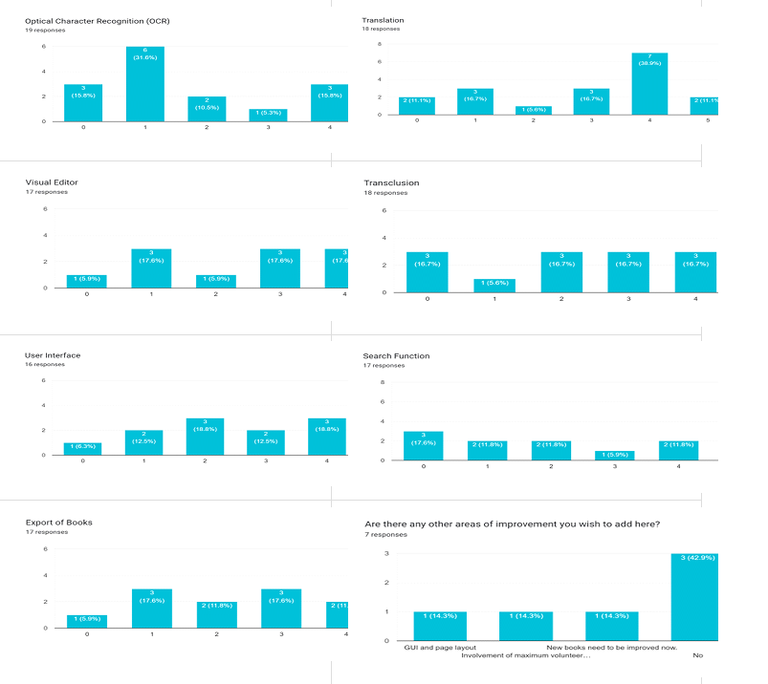
Some specific areas of improvement were also assessed on the survey, drawing upon a review of the community wishlists for the last few years. These included Optical Character Recognition (OCR), translation, visual editor, transclusion, user interface, search function and export of books. While all these functionalities did not receive responses from the entire set, many found these to be key challenges. OCR received the most responses (19), with 31.6% assessing this at 1 (needs minimal updates, functional with space for innovation). Translation received 18 responses, with 38.9% marking this at 4 (major challenges, requires focused work). Similarly, transclusion also received 18 responses with about 27.8% voting at 5 (significant challenges, requires long-term effort and resources). Visual editor, search function and export of books all received 17 responses each, with a majority in all three assessing these as 5. Of these search function had more people assessing the functionality at 5 (41.2%), followed closely by visual editor and export of books (35.3% each). User interface received 16 responses, with 31.3 % of respondents assessing it at 5 as well.
Open Access and Content Creation
In addition to the above, content curation and related aspects of open access and relicensing are also spaces with prevalent knowledge gaps in terms of protocols and best practices, which poses a challenge for content generation on Wikisource projects. Lack of awareness about Intellectual Property Rights (IPR) and relicensing in fact has been a significant impediment in content donation efforts, across projects. In this survey, a large number of respondents (42.6%) also said they were either unaware of these issues with Wikisource or about IPR itself, or mentioned that it was not applicable in this context. Among the challenges/issues mentioned, the need for simple, easily accessible advocacy material in print about open access was prominent, in order to encourage content creators/authors to share work on open licences. It was also noted that this process may be difficult for people who are not well-versed in the technical/legal aspects of the project, especially in terms of tracking down individual creators for consent to re-license and share their work. Respondents also noted that this work needs support from institutions to help set up collaborations, such as with educational organisations, publishing houses and authors, as also an understanding of official documentation and wider promotion etc. which may encourage more people to share content on open licences.
All of these aspects are further reflected in terms of strategies to address these issues as well, as observed in Fig. 4.
A similar disparity exists with content curation best practices as well, with a majority of respondents noting that their respective communities do not have clearly defined protocols for content curation. While such benchmarking is naturally difficult given several socio-cultural and linguistic subjectivities of each project, this also means that what makes it to Wikisource in a particular language can be defined by many factors, which also informs the quality, types and formats of content produced. Potential methods to address this include developing guidelines for content creation, and forms of review by experts as well as community members, all of which ranked high in the survey responses. ( See Fig 5)
As we did not receive enough responses on the interview questionnaires, there was not much additional qualitative data that could be gathered. There are however resonances with the survey responses, namely in terms of technical/hardware challenges such as poor quality of scanning, and the need for an app which is user-friendly and will further facilitate mobile editing, especially in areas with limited digital infrastructure and access. Some observations include the importance of the OTRS process in adding new content, and the need for better online and offline training, especially for new volunteers, in technical skills. Similarly, collaborations with educational institutions and local print media could be useful in creating more awareness, and therefore tapping into more content and resources in terms of new volunteers. Additionally, there are also some interesting observations on individual communities working on connecting work across projects, for example Wikisource and Wikiquote.
Conclusions and Recommendations
While the scope of the study had to be reduced significantly given several methodological challenges and external factors as mentioned earlier, the analysis of data does offer some significant learnings on the current challenges prevalent across Indian language Wikisource projects. Needless to say, many of these are also fairly contextual and nuanced, depending on how well-resourced certain languages are, given factors such as basic internet connectivity and digital literacy. The following is a short summary of key recommendations from this exercise.
Technological Infrastructure: Across the board, gaps in development of technological infrastructure have been prominent, ranging from basic fixes to advanced tools and user-friendly apps that may help mitigate some of the issues related to access. It is also notable that early challenges such as OCR and translation do not present as significant obstacles here (but continue to remain areas of ongoing work); features such as the visual editor, search and export functionalities emerged as continual challenges. The need for a user-friendly mobile app is also an important observation here. Some of this work is also quite resource-intensive in terms of funding; it would be prudent to look at collaborations with related organisations and local fundraising efforts that may help facilitate the same.
Capacity-Building: Similarly, capacity-building efforts need to be strengthened within communities, given the nature of work which is specialised and often quite technical( for example the process of transclusion). In addition to bringing in new volunteers, and equipping them with the requisite skill-sets to contribute effectively, there is a need for contributors with advanced skill-sets who may be able to address more technical challenges. Efforts here could include reaching out to the wider free and open source communities for external expertise, and working on a collaborative model of workshopping around strategic issues, and developing relevant skill-sets. Community-engagement: As noted by many respondents, bringing in new volunteers and their retention on projects has been a continual challenge, also due to the factors mentioned above. Improvements in technical infrastructure and capacity-building would help address some of these challenges as well. In addition to this, as noted by respondents, developing proactive collaborations with diverse institutions and individuals (educational/media/creative practice) would help widen networks, hence creating better awareness and visibility for work, such as through social media content and may also foster better engagement.
Content Curation and Open Access: As is widely understood, discourse around open access and relicensing is layered, and the protocols often vary widely depending on linguistic factors and cultural context. Instead of developing benchmarks, it may be prudent therefore to develop accessible content on existing, global relicensing protocols, in translation across languages. These may be further used by communities to understand and engage better with efforts in content donation. Guidelines for content curation will again need to be similarly developed and modified, keeping in mind how policies also evolve and change. An important consideration here in addition to quality, is also that of ethics of access and use, especially by communities themselves.
This short study was an effort to map some of the prevalent infrastructural challenges that underlie work on Indian language Wikisource projects. The observations from this report may offer useful insights in thinking through and developing strategies to address these gaps, through collaborative efforts in training and building resources for projects.


