Blog
Mapping cybersecurity in India: An infographic

Infographic designed by Saumyaa Naidu
Private-public partnership for cyber security
For security The private sector has a long history of fostering global pacts iStockphoto - Getty Images/iStockphoto
The article by Arindrajit Basu was published in Hindu Businessline on December 24, 2018.
On November 11, 2018, as 70 world leaders gathered in Paris to commemorate the countless lives lost in World War I, French President Emmanuel Macron inaugurated the Paris Peace Forum with a fiery speech denouncing nationalism and urging global leaders to pursue peace and stability through multilateral initiatives.
In many ways, it echoed US President Woodrow Wilson’s monumental speech delivered at the US Senate a century ago in which he outlined 14 points on the principles for peace post World War I. As history unkindly reminds us through the catastrophic realities of World War II, Wilson’s principles went on to be sacrificed at the altar of national self-interest and inadequate multilateral enforcement.
President Macron’s first initiative for global peace — the Paris Call for Trust and Security in Cyber Space was unveiled on November 12 — at the UNESCO Internet Governance Forum — also taking place in Paris. The call was endorsed by over 50 states, 200 private sector entities, including Indian business guilds such as FICCI and the Mobile Association of India and over 100 organisations from civil society and academia from all over the globe. The text essentially comprises a set of high-level principles that seeks to prevent the weaponisation of cyberspace and promote existing institutional mechanisms to “limit hacking and destabilising activities” in cyberspace.
Need for private participation
Given the increasing exploitation of the internet for reaping offensive dividends by state and non-state actors alike and the prevailing roadblocks in the multilateral cyber norms formulation process, Macron’s efforts are perhaps of Wilsonian proportions.
A key difference, however, was that Macron’s efforts were devised hand-in-glove with Microsoft — one of the most powerful and influential private sector actors of our time. Microsoft’s involvement is unsurprising given that private entities have become a critical component of the global cybersecurity landscape and governments need to start thinking about how to optimise their participation in this process.
Indeed, one of the defining features of cyberspace is its incompatibility with state-centric ‘command and control’ formulae that lead to the ordering of other global security regimes — such as nuclear non-proliferation. The decentralised nature of cyberspace means that private sector actors play a vital role in implementing the rules designed to secure cyberspace.
Simultaneously, private actors such as Microsoft have recognised the utility of clearly defined ‘rules of the road’ which ensure certainty and stability in cyberspace and ensure its trustworthiness among global customers.
Normative deadlock
There have been multiple gambits to develop universal norms of responsible state behaviour to foster cyber stability. The United Nations-Group of Governmental Experts (UN-GGE) has been constituted five times now and will meet again in January 2019.
While the third and fourth GGEs in 2013 and 2015 respectively made some progress towards agreeing on some baseline principles, the fifth GGE broke down due to opposition from states including Russia, China and Cuba on the application of specific principles of international law to cyberspace.
This was an extension of a long-running ‘Cold War’ like divide among states at the United Nations. The US along with its NATO allies believe in creating voluntary non-binding norms for cybersecurity through the application of international law in its entirety while Russia, China and its allies in the Shanghai Co-operation Organization (SCO) reject the premise that international law applies in its entirety and call for the negotiation of an independent treaty for cyberspace that lays down binding obligations on states.
Critical role
The private sector has begun to play a critical role in breaking this deadlock. Recent history is testament to catalytic roles played by non-state actors in cementing global co-operative regimes.
For example, Dupont — the world’s leading ChloroFluoroCarbon (CFC) producer — played a leading role in the 1970s and 1980s towards the development of The Montreal Protocol on Substances that Deplete the Ozone Layer and gained positive recognition for its efforts.
Another example is the International Committee of the Red Cross (ICRC) — a non-governmental organisation that played a crucial role in the development of the Geneva Conventions and its Additional Protocols, which regulate the conduct of atrocities in warfare by preparing initial drafts of the treaties and circulating them to key government players.
Similarly, in cyberspace, Microsoft’s Digital Geneva Convention which devised a set of rules to protect civilian use of the internet was put forward by Chief Legal Officer, Brad Smith two months before the fifth GGE met in 2017.
Despite the breakdown at the UN-GGE, Microsoft pushed on with the Tech Accords — a public commitment made by (as of today) 69 companies “agreeing to defend all customers everywhere from malicious attacks by cyber-criminal enterprises and nation-states.”
Much like the ICRC, Microsoft leads commendable diplomatic efforts with the Paris Call as they reached out to states, civil society actors and corporations for their endorsement.
Looking Forward
Private sector-led normative efforts towards securing cyberspace are redundant in the absence of three key recommendations. First, is the implementation of best practices at the organisational level through the implementation of robust cyber defense mechanisms, the detection and mitigation of vulnerabilities and breach notifications — both to consumer and the government.
Second, is the development of mechanisms that enables direct co-operation between governments and private actors at the domestic level. In India, a Joint Working Group between the Data Security Council of India (DSCI) and the National Security Council Secretariat (NSCS) was set up in 2012 to explore a Private Public Partnership on cyber-security in India , which has great potential but is yet to report any tangible outcomes.
The third and final point is the recognition that their efforts need to result in a plurality of states coming to the negotiating table. The absence of the US, China and Russia in the Paris Call are eerily reminiscent of the lack of US participation in Woodrow Wilson’s League of Nations, which was one of the reasons for its ultimate failure.
Microsoft needs to keep on calling with Paris but Beijing, Washington and Alibaba need to pick up.
Is the new ‘interception’ order old wine in a new bottle?
An opinion piece co-authored by Elonnai Hickok, Vipul Kharbanda, Shweta Mohandas and Pranav M. Bidare was published in Newslaundry.com on December 27, 2018.
On December 20, 2018, through an order issued by the Ministry of Home Affairs (MHA), 10 security agencies—including the Intelligence Bureau, the Central Bureau of Investigation, the Enforcement Directorate and the National Investigation Agency—were listed as the intelligence agencies in India with the power to intercept, monitor and decrypt "any information" generated, transmitted, received, or stored in any computer under Rule 4 of the Information Technology (Procedure and Safeguards for Interception, Monitoring and Decryption of Information) Rules, 2009, framed under section 69(1) of the IT Act.
On December 21, the Press Information Bureau published a press release providing clarifications to the previous day’s order. It said the notification served to merely reaffirm the existing powers delegated to the 10 agencies and that no new powers were conferred on them. Additionally, the release also stated that “adequate safeguards” in the IT Act and in the Telegraph Act to regulate these agencies’ powers.
Presumably, these safeguards refer to the Review Committee constituted to review orders of interception and the prior approval needed by the Competent Authority—in this case, the secretary in the Ministry of Home Affairs in the case of the Central government and the secretary in charge of the Home Department in the case of the State government.
As noted in the press release, the government has always had the power to authorise intelligence agencies to submit requests to carry out the interception, decryption, and monitoring of communications, under Rule 4 of the Information Technology (Procedure and Safeguards for Interception, Monitoring and Decryption of Information) Rules, 2009, framed under section 69(1) of the IT Act.
When considering the implications of this notification, it is important to look at it in the larger framework of India’s surveillance regime, which is made up of a set of provisions found across multiple laws and operating licenses with differing standards and surveillance capabilities.
- Section 5(2) of the Indian Telegraph Act, 1885 allows the government (or an empowered authority) to intercept or detain transmitted information on the grounds of a public emergency, or in the interest of public safety if satisfied that it is necessary or expedient so to do in the interests of the sovereignty and integrity of India, the security of the State, friendly relations with foreign states or public order or for preventing incitement to the commission of an offence. This is supplemented by Rule 419A of the Indian Telegraph Rules, 1951, which gives further directions for the interception of these messages.
- Condition 42 of the Unified Licence for Access Services, mandates that every telecom service provider must facilitate the application of the Indian Telegraph Act. Condition 42.2 specifically mandates that the license holders must comply with Section 5 of the same Act.
- Section 69(1) of the Information Technology Act and associated Rules allows for the interception, monitoring, and decryption of information stored or transmitted through any computer resource if it is found to be necessary or expedient to do in the interest of the sovereignty or integrity of India, defense of India, security of the State, friendly relations with foreign States or public order or for preventing incitement to the commission of any cognizable offence relating to above or for investigation of any offence.
- Section 69B of the Information Technology Act and associated Rules empowers the Centre to authorise any agency of the government to monitor and collect traffic data “to enhance cyber security, and for identification, analysis, and prevention of intrusion, or spread of computer contaminant in the country”.
- Section 92 of the CrPc allows for a Magistrate or Court to order access to call record details.
Notably, a key difference between the IT Act and the Telegraph Act in the context of interception is that the Telegraph Act permits interception for preventing incitement to the commission of an offence on the condition of public emergency or in the interest of public safety while the IT Act permits interception, monitoring, and decryption of any cognizable offence relating to above or for investigation of any offence. Technically, this difference in surveillance capabilities and grounds for interception could mean that different intelligence agencies would be authorized to carry out respective surveillance capabilities under each statute. Though the Telegraph Act and the associated Rule 419A do not contain an equivalent to Rule 4—nine Central Government agencies and one State Government agency have previously been authorized under the Act. The Central Government agencies authorised under the Telegraph Act are the same as the ones mentioned in the December 20 notification with the following differences:
- Under the Telegraph Act, the Research and Analysis Wing (RAW) has the authority to intercept. However, the 2018 notification more specifically empowers the Cabinet Secretariat of RAW to issue requests for interception under the IT Act.
- Under the Telegraph Act, the Director General of Police, of concerned state/Commissioner of Police, Delhi for Delhi Metro City Service Area, has the authority to intercept. However, the 2018 notification specifically authorises the Commissioner of Police, New Delhi with the power to issue requests for interception.
That said, the IT (Procedure and safeguard for Monitoring and Collecting Traffic Data or Information) Rules, 2009 under 69B of the IT Act contain a provision similar to Rule 4 of the IT (Procedure and Safeguards for Interception, Monitoring and Decryption of Information) Rules, 2009 - allowing the government to authorize agencies that can monitor and collect traffic data. In 2016, the Central Government authorised the Indian Computer Emergency Response Team to monitor and collect traffic data, or information generated, transmitted, received, or stored in any computer resource. This was an exercise of the power conferred upon the Central Government by Section 69B(1) of the IT Act. However, this notification does not reference Rule 4 of the IT Rules, thus it is unclear if a similar notification has been issued under Rule 4.
While it is accurate that the order does not confer new powers, areas of concern that existed with India’s surveillance regime continue to remain including the question of whether 69(1) and 69B and associated Rules are constitutionally valid, the lack of transparency by the government and the prohibition of transparency by service providers, heavy handed penalties on service providers for non-compliance, and a lack of legal backing and oversight mechanisms for intelligence agencies. Some of these could be addressed if the draft Data Protection Bill 2018 is enacted and the Puttaswamy Judgement fully implemented.
Conclusion
The MHA’s order and the press release thereafter have served to publicise and provide needed clarity with respect to the powers vested in which intelligence agencies in India under section 69(1) of the IT Act. This was previously unclear and could have posed a challenge to ensuring oversight and accountability of actions taken by intelligence agencies issuing requests under section 69(1) .
The publishing of the list has subsequently served to raise questions and create a debate about key issues concerning privacy, surveillance and state overreach. On December 24, the order was challenged by advocate ML Sharma on the grounds of it being illegal, unconstitutional and contrary to public interest. Sharma in his contention also stated the need for the order to be tested on the basis of the right to privacy established by the Supreme Court in Puttaswamy which laid out the test of necessity, legality, and proportionality. According to this test, any law that encroaches upon the privacy of the individual will have to be justified in the context of the right to life under Article 21.
But there are also other questions that exist. India has multiple laws enabling its surveillance regime and though this notification clarifies which intelligence agencies can intercept under the IT Act, it is still seemingly unclear which intelligence agencies can monitor and collect traffic data under the 69B Rules. It is also unclear what this order means for past interceptions that have taken place by agencies on this list or agencies outside of this list under section 69(1) and associated Rules of the IT Act. Will these past interceptions possess the same evidentiary value as interceptions made by the authorised agencies in the order?
Economics of Cybersecurity: Literature Review Compendium
Authored by Natallia Khaniejo and edited by Amber Sinha
Politics and economics are increasingly being amalgamated with Cybernetic frameworks and consequently Critical infrastructure has become intrinsically dependent on Information and Communication Technology (ICTs). The rapid evolution of technological platforms has been accompanied by a concomitant rise in the vulnerabilities that accompany them. Recurrent issues include concerns like network externalities, misaligned incentives and information asymmetries. Malignant actors use these vulnerabilities to breach secure systems, access and sell data, and essentially destabilize cyber and network infrastructures. Additionally, given the relative nascence of the realm, establishing regulatory policies without limiting innovation in the space becomes an additional challenge as well. The lack of uniform understanding regarding the definition and scope of what can be defined as Cybersecurity also serves as a barrier preventing the implementation of clear guidelines. Furthermore, the contrast between what is convenient and what is ‘sanitary’ in terms of best practices for cyber infrastructures is also a constant tussle with recommendations often being neglected in favor of efficiency. In order to demystify the security space itself and ascertain methods of effective policy implementation, it is essential to take stock of current initiatives being proposed for the development and implementation of cybersecurity best practices, and examine their adequacy in a rapidly evolving technological environment. This literature review attempts to document the various approaches that are being adopted by different stakeholders towards incentivizing cybersecurity and the economic challenges of implementing the same.
Click on the below links to read the entire story:
Registering for Aadhaar in 2019
The article was published in Business Standard on January 2, 2019.
Last November, a global committee of lawmakers from nine countries the UK, Canada, Ireland, Brazil, Argentina, Singapore, Belgium, France and Latvia summoned Mark Zuckerberg to what they called an “international grand committee” in London. Mr. Zuckerberg was too spooked to show up, but Ashkan Soltani, former CTO of the FTC was among those who testified against Facebook. He said “in the US, a lot of the reticence to pass strong policy has been about killing the golden goose” referring to the innovative technology sector. Mr. Soltani went on to argue that “smart legislation will incentivise innovation”. This could be done either intentionally or unintentionally by governments. For example, a poorly thought through blocking of pornography can result in innovative censorship circumvention technologies. On other occasions, this can happen intentionally. I hope to use my inaugural column in these pages to provide an Indian example of such intentional regulatory innovation.
Eight years ago, almost to this date, my colleague Elonnai Hickok wrote an open letter to the Parliamentary Finance Committee on what was then called the UID or Unique Identity. She compared Aadhaar to the digital identity project started by the National Democratic Alliance (NDA) government in 2001. Like the Vajpayee administration which was working in response to the Kargil War, she advocated a decentralised authentication architecture using smart cards based on public key cryptography. Last year, even before the five-judge constitutional bench struck down Section 57 of the Aadhaar Act, the UIDAI preemptively responded to this regulatory development by launching offline Aadhaar cards. This was to be expected especially since from the A.P. Shah Committee report, the Puttaswamy Judgment, the B.N. Srikrishna Committee consultation paper, report and bill, the principle of “privacy by design” was emerging as a key Indian regulatory principle in the domain of data protection.
The introduction of the offline Aadhaar mechanism eliminates the need for biometrics during authentication. I have previously provided 11 reasons why biometrics is inappropriate technology for e-governance applications by democratic governments, and this comes as a massive relief for both human rights activists and security researchers. Second, it decentralises authentication, meaning that there is a no longer a central database that holds a 360-degree view of all incidents of identification and authentication. Third, it dramatically reduces the attack surface for Aadhaar numbers, since only the last four digits remain unmasked on the card. Each data controller using Aadhaar will have to generate his/her own series of unique identifiers to distinguish between residents. If those databases leak or get breached, it won’t tarnish the credibility of Aadhaar or the UIDAI to the same degree. Fourth, it increases the probability of attribution in case a data breach were to occur; if the breached or leaked data contains identifiers issued by a particular data controller, it would become easier to hold them accountable and liable for the associated harms. Fifth, unlike the previous iteration of the Aadhaar “card”, on which the QR code was easy to forge and alter, this mechanism provides for integrity and tamper detection because the demographic information contained within the QR code is digitally signed by the UIDAI. Finally, it retains the earlier benefit of being very cheap to issue, unlike smart cards.
Thanks to the UIDAI, the private sector is also being forced to implement privacy by design. Previously, since everyone was responsible for protecting Aadhaar numbers, nobody was. Data controllers would gladly share the Aadhaar number with their contractors, that is, data processors, since nobody could be held responsible. Now, since their own unique identifiers could be used to trace liability back to them, data controllers will start using tokenisation when they outsource any work that involves processing of the collected data. Skin in the game immediately breeds more responsible behaviour in the ecosystem.
The fintech sector has been rightfully complaining about regulatory and technological uncertainty from last year’s developments. This should be addressed by developing open standards and free software to allow for rapid yet secure implementation of these changes. The QR code standard itself should be an open standard developed by the UIDAI using some of the best practices common to international standard setting organisations like the World Wide Web Consortium, Internet Engineers Task Force and the Institute of Electrical and Electronics Engineers. While the UIDAI might still choose to take the final decision when it comes to various technological choices, it should allow stakeholders to make contributions through comments, mailing lists, wikis and face-to-face meetings. Once a standard has been approved, a reference implementation must be developed by the UIDAI under liberal licences, like the BSD licence that allows for both free software and proprietary software derivative works. For example, a software that can read the QR code as well as send and receive the OTP to authenticate the resident. This would ensure that smaller fintech companies with limited resources can develop secure systems.
Since Justice Dhananjaya Y. Chandrachud’s excellent dissent had no other takers on the bench, holdouts like me must finally register for an Aadhaar number since we cannot delay filing taxes any further. While I would still have preferred a physical digital artefact like a smart card (built on an open standard), I must say it is a lot less scary registering for Aadhaar in 2019 than it was in 2010, given how the authentication modalities have since evolved.
Response to TRAI Consultation Paper on Regulatory Framework for Over-The-Top (OTT) Communication Services
Click here to view the submission (PDF).
This submission presents a response by Gurshabad Grover, Nikhil Srinath and Aayush Rathi (with inputs from Anubha Sinha and Sai Shakti) to the Telecom Regulatory Authority of India’s “Consultation Paper on Regulatory Framework for Over-The-Top (OTT) Communication Services (hereinafter “TRAI Consultation Paper”) released on November 12, 2018 for comments. CIS appreciates the continual efforts of Telecom Regulatory Authority of India (TRAI) to have consultations on the regulatory framework that should be applicable to OTT services and Telecom Service Providers (TSPs). CIS is grateful for the opportunity to put forth its views and comments.
Addendum: Please note that this document differs in certain sections from the submission emailed to TRAI: this document was updated on January 9, 2019 with design and editorial changes to enhance readability. The responses to Q5 and Q9 have been updated. This updated document was also sent to TRAI.
How to make EVMs hack-proof, and elections more trustworthy
The article was published in Times of India on December 9, 2018.
Electronic voting machines (EVM) have been in use for general elections in India since 1999 having been first introduced in 1982 for a by-election in Kerala. The EVMs we use are indigenous, having been designed jointly by two public-sector organisations: the Electronics Corporation of India Ltd. and Bharat Electronics Ltd. In 1999, the Karnataka High Court upheld their use, as did the Madras High Court in 2001.
Since then a number of other challenges have been levelled at EVMs, but the only one that was successful was the petition filed by Subramanian Swamy before the Supreme Court in 2013. But before we get to Swamy's case and its importance, we should understand what EVMs are and how they are used.
The EVM used in India are standardised and extremely simple machines. From a security standpoint this makes them far better than the myriad different, and some notoriously insecure machines used in elections in the USA. Are they 'hack-proof' and 'infallible' as has been claimed by the ECI? Not at all.
Similarly simple voting machines in the Netherlands and Germany were found to have vulnerabilities, leading both those countries to go back to paper ballots.
Because the ECI doesn't provide security researchers free and unfettered access to the EVMs, there had been no independent scrutiny until 2010. That year, an anonymous source provided a Hyderabad-based technologist an original EVM. That technologist, Hari Prasad, and his team worked with some of the world's foremost voting security experts from the Netherlands and the US, and demonstrated several actual live hacks of the EVM itself and several theoretical hacks of the election process, and recommended going back to paper ballots. Further, EVMs have often malfunctioned, as news reports tell us. Instead of working on fixing these flaws, the ECI arrested Prasad (for being in possession of a stolen EVM) and denied Princeton Prof Alex Halderman entry into India when he flew to Delhi to publicly discuss their research. Even in 2017, when the ECI challenged political parties to âhackâ EVMs, it did not provide unfettered access to the machines.
While paper ballots may work well in countries like Germany, they hadn't in India, where in some parts ballot-stuffing and booth-capturing were rampant. The solution as recognised by international experts, and as the ECI eventually realised, was to have the best of both worlds and to add a printer to the EVMs.
These would print out a small slip of paper containing the serial number and name of the candidate, and the symbol of the political party, so that the sighted voter could verify that her vote has been cast correctly. This paper would then be deposited in a sealed box, which would provide a paper trail that could be used to audit the correctness of the EVM. They called this VVPAT: voter-verifiable paper audit trail. Swamy, in his PIL, asked for VVPAT to be introduced. The Supreme Court noted that the ECI had already done trials with VVPAT, and made them mandatory.
However, VVPATs are of no use unless they are actually counted to ensure that the EVM tally and the paper tally do match. The most advanced and efficient way of doing this has been proposed by Lindeman & Stark, through a methodology called (RLAs), in which you keep auditing until either you've done a full hand count or you have strong evidence that continuing is pointless. The ECI could request the Indian Statistical Institute for its recommendations in implementing RLAs. Also, it must be remembered, current VVPAT technology are inaccessible for persons with visual impairments.
While in some cases, the ECI has conducted audits of the printed paper slips, in 2017 it officially noted that only the High Court can order an audit and that the ECI doesn't have the power to do so under election law. Rule 93 of the Conduct of Election Rules needs to be amended to make audits mandatory.
The ECI should also create separate security procedures for handling of VVPATs and EVMs, since there are now reports of EVMs being replaced 'after' voting has ended. Having separate handling of EVMs and VVPATs would ensure that two different safe-houses would need to be broken into to change the results of the vote. Implementing these two changes, changing election law to make risk-limiting audits mandatory, and improving physical security practices would make Indian elections much more trustworthy than they are now, while far more needs to be done to make them inclusive and accessible to all.
The DNA Bill has a sequence of problems that need to be resolved
The opinion piece was published by Newslaundry on January 14, 2019.
On January 9, Science and Technology Minister Harsh Vardhan introduced the DNA Technology (Use and Application) Regulation Bill, 2018, amidst opposition and questions about the Bill’s potential threat to privacy and the lack of security measures. The Bill aims to provide for the regulation of the use and application of DNA technology for certain criminal and civil purposes, such as identifying offenders, suspects, victims, undertrials, missing persons and unknown deceased persons. The Schedule of the Bill also lists civil matters where DNA profiling can be used. These include parental disputes, issues relating to immigration and emigration, and establishment of individual identity. The Bill does not cover the commercial or private use of DNA samples, such as private companies providing DNA testing services for conducting genetic tests or for verifying paternity.
The Bill has seen several iterations and revisions from when it was first introduced in 2007. However, after repeated expert consultations, the Bill even at its current stage is far from a comprehensive legislation. Experts have articulated concerns that the version of the Bill that was presented post the Puttaswamy judgement still fails to make provisions that fully uphold the privacy and dignity of the individual. The hurry to pass the Bill by pushing for it by extending the winter session and before the Personal Data Protection Bill is brought before Parliament is also worrying. The Bill was passed in the Lok Sabha with only one amendment: which changed the year of the Bill from 2018 to 2019.
Need for a better-drafted legislation
Although the Schedule of the Bill includes certain civil matters under its purview, some important provisions are silent on the procedure that is to be followed for these civil matters. For example, the Bill necessitates the consent of the individual for DNA profiling in criminal investigation and for identifying missing persons. However, the Bill is silent on the requirement for consent in all civil matters that have been brought under the scope of the Bill.
The omission of civil matters in the provisions of the Bill that are crucial for privacy is just one of the ways the Bill fails to ensure privacy safeguards. The civil matters listed in the Bill are highly sensitive (such as paternity/maternity, use of assisted reproductive technology, organ transplants, etc.) and can have a far-reaching impact on a number of sections of society. For example, the civil matters listed in the Bill affect women not just in the case of paternity disputes but in a number of matters concerning women including the Domestic Violence Act and the Prenatal Diagnostic Techniques Act. Other matters such as pedigree, immigration and emigration can disproportionately impact vulnerable groups and communities, raising raises concerns of discrimination and abuse.
Privacy and security concerns
Although the Bill makes provisions for written consent for the collection of bodily substances and intimate bodily substances, the Bill allows non-consensual collection for offences punishable by death or imprisonment for a term exceeding seven years. Another issue with respect to collection with consent is the absence of safeguards to ensure that consent is given freely, especially when under police custody. This issue was also highlighted by MP NK Premachandran when he emphasised that the Bill be sent to a Parliamentary Standing Committee.
Apart from the collection, the Bill fails to ensure the privacy and security of the samples. One such example of this failure is Section 35(b), which allows access to the information contained in the DNA Data Banks for the purpose of training. The use of these highly sensitive data—that carry the risk of contamination—for training poses risks to the privacy of the people who have deposited their DNA both with and without consent.
An earlier version of the Bill included a provision for the creation of a population statistics databank. Though this has been removed now, there is no guarantee that this provision will not make its way through regulation. This is a cause for concern as the Bill also covers certain civil cases including those relating to immigration and emigration.
Conclusion
In July 2018, the Justice Sri Krishna Committee released the draft Personal Data Protection Bill. The Bill was open for public consultation and is now likely to be introduced in Parliament in June. The PDP Bill, while defining “sensitive personal data”, provides an exhaustive list of data that can be considered sensitive, including biometric data, genetic data and health data. Under the Bill, sensitive personal data has heightened parameters for collection and processing, including clear, informed, and specific consent. Ideally, the DNA Bill should be passed after ensuring that it is in line with the PDP Bill.
The DNA Bill, once it becomes a law, will allow for law enforcement authorities to collect sensitive DNA data and database the same for forensic purposes without a number of key safeguards in place with respect to security and the rights of individuals. In 2016 alone, 29,75,711 crimes under various provisions the Indian Penal Code were reported. One can only guess the sheer number of DNA profiles and related information that will be collected from both criminal and specified civil cases. The Bill needs to be revised to reduce all ambiguity with respect to the civil cases, and also to ensure that it is in line with the data protection regime in India. A comprehensive privacy legislation should be enacted prior to the passing of this Bill.
There are still studies and cases that show that DNA testing can be fallible. The Indian government needs to ensure that there is proper sensitisation and training on the collection, storage and use of DNA profiles as well as the recognition and awareness of the fact that the DNA tests are not infallible amongst key stakeholders, including law enforcement and the judiciary.
India should reconsider its proposed regulation of online content
The article was published in the Hindustan Times on January 24, 2019. The author would like to thank Akriti Bopanna and Aayush Rathi for their feedback.
Flowing from the Information Technology (IT) Act, India’s current intermediary liability regime roughly adheres to the “safe harbour” principle, i.e. intermediaries (online platforms and service providers) are not liable for the content they host or transmit if they act as mere conduits in the network, don’t abet illegal activity, and comply with requests from authorised government bodies and the judiciary. This paradigm allows intermediaries that primarily transmit user-generated content to provide their services without constant paranoia, and can be partly credited for the proliferation of online content. The law and IT minister shared the intent to change the rules this July when discussing concerns of online platforms being used “to spread incorrect facts projected as news and designed to instigate people to commit crime”.
On December 24, the government published and invited comments to the draft intermediary liability rules. The draft rules significantly expand “due diligence” intermediaries must observe to qualify as safe harbours: they mandate enabling “tracing” of the originator of information, taking down content in response to government and court orders within 24 hours, and responding to information requests and assisting investigations within 72 hours. Most problematically, the draft rules go much further than the stated intentions: draft Rule 3(9) mandates intermediaries to deploy automated tools for “proactively identifying and removing [...] unlawful information or content”.
The first glaring problem is that “unlawful information or content” is not defined. A conservative reading of the draft rules will presume that the phrase means restrictions on free speech permissible under Article 19(2) of the Constitution, including that relate to national integrity, “defamation” and “incitement to an offence”.
Ambiguity aside, is mandating intermediaries to monitor for “unlawful content” a valid requirement under “due diligence”? To qualify as a safe harbour, if an intermediary must monitor for all unlawful content, then is it substantively different from an intermediary that has active control over its content and not a safe harbour? Clearly, the requirement of monitoring for all “unlawful content” is so onerous that it is contrary to the philosophy of safe harbours envisioned by the law.
By mandating automated detection and removal of unlawful content, the proposed rules shift the burden of appraising legality of content from the state to private entities. The rule may run afoul of the Supreme Court’s reasoning in Shreya Singhal v Union of India wherein it read down a similar provision because, among other reasons, it required an intermediary to “apply [...] its own mind to whether information should or should not be blocked”. “Actual knowledge” of illegal content, since then, has held to accrue to the intermediary only when it receives a court or government order.
Given the inconsistencies with legal precedence, the rules may not stand judicial scrutiny if notified in their current form.
The lack of technical considerations in the proposal is also apparent since implementing the proposal is infeasible for certain intermediaries. End-to-end encrypted messaging services cannot “identify” unlawful content since they cannot decrypt it. Internet service providers also qualify as safe harbours: how will they identify unlawful content when it passes encrypted through their network? Presumably, the government’s intention is not to disallow end-to-end encryption so that intermediaries can monitor content.
Intermediaries that can implement the rules, like social media platforms, will leave the task to algorithms that perform even specific tasks poorly. Just recently, Tumblr flagged its own examples of permitted nudity as pornography, and Youtube slapped a video of randomly-generated white noise with five copyright-infringement notices. Identifying more contextual expression, such as defamation or incitement to offences, is a much more complex problem. In the lack of accurate judgement, platforms will be happy to avoid liability by taking content down without verifying whether it violated law. Rule 3(9) also makes no distinction between large and small intermediaries, and has no requirement for an appeal system available to users whose content is taken down. Thus, the proposed rules set up an incentive structure entirely deleterious to the exercise of the right to freedom of expression. Given the wide amplitude and ambiguity of India’s restrictions on free speech, online platforms will end up removing swathes of content to avoid liability if the draft rules are notified.
The use of draconian laws to quell dissent plays a recurring role in the history of the Indian state. The draft rules follow India’s proclivity to join the ignominious company of authoritarian nations when it comes to disrespecting protections for freedom of expression. To add insult to injury, the draft rules are abstruse, ignore legal precedence, and betray a poor technological understanding. The government should reconsider the proposed regulation and the stance which inspired it, both of which are unsuited for a democratic republic.
Response to GCSC on Request for Consultation: Norm Package Singapore
The Global Commission on the Stability of Cyberspace, a multi-stakeholder initiative comprised of eminent individuals across the globe that seeks to promote awareness and understanding among the various cyberspace communities working on issues related to international cyber security. CIS is honoured to have contributed research to this initiative previously and commends the GCSC for the work done so far.
The GCSC announced the release of its new Norm Package on Thursday November 8, 2018 that featured six norms that sought to promote the stability of cyberspace.This was done with the hope that they may be adopted by public and private actors in a bid to improve the international security architecture of cyberspace
The norms introduced by the GCSC focus on the following areas:
- Norm to Avoid Tampering
- Norm Against Commandeering of ICT Devices into Botnets
- Norm for States to Create a Vulnerability Equities Process
- Norm to Reduce and Mitigate Significant Vulnerabilities
- Norm on Basic Cyber Hygiene as Foundational Defense
- Norm Against Offensive Cyber Operations by Non-State Actors
The GCSC opened a public comment procedure to solicit comments and obtain additional feedback. CIS responded to the public call-offering comments on all six norms and proposing two further norms. We sincerely hope that the Commission may find the feedback useful in their upcoming deliberations.
A Gendered Future of Work
Abstract
Studies around the future of work have predicted technological disruption across industries, leading to a shift in the nature and organisation of work, as well as the substitution of certain kinds of jobs and growth of others. This paper seeks to contextualise this disruption for women workers in India. The paper argues that two aspects of the structuring of the labour market will be pertinent in shaping the future of work: the gendered nature of skilling and skill classification, and occupational segregation along the lines of gender and caste. We will take the case study of the electronics manufacturing sector to flesh out these arguments further. Finally, we bring in a discussion on the platform economy, a key area of discussion under the future of work. We characterise it as both generating employment opportunities, particularly for women, due to the flexible nature of work, and retrenching traditional inequalities built into non-standard employment.
Introduction
The question on the future of work across the global North - and parts of the global South - has recently been raised with regards to technological disruption, as a result of digitisation, and more recently, automation (Leurent et al., 2018). While the former has been successively replacing routine cognitive tasks, the latter, defined as the deployment of cyber-physical systems, will enable the replacement of manual tasks previously being performed using human labour (Leurent et al., 2018). In combination, these are expected to have a twofold effect on: the “structure of employment”, which includes occupational roles and nature of tasks, and “forms of work”, including interpersonal relationships and organization of work (Piasna and Drahokoupil, 2017). Building from historical evidence, the diffusion of digitising or automative technologies can be anticipated to take place differently across economic contexts, with different factors causing varied kinds of technological upgradation across the global North and South. Moreover, occupational analysis projects occupations in the latter to be at a significantly higher risk of being disrupted than the former (WTO, 2017).
However, these concerns are somewhat offset by the barriers to technological adoption that exist in lower income countries such as lower wages, and a relatively higher share of non-routine manual jobs (WTO, 2017). 1 With the global North typically being early and quicker adopters of automation technologies, the differential technology levels in countries have been in fact been utilised to understand global inequality (Foster and Rosenzweig, 2010). Consequently, the labour-cost advantage that economies in the global South enjoy may be eroded, leading to what may be understood as re-shoring/back shoring - a reversal of offshoring (ILO, 2017). This may especially be the case in sectors where there has been a failure to capitalise on the labour-cost advantage by evolving supplier networks to complement assembly activities (such as in manufacturing) (Milington, 2017), or production of high-value services (such as in the services sector).
Extensive work over the past three decades has been conducted on the effects of liberalisation and globalisation on employment for women in the global South. This has explored conditional empowerment and exploitation as women are increasingly employed in factories and offices, with different ways of reproducing and challenging patriarchal relations. However, the effects of reshoring and technological disruption have yet to be explored to any degree of granularity for this population, which arguably will be one of the first to face its effects. This can be seen as a consequence of industries that rely on low cost labour being impacted first by re-shoring, such as textile and apparel and electronics manufacturing (Kucera and Tejani, 2014).
Download the full paper here.
CIS Submission to UN High Level Panel on Digital Cooperation
The high-level panel on
Digital Cooperation was convened by the UN Secretary-General to advance
proposals to strengthen cooperation in the digital space among
Governments, the private sector, civil society, international
organizations, academia, the technical community and other relevant
stakeholders. The Panel issued a call for input that called for
responses to various questions. CIS responded to the call for inputs.
The response can be accessed here.
Response to the Draft of The Information Technology [Intermediary Guidelines (Amendment) Rules] 2018
This document presents the Centre for Internet & Society (CIS) response to the Ministry of Electronics and Information Technology’s invitation to comment and suggest changes to the draft of The Information Technology [Intermediary Guidelines (Amendment) Rules] 2018 (hereinafter referred to as the “draft rules”) published on December 24, 2018. CIS is grateful for the opportunity to put forth its views and comments. This response was sent on the January 31, 2019.
In this response, we aim to examine whether the draft rules meet tests of constitutionality and whether they are consistent with the parent Act. We also examine potential harms that may arise from the Rules as they are currently framed and make recommendations to the draft rules that we hope will help the Government meet its objectives while remaining situated within the constitutional ambit.
The response can be accessed here.
The Future of Work in the Automotive Sector in India
Introduction
The adoption of information and communication based technology (ICTs) for industrial use is not a new phenomenon. However, the advent of Industry 4.0 hasbeen described as a paradigm shift in production, involving widespread automation and irreversible shifts in the structure of jobs. Industry 4.0 is widely understood as the technical integration of cyber-physical systems into production and logistics, and the use of Internet of Things (IoTs) in processes and systems. This may pose major challenges for industries, workers, and policymakers as they grapple with shifts in the structure of employment and content of jobs, bring about significant changes in business models, downstream services and the organisation of work.
The adoption of information and communication based technology (ICTs) for industrial use is not a new phenomenon. However, the advent of Industry 4.0 hasbeen described as a paradigm shift in production, involving widespread automation and irreversible shifts in the structure of jobs. Industry 4.0 is widelyunderstood as the technical integration of cyber-physical systems into production and logistics, and the use of Internet of Things (IoTs) in processes and systems.This may pose major challenges for industries, workers, and policymakers as they grapple with shifts in the structure of employment and content of jobs, bringabout significant changes in business models, downstream services and the organisation of work.
Industry 4.0 is characterised by four elements. First, the use of intelligent machines could have significant impact on production through the introduction of automated processes in ‘smart factories.’ Second, real-time production would begin optimising utilisation capacity, with shorter lead times and avoidance of standstills. Third, the self-organisation of machines can lead to decentralisation of production. Finally, Industry 4.0 is commonly characterised by the individualisation of production, responding to customer requests. The advancement of digital technology and consequent increase in automation has raised concerns about unemployment and changes in the structure of work. Globally, automation in manufacturing and services has been posited as replacing jobs with routine task content, while generating jobs with non-routine cognitive and manual tasks.
Some scholars have argued that unemployment will increase globally as technology eliminates tens of million of jobs in the manufacturing sector. It could then result in the lowering of wages and employment opportunities for low skilled workers, and increased investment in capital-intensive technologies for employer.
However, this theory of technologically driven job loss and increasing inequality has been contested on numerous occasions, with the assertion that technology will be an enabler, will change task content rather than displace workers, and will also create new jobs . It has further been argued that other factors such as increasing globalisation, weakening trade unions and platforms for collective bargaining, and disaggregation of the supply chain through outsourcing has led to declined wages, income inequality, inadequate health and safety conditions, and displacement of workers.
In India, there is little evidence of unemployment caused by adoption of technology due to Industry 4.0, but there is a strong consensus that technology affects labour by changing the job mix and skill demand. It should be noted that technological adoption under Industry 4.0 in advanced industrial economies has been driven by cost-benefit analysis due to accessible technology, and a highly skilled labour force. However, these key factors are serious impediments in the Indian context, which brings the large scale adoption of cyber-physical systems into question.
The diffusion of low cost manual labour across a large majority of roles in manufacturing raises concerns about the cost-benefit analysis of investing capital inexpensive automative technology, while also accounting for the resultant displacement of labour. Further, the skill gap across the labour force implies that the adoption of cyber-physical systems would require significant up-skilling or re-skilling to meet the potential shortage in highly skilled professionals.
This is an in-depth case study on the future of work in the automotive sector in India. We chose to focus on the future of work in the automotive sector in India for two reasons: first, the Indian automotive sector is one of largest contributors to the GDP at 7.2 percent, and second, it is one of the largest employment generators among non-agricultural industries. The first section details the structure of the automotive industry in India, including the range of stakeholders, and the national policy framework, through an analysis of academic literature, government reports, and legal documents.
The second section explores different aspects of the future of work in the automotive sector, through a combination of in-depth semi-structured interviews and enterprise-based surveys in the North Indian belt of Gurgaon-Manesar-Dharuhera-Bawal. Challenges posed by shifts in the industrial relations framework, with increasing casualization and emergence of a typical forms of work, will also be explored, with specific reference to crises in collective bargaining and social security. We will then move onto looking at the state of female participation in the workforce in the automotive industry. The report concludes with policy recommendations addressing some of the challenges outlined above.
Read the full report here.
CIS Comment on ICANN's Draft FY20 Operating Plan and Budget
The following are our comments on relevant aspects from the different documents:
There are several significant undertakings which have not found adequate support in this budget, chief among them being the implementation of the ICANN Workstream 2 recommendations on Accountability. The budget accounts for any expenses that arise from WS2 as emanating from its contingency fund which is a mere 4%. Totalling more than 100 recommendations across 8 sub groups, execution of these would require significant expenditure. Ideally, this should have been budgeted for in the FY20 budget considering the final report was submitted in June, 2018 and conversations about its implementation have been carried out ever since. It is wondered if this is because the second Workstream does not have the effectuation of its recommendations in its mandate and hence it is easier for ICANN to be slow on it.[1] As a member of the community deeply interested in integrating human rights better in ICANN’s various processes, it is concerning to note the glacial pace of the approval of the aforementioned recommendations especially coupled with the lack of funds allocated to it. Further, there is 1 one person assigned to work on the WS2 implementation work which seems insufficient for the magnitude of work involved.[2]
A topical issue with ICANN currently is its tussle with the implementation of the General Data Protection Regulation (GDPR) and despite the prominence and extent of the legal burden involved, resources to complying with it have not been allocated. Again, it is within the umbrella of the contingency budget.
The Cross Community Working Group on New gTLD Auction Proceeds is also, presently, developing recommendations on how to distribute the proceeds. It is unclear where these will be funded from since their work is funded by the core ICANN budget yet it is assumed that the recommendations will be funded by the auction proceeds. Almost 7 years after the new gTLD round was open, it is alarming that ICANN has not formulated a plan for the proceeds and are still debating the merits of the entity which would resolve this question, as recently as the last ICANN meeting in October, 2018.
Another important policy development process being undertaken right now is the Working Group who is reviewing the current new gTLD policies to improve the process by proposing changes or new policies. There are no resources in the FY20 budget to implement the changes that will arise from this but only those to support the Working Group activities.
Lastly, the budgets lack information on how much each individual RIR contributes.
Staff costs
ICANN’s internal costs on their personnel have been rising for years and slated to account for more than half their annual budget with an estimated 56% or $76.3 million in the next financial year. The community has been consistent in calling upon them to revise their staff costs with many questioning if the growth in staff is justified.[3] There was criticism from all quarters such as the GNSO Council who stated that it is “not convinced that the proposed budget funds the policy work it needs to do over the coming year”.[4] The excessive use of professional service consultants has come under fire too.
As pointed out in a mailing list, in comments on the FY19 budget, every single constituency and stakeholder group remarked that personnel costs presented too high a burden on the budget. One of the suggestions presented by the NCSG was to relocate positions from from the LA headquarters to less expensive countries such as those in Asia. This can be seen from the high increase this budget of $200,000 in operational costs though no clear breakdown of that entails was given.
The view seems to be that ICANN repeatedly chooses to retain higher salaries while reducing funding for the community. This is even more of an issue since there employment remuneration scheme is opaque. In a DIDP I filed enquiring about the average salary across designations, gender, regions and the frequency of bonuses, the response was either to refer to their earlier documents which do not have concrete information or that the relevant documents were not in their possession.[5]
ICANN Fellowship
The budget of the fellowship has been reduced which is an important initiative to involve individuals in ICANN who cannot afford the cost of flying to the global ICANN meetings. The focus should be not only be on arriving at a suitable figure for the funding but also to ensure that people who either actively contribute or are likely to are supported as opposed to individuals who are already known in this circle.
Again, our attempts at understanding the Fellowship selection were met with resistance from ICANN. In a DIDP filed regarding it with questions such as if anyone had received it more than the maximum limit of thrice and details on the selection criteria, no clarity was provided.[6]
Lobbying and Sponsorship
At ICANN 63 in Barcelona, I enquired about ICANN’s sponsorship strategies and how the decision making is done with respect to which all events in each region to sponsor and for a comprehensive list of all sponsorship ICANN undertakes and receives. I was told such a document would be published soon but in the 4 months since then, none can be found. It is difficult to comment on the budget for such a team where there is not much information on the work it specifically carries out and the impact of such sponsoring activities. When questioned to someone on their team, I was told that it depends on the needs of each region and events that are significant in such regions. However without public accountability and transparency about these, sponsorship can be seen as a vague heading which could be better spent on community initiatives.
Talking of Transparency, it has also been pointed out that the Information Transparency Initiative has 3 million dollars set aside for its activities in this budget. It sounds positive yet with no deliverables to show in the past 2 years, it is difficult to ascertain the value of the investment in this initiative.
Lobbying activities do not find any mention in the budget and neither do the nature of sponsorship from other entities in terms of whether it is travel and accommodation of personnel or any other kind of institutional sponsorship.
[1] https://cis-india.org/internet-governance/blog/icann-work-stream-2-recommendations-on-accountability
[2] https://www.icann.org/en/system/files/files/proposed-opplan-fy20-17dec18-en.pdf
[3] http://domainincite.com/22680-community-calls-on-icann-to-cut-staff-spending
[4] Ibid
[5]https://cis-india.org/internet-governance/blog/didp-request-30-enquiry-about-the-employee-pay-structure-at-icann
[6] https://cis-india.org/internet-governance/blog/didp-31-on-icanns-fellowship-program
Intermediary liability law needs updating
The article was published in Business Standard on February 9, 2019.
Intermediaries get immunity from liability emerging from user-generated and third-party content because they have no “actual knowledge” until it is brought to their notice using “take down” requests or orders.
Since some of the harm caused is immediate, irreparable and irreversible, it is the preferred alternative to approaching courts for each case. When intermediary liability regimes were first enacted, most intermediaries were acting as common carriers — ie they did not curate the experience of users in a substantial fashion. While some intermediaries like Wikipedia continue this common carrier tradition, others driven by advertising revenue no longer treat all parties and all pieces of content neutrally. Facebook, Google and Twitter do everything they can to raise advertising revenues. They make you depressed. And if they like you, they get you to go out and vote. There is an urgent need to update intermediary liability law.
In response to being summoned by multiple governments, Facebook has announced the establishment of an independent oversight board. A global free speech court for the world’s biggest online country. The time has come for India to exert its foreign policy muscle. The amendments to our intermediary liability regime can have global repercussions, and shape the structure and functioning of this and other global courts.
While with one hand Facebook dealt the oversight board, with the other hand it took down APIs that would enable press and civil society to monitor political advertising in real time. How could they do that with no legal consequences? The answer is simple — those APIs were provided on a voluntary basis. There was no law requiring them to do so.
There are two approaches that could be followed. One, as scholar of regulatory theory Amba Kak puts it, is to “disincentivise the black box”. Most transparency reports produced by intermediaries today are on a voluntary basis; there is no requirement for this under law. Our new law could require a extensive transparency with appropriate privacy safeguards for the government, affected parties and the general public in terms of revenues, content production and consumption, policy development, contracts, service-level agreements, enforcement, adjudication and appeal. User empowerment measures in the user interface and algorithm explainability could be required. The key word in this approach is transparency.
The alternative is to incentivise the black box. Here faith is placed in technological solutions like artificial intelligence. To be fair, technological solutions may be desirable for battling child pornography, where pre-censorship (or deletion before content is published) is required. Fingerprinting technology is used to determine if the content exists in a global database maintained by organisations like the Internet Watch Foundation. A similar technology called Content ID is used pre-censor copyright infringement. Unfortunately, this is done by ignoring the flexibilities that exist in Indian copyright law to promote education, protect access knowledge by the disabled, etc. Even within such narrow application of technologies, there have been false positives. Recently, a video of a blogger testing his microphone was identified as a pre-existing copyrighted work.
The goal of a policy-maker working on this amendment should be to prevent repeats of the Shreya Singhal judgment where sections of the IT Act were read down or struck down. To avoid similar constitution challenges in the future, the rules should not specify any new categories of illegal content, because that would be outside the scope of the parent clause. The fifth ground in the list is sufficient — “violates any law for the time being in force”. Additional grounds, such as “harms minors in anyway”, is vague and cannot apply to all categories of intermediaries — for example, a dating site for sexual minorities. The rights of children need to be protected. But that is best done within the ongoing amendment to the POCSO Act.
As an engineer, I vote to eliminate redundancy. If there are specific offences that cannot fit in other parts of the law, those offences can be added as separate sections in the IT Act. For example, even though voyeurism is criminalised in the IT Act, the non-consensual distribution of intimate content could be criminalised, as it has been done in the Philippines.
Provisions that have to do with data retention and government access to that data for the purposes of national security, law enforcement and also anonymised datasets for the public interest should be in the upcoming Data Protection law. The rules for intermediary liability is not the correct place to deal with it, because data retention may also be required of those intermediaries that don’t handle any third-party information or user generated content. Finally, there have to be clear procedures in place for reinstatement of content that has been taken down.
Disclosure: The Centre for Internet and Society receives grants from Facebook, Google and Wikimedia Foundation
Data Infrastructures and Inequities: Why Does Reproductive Health Surveillance in India Need Our Urgent Attention?
The article was first published by EPW Engage, Vol. 54, Issue No. 6, on 9 February 2019.
Framing Reproductive Health as a Surveillance Question
The approach of the postcolonial Indian state to healthcare has been Malthusian, with the prioritisation of family planning and birth control (Hodges 2004). Supported by the notion of socio-economic development arising out of a “modernisation” paradigm, the target-based approach to achieving reduced fertility rates has shaped India’s reproductive and child health (RCH) programme (Simon-Kumar 2006).
This is also the context in which India’s abortion law, the Medical Termination of Pregnancy (MTP) Act, was framed in 1971, placing the decisional privacy of women seeking abortions in the hands of registered medical practitioners. The framing of the MTP act invisibilises females seeking abortions for non-medical reasons within the legal framework. The exclusionary provisions only exacerbated existing gaps in health provisioning, as access to safe and legal abortions had already been curtailed by severe geographic inequalities in funding, infrastructure, and human resources. The state has concomitantly been unable to meet contraceptive needs of married couples or reduce maternal and infant mortality rates in large parts of the country, mediating access along the lines of class, social status, education, and age (Sanneving et al 2013).
While the official narrative around the RCH programme transitioned to focus on universal access to healthcare in the 1990s, the target-based approach continues to shape the reality on the ground. The provision of reproductive healthcare has been deeply unequal and, in some cases, in hospitals. These targets have been known to be met through the practice of forced, and often unsafe, sterilisation, in conditions of absence of adequate provisions or trained professionals, pre-sterilisation counselling, or alternative forms of contraception (Sama and PLD 2018). Further, patients have regularly been provided cash incentives, foreclosing the notion of free consent, especially given that the target population of these camps has been women from marginalised economic classes in rural India.
Placing surveillance studies within a feminist praxis allows us to frame the reproductive health landscape as more than just an ill-conceived, benign monitoring structure. The critical lens becomes useful for highlighting that taken-for-granted structures of monitoring are wedded with power differentials: genetic screening in fertility clinics, identification documents such as birth certificates, and full-body screeners are just some of the manifestations of this (Adrejevic 2015). Emerging conversations around feminist surveillance studies highlight that these data systems are neither benign nor free of gendered implications (Andrejevic 2015). In continual remaking of the social, corporeal body as a data actor in society, such practices render some bodies normative and obfuscate others, based on categorisations put in place by the surveiller.
In fact, the history of surveillance can be traced back to the colonial state where it took the form of systematic sexual and gendered violence enacted upon indigenous populations in order to render them compliant (Rifkin 2011; Morgensen 2011). Surveillance, then, manifests as a “scientific” rationalisation of complex social hieroglyphs (such as reproductive health) into formats enabling administrative interventions by the modern state. Lyon (2001) has also emphasised how the body emerged as the site of surveillance in order for the disciplining of the “irrational, sensual body”—essential to the functioning of the modern nation-state—to effectively happen.
Questioning the Information and Communications Technology for Development (ICT4D) and Big Data for Development (BD4D) Rhetoric
Information and Communications Technology (ICT) and data-driven approaches to the development of a robust health information system, and by extension, welfare, have been offered as solutions to these inequities and exclusions in access to maternal and reproductive healthcare in the country.
The move towards data-driven development in the country commenced with the introduction of the Health Management Information System in Andhra Pradesh in 2008, and the Mother and Child Tracking System (MCTS) nationally in 2011. These are reproductive health information systems (HIS) that collect granular data about each pregnancy from the antenatal to the post-natal period, at the level of each sub-centre as well as primary and community health centre. The introduction of HIS comprised cross-sectoral digitisation measures that were a part of the larger national push towards e-governance; along with health, thirty other distinct areas of governance, from land records to banking to employment, were identified for this move towards the digitalised provisioning of services (MeitY 2015).
The HIS have been seen as playing a critical role in the ecosystem of health service provision globally. HIS-based interventions in reproductive health programming have been envisioned as a means of: (i) improving access to services in the context of a healthcare system ridden with inequalities; (ii) improving the quality of services provided, and (iii) producing better quality data to facilitate the objectives of India’s RCH programme, including family planning and population control. Accordingly, starting 2018, the MCTS is being replaced by the RCH portal in a phased manner. The RCH portal, in areas where the ANMOL (ANM Online) application has been introduced, captures data real-time through tablets provided to health workers (MoHFW 2015).
A proposal to mandatorily link the Aadhaar with data on pregnancies and abortions through the MCTS/RCH has been made by the union minister for Women and Child Development as a deterrent to gender-biased sex selection (Tembhekar 2016). The proposal stems from the prohibition of gender-biased sex selection provided under the Pre-Conception and Pre-Natal Diagnostics Techniques (PCPNDT) Act, 1994. The approach taken so far under the PCPNDT Act, 2014 has been to regulate the use of technologies involved in sex determination. However, the steady decline in the national sex ratio since the passage of the PCPNDT Act provides a clear indication that the regulation of such technology has been largely ineffective. A national policy linking Aadhaar with abortions would be aimed at discouraging gender-biased sex selection through state surveillance, in direct violation of a female’s right to decisional privacy with regards to their own body.
Linking Aadhaar would also be used as a mechanism to enable direct benefit transfer (DBT) to the beneficiaries of the national maternal benefits scheme. Linking reproductive health services to the Aadhaar ecosystem has been critiqued because it is exclusionary towards women with legitimate claims towards abortions and other reproductive services and benefits, and it heightens the risk of data breaches in a cultural fabric that already stigmatises abortions. The bodies on which this stigma is disproportionately placed, unmarried or disabled females, for instance, experience the harms of visibility through centralised surveillance mechanisms more acutely than others by being penalised for their deviance from cultural expectations. This is in accordance with the theory of "data extremes,” wherein marginalised communities are seen as living on the extremes of data capture, leading to a data regime that either refuses to recognise them as legitimate entities or subjects them to overpolicing in order to discipline deviance (Arora 2016). In both developed and developing contexts, the broader purpose of identity management has largely been to demarcate legitimate and illegitimate actors within a population, either within the framework of security or welfare.
Potential Harms of the Data Model of Reproductive Health Provisioning
Informational privacy and decisional privacy are critically shaped by data flows and security within the MCTS/RCH. No standards for data sharing and storage, or anonymisation and encryption of data have been implemented despite role-based authentication (NHSRC and Taurus Glocal 2011). The risks of this architectural design are further amplified in the context of the RCH/ANMOL where data is captured real-time. In the absence of adequate safeguards against data leaks, real-time data capture risks the publicising of reproductive health choices in an already stigmatised environment. This opens up avenues for further dilution of autonomy in making future reproductive health choices.
Several core principles of informational privacy, such as limitations regarding data collection and usage, or informed consent, also need to be reworked within this context.[1] For instance, the centrality of the requirement of “free, informed consent” by an individual would need to be replaced by other models, especially in the context of reproductive health of rape survivors who are vulnerable and therefore unable to exercise full agency. The ability to make a free and informed choice, already dismantled in the context of contemporary data regimes, gets further precluded in such contexts. The constraints on privacy in decisions regarding the body are then replicated in the domain of reproductive data collection.
What is uniform across these digitisation initiatives is their treatment of maternal and reproductive health as solely a medical event, framed as a data scarcity problem. In doing so, they tend to amplify the understanding of reproductive health through measurable indicators that ignore social determinants of health. For instance, several studies conducted in the rural Indian context have shown that the degree of women’s autonomy influences the degree of usage of pregnancy care, and that the uptake of pregnancy care was associated with village-level indicators such as economic development, provisioning of basic infrastructure and social cohesion. These contextual factors get overridden in pervasive surveillance systems that treat reproductive healthcare as comprising only of measurable indicators and behaviours, that are dependent on individual behaviour of practitioners and women themselves, rather than structural gaps within the system.
While traditionally associated with state governance, the contemporary surveillance regime is experienced as distinct from its earlier forms due to its reliance on a nexus between surveillance by the state and private institutions and actors, with both legal frameworks and material apparatuses for data collection and sharing (Shepherd 2017). As with historical forms of surveillance, the harms of contemporary data regimes accrue disproportionately among already marginalised and dissenting communities and individuals. Data-driven surveillance has been critiqued for its excesses in multiple contexts globally, including in the domains of predictive policing, health management, and targeted advertising (Mason 2015). In the attempts to achieve these objectives, surveillance systems have been criticised for their reliance on replicating past patterns, reifying proximity to a hetero-patriarchal norm (Haggerty and Ericson 2000). Under data-driven surveillance systems, this proximity informs the preexisting boxes of identity for which algorithmic representations of the individual are formed. The boxes are defined contingent on the distinct objectives of the particular surveillance project, collating disparate pieces of data flows and resulting in the recasting of the singular offline self into various 'data doubles' (Haggerty and Ericson 2000). Refractive, rather than reflective, the data doubles have implications for the physical, embodied life of individual with an increasing number of service provisioning relying on the data doubles (Lyon 2001). Consider, for instance, apps on menstruation, fertility, and health, and wearables such as fitness trackers and pacers, that support corporate agendas around what a woman’s healthy body should look, be or behave like (Lupton 2014). Once viewed through the lens of power relations, the fetishised, apolitical notion of the data “revolution” gives way to what we may better understand as “dataveillance.”
Towards a Networked State and a Neo-liberal Citizen
Following in this tradition of ICT being treated as the solution to problems plaguing India’s public health information system, a larger, all-pervasive healthcare ecosystem is now being proposed by the Indian state (NITI Aayog 2018). Termed the National Health Stack, it seeks to create a centralised electronic repository of health records of Indian citizens with the aim of capturing every instance of healthcare service usage. Among other functions, it also envisions a platform for the provisioning of health and wellness-based services that may be dispensed by public or private actors in an attempt to achieve universal health coverage. By allowing private parties to utilise the data collected through pullable open application program interfaces (APIs), it also fits within the larger framework of the National Health Policy 2017 that envisions the private sector playing a significant role in the provision of healthcare in India. It also then fits within the state–private sector nexus that characterises dataveillance. This, in turn, follows broader trends towards market-driven solutions and private financing of health sector reform measures that have already had profound consequences on the political economy of healthcare worldwide (Joe et al 2018).
These initiatives are, in many ways, emblematic of the growing adoption of network governance reform by the Indian state (Newman 2001). This is a stark shift from its traditional posturing as the hegemonic sovereign nation state. This shift entails the delayering from large, hierarchical and unitary government systems to horizontally arranged, more flexible, relatively dispersed systems.[2] The former govern through the power of rules and law, while the latter take the shape of self-regulating networks such as public–private contractual arrangements (Snellen 2005). ICTs have been posited as an effective tool in enabling the transition to network governance by enhancing local governance and interactive policymaking enabling the co-production of knowledge (Ferlie et al 2011). The development of these capabilities is also critical to addressing “wicked problems” such as healthcare (Rittel and Webber 1973).[3] The application of the techno-deterministic, data-driven model to reproductive healthcare provision, then, resembles a fetishised approach to technological change. The NHSRC describes this as the collection of data without an objective, leading to a disproportional burden on data collection over use (NHSRC and Taurus Glocal 2011).
The blurring of the functions of state and private actors is reflective of the neo-liberal ethic, which produces new practices of governmentality. Within the neo-liberal framework of reproductive healthcare, the citizen is constructed as an individual actor, with agency over and responsibility for their own health and well-being (Maturo et al 2016).
“Quantified Self” of the Neo-liberal Citizen
Nowhere can the manifestation of this neo-liberal citizen can be seen as clearly as in the “quantified self” movement. The quantified self movement refers to the emergence of a whole range of apps that enable the user to track bodily functions and record data to achieve wellness and health goals, including menstruation, fertility, pregnancies, and health indicators in the mother and baby. Lupton (2015) labels this as the emergence of the “digitised reproductive citizen,” who is expected to be attentive to her fertility and sexual behaviour to achieve better reproductive health goals. The practice of collecting data around reproductive health is not new to the individual or the state, as has been demonstrated by the discussion above. What is new in this regime of datafication under the self-tracking movement is the monetisation of reproductive health data by private actors, the labour for which is performed by the user. Focusing on embodiment draws attention to different kinds of exploitation engendered by reproductive health apps. Not only is data about the body collected and sold, the unpaid labour for collection is extracted from the user. The reproductive body can then be understood as a cyborg, or a woman-machine hybrid, systematically digitising its bodily functions for profit-making within the capitalist (re)production machine (Fotoloulou 2016). Accordingly, all major reproductive health tracking apps have a business model that relies on selling information about users for direct marketing of products around reproductive health and well-being (Felizi and Varon nd).
As has been pointed out in the case of big data more broadly, reproductive health applications (apps) facilitate the visibility of the female reproductive body in the public domain. Supplying anonymised data sets to medical researchers and universities fills some of the historical gaps in research around the female body and reproductive health. Reproductive and sexual health tracking apps globally provide their users a platform to engage with biomedical information around sexual and reproductive health. Through group chats on the platform, they are also able to engage with experiential knowledge of sexual and reproductive health. This could also help form transnational networks of solidarity around the body and health (Fotopoulou 2016).
This radical potential of network-building around reproductive and sexual health is, however, tempered to a large extent by the reconfiguration of gendered stereotypes through these apps. In a study on reproductive health apps on Google Play Store, Lupton (2014) finds that products targeted towards female users are marketed through the discourse of risk and vulnerability, while those targeted towards male users are framed within that of virility. Apart from reiterating gendered stereotypes around the male and female body, such a discourse assumes that the entire labour of family planning is performed by females. This same is the case with the MCTS/RCH.
Technological interventions such as reproductive health apps as well as HIS are based on the assumption that females have perfect control over decisions regarding their own bodies and reproductive health, despite this being disproved in India. The Guttmacher Institute (2014) has found that 60% of women in India report not having control over decisions regarding their own healthcare. The failure to account for the husband or the family as stakeholder in decision-making around reproductive health has been a historical failure of the family planning programme in India, and is now being replicated in other modalities. This notion of an autonomous citizen who is able to take responsibility of their own reproductive health and well-being does not hold true in the Indian context. It can even be seen as marginalising females who have already been excluded from the reproductive health system, as they are held responsible for their own inability to access healthcare.
Concluding Remarks
The interplay that emerges between reproductive health surveillance and data infrastructures is a complex one. It requires the careful positioning of the political nature of data collection and processing as well as its hetero-patriarchal and colonial legacies, within the need for effective utilisation of data for achieving developmental goals. Assessing this discourse through a feminist lens identifies the web of power relations in data regimes. This problematises narratives of technological solutions for welfare provision.
The reproductive healthcare framework in India then offers up a useful case study to assess these concerns. The growing adoption of ICT-based surveillance tools to equalise access to healthcare needs to be understood in the socio-economic, legal, and cultural context where these tools are being implemented. Increased surveillance has historically been associated with causing the structural gendered violence that it is now being offered as a solution to. This is a function of normative standards being constructed for reproductive behaviour that necessarily leave out broader definitions of reproductive health and welfare when viewed through a feminist lens. Within the larger context of health policymaking in India, moves towards privatisation then demonstrate the peculiarity of dataveillance as it functions through an unaccountable and pervasive overlapping of state and private surveillance practises. It remains to be seen how these trends in ICT-driven health policies affect access to reproductive rights and decisional privacy for millions of females in India and other parts of the global South.
CIS Submission to UN High Level Panel on Digital Co-operation
Download the submission here
CIS Submission to the UN Special Rapporteur on Freedom of Speech and Expression: Surveillance Industry and Human Rights
CIS is grateful for the opportunity to submit the United Nations (UN) Special Rapporteur on call for submissions on the surveillance industry and human rights.1 Over the last decade, CIS has worked extensively on research around state and private surveillance around the world. In this response, individuals working at CIS wish to highlight these programs, with a special focus on India.
The response can be accessed here.
Resurrecting the marketplace of ideas
The article by Arindrajit Basu was published in Hindu Businessline on February 19, 2019.
A century after the ‘marketplace of ideas’ first found its way into a US Supreme Court judgment through the dissenting opinion of Justice Oliver Wendell Holmes Jr (Abrams v United States, 1919), the oft-cited rationale for free speech is arguably under siege.
The increasing quantity and range of online speech hosted by internet platforms coupled with the shock waves sent by revelations of rampant abuse through the spread of misinformation has lead to a growing inclination among governments across the globe to demand more aggressive intervention by internet platforms in filtering the content they host.
Rule 3(9) of the Draft of the Information Technology [Intermediary Guidelines (Amendment) Rules] 2018 released by the Ministry of Electronics and Information Technology (MeiTy) last December follows the interventionist regulatory footsteps of countries like Germany and France by mandating that platforms use “automated tools or appropriate mechanisms, with appropriate controls, for proactively identifying and removing or disabling public access to unlawful information or content.”
Like its global counterparts, this rule, which serves as a pre-condition for granting immunity to the intermediary from legal claims arising out of user-generated communications, might not only have an undue ‘chilling effect’ on free speech but is also a thoroughly uncooked policy intervention.
Censorship by proxy
Rule 3(9) and its global counterparts might not be in line with the guarantees enmeshed in the right to freedom of speech and expression for three reasons. First, the vague wording of the law and the abstruse guidelines for implementation do not provide clarity, accessibility and predictability — which are key requirements for any law restricting free speech .The NetzDG-the German law, aimed at combating agitation and fake news, has attracted immense criticism from civil society activists and the UN Special Rapporteur David Kaye on similar grounds.
Second, as proved by multiple empirical studies across the globe, including one conducted by CIS on the Indian context, it is likely that legal requirements mandating that private sector actors make determinations on content restrictions can lead to over-compliance as the intermediary would be incentivised to err on the side of removal to avoid expensive litigation.
Finally, by shifting the burden of determining and removing ‘unlawful’ content onto a private actor, the state is effectively engaging in ‘censorship by proxy’. As per Article 12 of the Constitution, whenever a government body performs a ‘public function’, it must comply with all the enshrined fundamental rights.
Any individual has the right to file a writ petition against the state for violation of a fundamental right, including the right to free speech.
However, judicial precedent on the horizontal application of fundamental rights, which might enable an individual to enforce a similar claim against a private actor has not yet been cemented in Indian constitutional jurisprudence.
This means that any individual whose content has been wrongfully removed by the platform may have no recourse in law — either against the state or against the platform.
Algorithmic governmentality
Using automated technologies comes with its own set of technical challenges even though they enable the monitoring of greater swathes of content. The main challenge to automated filtering is the incomplete or inaccurate training data as labelled data sets are expensive to curate and difficult to acquire, particularly for smaller players.
Further, an algorithmically driven solution is an amorphous process.
Through it is hidden layers and without clear oversight and accountability mechanisms, the machine generates an output, which corresponds to assessing the risk value of certain forms of speech, thereby reducing it to quantifiable values — sacrificing inherent facets of dignity such as the speaker’s unique singularities, personal psychological motivations and intentions.
Possible policy prescriptions
The first step towards framing an adequate policy response would be to segregate the content needing moderation based on the reason for them being problematic.
Detecting and removing information that is false might require the crafting of mechanisms that are different from those intended to tackle content that is true but unlawful, such as child pornography.
Any policy prescription needs to be adequately piloted and tested before implementation. It is also likely that the best placed prescription might be a hybrid amalgamation of the methods outlined below.
Second, it is imperative that the nature of intermediaries to which a policy applies are clearly delineated. For example, Whatsapp, which offers end-to-end encrypted services would not be able to filter content in the same way internet platforms like Twitter can.
The first option going forward is user-filtering, which as per a recent paper written by Ivar Hartmann, is a decentralised process, through which the users of an online platform collectively endeavour to regulate the flow of information.
Users collectively agree on a set of standards and general guidelines for filtering. This method combined with an oversight and grievance redressal mechanism to address any potential violation may be a plausible one.
The second model is enhancing the present model of self-regulation. Ghonim and Rashbass recommend that the platform must publish all data related to public posts and the processes followed in a certain post attaining ‘viral’ or ‘trending’ status or conversely, being removed.
This, combined with Application Programme Interfaces (APIs) or ‘Public Interest Algorithms’, which enables the user to keep track of the data-driven process that results in them being exposed to a certain post, might be workable if effective pilots for scaling are devised.
The final model that operates outside the confines of technology are community driven social mechanisms. An example of this is Telengana Police Officer Remi Rajeswari’s efforts to combat fake news in rural areas by using Janapedam — an ancient form of story-telling — to raise awareness about these issues.
Given the complex nature of the legal, social and political questions involved here, the quest for a ‘silver-bullet’ might be counter-productive.
Instead, it is essential for us to take a step back, frame the right questions to understand the intricacies in the problems involved and then, through a mix of empirical and legal analysis, calibrate a set of policy interventions that may work for India today.
Comments on the Draft Second Protocol to the Convention on Cybercrime (Budapest Convention)
The Centre for Internet and Society, (“CIS”), is a non-profit organisation that undertakes interdisciplinary research on internet and digital technologies from policy and academic perspectives. The areas of focus include digital accessibility for persons with diverse abilities, access to knowledge, intellectual property rights, openness (including open data, free and open source software, open standards, and open access), internet governance, telecommunication reform, digital privacy, artificial intelligence, freedom of expression, and cyber-security. This submission is consistent with CIS’ commitment to safeguarding general public interest, and the rights of stakeholders. CIS is thankful to the Cybercrime Convention Committee for this opportunity to provide feedback to the Draft.
The draft text addresses three issues viz. language of requests, emergency multilateral cooperation and taking statements through video conferencing. Click to download the entire submission here.
Unbox Festival 2019: CIS organizes two Workshops
'What is your Feminist Infrastructure Wishlist?
The first workshop 'What is your Feminist Infrastructure Wishlist?' was on Feminist Infrastructure Wishlists that was conducted by P.P. Sneha and Saumyaa Naidu on 15 February 2019. The objective of the workshop was to explore what it means to have infrastructure that is feminist. How do we build spaces, networks, and systems that are equal, inclusive, diverse, and accessible? We will also reflect on questions of network configurations, expertise, labour and visibility. For reading material click here.
AI for Good
With a backdrop of AI for social good, we explore existing applications of artificial intelligence, how we interact and engage with this technology on a daily basis. A discussion led by Saumyaa Naidu and Shweta Mohandas invited participants to examine current narratives around AI and imagine how these may transform with time. Questions around how we can build an AI for the future will become the starting point to trace its implications relating to social impact, policy, gender, design, and privacy. For reading materials see AI Now Report 2018, Machine Bias, and Why Do So Many Digital Assistants Have Feminine Names?
For info on Unbox Festival, click here
The Localisation Gambit: Unpacking policy moves for the sovereign control of data in India
The full paper can be accessed here.
Executive Summary
The vision of a borderless internet that functions as an open distributed network is slowly ceding ground to a space that is greatly political, and at risk of fragmentation due to cultural, economic, and geo-political differences. A variety of measures for asserting sovereign control over data within national territories is a manifestation of this trend. Over the past year, the Indian government has drafted and introduced multiple policy instruments which dictate that certain types of data must be stored in servers located physically within the territory of India. These localization gambits have triggered virulent debate among corporations, civil society actors, foreign stakeholders, business guilds, politicians, and governments. This White Paper seeks to serve as a resource for stakeholders attempting to intervene in this debate and arrive at a workable solution where the objectives of data localisation are met through measures that have the least negative impact on India’s economic, political, and legal interests. We begin this paper by studying the pro-localisation policies in India. We have defined data localisation as 'any legal limitation on the ability for data to move globally and remain locally.' These policies can take a variety of forms. This could include a specific requirement to locally store copies of data, local content production requirements, or imposing conditions on cross border data transfers that in effect act as a localization mandate.Presently, India has four sectoral policies that deal with localization requirements based on type of data, for sectors including banking, telecom, and health - these include the RBI Notification on ‘Storage of Payment System Data’, the FDI Policy 2017, the Unified Access License, and the Companies Act, 2013 and its Rules, The IRDAI (Outsourcing of Activities by Indian Insurers) Regulations, 2017, and the National M2M Roadmap.
At the same time, 2017 and 2018 has seen three separate proposals for comprehensive and sectoral localization requirements based on type of data across sectors including the draft Personal Data Protection Bill 2018, draft e-commerce policy, and the draft e-pharmacy regulations. The policies discussed reflect objectives such as enabling innovation, improving cyber security and privacy, enhancing national security, and protecting against foreign surveillance. The subsequent section reflects on the objectives of such policy measures, and the challenges and implications for individual rights, markets, and international relations. We then go on to discuss the impacts of these policies on India’s global and regional trade agreements. We look at the General Agreement on Trade in Services (GATS) and its implications for digital trade and point out the significance of localisation as a point of concern in bilateral trade negotiations with the US and the EU. We then analyse the responses of fifty-two stakeholders on India’s data localisation provisions using publicly available statements and submissions. Most civil society groups - both in India and abroad are ostensibly against blanket data localisation, the form which is mandated by the Srikrishna Bill. Foreign stakeholders including companies such as Google and Facebook, politicians including US Senators, and transnational advocacy groups such as the US-India Strategic Partnership Forum, were against localisation citing it as a grave trade restriction and an impediment to a global digital economy which relies on the cross-border flow of data. The stance taken by companies such as Google and Facebook comes as no surprise, since they would likely incur huge costs in setting up data centres in India if the localisation mandate was implemented.
Stakeholders arguing for data localisation included politicians and some academic and civil society voices that view this measure as a remedy for ‘data colonialism’ by western companies and governments. Large Indian corporations, such as Reliance, that have the capacity to build their own data centres or pay for their consumer data to be stored on data servers support this measure citing the importance of ‘information sovereignty.’ However, industry associations such as NASSCOM and Internet and Mobile Association of Indian (IAMAI) are against the mandate citing a negative impact on start-ups that may not have the financial capacity to fulfil the compliance costs required. Leading private players in the digital economy, such as Phone Pe and Paytm support the mandate on locally storing payments data as they believe it might improve the condition of financial security services. As noted earlier, various countries have begun to implement restrictions on the cross-border flow of data. We studied 18 countries that have such mandates and found that models can differ on the basis of the strength and type of mandate, as well as the type of data to which the restriction applies, and sectors to which the mandate extends to. These models can be used by india to think think through potential means of pushing through a localisation mandate. Our research suggests that the various proposed data localization measures, serve the primary objective of ensuring sovereign control over Indian data. Various stakeholders have argued that data localisation is a way of asserting Indian sovereignty over citizens’ data and that the data generated by Indian individuals must be owned by Indian corporations. It has been argued that Indian citizens’ data must be governed my Indian laws, security standards and protocols.
However, given the complexity of technology, the interconnectedness of global data flows, and the potential economic and political implications of localization requirements - approaches to data sovereignty and localization should be nuanced. In this section we seek to posit the building blocks which can propel research around these crucial issues. We have organized these questions into the broader headings of prerequisites, considerations, and approaches:
PRE-REQUISITES
From our research, we find that any thinking on data localisation requirements must be preceded with the following prerequisites, in order to protect fundamental rights, and promote innovation.
-
Is the national, legal infrastructure and security safeguards adequate to support localization requirements?
-
Are human rights, including privacy and freedom of expression online and offline, adequately protected and upheld in practice?
-
Do domestic surveillance regimes have adequate safeguards and checks and balances?
-
Does the private and public sector adhere to robust privacy and security standards and what should be the measure to ensure protection of data?
CONSIDERATIONS
-
What are the objectives of localization?
-
Innovation and Local ecosystem
-
The Srikrishna Committee Report specifically refers to the value in developing an indigenous Artificial Intelligence ecosystem. Much like the other AI strategies produced by the NITI Aayog and the Task Force set up by the Commerce Department, it states that AI can be a key driver in all areas of economic growth, and cites developments in China and the USA as instances of reference.
-
National Security, Law Enforcement and Protection from Foreign Surveillance
-
As recognised by the Srikrishna White Paper, a disproportionate amount of data belonging to Indian citizens is stored in the United States, and the presently existing Mutual Legal Assistance Treaties process (MLATs) through which Indian law enforcement authorities gain access to data stored in the US is excessively slow and cumbersome.
-
The Srikrishna Committee report also states that undersea cable networks that transmit data from one country to another are vulnerable to attack.
-
The report suggests that localisation might help protect Indian citizens against foreign surveillance.
-
What are the potential spill-overs and risks of a localisation mandate?
-
Diplomatic and political: Localisation could impact India’s trade relationships with its partners.
-
Security risks (“Regulatory stretching of the attack surface”): Storing data in multiple physical centres naturally increases the physical exposure to exploitation by individuals physically obtaining data or accessing the data remotely. So, the infrastructure needs to be backed up with robust security safeguards and significant costs to that effect.
-
Economic impact: Restrictions on cross-border data flow may harm overall economic growth by increasing compliance costs and entry barriers for foreign service providers and thereby reducing investment or passing on these costs to the consumers. The major compliance issue is the significant cost of setting up a data centre in India combined with the unsuitability of weather conditions. Further, for start-ups looking to attain global stature, reciprocal restrictions slapped by other countries may prevent access to the data in several other jurisdictions.
-
What are the existing alternatives to attain the same objectives?
The objective and potential alternatives are listed below:
|
OBJECTIVE |
ALTERNATE |
|
Law enforcement access to data |
Pursuing international consensus through negotiations rooted in international law |
|
Widening tax base by taxing entities that do not have an economic presence in India |
Equalisation levy/Taxing entities with a Significant Economic Presence in India (although an enforcement mechanism still needs to be considered). |
|
Threat to fibre-optic cables |
Building of strong defense alliances with partners to protect key choke points from adversaries and threats |
|
Boost to US based advertisement revenue driven companies like Facebook and Google (‘data colonisation’) |
Developing robust standards and paradigms of enforcement for competition law |
APPROACH
-
What data might be beneficial to store locally for ensuring national interest? What data could be mandated to stay within the borders of the country? What are the various models that can be adopted?
-
Mandatory Sectoral Localisation: Instead of imposing a generalized mandate, it may be more useful to first identify sectors or categories of data that may benefit most from local storage.
b. ‘Conditional (‘Soft’) Localisation: For all data not covered within the localisation mandate, India should look to develop conditional prerequisites for transfer of all kinds of data to any jurisdiction, like the Latin American countries, or the EU. This could be conditional on two key factors:
- Equivalent privacy and security safeguards: Transfers should only be allowed to countries which uphold the same standards. In order to do this, India must first develop and incorporate robust privacy and security protections.
-
Agreement to share data with law enforcement officials when needed: India should allow cross-border transfer only to countries that agree toshare data with Indian authorities based on standards set by Indian law.
Improving the Processes for Disclosing Security Vulnerabilities to Government Entities in India
The ubiquitous adoption and integration of information and communication technologies in almost all aspects of modern life raises with it the importance of being able to ensure the security and integrity of the systems and resources that we rely on. This importance is even more pressing for the Government, which is increasing its push of efforts towards digitising the operational infrastructure it relies on, both at the State as well as the Central level.
This policy brief draws from knowledge that has been gathered from various sources, including information sourced from newspaper and journal articles, current law and policy, as well as from interviews that we conducted with various members of the Indian security community. This policy brief touches upon the issue of vulnerability disclosures, specifically those that are made by individuals to the Government, while exploring prevalent challenges with the same and making recommendations as to how the Government’s vulnerability disclosure processes could potentially be improved.
Key learnings from the research include:
-
There is a noticeable shortcoming in the availability of information with regard to current vulnerability disclosure programmes and process of Indian Government entities, which is only exacerbated further by a lack of transparency;
-
There is an observable gap in the amount and quality of interaction between security researchers and the Government, which is supported by the lack of proper channels for mediating such communication and cooperation;
-
There are several sections and provisions within the Information Technology Act, 2000, which have the potential to disincentivise legitimate security research, even if the same has been carried out in good faith.
CIS Response to Draft E-Commerce Policy
Access our response to the draft policy here: Download (PDF)
The E-Commerce Policy is a much needed and timely document that seeks to enable the growth of India's digital ecosystem. Crucially, it backs up India's stance at the WTO, which has been a robust pushback against digital trade policies that would benefit the developed world at the cost of emerging economies. However, in order to ensure that the benefits of the digital economy are truly shared, focus must not only be on the sellers but also on the consumers, which automatically brings in individual rights into the question. No right is absolute but there needs to be a fair trade-off between the mercantilist aspirations of a burgeoning digital economy and the civil and political rights of the individuals who are spurring the economy on. We also appreciate the recognition that the regulation of e-commerce must be an inter-disciplinary effort and the assertion of the roles of various other departments and ministries. However, we also caution against over-reach and encroaching into policy domains that fall within the mandate of existing laws.
DIDP #33 On ICANN's 2012 gTLD round auction fund
In 2012, after years of deliberation ICANN opened the application round for new top level domains and saw over 1930 applications. Since October 2013, delegation of these extensions commenced with it still going on. However, 7 years since the round was open there has been no consensus on how to utilize the funds obtained from the auctions. ICANN until its last meeting was debating on the legal mechanisms/ entities to be created who will decide on the disbursement of these funds. There is no clear information on how those funds have been maintained over the years or its treatments in terms of whether they have been set aside or invested etc. Thus, our DIDP questions ICANN on the status of these funds and can be found here.
The response to the DIDP received on 24th April, 2019 states that that even though the request asked for information, rather than documentation, our question was answered. Reiterating that the DIDP mechanism was developed to provide documentation rather than information. It stated that on 25 October 2018, Resolution 2018.10.25.23 was passed that compels the President and CEO to allocate $36 million to the Reserve Fund. The gTLD auction proceeds were allocated to separate investment accounts, and the interest accruing from the proceedings was in accordance with the new gTLD Investment Policy.
CIS Response to Call for Stakeholder Comments: Draft E-Commerce Policy
The Department of Industrial Policy and Promotion released a draft e-commerce policy in February for which stakeholder comments were sought. CIS responded to the request for comments.
The full text can be accessed here.
To preserve freedoms online, amend the IT Act
In the absence of transparency, we have to rely on a mix of user reports and media reports that carry leaked government documents to get a glimpse into what websites the government is blocking(Getty Images)
The article by Gurshabad Grover was published in the Hindustan Times on April 16, 2019.
The issue of blocking of websites and online services in India has gained much deserved traction after internet users reported that popular services like Reddit and Telegram were inaccessible on certain Internet Service Providers (ISPs). The befuddlement of users calls for a look into the mechanisms that allow the government and ISPs to carry out online censorship without accountability.
Among other things, Section 69A of the Information Technology (IT) Act, which regulates takedown and blocking of online content, allows both government departments and courts to issue directions to ISPs to block websites. Since court orders are in the public domain, it is possible to know this set of blocked websites and URLs. However, the process is much more opaque when it comes to government orders.
The Information Technology (Procedure and Safeguards for Blocking for Access of Information by Public) Rules, 2009, issued under the Act, detail a process entirely driven through decisions made by executive-appointed officers. Although some scrutiny of such orders is required normally, it can be waived in cases of emergencies. The process does not require judicial sanction, and does not present an opportunity of a fair hearing to the website owner. Notably, the rules also mandate ISPs to maintain all such government requests as confidential, thus making the process and complete list of blocked websites unavailable to the general public.
In the absence of transparency, we have to rely on a mix of user reports and media reports that carry leaked government documents to get a glimpse into what websites the government is blocking. Civil society efforts to get the entire list of blocked websites have repeatedly failed. In response to the Right to Information (RTI) request filed by the Software Freedom Law Centre India in August 2017, the Ministry of Electronics and IT refused to provide the entire of list of blocked websites citing national security and public order, but only revealed the number of blocked websites: 11,422.
Unsurprisingly, ISPs do not share this information because of the confidentiality provision in the rules. A 2017 study by the Centre for Internet and Society (CIS) found all five ISPs surveyed refused to share information about website blocking requests. In July 2018, the Bharat Sanchar Nagam Limited rejected the RTI request by CIS which asked for the list of blocked websites.
The lack of transparency, clear guidelines, and a monitoring mechanism means that there are various forms of arbitrary behaviour by ISPs. First and most importantly, there is no way to ascertain whether a website block has legal backing through a government order because of the aforementioned confidentiality clause. Second, the rules define no technical method for the ISPs to follow to block the website. This results in some ISPs suppressing Domain Name System queries (which translate human-parseable addresses like ‘example.com’ to their network address, ‘93.184.216.34’), or using the Hypertext Transfer Protocol (HTTP) headers to block requests. Third, as has been made clear with recent user reports, users in different regions and telecom circles, but serviced by the same ISP, may be facing a different list of blocked websites. Fourth, when blocking orders are rescinded, there is no way to make sure that ISPs have unblocked the websites. These factors mean that two Indians can have wildly different experiences with online censorship.
Organisations like the Internet Freedom Foundation have also been pointing out how, if ISPs block websites in a non-transparent way (for example, when there is no information page mentioning a government order presented to users when they attempt to access a blocked website), it constitutes a violation of the net neutrality rules that ISPs are bound to since July 2018.
While the Supreme Court upheld the legality of the rules in 2015 in Shreya Singhal vs. Union of India, recent events highlight how the opaque processes can have arbitrary and unfair outcomes for users and website owners. The right to access to information and freedom of expression are essential to a liberal democratic order. To preserve these freedoms online, there is a need to amend the rules under the IT Act to replace the current regime with a transparent and fair process that makes the government accountable for its decisions that aim to censor speech on the internet.
CIS Response to ICANN's proposed renewal of .org Registry
Presumption of Renewal
CIS has, in the past, questioned the need for a presumption of renewal in registry contracts and it is important to emphasize this within the context of this comment as well. We had, also, asked ICANN for their rationale on having such a practice with reference to their contract with Verisign to which they responded saying:
“Absent countervailing reasons, there is little public benefit, and some significant potential for disruption, in regular changes of a registry operator. In addition, a significant chance of losing the right to operate the registry after a short period creates adverse incentives to favor short term gain over long term investment.”
This logic can presumably be applied to the .org registry, as well, yet a re-auction of ,even, legacy top-level domains can only serve to further a fair market, promote competition and ensure that existing registries do not become complacent.
These views were supported in the course of the PDP on Contractual Conditions - Existing Registries in 2006 wherein competition was seen useful for better pricing, operational performance and contributions to registry infrastructure. It was also noted that most service industries incorporate a presumption of competition as opposed to one of renewal.
Download the file to access our full response.
International Cooperation in Cybercrime: The Budapest Convention
Click to download the file here
However, the global nature of the internet challenges traditional methods of law enforcement by forcing states to cooperate with each other for a greater variety and number of cases than ever before in the past. The challenges associated with accessing data across borders in order to be able to fully investigate crimes which may otherwise have no international connection forces states to think of easier and more efficient ways of international cooperation in criminal investigations. One such mechanism for international cooperation is the Convention on Cybercrime adopted in Budapest (“Budapest Convention”). Drafted by the Council of Europe along with Canada, Japan, South Africa and the United States of America it is the first and one of the most important multilateral treaties addressing the issue of cybercrime and international cooperation.[1]
Extradition
Article 24 of the Budapest Convention deals with the issue of extradition of individuals for offences specified in Articles 2 to 11 of the Convention. Since the Convention allows Parties to prescribe different penalties for the contraventions contained in Articles 2-11, it specifies that extradition cannot be asked for unless the crime committed by the individual carries a maximum punishment of deprivation of liberty for atleast one year.[2] In order to not complicate issues for Parties which may already have extradition treaties in place, the Convention clearly mentions that in cases where such treaties exist, extradition will be subject to the conditions provided for in such extradition treaties.[3] Although extradition is also subject to the laws of the requested Party, if the laws provide for the existence of an extradition treaty, such a requirement shall be deemed to be satisfied by considering the Convention as the legal basis for the extradition.[4] The Convention also specifies that the offences mentioned in Articles 2 to 11 shall be deemed to be included in existing extradition treaties and Parties shall include them in future extradition treaties to be executed.[5]
The Convention also recognises the principle of "aut dedere aut judicare" (extradite or prosecute) and provides that if a Party refuses to extradite an offender solely on the basis that it shall not extradite their own citizens,[6] then, if so requested, such Party shall prosecute the offender for the offences alleged in the same manner as if the person had committed a similar offence in the requested Party itself.[7] The Convention also requires the Secretary General of the Council of Europe to maintain an updated register containing the authorities designated by each of the Parties for making or receiving requests for extradition or provisional arrest in the absence of a treaty.[8]
Mutual Assistance Requests
The Convention imposes an obligation upon the Parties to provide mutual assistance “to the widest extent possible” for investigations or proceedings of criminal offences related to computer systems and data.[9] Just as in the case of extradition, the mutual assistance to be provided is also subject to the conditions prescribed by the domestic law of the Parties as well as mutual assistance treaties between the Parties.[10] However, it is in cases where no mutual assistance treaties exist between the Parties that the Convention tries to fill the lacuna and provide for a mechanism for mutual assistance.
The Convention requires each Party to designate an authority for the purpose of sending and answering mutual assistance requests from other Parties as well as transmitting the same to the relevant authority in their home country. Similar to the case of authorities for extradition, the Secretary General is required to maintain an updated register of the central authorities designated by each Party.[11] Recognising the fact that admissibility of the evidence obtained through mutual assistance in the domestic courts of the requesting Party is a major concern, the Convention provides that the mutual assistance requests are to be executed in accordance with the procedures prescribed by the requesting Party unless such procedures are incompatible with the laws of the requested Party.[12]
Parties are allowed to refuse a request for mutual assistance on the grounds that (i) the domestic laws of the requested party do not allow it to carry out the request;[13] (ii) the request concerns an offence considered as a political offence by the requested Party;[14] or (iii) in the opinion of the requested Party such a request is likely to prejudice its sovereignty, security, ordre public or other essential interests.[15] The requested Party is also allowed to postpone any action on the request if it thinks that acting on the request would prejudice criminal investigations or proceedings by its own authorities.[16] In cases where assistance would be refused or postponed, the requested Party may consult with the other Party and consider whether partial or conditional assistance may be provided.[17]
In practice it has been found that though States refuse requests on a number of grounds,[18] some states even refuse cooperation in the event that the case is minor but requires an excessive burden on the requested state.[19] A case study of a true instance recounted below gives an idea of the effort and resources it may take for a requested state to carry out a mutual assistance request:
“In the beginning of 2005, a Norwegian citizen (let’s call him A.T.) attacked a bank in Oslo. He intended to steal money and he did so effectively. During his action, a police officer was killed. A.T. ran away and could not be found in Norway. Some days later, police found and searched his home and computer and discovered that A.T. was the owner of an email account from a provider in the United Kingdom. International co-operation was required from British authorities which asked the provider to put his email account under surveillance. One day, A.T. used his email account to send an email message. In the United Kingdom, police asked the ISP information about the IP address where the communication came from and it was found that it came from Spain.
British and Spanish authorities installed an alert system whose objective was to know, each time that A.T. used his email account, where he was. Thus, each time A.T. used his account, British police obtained the IP address of the computer in the origin of the communication and provided it immediately to Spanish police. Then, Spanish police asked the Spanish ISPs about the owner or user of the IP address. All the connexions were made from cybercafés in Madrid. Even proceeding to that area very quickly, during a long period of time it was not possible to arrive at those places before A.T. was gone.
Later, A.T. began to use his email account from a cybercafé in Malaga. This is a smaller town than Madrid and there it was possible to put all the cybercafés from a certain area permanently under physical surveillance. After some days of surveillance, British police announced that A.T. was online, using his email account, and provided the IP address. Very rapidly, the Spanish ISP informed Spanish police from the concrete location of the cybercafé what allowed the officers in the street to identify and arrest A.T. in place.
A.T. was extradited to Norway and prosecuted.”[20]
It is clear from the above that although the crime occurred in Norway, a lot of work was actually done by the authorities in the United Kingdom and Spain. In a serious case such as this where there was a bank robbery as well as a murder involved, the amount of effort expended by authorities from other states may be appropriate but it is unlikely that the authorities in Britain and Spain would have allocated such resources for a petty crime.
In sensitive cases where the requests have to be kept secret or confidential for any reason, the requesting Party has to specify that the request should be kept confidential except to the extent required to execute the request (such as disclosure in front of appropriate authorities to obtain the necessary permissions). In case confidentiality cannot be maintained the requested Party shall inform the requesting Party of this fact, which shall then take a decision regarding whether to withdraw the request or not.[21] On the other hand the requested Party may also make its supply of information conditional to it being kept confidential and that it not be used in proceedings or investigations other than those stated in the request.[22] If the requesting Party cannot comply with these conditions it shall inform the requested Party which will then decide whether to supply the information or not.[23]
In the normal course the Convention envisages requests being made and executed through the respective designated central authorities, however it also makes a provision, in urgent cases, for requests being made directly by the judicial authorities or even the Interpol.[24] Even in non urgent cases, if the authority of the requested Party is able to comply with the request without making use of coercive action, requests may be transmitted directly to the competent authority without the intervention of the central authority.[25]
The Convention clarifies that through these mutual assistance requests a Party may ask another to (i) either search, seize or disclose computer data within its territory,[26] (ii) provide real time collection of traffic data with specified communications in its territory;[27] and (iii) provide real time collection or recording of content data of specified communications.[28] The provision of mutual assistance specified above has to be in accordance with the domestic laws of the requested Party.
The procedure for sending mutual assistance requests under the Convention is usually the following:
- Preparation of a request for mutual assistance by the prosecutor or enforcement agency which is responsible for an investigation.
- Sending the request by the prosecutor or enforcement agency to the Central Authority for verification (and translation, if necessary).
- The Central Authority then submits the request either, (i) to the foreign central authority, or (ii) directly to the requested judicial authority.
The following procedure is then followed in the corresponding receiving Party:
- Receipt of the request by the Central Authority.
- Central Authority then examines the request against formal and legal requirements (and translates it, if necessary).
- Central Authority then transmits the request to the competent prosecutor or enforcement agency to obtain court order (if needed).
- Issuance of a court order (if needed).
- Prosecutor orders law enforcement (e.g. cybercrime unit) to obtain the requested data.
- Data obtained is examined against the MLA request, which may entail translation or
using a specialist in the language.
- The information is then transmitted to requesting State via MLA channels.[29]
In practice, the MLA process has generally been found to be inefficient and this inefficiency is even more pronounced with respect to electronic evidence. The general response times range from six months to two years and many requests (and consequently) investigations are often abandoned.[30] Further, the lack of awareness regarding procedure and applicable legislation of the requested State lead to formal requirements not being met. Requests are often incomplete or too broad; do not meet legal thresholds or the dual criminality requirement.[31]
Preservation Requests
The Budapest Convention recognises the fact that computer data is highly volatile and may be deleted, altered or moved, rendering it impossible to trace a crime to its perpetrator or destroying critical proof of guilt. The Convention therefore envisioned the concept of preservation orders which is a limited, provisional measure intended to take place much more rapidly than the execution of a traditional mutual assistance. Thus the Convention gives the Parties the legal ability to obtain the expeditious preservation of data stored in the territory of another (requested) Party, so that the data is not altered, removed or deleted during the time taken to prepare, transmit and execute a request for mutual assistance to obtain the data.
The Convention therefore provides that a Party may request another Party to obtain the expeditious preservation of specified computer data in respect of which such Party intends to submit a mutual assistance request. Once such a request is received the other Party has to take all appropriate measures to ensure compliance with such a request. The Convention also specifies that dual criminality is not a condition to comply with such requests for preservation of data since these are considered to be less intrusive than other measures such as seizure, etc.[32] However in cases where parties have a dual criminality requirement for providing mutual assistance they may refuse a preservation request on the ground that at the time of providing the data the dual criminality condition would not be met, although in regard to the offences covered under Articles 2 to 11 of the Convention, the requirement of dual criminality will be deemed to have been satisfied.[33] In addition to dual criminality a preservation request may also be refused on the grounds that (i) the offence alleged is a political offence; and (ii) execution of the request would likely to prejudice the sovereignty, security, ordre public or other essential interests of the requested Party.[34]
In case the requested Party feels that preservation will not ensure the future availability of the data or will otherwise prejudice the investigation, it shall promptly inform the requesting Party which shall then take a decision as to whether to ask for the preservation irrespective.[35] Preservation of the data pursuant to a request will be for a minimum period of 60 days and upon receipt of a mutual assistance request will continue to be preserved till a decision is taken on the mutual assistance request.[36] If the requested Party finds out in the course of executing the preservation request that the data has been transmitted through a third state or the requesting Party itself, it has a duty to inform the requesting Party of such facts as well as provide it with sufficient traffic data in order for it to be able to identify the service provider in the other state.[37]
Jurisdiction and Access to Stored Data
The problem of accessing data across international borders stems from the international law principle which provides that the authority to enforce (an action) on the territory of another State is permitted only if the latter provides consent for such behaviour. States that do not acquire such consent may therefore be acting contrary to the principle of non-intervention and may be in violation of the sovereignty of the other State.[38] The Convention specifies two situations in which a Party may access computer data stored in another Party’s jurisdiction; (i) when such data is publicly available; and (ii) when the Party has accessed such data located in another state through a computer system located in its own territory provided it has obtained the “lawful and voluntary consent of the person who has the lawful authority to disclose the data to the Party through that computer system”.[39] These are two fairly obvious situations where a state should be allowed to use the computer data without asking another state, infact if a state was required to take the permission of the state in the territory of which the data was physically located even in these situations, then it would likely delay a large number of regular investigations where the data would otherwise be available but could not be legally used unless the other country provided it under the terms of the Convention or some other legal instrument. At the time of drafting the Convention it appears that Parties could not agree upon any other situations where it would be universally acceptable for a state to unilaterally access data located in another state, however it must be noted that other situations for unilaterally accessing data are neither authorized, nor precluded.[40]
Since the language of the Budapest Convention stopped shy of addressing other situations law enforcement agencies had been engaged in unilateral access to data stored in other jurisdictions on an uncertain legal basis risking the privacy rights of individuals raising concerns regarding national sovereignty.[41] It was to address this problem that the Cybercrime Committee established the “ad-hoc sub-group of the T-CY on jurisdiction and transborder access to data and data flows” (the “Transborder Group”) in November 2011 which came out with a Guidance Note clarigying the legal position under Article 32.
The Guidance Note # 3 on Article 32 by the Cybercrime Committee specifies that Article 32(b) would not cover situations where the data is not stored in another Party or where it is uncertain where the data is located. A Party is also not allowed to use Article 32(b) to obtain disclosure of data that is stored domestically. Since the Convention neither authorizes nor precludes other situations, therefore if it is unknown or uncertain that data is stored in another Party, Parties may need to evaluate themselves the legitimacy of a search or other type of access in the light of domestic law, relevant international law principles or considerations of international relations.[42] The Budapest Convention does not require notification to the other Party but parties are free to notify the other Party if they deem it appropriate.[43] The “voluntary and lawful consent” of the person means that the consent must be obtained without force or deception. Giving consent in order to avoid or reduce criminal charges would also constitute lawful and voluntary consent. If cooperation in a criminal investigation requires explicit consent in a Party, this requirement would not be fulfilled by agreeing to the general terms and conditions of an online service, even if the terms and conditions indicate that data would be shared with criminal justice authorities.[44]
The person who is lawfully authorized to give consent is unlikely to include service providers with respect to their users’ data. This is because normally service providers would only be holders of the data, they would not own or control the data and therefore cannot give valid consent to share the data.[45] The Guidance Note also specifies that with respect to the location of the person providing access or consent, while the standard assumption is that the person would be physically located in the requesting Party however there may be other situations, “It is conceivable that the physical or legal person is located in the territory of the requesting law enforcement authority when agreeing to disclose or actually providing access, or only when agreeing to disclose but not when providing access, or the person is located in the country where the data is stored when agreeing to disclose and/or providing access. The person may also be physically located in a third country when agreeing to cooperate or when actually providing access. If the person is a legal person (such as a private sector entity), this person may be represented in the territory of the requesting law enforcement authority, the territory hosting the data or even a third country at the same time.” Parties are also required to take into account the fact that third Parties may object (and some even consider it a criminal offence) if a person physically located in their territory is directly approached by a foreign law enforcement authority to seek his or her cooperation.[46]
Production Order
A similar problem arises in case of Article 18 of the Convention which requires Parties to put in place procedural provisions to compel a person in their territory to provide specified stored computer data, or a service provider offering services in their territory to submit subscriber information.[47] It must be noted here, that the data in question must be already stored or existing data, which implies that this provision does not cover data that has not yet come into existence such as traffic data or content data related to future communications.[48] Since the term used in this provision is that the data must be within the “possession or control” of the person or the service provider, therefore this provision is also capable of being used to access data stored in the territory of a third party as long as the data is within the possession and control of the person on whom the Production Order has been served. In this regard it must be noted that the Article makes a distinction between computer data and subscriber information and specifies that computer data can only be asked for from a person (including a service provider) located within the territory of the ordering Party even if the data is stored in the territory of a third Party.[49] However subscriber information[50] can be ordered only from a service provider even if the service provider is not located within the territory of the ordering Party as long as it is offering its services in the territory of that Party and the subscriber information relates to the service offered in the ordering Party’s territory.[51]
Since the power under Article 18 is a domestic power which potentially can be used to access subscriber data located in another State, the use of this Article may raise complicated jurisdictional issues. This combined with the growth of cloud computing and remote data storage also raises concerns regarding privacy and data protection, the jurisdictional basis pertaining to services offered without the service provider being established in that territory, as well as access to data stored in foreign jurisdictions or in unknown or multiple locations “within the cloud”.[52] Even though some of these issues require further discussions and a more nuanced treatment, the Cybercrime Committee felt the need to issue a Guidance Note to Article 18 in order to avoid some of the confusion regarding the implementation of this provision.
Article 18(1)(b) may include a situation where a service provider is located in one jurisdiction, but stores the data in another jurisdiction. Data may also be mirrored in several jurisdictions or move between jurisdictions without the knowledge or control of the subscriber. In this regard the Guidance Note points out that legal regimes increasingly recognize that, both in the criminal justice sphere and in the privacy and data protection sphere, the location of the data is not the determining factor for establishing jurisdiction.[53]
The Guidance Note further tries to clarify the term “offering services in its territory” by saying that Parties may consider that a service provider is offering services if: (i) the service provider enables people in the territory of the Party to subscribe to its services (and does not, for example, block access to such services); and (ii) the service provider has established a real and substantial connection that Party. Relevant factors to determine whether such a connection has been established include “the extent to which a service provider orients its activities toward such subscribers (for example, by providing local advertising or advertising in the language of the territory of the Party), makes use of the subscriber information (or associated traffic data) in the course of its activities, interacts with subscribers in the Party, and may otherwise be considered established in the territory of a Party”.[54] A service provider will not be presumed to be offering services within the territory of a Party just because it uses a domain name or email address connected to that country.[55] The Guidance Note provides a very elegant tabular illustration of its requirements to serve a valid Production Order on a service provider:[56]
|
PRODUCTION ORDER CAN BE SERVED |
||
|
IF The criminal justice authority has jurisdiction over the offence |
||
|
AND The service provider is in possession or control of the subscriber information |
||
|
AND |
||
|
The service provider is in the territory of the Party (Article 18(1)(a)) |
Or |
A Party considers that a service provider is “offering its services in the territory of the Party” when, for example: - the service provider enables persons in the territory of the Party to subscribe to its services (and does not, for example, block access to such services); and - the service provider has established a real and substantial connection to a Party. Relevant factors include the extent to which a service provider orients its activities toward such subscribers (for example, by providing local advertising or advertising in the language of the territory of the Party), makes use of the subscriber information (or associated traffic data) in the course of its activities, interacts with subscribers in the Party, and may otherwise be considered established in the territory of a Party. (Article 18(1)(b)) |
|
AND |
||
|
|
the subscriber information to be submitted is relating to services of a provider offered in the territory of the Party. |
|
The existing processes for accessing data across international borders, whether through MLATs or through the mechanism established under the Budapest Convention are clearly too slow to be a satisfactory long term solution. It is precisely for that reason that the Cybercrime Committee has suggested alternatives to the existing mechanism such as granting access to data without consent in certain specific emergency situations;[57] or access to data stored in another country through a computer in its own territory provided the credentials for such access are obtained through lawful investigative activities.[58] Another option suggested by the Cybercrime Committee is to look beyond the principle of territoriality, specially in light of the recent developments in cloud computing where the location of the data may not be certain or data may be located in multiple locations,[59] and look at a connecting legal factor as an alternative such as the “power of disposal”. This option implies that even if the location of the data cannot be determined it can be connected to the person having the power to “alter, delete, suppress or render unusable as well as the right to exclude other from access and any usage whatsoever”.[60]
Language of Requests
It was found from practice that the question of the language in which the mutual assistance requests were made was a big issue in most States since it created problems such as delays due to translations, costly translations, quality of translations, etc. The Cybercrime Committee therefore suggested that an additional protocol be added to the Budapest Convention to stipulate that requests sent by Parties should be accepted in English atleast in urgent cases since most States accepted a request in English.[61] Due to these problems associated with the language of assistance requests, the Cybercrime Convention Committee has already released a provisional draft Additional Protocol to address the issue of language of mutual assistance requests for public comments.[62]
24/7 Network
Parties are required to designate a point of contact available on a twenty-four hour, seven-day-a week basis, in order to ensure the provision of immediate assistance for the purpose of investigations or proceedings concerning criminal offences related to computer systems and data, or for the collection of evidence, in electronic form, of a criminal offence. The point of contact for each Party is required to have the capacity to carry out communications with the points of contact for any other Party on an expedited basis. It is the duty of the Parties to ensure that trained and properly equipped personnel are available in order to facilitate the operation of the network.[63] The Parties recognized that establishment of this network is among the most important means provided by the Convention of ensuring that Parties can respond effectively to the law enforcement challenges posed by computer-or computer-related crimes.[64] In practice however it has been found that in a number of Parties there seems to be a disconnect between the 24/7 point of contact and the MLA request authorities leading to situations where the contact points may not be informed about whether preservation requests are followed up by MLA authorities or not.[65]
Drawbacks and Improvements
The Budapest Convention, whilst being the most comprehensive and widely accepted document on international cooperation in the field of cybercrime, has its own share of limitations and drawbacks. Some of the major limitations which can be gleaned from the discussion above (and potential recommendations for the same) are listed below:
Weakness and Delays in Mutual Assistance: In practice it has been found that though States refuse requests on a number of grounds,[66] some states even refuse cooperation in the event that the case is minor but requires an excessive burden on the requested state. Further, the delays associated with the mutual assistance process are another major hurdle, and are perhaps the reason by police-to-police cooperation for the sharing of data related to cybercrime and e-evidence is much more frequent than mutual legal assistance.[67] The lack of regulatory and legal awareness often leads to procedural lapses due to which requests do not meet legal thresholds. More training, more information on requirements to be met and standardised and multilingual templates for requests may be a useful tool to address this concern.
Access to data stored outside the territory: Access to data located in another country without consent of the authorities in that country poses another challenge. The age of cloud computing with processes of data duplication and delocalisation of data have added a new dimension to this problem.[68] It is precisely for that reason that the Cybercrime Committee has suggested alternatives to the existing mechanism such as granting access to data without consent in certain specific emergency situations;[69] or access to data stored in another country through a computer in its own territory provided the credentials for such access are obtained through lawful investigative activities.[70] Another option suggested by the Cybercrime Committee is to look beyond the principle of territoriality and look at a connecting legal factor as an alternative such as the “power of disposal”.
Language of requests: Language of requests create a number of problems such as delays due to translations, cost of translations, quality of translations, etc. Due to these problems, the Cybercrime Convention Committee has already released for public comment, a provisional draft Additional Protocol to address the issue.[71]
Bypassing of 24/7 points of contact: Although 24/7 points have been set up in most States, it has been found that there is often a disconnect between the 24/7 point of contact and the MLA request authorities leading to situations where the contact points may not be informed about whether preservation requests are followed up by MLA authorities or not.[72]
India and the Budapest Convention
Although countries outside the European Union have the option on signing the Budapest Convention and getting onboard the international cooperation mechanism envisaged therein, India has so far refrained from signing the Budapest Convention. The reasons for this refusal appear to be as follows:
- India did not participate in the drafting of the treaty and therefore should not sign. This concern, while valid is not a consistent foreign policy stand that India has taken for all treaties, since India has signed other treaties, where it had no hand in the initial drafting and negotiations.[73]
- Article 32(b) of the Budapest Convention involves tricky issues of national sovereignty since it allows for cross border access to data without the consent of the other party. Although, as discussed above, the Guidance Note on Article 32 clarified this issue to an extent, it appears that arguments have been raised in some quarters of the government that the options provided by Article 32 are too limited and additional means may be needed to deal with cross border data access.[74]
- The mutual legal assistance framework under the Convention is not effective enough and the promise of cooperation is not firm enough since States can refuse to cooperate on a number of grounds.[75]
- It is a criminal justice treaty and does not cover state actors; further the states from which most attacks affecting India are likely to emanate are not signatories to the Convention either.[76]
- Instead of joining the Budapest Convention, India should work for and promote a treaty at the UN level.[77]
Although in January 2018 there were a number of news reports indicating that India is seriously considering signing the Budapest Convention and joining the international cooperation mechanism under it, there have been no updates on the status of this proposal.[78]
Conclusion
The Budapest Convention has faced a number of challenges over the years as far as provisions regarding international cooperation are concerned. These include delays in getting responses from other states, requests not being responded to due to various reasons (language, costs, etc.), requests being overridden by mutual agreements, etc. The only other alternative which is the MLAT system is no better due to delays in providing access to requested data.[79] This however does not mean that international cooperation through the Budapest Convention is always late and inefficient, as was evident from the example of the Norwegian bank robber-murderer given above. There is no doubt that the current mechanisms are woefully inadequate to deal with the challenges of cyber crime and even regular crimes (specially in the financial sector) which may involve examination of electronic evidence. However that does not mean the end of the road for the Budapest Convention, one has to recognize the fact that it is the pre-eminent document on international cooperation on electronic evidence with 62 State Parties as well as another 10 Observer States. Any mechanism which offers a solution to the thorny issues of international cooperation in the field of cyber crime would require most of the nations of the world to sign up to it; till such time that happens, expanding the scope of the Budapest Convention to address atleast some of the issues discussed above by leveraging the work already done by the Cybercrime Committee through various reports and Guidance Notes (some of which have been referenced in this paper itself) may be a good option as this could be an incentive for non signatories to become parties to a better and more efficient Budapest Convention providing a more robust international cooperation regime.
[1] Council of Europe, Explanatory Report to the Convention on Cybercrime, https://rm.coe.int/16800cce5b, para 304.
[2] Council of Europe, Convention on Cybercrime, 23 November 2001, Article 24(1)(a). Except in cases where a different minimum threshold has been provided by a mutual arrangement, in which case such other minimum threshold shall be applied.
[3] Council of Europe, Convention on Cybercrime, 23 November 2001, Article 24(5).
[4] Council of Europe, Convention on Cybercrime, 23 November 2001, Article 24(3).
[5] Council of Europe, Convention on Cybercrime, 23 November 2001, Article 24(2).
[6] Council of Europe, Explanatory Report to the Convention on Cybercrime, Para 304, https://rm.coe.int/16800cce5b, para 251.
[7] Council of Europe, Convention on Cybercrime, 23 November 2001, Article 24(6).
[8] Council of Europe, Convention on Cybercrime, 23 November 2001, Article 24(7).
[9] Council of Europe, Convention on Cybercrime, 23 November 2001, Article 25(1).
[10] Council of Europe, Convention on Cybercrime, 23 November 2001, Article 25(4).
[11] Council of Europe, Convention on Cybercrime, 23 November 2001, Article 27(2).
[12] Council of Europe, Convention on Cybercrime, 23 November 2001, Article 27(3) read with para 267 of the Explanatory Note to the Budapest Convention.
[13] Council of Europe, Convention on Cybercrime, 23 November 2001, Article 25(4).
[14] Council of Europe, Convention on Cybercrime, 23 November 2001, Article 27(4)(a).
[15] Council of Europe, Convention on Cybercrime, 23 November 2001, Article 27(4)(b).
[16] Council of Europe, Convention on Cybercrime, 23 November 2001, Article 27(5).
[17] Council of Europe, Convention on Cybercrime, 23 November 2001, Article 27(6).
[18] Some of the grounds listed by Parties for refusal are: (i) grounds listed in Article 27 of the Convention, (ii) the request does not meet formal or other requirements, (iii) the request is motivated by race, religion, sexual orientation, political opinion or similar, (iv) the request concerns a political or military offence, (v) Cooperation may lead to torture or death penalty, (vi) Granting the request would prejudice sovereignty, security, public order or national interest or other essential interests, (vii) the person has already been punished or acquitted or pardoned for the same offence “Ne bis in idem”, (viii) the investigation would impose an excessive burden on the requested State or create practical difficulties, (ix) Granting the request would interfere in an ongoing investigation (in which case the execution of the request may be postponed). Council of Europe, Cybercrime Convention Committee assessment report: The mutual legal assistance provisions of the Budapest Convention on Cybercrime, December 2014, pg. 34.
[19] Council of Europe, Cybercrime Convention Committee assessment report: The mutual legal assistance provisions of the Budapest Convention on Cybercrime, December 2014, pg. 34.
[20] Pedro Verdelho, Discussion Paper: The effectiveness of international cooperation against cybercrime: examples of good practice, 2008, pg. 5, https://www.coe.int/t/dg1/legalcooperation/economiccrime/cybercrime/T-CY/DOC-567study4-Version7_en.PDF, accessed on March 28, 2019.
[21] Council of Europe, Convention on Cybercrime, 23 November 2001, Article 27(8).
[22] However, disclosure of the material to the defence and the judicial authorities is an implicit exception to this rule. Further the ability to use the material in a trial (which is generally a public proceeding) is also a recognised exception to the right to limit usage of the material. See para 278 of the the Explanatory Note to the Budapest Convention.
[23] Council of Europe, Convention on Cybercrime, 23 November 2001, Article 28.
[24] Council of Europe, Convention on Cybercrime, 23 November 2001, Article 27(9)(a) and (b).
[25] Council of Europe, Convention on Cybercrime, 23 November 2001, Article 27(9)(d) read with para 274 of the Explanatory Note to the Budapest Convention.
[26] Council of Europe, Convention on Cybercrime, 23 November 2001, Article 31.
[27] Council of Europe, Convention on Cybercrime, 23 November 2001, Article 33.
[28] Council of Europe, Convention on Cybercrime, 23 November 2001, Article 34.
[29] Council of Europe, Cybercrime Convention Committee assessment report: The mutual legal assistance provisions of the Budapest Convention on Cybercrime, December 2014, pg. 37.
[30] Council of Europe, Cybercrime Convention Committee assessment report: The mutual legal assistance provisions of the Budapest Convention on Cybercrime, December 2014, pg. 123.
[31] Ibid at 124.
[32] Council of Europe, Convention on Cybercrime, 23 November 2001, Article 29(3) read with para 285 of the Explanatory Note to the Budapest Convention.
[33] Council of Europe, Convention on Cybercrime, 23 November 2001, Article 29(4).
[34] Council of Europe, Convention on Cybercrime, 23 November 2001, Article 29(5).
[35] Council of Europe, Convention on Cybercrime, 23 November 2001, Article 29(6).
[36] Council of Europe, Convention on Cybercrime, 23 November 2001, Article 29(7).
[37] Council of Europe, Convention on Cybercrime, 23 November 2001, Article 30.
[38] Anna-Maria Osula, Accessing Extraterritorially Located Data: Options for States, http://ccdcoe.eu/uploads/2018/10/Accessing-extraterritorially-located-data-options-for-States_Anna-Maria_Osula.pdf, accessed on March 28, 2019.
[39] Council of Europe, Convention on Cybercrime, 23 November 2001, Article 32.
[40] Council of Europe, Explanatory Report to the Convention on Cybercrime, Para 304, https://rm.coe.int/16800cce5b, para 293.
[41] Council of Europe, Cybercrime Convention Committee, Report of the Transborder Group, Transborder access and jurisdiction: What are the options?, December 2012, para 310.
[42] Council of Europe, Cybercrime Convention Committee Guidance Note # 3, Transborder access to data (Article 32), para 3.2.
[43] Council of Europe, Cybercrime Convention Committee Guidance Note # 3, Transborder access to data (Article 32), para 3.3.
[44] Council of Europe, Cybercrime Convention Committee Guidance Note # 3, Transborder access to data (Article 32), para 3.4.
[45] Council of Europe, Cybercrime Convention Committee Guidance Note # 3, Transborder access to data (Article 32), para 3.6.
[46] Council of Europe, Cybercrime Convention Committee Guidance Note # 3, Transborder access to data (Article 32), para 3.8.
[47] Council of Europe, Convention on Cybercrime, 23 November 2001, Article 18.
[48] Council of Europe, Explanatory Report to the Convention on Cybercrime, Para 304, https://rm.coe.int/16800cce5b, para 170.
[49] Council of Europe, Explanatory Report to the Convention on Cybercrime, Para 304, https://rm.coe.int/16800cce5b, para 173.
[50] Defined in Article 18(3) as “any information contained in the form of computer data or any other form that is held by a service provider, relating to subscribers of its services other than traffic or content data and by which can be established:
a. the type of communication service used, the technical provisions taken thereto and the period of service;
b. the subscriber’s identity, postal or geographic address, telephone and other access number, billing and payment information, available on the basis of the service agreement or arrangement;
c. any other information on the site of the installation of communication equipment, available on the basis of the service agreement or arrangement.
[51] Council of Europe, Explanatory Report to the Convention on Cybercrime, Para 304, https://rm.coe.int/16800cce5b, para 173.
[52] Council of Europe, Cybercrime Convention Committee Guidance Note #10, Production orders for subscriber information (Article 18 Budapest Convention), at pg.3.
[53] Council of Europe, Cybercrime Convention Committee Guidance Note #10, Production orders for subscriber information (Article 18 Budapest Convention), para 3.5 at pg. 7.
[54] Council of Europe, Cybercrime Convention Committee Guidance Note #10, Production orders for subscriber information (Article 18 Budapest Convention), para 3.6 at pg. 8.
[55] Id.
[56] Council of Europe, Cybercrime Convention Committee Guidance Note #10, Production orders for subscriber information (Article 18 Budapest Convention), para 3.8 at pg. 9.
[57] Situations such as preventions of imminent danger, physical harm, the escape of a suspect or similar situations including risk of destruction of relevant evidence.
[58] Council of Europe, Cybercrime Convention Committee, Subgroup on Transborder Access, (Draft) Elements of an Additional Protocol to the Budapest Convention on Cybercrime Regarding Transborder Access to Data, April 2013, pg. 49.
[59] Council of Europe, Cybercrime Convention Committee Cloud Evidence Group, Criminal justice access to data in the cloud: challenges (Discussion paper), May 2015, pgs 10-14.
[60] Council of Europe, Cybercrime Convention Committee, Subgroup on Transborder Access, (Draft) Elements of an Additional Protocol to the Budapest Convention on Cybercrime Regarding Transborder Access to Data, April 9, 2013, pg. 50.
[61] Council of Europe, Cybercrime Convention Committee assessment report: The mutual legal assistance provisions of the Budapest Convention on Cybercrime, December 2014, pg. 35.
[62] https://www.coe.int/en/web/cybercrime/-/towards-a-protocol-to-the-budapest-convention-further-consultatio-1
[63] Council of Europe, Convention on Cybercrime, 23 November 2001, Article 35.
[64] Council of Europe, Explanatory Report to the Convention on Cybercrime, Para 304, https://rm.coe.int/16800cce5b, para 298.
[65] Council of Europe, Cybercrime Convention Committee assessment report: The mutual legal assistance provisions of the Budapest Convention on Cybercrime, December 2014, pg. 86.
[66] Some of the grounds listed by Parties for refusal are: (i) grounds listed in Article 27 of the Convention, (ii) the request does not meet formal or other requirements, (iii) the request is motivated by race, religion, sexual orientation, political opinion or similar, (iv) the request concerns a political or military offence, (v) Cooperation may lead to torture or death penalty, (vi) Granting the request would prejudice sovereignty, security, public order or national interest or other essential interests, (vii) the person has already been punished or acquitted or pardoned for the same offence “Ne bis in idem”, (viii) the investigation would impose an excessive burden on the requested State or create practical difficulties, (ix) Granting the request would interfere in an ongoing investigation (in which case the execution of the request may be postponed). Council of Europe, Cybercrime Convention Committee assessment report: The mutual legal assistance provisions of the Budapest Convention on Cybercrime, December 2014, pg. 34.
[67] Council of Europe, Cybercrime Convention Committee assessment report: The mutual legal assistance provisions of the Budapest Convention on Cybercrime, December 2014, pg. 7.
[68] Giovanni Buttarelli, Fundamental Legal Principles for a Balanced Approach, Selected papers and contributions from the International Conference on “Cybercrime: Global Phenomenon and its Challenges”, Courmayeur Mont Blanc, Italy available at ispac.cnpds.org/download.php?fld=pub_files&f=ispacottobre2012bassa.pdf
[69] Situations such as preventions of imminent danger, physical harm, the escape of a suspect or similar situations including risk of destruction of relevant evidence.
[70] Council of Europe, Cybercrime Convention Committee, Subgroup on Transborder Access, (Draft) Elements of an Additional Protocol to the Budapest Convention on Cybercrime Regarding Transborder Access to Data, April 2013, pg. 49.
[71] https://www.coe.int/en/web/cybercrime/-/towards-a-protocol-to-the-budapest-convention-further-consultatio-1
[72] Council of Europe, Cybercrime Convention Committee assessment report: The mutual legal assistance provisions of the Budapest Convention on Cybercrime, December 2014, pg. 86.
[73] Dr. Anja Kovaks, India and the Budapest Convention - To Sign or not? Considerations for Indian Stakeholders, available at https://internetdemocracy.in/reports/india-and-the-budapest-convention-to-sign-or-not-considerations-for-indian-stakeholders/
[74] Alexander Seger, India and the Budapest Convention: Why not?, Digital Debates: The CyFy Journal, Vol III, available at https://www.orfonline.org/expert-speak/india-and-the-budapest-convention-why-not/
[75] Id.
[76] Id.
[77] Id.
[78] https://indianexpress.com/article/india/home-ministry-pitches-for-budapest-convention-on-cyber-security-rajnath-singh-5029314/
[79] Elonnai Hickok and Vipul Kharbanda, Cross Border Cooperation on Criminal Matters - A perspective from India, available at https://cis-india.org/internet-governance/blog/cross-border-cooperation-on-criminal-matters
FinTech in India: A Study of Privacy and Security Commitments
Access the full report: Download (PDF)
The report by Aayush Rathi and Shweta Mohandas was edited by Elonnai Hickok. Privacy policy testing was done by Anupriya Nair and visualisations were done by Saumyaa Naidu. The project is supported by the William and Flora Hewlett Foundation.
In India, the Information Technology (Reasonable Security Practices and Procedures and Sensitive Personal Data or Information) Rules, 2011 (subsequently referred to as SPD/I Rules) framed under the Information Technology Act, 2000 make privacy policies a ubiquitous feature of websites and mobile applications of firms operating in India. Privacy policies are drafted in order to allow consumers to make an informed choice about the privacy commitments being made vis-à-vis their information, and is often the sole document that lays down a companies’ privacy and security practices.In India, the Information Technology (Reasonable Security Practices andProcedures and Sensitive Personal Data or Information) Rules, 2011 (subsequently referred to as SPD/I Rules) framed under the Information Technology Act, 2000 make privacy policies a ubiquitous feature of websites and mobile applications of firms operating in India. Privacy policies are drafted in order to allow consumers to make an informed choice about the privacy commitments being made vis-à-vis their information, and is often the sole document that lays down a companies’ privacy and security practices.
The objective of this study is to understand privacy commitments undertaken by fintech companies operating in India as documented in their public facing privacy policies. This exercise will be useful to understand what standards of privacy and security protection fintech companies are committing to via their organisational privacy policies. The research will do so by aiming to understand the alignment of the privacy policies with the requirements mandated under the SPD/I Rules. Contingent on the learnings from this exercise, trends observed in fintech companies’ privacy and security commitments will be culled out.
How privacy fares in the 2019 election manifestos | Opinion
The article by Aayush Rathi and Ambika Tandon was published in the Hindustan Times on May 1, 2019.
In August 2017, the Supreme Court, in Puttaswamy vs Union of India, unanimously recognised privacy as a fundamental right guaranteed by the Constitution. Before the historic judgment, the right to privacy had remained contested and was determined on a case-by-case basis. By understanding privacy as the preservation of individual dignity and autonomy, the judgment laid the groundwork to accommodate subsequent landmark legislative moves — varying from decriminalising homosexuality to limiting the use of the Aadhaar by private actors.
Reflecting the importance gained by privacy within public imagination, the 2019 elections are the first time it finds mention across major party manifestos. In 2014, the Communist Party of India (Marxist) was the only political party to have made commitments to safeguarding privacy, albeit in a limited fashion. For the 2019 election, both the Congress and the CPI(M) promise to protect the right to privacy if elected to power. The Congress promises to “pass a law to protect the personal data of all persons and uphold the right to privacy”. However, it primarily focuses on informational privacy and its application to data protection, limited to the right of citizens to control access and use of information about themselves.
The CPI(M) focuses on privacy more broadly while promising to protect against “intrusion into the fundamental right to privacy of every Indian”. In a similar vein, both the Congress and the CPI(M) also commit to bringing about surveillance reform by incorporating layers of oversight. The CPI(M) manifesto further promises to support the curtailment of mass surveillance globally. It promises to enact a data privacy law to protect against “appropriation/misuse of private data for commercial use”, albeit without any reference to misuse by government agencies.
On the other hand, the Samajwadi Party manifesto proposes the reintroduction of the controversial NATGRID, an overarching surveillance tool proposed by the Congress in the aftermath of the 26/11 Mumbai attacks. In this backdrop, digital rights for individuals are conspicuous by their absence from the Bharatiya Janata Party’s manifesto. Data protection is only seen in a limited sense as being required in conjunction with increasing digital financialisation.
The favourable articulation of privacy in some of the manifestos should be read along with other commitments across parties around achieving development goals through the digital economy. Central to the operation of this is aggregating citizen data. Utilising this aggregated data for predictive abilities is key to initiatives being proposed in the manifestos —digitising health records, a focus on sunrise technologies, such as machine learning and big data, and readiness for “Industry 5.0” are some examples.
The right is then operationalised in a manner that leads data subjects to pick between their privacy and accessing services being provided by the data collector. Relinquishing privacy becomes the only option especially when access to welfare services is at stake.
The discourse around privacy in India has historically been used to restrict individual freedoms. In the Puttaswamy case, Justice DY Chandrachud, in his plurality opinion, acknowledges feminist scholarship to broaden the understanding of the right to privacy to one that protects bodily integrity and decisional privacy for marginalised communities. This implies protection against any manner of State interference with decisions regarding the self, and, more broadly, the right to create a private space to allow the personality to develop without interference. This includes protection from undue violations of bodily integrity such as protecting the freedom to use public spaces without fear of harassment, and criminalising marital rape.
While the articulation of privacy in the manifestos is a good start, it should be much more. Governance must implement the right to look beyond the individualised conception of privacy so as to allow it to support a whole range of freedoms, rather than limiting it to data protection. This could take the shape of modifying traditional legal codes. Family law, for instance, could be reshaped to allow for greater exercise of agency by women in marriage, guardianship, succession etc. Criminal law, too, could render inadmissible evidence obtained through unjustified privacy violations. The manifestos do mark the entry of a rights-based language around privacy and bodily integrity into mainstream political discourse. However, there appears to be a lack of imagination of the extent to which these protections can be used to further individual liberty collectively.
Why the TikTok ban is worrying
The article by Gurshabad Grover was published in Hindustan Times on May 2, 2019.
In a span of less than two weeks, the Madras High Court has imposed and lifted a ban on the TikTok mobile application, an increasingly popular video and social platform. While rescinding the ban is welcome, the events tell a worrying tale of how the courts can arbitrarily censor online expression with little accountability.
On April 3, the Madras High Court heard a public interest litigation petitioning for the TikTok mobile app to be banned in India because it was “encouraging pornography”, “degrading culture”, “causing paedophiles”, spreading “explicit disturbing content” and causing health problems for teenagers. It is difficult to establish the truth of these extreme claims about content on the platform that has user generated content, but the court was confident enough to pass wide ranging interim orders on the same day without hearing ByteDance, the company that operates the Tik Tok app.
The interim order had three directives. First, the Madras High Court ordered the government to prohibit the downloading of the app. Second, it restricted the media from broadcasting videos made using the app. Third, it asked the government to respond about whether it plans to enact legislation that would protect children’s online privacy. While the third directive poses an important question to the government that merits a larger discussion, the first two completely lacked a legal rationale. The court order also implied that the availability of pornography on the platform was problematic, even though it is not illegal to access pornography in India.
Appallingly, the order makes no mention at all of the most pertinent legal provision: Section 79 of the Information Technology (IT) Act and the rules issued under it, which form the liability regime applicable to intermediaries (online services). The intermediary liability rules in India generally shield online platforms from liability for the content uploaded to their platform as long as the company operating is primarily involved in transmitting the content, complies with government and court orders, and is not abetting illegal activity. It is this regime that has ensured that online platforms are not hyperactively censoring expression to avoid liability, and has directly supported the proliferation of speech online.
The courts do have some powers of online censorship under the provision, which they have used many times in the past. They have the authority to decide on questions of whether certain content violates law and then direct intermediaries to disable access to that specific content. Such a legal scenario was certainly not the case before the Madras High Court. We can also be sure that the app stores run by Apple and Google, on which TikTok is available, were not the intermediaries under consideration here (which would also be problematic in its own ways) since the interim order makes no mention of them. So, despite the fact that the court’s order had no clear jurisdiction and legal basis, Apple and Google were ordered by the government to remove TikTok from their respective mobile app stores for India.
ByteDance Technology appealed to the Supreme Court of India to rescind the ban, arguing that they qualify as intermediaries under the IT Act and should not face a blanket ban as a repercussion of allegedly problematic content on their platform. The Supreme Court refrained from staying the problematic Madras High Court interim order, but decided that the ban on the app will be lifted by April 24 if the case wasn’t decided by then. On April 24, sense finally prevailed when the High Court decided to take the interim directive back.
Admittedly, popular online platforms can create certain social problems. TikTok has faced bans elsewhere and was fined by the Federal Trade Commission in the United Sates for collecting information on its users who were below the age of 13. There is no debate that the company is legally bound to follow the rules issued under the IT Act, be responsive to legally valid government and court orders, and should strictly enforce their community guidelines that aim to create a safe environment for the young demographic that forms a part of its user base. However, a ban is a disproportionate move that sends signals of regulatory uncertainty, especially for technology companies trying to break into an increasingly consolidated market. The failure of the government to enact a law that protects children’s privacy also cannot be considered a legitimate ground for a ban on a mobile app.
Perhaps most importantly, the interim court order adds yet another example to the increasing number of times the judiciary has responded to petitions by passing censorship orders that have no basis in law. As constitutional scholar Gautam Bhatia has pointed out, we are faced with the trend of “judicial censorship” wherein the judiciary is exercising power without accountability in ways not envisioned by the Constitution. Rather than critically examining the infringement of liberties by the political executive, the Indian courts are becoming an additional threat to the right to freedom of expression, which we must be increasingly wary of.
An Analysis of the RBI’s Draft Framework on Regulatory Sandbox for Fintech
Click here to download the file.
It originated as a term referring to the back-end technology used by large financial institutions, but has expanded to include technological innovation in the financial sector, including innovations in financial literacy and education, retail banking, investments, etc. Entities engaged in FinTech offer an array of services ranging from peer-to-peer lending platforms and mobile payment solutions to online portfolio management tools and international money transfers.
Regulation and supervision of the Fintech industry raises some unique challenges for regulatory authorities as they have to strike a balance between financial inclusion, stability, integrity, consumer protection, and competition. One of the methods that have been adopted by regulators in certain jurisdictions to tackle the complexities of this sector is to establish a “regulatory sandbox” which could nurture innovative fintech enterprises while at the same time ensuring that the risk associated with any regulatory relaxations is contained within specified boundaries. It was precisely for this reason that establishment of a regulatory sandbox was one of the options put forward by the Working Group on Fintech and Digital Banking established by the Reserve Bank of India in its report of November, 2017 which was released for public comments on February 8, 2018. Acting on this recommendation the Reserve Bank has proposed a Draft Enabling Framework for Regulatory Sandbox, dated April 18, 2019, (“RBI Framework”) which is analysed and discussed below.
Regulatory Sandbox and its benefits
While the basic concept of a regulatory sandbox is to ensure that there is regulatory encouragement and incentive for fledgling Fintech enterprises in a contained environment to mitigate risks, different regulatory authorities have adopted varied methods of achieving this objective. While the Australian Securities and Exchange Commission (ASIC) uses a method where the eligible enterprises notify the ASIC and commence testing without an individual application process, the Financial Conduct Authority, UK (FCA) uses a cohort approach wherein eligible enterprises have to apply to the FCA which then selects the best options based on criteria laid down in the policy. The RBI has, not surprisingly, adopted an approach similar to the FCA wherein applicants will be selected by the RBI based on pre-defined eligibility criterion and start the regulatory sandbox in cohorts containing a few entities at a time.
A regulatory sandbox offers the users the opportunity to test the product’s viability without a larger and more expensive roll out involving heavy investment and regulatory authorizations. If the product appears to have the potential to be successful, it might then be authorized and brought to the broader market more quickly. If there are any problems with the product the limited nature of the sandbox ensures that the consequences of the problems are contained and do not affect the broader market. It also allows regulators to obtain first-hand empirical evidence on the benefits and risks of emerging technologies and business models, and their implications, which allows them to take a considered (and perhaps more nuanced) view on the regulatory requirements that may be needed to support useful innovation, while mitigating the attendant risks. A regulatory sandbox initiative also sends a clear signal to the market that innovation is on the agenda of the regulator.
RBI Draft Framework
Since the RBI has adopted a cohort approach for its regulatory sandbox process (“RS”), it implies that fintech entities will have to apply to the RBI to be selected in the RS. The eligibility criterion provides that the applicants will have to meet the eligibility conditions prescribed by the government for start-ups as per the Government of India, Department of Industrial Policy and Promotion, Notification GSR 364(E) April 11, 2018. The RS will focus on areas where (i) there is an absence of regulations, (ii) regulations need to be eased to encourage innovation, and (iii) the innovation/product shows promise of easing/effecting delivery of financial services in a significant way. The Framework also provides an indicative list of innovative products and technologies which could be considered for RS testing, and at the same time prohibits certain products and technologies from being considered for this programme such as credit registry, crypto currencies, ICOs, etc.
The RBI Framework also lays down specific conditions that the entity has to satisfy in order to be considered for the RS such as satisfaction of the conditions to be considered a start-up, minimum net worth requirements, fit and proper criteria for Directors and Promoters, satisfactory conduct of bank accounts of promoters/directors, satisfactory credit score, technological readiness of the product for deployment in the broader market, ensuring compliance with existing laws and regulations on consumer data and privacy, adequate safeguards in its IT systems for protection against unauthorised access etc. and a robust IT infrastructure and managerial resources. The fit and proper criteria for Directors and Promoters which requires elements of credit history along with the minimum net worth requirements in the RBI Framework are conditions which may be too difficult for some of the smaller and newer start-ups to satisfy even though the technology and products they offer might be sound. The applicants are also required to: (i) highlight an existing gap in the financial ecosystem and how they intend to address that, (ii) show a regulatory barrier or gap that prevents the implementation of the solution on a large scale, (iii) clearly define the test scenarios, expected outcomes, boundary conditions, exit or transition strategy, assessment and mitigation of risks, etc.
The RBI Framework specifies that the focus of the RS should be narrow in terms of areas of innovation and limited in terms of intake. While limits on the number of entities per cohort may be justified based on paucity of resources, limiting the focus of the RS by narrow areas of innovation is a lost opportunity in terms of sharing of ideas and learning from the mistakes of their colleagues who may be employing technologies and principles which could be useful in fields other than those where they are currently being applied.
The RBI Framework specifies that the boundaries of the RS have to be well defined so that any consequences of failure can be contained. These boundary conditions include a specific start and end date, target customer type and limits on number of customers, cash holdings, transaction amounts and customer losses. The Framework does not put in place any hard numbers on the boundary conditions which ensures that the RS process can be customised to the needs of specific entities since the sample sizes and data needed to determine the viability of fintech entities and products may vary from product to product. However a major dampener is the hard limit of 12 weeks imposed on the testing phase of the RS, which is the most important phase since all the data from the operations is generated during this phase and 12 weeks may not be enough time to generate enough reliable data so as to reach a determination of the viability of the product.
Although the RBI has shown a willingness to relax regulatory requirements for RS participants on a case to case basis, it has specified that there shall be no relaxation on issues of customer privacy and data protection, security of payment data, transaction security, KYC requirements and statutory restrictions. Since this is only an initiative by the RBI the RS participants dealing with the insurance or securities sector would not be entitled to any relaxations from the IRDA or the SEBI even if they are found eligible for relaxations from RBI regulations. This would severely limit the efficacy of the RS process and is an issue that could have been addressed if all three regulators had collaborated thereby encouraging innovative start-ups offering a broader spectrum of services.
Once the RS is finished, the regulatory relaxations provided by the RBI will expire and the fintech entity will have to either stop operations or comply with the relevant regulations. In case the entity requires an extension of the RS period, it would apply to the RBI atleast one month prior to the expiry of the RS period with reasons for the extension. The RBI also has the option of prematurely terminating the sandbox process in case the entity does not achieve its intended purpose or if it cannot comply with the regulatory requirements and other conditions specified at the relevant stage of the sandbox process. The fintech entity is also entitled to quit the RS process prematurely by giving one week’s notice to the RBI, provided it ensures that all its existing obligations to its customers are fully addressed before such discontinuance. Infact customer obligations have to be met by the fintech entities irrespective of whether the operations are prematurely ended by the entity or it continues through the entire RS process; no waiver of the legal liability towards consumers is provided by the RS process. In addition, customers are required to be notified upfront about the potential risks and their explicit consent is to be taken in this regard.
The RBI Framework itself lists out some of the risks associated with the regulatory sandbox model such as (i) loss of flexibility in going through the RS process, (ii) case by case determinations involve time and discretional judgements, (iii) no legal waivers, (iv) requirement of regulatory approvals after the RS process is over, (iv) legal issues such as consumer complaints, challenges from rejected candidates, etc. While acknowledging the above risks the Framework also mentions that atleast some of them may be mitigated by following a time bound and transparent process thus reducing risks of arbitrary discretion and loss of flexibility.
Conclusions
While there are some who are sceptical of the entire concept of a regulatory sandbox for the reason that it loosens regulation too much while at the same time putting customers at risk, the cohort model adopted by the RBI would reduce that risk to an extent since it ensures comprehensive screening and supervision by the RBI with clear exit strategies and an emphasis on consumer interests. On the other hand the eligibility criterion for applicants prescribes minimum net worth requirements as well as credit history, etc. which may impose conditions too onerous for some start ups which may be their infancy. Further the clear emphasis on protection of customer privacy and consumer interests also ensures that the RBI will not put the interests of ordinary citizens at risk in order to promote new and untested technologies. That said, the regulatory sandbox process is a welcome initiative by the RBI which may send a signal to the financial community that it is aware of the potential advantages as well as risks of Fintech and is willing to play a proactive role in encouraging new technologies to improve the financial sector in India.
Report of Working Group on Fintech and Digital Banking, Reserve Bank of India, November, 2017, available at https://www.rbi.org.in/Scripts/PublicationReportDetails.aspx?UrlPage=&ID=892
Jenik, Ivo, and Kate Lauer. 2017. “Regulatory Sandboxes and Financial Inclusion.” Working Paper. Washington, D.C.: CGAP, available at https://www.cgap.org/sites/default/files/Working-Paper-Regulatory-Sandboxes-Oct-2017.pdf
Other countries which have regulatory sandboxes are Netherlands, Bahrain, Abu Dhabi, Saudi Arabia, etc.
Report of Working Group on Fintech and Digital Banking, Reserve Bank of India, November, 2017, available at https://www.rbi.org.in/Scripts/PublicationReportDetails.aspx?UrlPage=&ID=892
Jenik, Ivo, and Kate Lauer. 2017. “Regulatory Sandboxes and Financial Inclusion.” Working Paper. Washington, D.C.: CGAP, available at https://www.cgap.org/sites/default/files/Working-Paper-Regulatory-Sandboxes-Oct-2017.pdf
These conditions are fairly liberal in that they require that the entity should be less than 7 years old; should not have a turnover of more than 25 crores, and should be working for innovation, development or improvement of products or processes or services, or if it is a scalable business model with a high potential of employment generation or wealth creation.
Clause 5 of the RBI Framework.
Clause 6.1 of the RBI Framework.
Clause 6.3 of the RBI Framework.
Clause 6.5 of the RBI Framework.
Clause 6.4 of the RBI Framework.
Clause 6.7 of the RBI Framework.
Clauses 6.2 and 8 of the RBI Framework.
Clause 6.6 of the RBI Framework.
Clause 6.9 of the RBI Framework.
Jemima Kelly, A “fintech sandbox” might sound like a harmless idea. It's not, Financial Times, Aplphaville, https://ftalphaville.ft.com/2018/12/05/1543986004000/A--fintech-sandbox--might-sound-like-a-harmless-idea--It-s-not/
Will the WTO Finally Tackle the ‘Trump’ Card of National Security?
The article by Arindrajit Basu was published in the Wire on May 8, 2019.
From stonewalling appointments at the appellate body of the WTO’s dispute settlement body (DSB) to slapping exorbitant steel and aluminium tariffs on a variety of countries, Trump has attempted to desecrate an institution that he views as being historically unfair to America’s national interests.
Given this potentially cataclysmic state of affairs, a WTO panel report adopted last month regarding a transport restriction dispute between the Russia and Ukraine would ordinarily have attracted limited attention. In reality, this widely celebrated ruling was the first instance of the WTO mechanism mounting a substantive legal resistance to Trump’s blitzkrieg.
The opportunity arose from the Russian Federation’s invocation of the ‘national security exception’ carved into the Article XXI of the General Agreement on Tariffs and Trade (GATT-the primary WTO covered agreement dealing with trade in goods.)
This clause has rarely been invoked by a litigating party at the DSB and never been interpreted by the panel or appellate body due to the belief among WTO member states that the exception is ‘self-judging’ i.e. beyond the purview of WTO jurisdiction sovereign prerogative to use as they see fit.
Over the past couple of years, the provision has taken on a new avatar with trade restrictions being increasingly used as a strategic tool to accomplish national security objectives. In addition to the Russian Federation, in this case, it was used by the UAE to justify sanctions against Qatar in 2017and notably by the US administration in response to the commencement of WTO proceedings by nine countries (including India) against its steel and aluminum tariffs.
India itself has also cited the clause in its diplomatic statements when justifying revocation of the Most Favoured Nation Status to Pakistan, although this has not yet resulted in proceedings at the WTO.
Even though the panel held in favour of Russia, this report lays down the edifice for dismantling the Trump Administration’s present strategy. By explicitly stating that Article XXI is not entirely beyond review of the WTO, the panel report gives a cause de celebre for all countries attempting to legally battle Trump’s arbitrary protectionist cause disguised as genuine national security concerns.
At the same time, it might act as a source of comfort for Huawei and China as it allows them to challenge the legality of banning Huawei (as some countries have chosen to do) at the WTO.
History of Article XXI
Article XXI had an uncertain presence in the legal architecture of the WTO from its very inception. It had its origins in the US proposal to establish the International Trade Organisation. The members of the delegation themselves were divided between those who wanted to preserve the sovereign right of the United States to interpret the extent of the exception as it saw fit and others who felt that this provision would be abused to further arbitrary protectionism. The delegate of Australia was also skeptical about the possible exclusion of dispute resolution through a mere invocation of the security exception.
Given this divergence, the drafters of the provision thus sought to create a specific set of exceptions in order to arrive at a compromise that “would take care of real security interests” while limiting “the exception so as to prevent the adoption of protection for maintaining industries under every conceivable circumstances”.
To attain that objective, the provision in the ITO Charter, which was reflected in Article XXI of GATT 1947 was worded thus:
Nothing in this Agreement shall be construed
to require any contracting party to furnish any information the disclosure of which it considers contrary to its essential security interests;
or to prevent any contracting party from taking any action which it considers necessary for the protection of its essential security interests (i) relating to fissionable materials or the materials from which they are derived; (ii) relating to the traffic in arms, ammunition and implements of war and to such traffic in other goods and materials as is carried on directly or indirectly for the purpose of supplying a military establishment; (iii) taken in time of war or other emergency in international relations; or
to prevent any contracting party from taking any action in pursuance of its obligations under the United Nations Charter for the maintenance of international peace and security
Article XXI has been historically invoked in cases where national security is devised as a smokescreen for protectionism. For example, in 1975, Sweden cited Article XXI to justify global import restrictions it had had slapped on certain types of footwear. It argued that a decrease in domestic production of said kinds of footwear represented ” a critical threat to the emergency planning of its economic defense.” There was sustained criticism from some states, who questioned Sweden’s juxtaposition of a national security threat with economic strife, claiming that they too were suffering from severe unemployment at the time and the Swedish restrictions would be devastating for their economic position.
The Swedish problem dissipated when Sweden withdrew the restrictions but the uncertain peril of Article XXI remained.
In another instance, the US themselves had previously relied on the security exception to justify measures prohibiting all imports of goods and services of Nicaraguan origin to the US in addition to all U.S. exports to Nicaragua.It argued that Article XXI was self-judging and each party could enact measures it considered necessary for the protection of its essential security interests. In fact, it was successful in keeping its Article XXI invocation outside the terms of reference (which establishes the scope of the Panel’s report), which precluded the Panel from asserting its jurisdiction and examining the provision. It is worth noting, though, that the Panel was critical of the US for utilising the provision in this case and emphasised the need for balancing this exception against the need to preserve the stability of global trade.
The recent spate of national security driven justifications to subvert the adjudicatory powers of the WTO provided a necessary opportunity for the panel to clarify its stance on this issue.
The findings of the panel
The findings of the panel can be divided into three broad clusters:
1) The WTO tribunals’ jurisdiction over the security exception: Right from the outset, the panel clearly stated that it had jurisdiction to adjudicate the matter at hand. It rebutted Russia’s claim that any country invoking the exception had unfettered discretion in the matter
2) The ambit of the self-judging nature of the security clause: Both the Russian Federation and the United States, which had filed a third party submission, re-emphasised the supposed self-judging nature of the security clause due to the incorporation of the words “ which it[the WTO member] considers necessary for the protection of its essential security interests” in clause (2) of the provision.
However, the panel argued that the sub-paragraphs (i)-(iii) require an objective review by the Panel to determine whether the state of affairs indicated in the sub-paragraphs do, in fact, exist. In this way, the Panel added,the three sub-clauses act as “limiting qualifying clauses.” The determination of the measures that may be ‘necessary’ for protecting their ‘essential security interests’ are then left to each WTO member. By interpreting the clause in this manner,the Panel deftly preserved the sovereign autonomy of member states while preventing the bestowing of carte blanche’ ability to take shelter behind the provision.
3) Determination of emergency in international relations: The use of the term “other emergency in international relations” as used in the provision is an amorphous one because the term ‘emergency’ is not clearly defined in international law. Therefore, the Panel relied on UN General Assembly Resolutions and the fact that multiple states had imposed sanctions on Russia to conclude that there was, in fact, an ‘emergency’ in international relations in this case. In doing so, the Panel upheld the transport restrictions imposed by Russia. However, the implications extend far beyond the immediate impact on the two parties.
Implications of the ruling
Before considering the implications of this report, we must consider that, like in other avenues of international law, the municipal legal principle of stare decisis does not apply to Panel or Appellate Body decisions. This means that future panels are not bound by law to follow the finding in this report.
However, WTO tribunals have often used the reasoning put forward in previous panel or Appellate Body reports to support their findings.
Steel and aluminium tariffs
The US, whose third party submission failed to sway the panel has recognised the potential implications of the report and disparaged it as being “seriously flawed”. They have also discouraged the WTO tribunals deciding the steel and aluminium tariff disputes from using it as precedent.
However, Australia, Brazil, Canada, China, European Union, Japan, Moldova, Singapore and Turkey had all filed third party submissions which encouraged the panel to assert its jurisdiction in the matter and have openly supported the panel’s approach – which would be a boost for the panels set up to adjudicate the Trump sanctions.
Given the groundwork laid out by the panel in this dispute, it would be difficult for the US to satisfy the panel’s understanding of ‘emergency in international relations’ as the Panel clearly stated that “political or economic differences between Members are not sufficient, of themselves, to constitute an emergency in international relations for purposes of subparagraph (iii)”.
Huawei and cybersecurity
In addition to steel and aluminium tariffs, the panel’s decision also has an impact on the rapidly unfolding Huawei saga. Huawei, which is the world’s largest telecom equipment company and is now taken the lead in the race to develop one of the world’s most critical emerging technologies: fifth generation mobile telephony.
However, Huawei has recently fallen out of favour with the US and other western countries amidst suspicions of them enabling the Chinese government to spy on other countries by incorporating backdoors into their infrastructure.
Various countries, including Australia, Japan, New Zealand have effectively banned Huawei from public participation while the US has prevented government agencies from buying Huawei infrastructure-triggering litigation by Huawei seeking to prevent the move.India has adopted an independent approach by allowing Huawei to participate in field trials of 5G equipment despite Indian agencies flagging concerns over the use of Chinese made telecom equipment.
On April 11, China complained about the Australian decision at the formal meeting of the WTO’s Council for Trade in Goods by highlighting its discriminatory impact on China. To defend itself, Australia may need to invoke Article XXI and argue that the ban fits in under one of the sub-paragraphs (i)-(iii) of clause (2) The report by this panel, may, therefore propel the WTO’s first big foray into cybersecurity and enable it to act as a multi-lateral adjudicator of the critical geo-political issues discussed in this piece.
The history of international law has been a history of powerful nations manipulating its tenets for strategic gain. At the same time, it has been a history of institutional resilience, evolution and change. The World Trade Organisation is no exception. Despite several aspects of the WTO ecosystem being severely flawed with a disparate impact on vulnerable groups in weaker nations, it has been the bulwark of the modern geo-economic order.
By taking the ‘national security’ exception head on, the panel has undertaken a brave act of self-preservation and foiled the utilisation of a dangerous trump card.
RTI Application to BSNL for the list of websites blocked in India
Background
The Government of India draws powers from Section 69A of the Information Technology (IT) Act and the rules issued under it to order Internet Service Providers (ISPs) to block websites and URLs for users. Several experts have questioned the constitutionality of the process laid out in the Information Technology (Procedure and Safeguards for Blocking for Access of Information by Public) Rules, 2009 (hereinafter, “the rules”) [1] since Rule 16 in the regulations allows blocking of websites by the Government and ISPs in secrecy, as it mandates all such orders to be maintained confidentially.
Thus, the law sets up a structure where it is impossible to know the complete list of websites blocked in India and the reasons thereof. Civil society and individual efforts have repeatedly failed to obtain this list. For instance, the Software Freedom Law Centre (SFLC), in August 2017, asked the Ministry of Electronics and Information Technology (MeitY) for the number and list of websites and URLs that are blocked in India. In response, MeitY revealed the number of blocked websites and URLs: 11,422. MeitY refused to share the list of websites blocked by Government orders citing the aforementioned confidentiality provision in the rules (and subsequently citing national security when MeitY’s reply was appealed against by SFLC). In 2017, researchers at the Centre for Internet and Society (CIS) contacted five ISPs, all of which refused to share information about website blocking requests.
Application under the Right to Information (RTI) Act
To
Manohar Lal, DGM(Cordn), Bharat Sanchar Nigam Limited
Room No. 306, Bharat Sanchar Bhawan, H.C.Mathur Lane
Janpath, New Delhi, PIN 110001
Subject: Seeking of Information under RTI Act 2005
Sir,
Kindly arrange to provide the following information under the provisions of RTI Act:
- What are the names and URLs of websites currently blocked by government notification in India?
- Please provide copies of blocking orders issued by the Department of Telecommunications, Ministry of Communications and other competent authorities to block such websites.
Thanking you
Yours faithfully
Akash Sriram
Centre for Internet and Society
The Information sought vide above reference cannot be disclosed vide clause 8(e) and 8(g) of the RTI act which states.
"8(e) - Information, available to a person in his fiduciary relationship, unless the competent authority is satisfied that the larger public interest warrants the disclosure of such information"
“8(g) - Information, the disclosure of which would endanger the life or physical safety of any person or identify the source of information or assistance given in confidence for law enforcement or security purposes"
This is issued with the approval of competent authority.
Workshop on Feminist Information Infrastructure
A group of five researchers, one from Blank Noise and four from Sangama, presented their research on different aspects of feminist infrastructure. The workshop was attended by a diverse group of participants, including activists, academics, and representatives from civil society organisations and trade unions.
Feminist infrastructure is a broadly conceptualised term referring to infrastructure that is designed by, and keeping in mind the needs of, diverse social groups with different kinds of marginality. In the field of technology, efforts to conceptualise feminist infrastructure have ranged from rethinking basic technological infrastructure, such as feminist spectrum , to community networks and tools for mobilisation . This project aimed to explore the imagination of feminist infrastructure in the context of different marginalities and lived experiences. Rather than limiting intersectionality to the subject of the research, as with most other feminist projects, this project aimed to produce knowledge from the ‘standpoint’ of those with the lived experience of marginalisation.
This report by Ambika Tandon was edited by Gurshabad Grover and designed by Saumyaa Naidu. The full report can be downloaded here.
Announcement of a Three-Region Research Alliance on the Appropriate Use of Digital Identity
As governments across the globe are implementing new, digital foundational identification systems or modernizing existing ID programs, there is a dire need for greater research and discussion about appropriate design choices for a digital identity framework. There is significant momentum on digital ID, especially after the adoption of UN Sustainable Development Goal 16.9, which calls for legal identity for all by 2030. Given the importance of this subject, its implications for both the development agenda as well its impact on civil, social and economic rights, there is a need for more focused research that can enable policymakers to take better decisions, guide civil society in different jurisdictions to comment on and raise questions about digital identity schemes, and provide actionable material to the industry to create identity solutions that are privacy enhancing and inclusive.
Excerpt from the blog post by Subhashish Bhadra announcing this new research alliance
...In the absence of any widely-accepted thinking on this issue, we run the risk of digital identity systems suffering from mission creep, that is being made mandatory or being used for an ever-expanding set of services. We believe this creates several risks. First, people may be excluded from services if they do not have a digital identity or because it malfunctions. Second, this approach creates a wider digital footprint that can be used to create a profile of an individual, sometimes without consent. This can increase privacy risk. Third, this approach increases the power of institutions versus individuals and can be used as rationale to intentionally deny services, especially to vulnerable or persecuted groups.
Three exceptional research groups have undertaken the effort of answering this complex and important question. Over the next six months, these think tanks will conduct independent research, as well as involve experts from across the globe. Based in South America, Africa, and Asia, these institutions represent the collective wisdom and experiences of three very distinct geographies in emerging markets. While drawing on their local context, this research effort is globally oriented. The think tanks will create a set of recommendations and tools that can be used by stakeholders to engage with digital identity systems in any part of the world...
This research will use a collaborative and iterative process. The researchers will put out some ideas every few weeks, with the objective of seeking thoughts, questions, and feedback from various stakeholders. They will participate in several digital rights and identity events across the globe over the next several months. They will also organize webinars to seek input from and present their interim findings to interested communities from across the globe. Each of these provide an opportunity for you to provide your thoughts and help this research program provide an independent, rigorous, transparent, and holistic answer to the question of when it’s appropriate for digital identity to be used. We need a diversity of viewpoints and collaborative dissent to help solve the most pressing issues of our times.
Picking ‘Wholes’ - Thinking in Systems Workshop
It was organised as part of the Digital Identity project to explore the use of system’s thinking approach in a digital identity system, and addressing questions of policy choices and uses, while creating such a system. The workshop was attended by Amber Sinha, Ambika Tandon, Anubha Sinha, Pooja Saxena, Radhika Radhakrishnan, Saumyaa Naidu, Shruti Trikanad, Shyam Ponappa, Sumandro Chattapadhyay, Sunil Abraham, Swati Gautam, and Yesha Paul.
Dinesh Korjan is a proponent of the strategic use of design for the larger good. He is a product designer and co-founder of Studio Korjan in Ahmedabad. He complements his practice with active engagement in academics and teaches at many leading design schools including NID, Ahmedabad, Indian Institute of Technology (IIT), Gandhinagar, Srishti School of Art Design & Technology, Bangalore, and CEPT University, Ahmedabad.
The masterclass was aimed at learning to address complex problems using systems thinking approach. It involved experiential and collaborative learning through discussions, and doing and making activities. The workshop began with identifying different actors, processes, institutions, and other entities involved in a complex problem. The method of role-playing was introduced to learn to detail out and map the problem. Concepts such as synergy/ emergence, relationships, and flows were introduced through examples and case studies. These concepts were applied while mapping complex problems to find insights such as patterns, purposes, feedback loops, and finally a leverage. The workshop also introduced the idea of ephemeralization. Participants were prompted to find solutions that require least input but have greatest impact.
For further reading click here
The Impact of Consolidation in the Internet Economy on the Evolution of the Internet
Edited by Swaraj Barooah, Elonnai Hickok and Vishnu Ramachandran. Inputs by Swagam Dasgupta
This report is a summary of the proceedings of the roundtables organized by the Centre for Internet and Society in partnership with the Internet Society on the impact of consolidation in the Internet economy. It was conducted under the Chatham House Rule, at The Energy and Resource Institute, Bangalore on the 29 June 2018 from 11AM to 4PM. This report was authored on 29 June 2018, and subsequently edited for readability on 25 June 2019. This report contributed to the Internet Society’s 2019 Global Internet Report on Consolidation in the Internet Economy.
The roundtables aimed to analyze how growing forces of consolidation, including concentration, vertical and horizontal integration, and barriers to market entry and competition would influence the Internet in the next 3 to 5 years.
To provide for sufficient investigation, the discussions were divided across two sessions. The focus of the first group was the impact of consolidation on applicable regulatory andpolicy norms including regulation of internet services, the potential to secure or undermine people’s ability to choose services, and the overall impact on the political economy. Thesecond discussion delved into the effect of consolidation on the technical evolution of the internet (in terms of standards, tools and software practices) and consumer choices (interms of standards of privacy, security, other human rights).
The sessions had participants from the private sector (2), research (4), government (1), technical community (3) and civil society organizations (6). Five women and eleven men constituted the participant list.
DIDP #34 On granular detail on ICANN's budget for policy development process
The ICANN budgets are published for public comment yet the community does not have supporting documents to illustrate how the numbers were estimated or the rationale for allocation of the resources. There is a lack of transparency when it comes to the internal budgeting.
This DIDP is concerned with the policy development budget which, as Stephanie Perrin of the Non-Commercial Stakeholder Group pointed out, was merely 5% of ICANN’s total budget, a number significantly low for a policy making organization. Thus, the information we request is a detailed breakdown for the budgets for every Advisory Council as well as Supporting Organizations for the previous fiscal year. You can find the attached request here.
Old Isn't Always Gold: FaceApp and Its Privacy Policies
The article by Mira Swaminathan and Shweta Reddy was published in the Wire on July 20, 2019.
If you, much like a large number of celebrities, have spammed your followers with the images of ‘how you may look in your old age’, you have successfully been a part of the FaceApp fad that has gone viral this week.
The problem with the FaceApp trend isn’t that it has penetrated most social circles, but rather, the fact that it has gone viral with minimal scrutiny of its vaguely worded privacy policy guidelines. We click ‘I agree’ without understanding that our so called ‘explicit consent’ gives the app permission to use our likeness, name and username, for any purpose, without our knowledge and consent, even after we delete the app. FaceApp is currently the most downloaded free app on the Apple Store due to a large number of people downloading the app to ‘turn their old selfies grey’.
There are many things that the app could do. It could process the images on your device, rather than take submitted photos to an outside server. It could also upload your photos to the cloud without making it clear to you that processing is not taking place locally on their device.
Further, if you have an Apple product, the iOS app appears to be overriding your settings even if you have denied access to their camera roll. People have reported that they could still select and upload a photo despite the app not having permission to access their photos. This ‘allowed behaviour’ in iOS is quite concerning, especially when we have apps with loosely worded terms and conditions.
FaceApp responded to these privacy concerns by issuing a statement with a list of defences. The statement clarified that FaceApp performs most of the photo processing in the cloud, that they only upload a photo selected by a user for editing and also confirmed that they never transfer any other images from the phone to the cloud. However, even in their clarificatory statement, they stated that they ‘might’ store an uploaded photo in the cloud and explained that the main reason for that is “performance and traffic”. They also stated that ‘most’ images are deleted from their servers within 48 hours from the upload date.
Further, the statement ends by saying that “all pictures from the gallery are uploaded to our servers after a user grants access to the photos”. This is highly problematic.
We have explained the concerns arising out of the privacy policy with reference to the global gold standards: the OECD Guidelines on the Protection of Privacy and Transborder Flows of Personal Data, APEC Privacy Framework, Report of the Group of Experts on Privacy chaired by Justice A.P. Shah and the General Data Protection Regulation in the table below:
| Privacy Domain | OECD Guidelines | APEC Privacy Framework | Report of the Group of Experts on Privacy | General Data Protection Regulation | FaceApp Privacy Policy |
| Transparency | There should be a general policy of openness about developments, practices and policies with respect to personal data. | Personal information controllers should provide clear and easily accessible statements about their practices and policies with respect to personal data. | A data controller shall give a notice that is understood simply of its information practices to all individuals, in clear and concise language, before any personal information is collected from them. | Transparency:
The controller shall take appropriate measures to provide information relating to processing to the data subject in a concise, transparent, intelligible and easily accessible form, using clear and plain language. Article 29 working party guidelines on Transparency: The information should be concrete and definitive, it should not be phrased in abstract or ambivalent terms or leave room for different interpretations. Example: “We may use your personal data to develop new services” (as it is unclear what the services are or how the data will help develop them); |
Information we collect
“When you visit the Service, we may use cookies and similar technologies”……. provide features to you. We may ask advertisers or other partners to serve ads or services to your devices, which may use cookies or similar technologies placed by us or the third party. “We may also collect similar information from emails sent to our Users..” Sharing your information “We may share User Content and your information with businesses…” “We also may share your information as well as information from tools like cookies, log files..” “We may also combine your information with other information..” |
| A simple reading of the guidelines in comparison with the privacy policy of FaceApp can help us understand that the terms used by the latter are ambiguous and vague. The possibility of a ‘may not’ can have a huge impact on the privacy concerns of the user.
The entire point of ‘transparency’ in a privacy policy is for the user to understand the extent of processing undertaken by the organisation and then have the choice to provide consent. Vague phrases do not adequately provide a clear indication of the extent of processing of personal data of the individual. |
|||||
| Privacy Domain | OECD Guidelines | APEC Privacy Framework | Report of the Group of Experts on Privacy | General Data Protection Regulation | FaceApp Privacy Policy |
| Security Safeguards | Personal data should be protected by reasonable security safeguards against such risks as loss or unauthorised access, destruction, use, modification or disclosure of data | Personal information controllers should protect personal information that they hold with appropriate safeguards against risks, such as loss or unauthorised access to personal information or unauthorised destruction, use, modification or disclosure of information or other misuses. | A data controller shall secure personal information that they have either collected or have in their custody by reasonable security safeguards against loss, unauthorised access, destruction, use, processing, storage, modification, deanonymization, unauthorised disclosure or other reasonably foreseeable risks | The controller and processor shall implement appropriate technical and organisational measures to ensure a level of security appropriate to the risk. | How we store your information
“We use commercially reasonable safeguards to help keep the information collected through the Service secure and take reasonable steps… However, FaceApp cannot ensure the security of any information you transmit to FaceApp or guarantee that information on the Service may not be accessed, disclosed, altered, or destroyed.” |
The obligation of implementing reasonable security measures to prevent unauthorised access and misuse of personal data is placed on the organisations processing such data. FaceApp’s privacy policy assures that reasonable security measures according to commercially accepted standards have been implemented. Despite such assurances, FaceApp’s waiver of the liability by stating that it cannot ensure the security of the information against it being accessed, disclosed, altered or destroyed itself says that the policy is faltered in nature.
The privacy concerns and the issue of transparency (or the lack thereof) in FaceApp are not isolated. After all, as a Buzzfeed analysis of the app noted, while there appeared to be no data going back to Russia, this could change at any time due to its overly broad privacy policy.
The business model of most mobile applications being developed currently relies heavily on personal data collection of the user. The users’ awareness regarding the type of information accessed based on the permissions granted to the mobile application is questionable.
In May 2018, Symantec tested the top 100 free Android and iOS apps with the primary aim of identifying cases where the apps were requesting ‘excessive’ access to information of the user in relation to the functions being performed. The study identified that 89% of Android apps and 39% of the iOS app request for what can be classified as ‘risky’ permissions, which the study defines as permissions where the app requests data or resources which involve the user’s private information, or, could potentially affect the user’s locally stored data or the operation of other apps.
Requesting risky permissions may not on its own be objectionable, provided clear and transparent information regarding the processing, which takes place upon granting permission, is provided to the individuals in the form of a clear and concise privacy notice. The study concluded that 4% of the Android apps and 3% of the iOS apps seeking risky permissions didn’t even have a privacy policy.
The lack of clarity with respect to potentially sensitive user data being siphoned off by mobile applications became even more apparent with the case of a Hyderabad based fintech company that gained access to sensitive user data by embedding a backdoor inside popular apps.
In the case of the Hyderabad-based fintech company, the user data which was affected included GPS locations, business SMS text messages from e-commerce websites and banks, personal contacts, etc. This data was used to power the company’s self-learning algorithms which helped organisations determine the creditworthiness of loan applicants. It is pertinent to note that even when apps have privacy policies, users can still find it difficult to navigate through the long content-heavy documents.
The New York Times, as part of its Privacy Project, analysed the length and readability of privacy policies of around 150 popular websites and apps. It was concluded that the vast majority of the privacy policies that were analysed exceeded the college reading level. Usage of vague language like “adequate performance” and “legitimate interest” and wide interpretation of such phrases allows organisations to use data in extensive ways while providing limited clarity on the processing activity to the individuals.
The Data Protection Authorities operating under the General Data Protection Regulation are paying close attention to openness and transparency of processing activities by organisations. The French Data Protection Authority fined Google for violating their obligations of transparency and information. The UK’s Information Commissioner’s office issued an enforcement notice to a Canadian data analytics firm for failing to provide information in a transparent manner to the data subject.
Thus, in the age of digital transformation, the unwelcome panic caused by FaceApp should be channelled towards a broader discussion on the information paradox currently existing between individuals and organisations. Organisations need to stop viewing ambiguous and opaque privacy policies as a get-out-of-jail-free card. On the contrary, a clear and concise privacy policy outlining the details related to processing activity in simple language can go a long way in gaining consumer trust.
The next time an “AI-based Selfie App” goes viral, let’s take a step back and analyse how it makes use of user-provided data and information both over and under the hood, since if data is the new gold, we can easily say that we’re in the midst of a gold rush.
What is the problem with ‘Ethical AI’? An Indian Perspective
The article by Arindrajit Basu and Pranav M.B. was published by cyberBRICS on July 17, 2019.
This was followed by the G20 adopted human-centred AI Principles on June 9th. These are the latest in a slew of (at least 32!) public, and private ‘Ethical AI’ initiatives that seek to use ethics to guide the development, deployment and use of AI in a variety of use cases. They were conceived as a response to a range of concerns around algorithmic decision-making, including discrimination, privacy, and transparency in the decision-making process.
In India, a noteworthy recent document that attempts to address these concerns is the National Strategy for Artificial Intelligence published by the National Institution for Transforming India, also called NITI Aayog, in June 2018. As the NITI Aayog Discussion paper acknowledges, India is the fastest growing economy with the second largest population in the world and has a significant stake in understanding and taking advantage of the AI revolution. For these reasons the goal pursued by the strategy is to establish the National Program on AI, with a view to guiding the research and development in new and emerging technologies, while addressing questions on ethics, privacy and security.
While such initiatives and policy measures are critical to promulgating discourse and focussing awareness on the broad socio-economic impacts of AI, we fear that they are dangerously conflating tenets of existing legal principles and frameworks, such as human rights and constitutional law, with ethical principles – thereby diluting the scope of the former. While we agree that ethics and law can co-exist, ‘Ethical AI’ principles are often drafted in a manner that posits as voluntary positive obligations various actors have taken upon themselves as opposed to legal codes they necessarily have to comply with.
To have optimal impact, ‘Ethical AI’ should serve as a decision-making framework only in specific instances when human rights and constitutional law do not provide a ready and available answer.
Vague and unactionable
Conceptually, ‘Ethical AI’ is a vague set of principles that are often difficult to define objectively. In this perspective, academics like Brett Mittelstadt of the Oxford Internet Institute argues that unlike in the field of medicine – where ethics has been used to design a professional code, ethics in AI suffers from four core flaws. First, developers lack a common aim or fiduciary duty to a consumer, which in the case of medicine is the health and well-being of the patient. Their primary duty lies to the company or institution that pays their bills, which often prevents them from realizing the extent of the moral obligation they owe to the consumer.
The second is a lack of professional history which can help clarify the contours of well-defined norms of ‘good behaviour.’ In medicine, ethical principles can be applied to specific contexts by considering what similarly placed medical practitioners did in analogous past scenarios. Given the relative nascent emergence of AI solutions, similar professional codes are yet to develop.
Third is the absence of workable methods or sustained discourse on how these principles may be translated into practice. Fourth, and we believe most importantly, in addition to ethical codes, medicine is governed by a robust and stringent legal framework and strict legal and accountability mechanisms, which are absent in the case of ‘Ethical AI’. This absence gives both developers and policy-makers large room for manoeuvre.
However, such focus on ethics may be a means of avoiding government regulation and the arm of the law. Indeed, due to its inherent flexibility and non-binding nature, ethics can be exploited as a piecemeal red herring solution to the problems posed by AI. Controllers of AI development are often profit-driven private entities, that gain reputational mileage by using the opportunity to extensively deliberate on broad ethical notions.
Under the guise of meaningful ‘self-regulation’, several organisations publish internal ‘Ethical AI’ guidelines and principles, and fund ethics research across the globe. In doing so, they occlude the shackles of binding obligation and deflect from attempts at tangible regulation.
Comparing Law to Ethics
This is in contrast to the well-defined jurisprudence that human rights and constitutional law offer, which should serve as the edifice of data-driven decision making in any context.
In the table below, we try to explain this point by looking at how three core fundamental rights enshrined both in our constitution and human rights instruments across the globe-right to privacy, right to equality/right against discrimination and due process-find themselves captured in three different sets of ‘Ethical AI frameworks.’ One of these inter-governmental (OECD), one devised by a private sector actor (‘Google AI’) and one by our very own, NITI AAYOG.
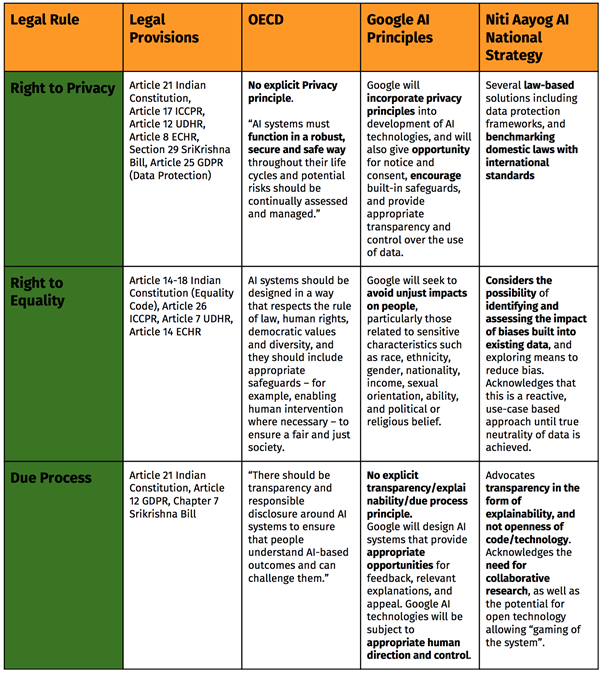
With the exception of certain principles,most ‘Ethical AI’ principles are loosely worded as ‘‘seek to avoid’, ‘give opportunity for’, or ‘encourage’. A notable exception is the NITI AAYOG’s approach to protecting privacy in the context of AI. The document explicitly recommends the establishment of a national data protection framework for data protection, sectoral regulations that apply to specific contexts with the consideration of international standards such as GDPR as benchmarks. However, it fails to reference available constitutional standards when it discusses bias or explainability.
Several similar legal rules that have been enshrined in legal provisions -outlined and elucidated through years of case law and academic discourse – can be utilised to underscore and guide AI principles. However, existing AI principles do not adequately articulate how the legal rule can actually be applied to various scenarios by multiple organisations.
We do not need a new “Law of Artificial Intelligence” to regulate this space. Judge Frank Easterbrook’s famous 1996 proclamation on the ‘Law of the Horse’ through which he opposed the creation of a niche field of ‘cyberspace law’ comes to mind. He argued that a multitude of legal rules deal with ‘horses’, including the sale of horses, individuals kicked by horses, and with the licensing and racing of horses. Like with cyberspace, any attempt to arrive at a corpus of specialised ‘law of the horse’ would be shallow and ineffective.
Instead of fidgeting around for the next shiny regulatory tool, industry, practitioners, civil society and policy makers need to get back to the drawing board and think about applying the rich corpus of existing jurisprudence to AI governance.
What is the role for ‘Ethical AI?’
What role can ‘ethical AI’ then play in forging robust and equitable governance of Artificial Intelligence? As it does in all other societal avenues, ‘ethical AI’ should serve as a framework for making legitimate algorithmic decisions in instances where law might not have an answer. An example of such a scenario is the Project Maven saga – where 3,000 Google employees signed a petition opposing Google’s involvement with a US Department of Defense project by claiming that Google should not be involved in “the business of war.” There is no law-international or domestic that suggests that Project Maven-which was designed to study battlefield imagery using AI, was illegal. However, the debate at Google proceeded on ethical grounds and on the application of the ‘Ethical AI’ principles to this present context.
We realise the importance of social norms and mores in carving out any regulatory space. We also appreciate the role of ethics in framing these norms for responsible behaviour. However, discourse across civil society, academic, industry and government circles all across the globe needs to bring law back into the discussion as a framing device. Not doing so risks diluting the debate and potential progress to a set of broad, unactionable principles that can easily be manipulated for private gain at the cost of public welfare.
India is falling down the facial recognition rabbit hole
The article by Prem Sylvester and Karan Saini was published in the Wire on July 23, 2019.
In a discomfiting reminder of how far technology can be used to intrude on the lives of individuals in the name of security, the Ministry of Home Affairs, through the National Crime Records Bureau, recently put out a tender for a new Automated Facial Recognition System (AFRS).
The stated objective of this system is to “act as a foundation for a national level searchable platform of facial images,” and to “[improve] outcomes in the area of criminal identification and verification by facilitating easy recording, analysis, retrieval and sharing of Information between different organizations.”
The system will pull facial image data from CCTV feeds and compare these images with existing records in a number of databases, including (but not limited to) the Crime and Criminal Tracking Networks and Systems (or CCTNS), Interoperable Criminal Justice System (or ICJS), Immigration Visa Foreigner Registration Tracking (or IVFRT), Passport, Prisons, Ministry of Women and Child Development (KhoyaPaya), and state police records.
Furthermore, this system of facial recognition will be integrated with the yet-to-be-deployed National Automated Fingerprint Identification System (NAFIS) as well as other biometric databases to create what is effectively a multi-faceted system of biometric surveillance.
It is rather unfortunate, then, that the government has called for bids on the AFRS tender without any form of utilitarian calculus that might justify its existence. The tender simply states that this system would be “a great investigation enhancer.”
This confidence is misplaced at best. There is significant evidence that not only is a facial recognition system, as has been proposed, ineffective in its application as a crime-fighting tool, but it is a significant threat to the privacy rights and dignity of citizens. Notwithstanding the question of whether such a system would ultimately pass the test of constitutionality – on the grounds that it affects various freedoms and rights guaranteed within the constitution – there are a number of faults in the issued tender.
Let us first consider the mechanics of a facial recognition system itself. Facial recognition systems chain together a number of algorithms to identify and pick out specific, distinctive details about a person’s face – such as the distance between the eyes, or shape of the chin, along with distinguishable ‘facial landmarks’. These details are then converted into a mathematical representation known as a face template for comparison with similar data on other faces collected in a face recognition database. There are, however, several problems with facial recognition technology that employs such methods.
Facial recognition technology depends on machine learning – the tender itself mentions that the AFRS is expected to work on neural networks “or similar technology” – which is far from perfect. At a relatively trivial level, there are several ways to fool facial recognition systems, including wearing eyewear, or specific types of makeup. The training sets for the algorithm itself can be deliberately poisoned to recognise objects incorrectly, as observed by students at MIT.
More consequentially, these systems often throw up false positives, such as when the face recognition system incorrectly matches a person’s face (say, from CCTV footage) to an image in a database (say, a mugshot), which might result in innocent citizens being identified as criminals. In a real-time experiment set in a train station in Mainz, Germany, facial recognition accuracy ranged from 17-29% – and that too only for faces seen from the front – and was at 60% during the day but 10-20% at night, indicating that environmental conditions play a significant role in this technology.
Facial recognition software used by the UK’s Metropolitan Police has returned false positives in more than 98% of match alerts generated.
When the American Civil Liberties Union (ACLU) used Amazon’s face recognition system, Rekognition, to compare images of legislative members of the American Congress with a database of mugshots, the results included 28 incorrect matches.
There is another uncomfortable reason for these inaccuracies – facial recognition systems often reflect the biases of the society they are deployed in, leading to problematic face-matching results. Technological objectivity is largely a myth, and facial recognition offers a stark example of this.
An MIT study shows that existing facial recognition technology routinely misidentifies people of darker skin tone, women and young people at high rates, performing better on male faces than female faces (8.1% to 20.6% difference in error rate), lighter faces than darker faces (11.8% to 19.2% difference in error rate) and worst on darker female faces (20.8% to 34.7% error rate). In the aforementioned ACLU study, the false matches were disproportionately people of colour, particularly African-Americans. The bias rears its head when the parameters of machine-learning algorithms, derived from labelled data during a “supervised learning” phase, adhere to socially-prejudiced ideas of who might commit crimes.
The implications for facial recognition are chilling. In an era of pervasive cameras and big data, such prejudice can be applied at unprecedented scale through facial recognition systems. By replacing biased human judgment with a machine learning technique that embeds the same bias, and more reliably, we defeat any claims of technological neutrality. Worse, because humans will assume that the machine’s “judgment” is not only consistently fair on average but independent of their personal biases, they will read agreement of its conclusions with their intuition as independent corroboration.
In the Indian context, consider that Muslims, Dalits, Adivasis and other SC/STs are disproportionately targeted by law enforcement. The NCRB in its 2015 report on prison statistics in India recorded that over 55% of the undertrials prisoners in India are either Dalits, Adivasis or Muslims, a number grossly disproportionate to the combined population of Dalits, Adivasis and Muslims, which amounts to just 39% of the total population according to the 2011 Census.
If the AFRS is thus trained on these records, it would clearly reinforce socially-held prejudices against these communities, as inaccurately representative as they may be of those who actually carry out crimes. The tender gives no indication that the developed system would need to eliminate or even minimise these biases, nor if the results of the system would be human-verifiable.
This could lead to a runaway effect if subsequent versions of the machine-learning algorithm are trained with criminal convictions in which the algorithm itself played a causal role. Taking such a feedback loop to its logical conclusion, law enforcement may use machine learning to allocate police resources to likely crime spots – which would often be in low income or otherwise vulnerable communities.
Adam Greenfield writes in Radical Machines on the idea of ‘over transparency,’ that combines “bias” of the system’s designers as well of the training sets – based as these systems are on machine learning – and “legibility” of the data from which patterns may be extracted. The “meaningful question,” then, isn’t limited to whether facial recognition technology works in identification – “[i]t’s whether someone believes that they do, and acts on that belief.”
The question thus arises as to why the MHA/NCRB believes this is an effective tool for law enforcement. We’re led, then, to another, larger concern with the AFRS – that it deploys a system of surveillance that oversteps its mandate of law enforcement. The AFRS ostensibly circumvents the fundamental right to privacy, as ratified by the Supreme Court in 2018, through sourcing its facial images from CCTV cameras installed in public locations, where the citizen may expect to be observed.
The extent of this surveillance is made even clearer when one observes the range of databases mentioned in the tender for the purposes of matching with suspects’ faces extends to “any other image database available with police/other entity” besides the previously mentioned CCTNS, ICJS et al. The choice of these databases makes overreach extremely viable.
This is compounded when we note that the tender expects the system to “[m]atch suspected criminal face[sic] from pre-recorded video feeds obtained from CCTVs deployed in various critical identified locations, or with the video feeds received from private or other public organization’s video feeds.” There further arises a concern with regard to the process of identification of such “critical […] locations,” and if there would be any mechanisms in place to prevent this from being turned into an unrestrained system of surveillance, particularly with the stated access to private organisations’ feeds.
The Perpetual Lineup report by Georgetown Law’s Center on Privacy & Technology identifies real-time (and historic) video surveillance as posing a very high risk to privacy, civil liberties and civil rights, especially owing to the high-risk factors of the system using real-time dragnet searches that are more or less invisible to the subjects of surveillance.
It is also designated a “Novel Use” system of criminal identification, i.e., with little to no precedent as compared to fingerprint or DNA analysis, the latter of which was responsible for countless wrongful convictions during its nascent application in the science of forensic identification, which have since then been overturned.
In the Handbook of Face Recognition, Andrew W. Senior and Sharathchandra Pankanti identify a more serious threat that may be born out of automated facial recognition, assessing that “these systems also have the potential […] to make judgments about [subjects’] actions and behaviours, as well as aggregating this data across days, or even lifetimes,” making video surveillance “an efficient, automated system that observes everything in front of any of its cameras, and allows all that data to be reviewed instantly, and mined in new ways” that allow constant tracking of subjects.
Such “blanket, omnivident surveillance networks” are a serious possibility through the proposed AFRS. Ye et al, in their paper on “Anonymous biometric access control”, show how automatically captured location and facial image data obtained from cameras designed to track the same can be used to learn graphs of social networks in groups of people.
Consider those charged with sedition or similar crimes, given that the CCTNS records the details as noted in FIRs across the country. Through correlating the facial image data obtained from CCTVs across the country – the tender itself indicates that the system must be able to match faces obtained from two (or more) CCTVs – this system could easily be used to target the movements of dissidents moving across locations.
Constantly watched
Further, something which has not been touched upon in the tender – and which may ultimately allow for a broader set of images for carrying out facial recognition – is the definition of what exactly constitutes a ‘criminal’. Is it when an FIR is registered against an individual, or when s/he is arrested and a chargesheet is filed? Or is it only when an individual is convicted by a court that they are considered a criminal?
Additionally, does a person cease to be recognised by the tag of a criminal once s/he has served their prison sentence and paid their dues to society? Or are they instead marked as higher-risk individuals who may potentially commit crimes again? It could be argued that such a definition is not warranted in a tender document, however, these are legitimate questions which should be answered prior to commissioning and building a criminal facial recognition system.
Senior and Pankanti note the generalised metaphysical consequences of pervasive video surveillance in the Handbook of Face Recognition:
“the feeling of disquiet remains [even if one hasn’t committed a major crime], perhaps because everyone has done something “wrong”, whether in the personal or legal sense (speeding, parking, jaywalking…) and few people wish to live in a society where all its laws are enforced absolutely rigidly, never mind arbitrarily, and there is always the possibility that a government to which we give such powers may begin to move towards authoritarianism and apply them towards ends that we do not endorse.”
Such a seemingly apocalyptic scenario isn’t far-fetched. In the section on ‘Mandatory Features of the AFRS’, the system goes a step further and is expected to integrate “with other biometric solution[sic] deployed at police department system like Automatic Fingerprint identification system (AFIS)[sic]” and “Iris.” This form of linking of biometric databases opens up possibilities of a dangerous extent of profiling.
While the Aadhaar Act, 2016, disallows Aadhaar data from being handed over to law enforcement agencies, the AFRS and its linking with biometric systems (such as the NAFIS) effectively bypasses the minimal protections from biometric surveillance the prior unavailability of Aadhaar databases might have afforded. The fact that India does not have a data protection law yet – and the Bill makes no references to protection against surveillance either – deepens the concern with the usage of these integrated databases.
The Perpetual Lineup report warns that the government could use biometric technology “to identify multiple people in a continuous, ongoing manner [..] from afar, in public spaces,” allowing identification “to be done in secret”. Senior and Pankanti warn of “function creep,” where the public grows uneasy as “silos of information, collected for an authorized process […] start being used for purposes not originally intended, especially when several such databases are linked together to enable searches across multiple domains.”
This, as Adam Greenfield points out, could very well erode “the effectiveness of something that has historically furnished an effective brake on power: the permanent possibility that an enraged populace might take to the streets in pursuit of justice.”
What the NCRB’s AFRS amounts to, then, is a system of public surveillance that offers little demonstrable advantage to crime-fighting, especially as compared with its costs to fundamental human rights of privacy and the freedom of assembly and association. This, without even delving into its implications with regard to procedural law. To press on with this system, then, would be indicative of the government’s lackadaisical attitude towards protecting citizens’ freedoms.
The views expressed by the authors in this article are personal.
The Digital Identification Parade
The article by Aayush Rathi and Ambika Tandon was published in the Indian Express on July 29, 2019. The authors acknowledge Sumandro Chattapadhyay, Amber Sinha and Arindrajit Basu for their edits and Karan Saini for his inputs.
The National Crime Records Bureau recently issued a request for proposals for the procurement of an Automated Facial Recognition System (AFRS). The stated objective of the AFRS is to “identify criminals, missing persons/children, unidentified dead bodies and unknown traced children/persons”. It will be designed to compare images against a “watchlist” curated using images from “any […] image database available with police/other entity”, and “newspapers, raids, sent by people, sketches, etc.” The integration of diverse databases indicates the lack of a specific purpose, with potential for ad hoc use at later stages. Data sharing arrangements with the vendor are unclear, raising privacy concerns around corporate access to sensitive information of crores of individuals.
While a senior government official clarified that the AFRS will only be used against the integrated police database in India — the Crime and Criminal Tracking Network and Systems (CCTNS) — the tender explicitly states the integration of several other databases, including the passport database, and the National Automated Fingerprint Identification System. This is hardly reassuring. Even a targeted database like the CCTNS risks over-representation of marginalised communities, as has already been witnessed in other countries. The databases that the CCTNS links together have racial and colonial origins, recording details of unconvicted persons if they are found to be “suspicious”, based on their tribe, caste or appearance. However, including other databases puts millions of innocent individuals on the AFRS’s watchlist. The objective then becomes to identify “potential criminals” — instead of being “presumed innocent”, we are all persons-who-haven’t-been-convicted-yet.
The AFRS may allow indiscriminate searching by tapping into publicly and privately installed CCTVs pan-India. While facial recognition technology (FRT) has proliferated globally, only a few countries have systems that use footage from CCTVs installed in public areas. This is the most excessive use of FRT, building on its more common implementation as border technology. CCTV cameras are already rife with cybersecurity issues, and integration with the AFRS will expand the “attack surface” for exploiting vulnerabilities in the AFRS. Additionally, the AFRS will allow real-time querying, enabling “continuous” mass surveillance. Misuse of continuous surveillance has been seen in China, with the Uighurs being persecuted as an ethnic minority.
FRT differs from other biometric forms of identification (such as fingerprints, DNA samples) in the degree and pervasiveness of surveillance that it enables. It is designed to operate at a distance, without any knowledge of the targeted individual(s). It is far more difficult to prevent an image of one’s face from being captured, and allows for the targeting of multiple persons at a time. By its very nature, it is a non-consensual and covert surveillance technology.
Potential infringements on the right to privacy, a fundamental right, could be enormous as FRT allows for continuous and ongoing identification. Further, the AFRS violates the legal test of proportionality that was articulated in the landmark Puttaswamy judgment, with constant surveillance being used as a strategy for crime detection. Other civil liberties such as free speech and the right to assemble peacefully could be implicated as well, as specific groups of people such as dissidents and protests can be targeted.
Moreover, facial recognition technology has not performed well as a crime detection technology. Challenges arise at the stage of input itself. Variations in pose, illumination, and expression, among other factors, adversely impact the accuracy of automated facial analysis. In the US, law enforcement has been using images from low-quality surveillance feed as probe photos, leading to erroneous matches. A matter of concern is that several arrests have been made solely on the basis of likely matches returned by FRT.
Research indicates that default camera settings better expose light skin than dark, which affects results for FRT across racial groups. Moreover, the software could be tested on certain groups more often than others, and could consequently be more accurate in identifying individuals from that group. The AFRS is envisioned as having both functionalities of an FRT — identification of an individual, and social classification — with the latter holding significant potential to misclassify minority communities.
In the UK, after accounting for a host of the issues outlined above, the Science and Technology Committee, comprising 14 sitting MPs, recently called for a moratorium on deploying live FRT. It will be prudent to pay heed to this directive in India, in the absence of any framework around data protection, or the use of biometric technologies by law enforcement.
The experience of law enforcement’s use of FRT globally, and the unique challenges posed by the usage of live FRT demand closer scrutiny into how it can be regulated. One approach may be to use a technology-neutral regulatory framework that identifies gradations of harms. However, given the history of political surveillance by the Indian state, a complete prohibition on FRT may not be too far-fetched.
In India, Privacy Policies of Fintech Companies Pay Lip Service to User Rights
The article by Shweta Mohandas highlighting the key observations in Fintech study conducted by CIS was published in the Wire on July 30, 2019.
Earlier this month, an investigation revealed that a Hyderabad-based fintech company called CreditVidya was sneakily collecting user data through their devotional and music apps to assess people’s creditworthiness.
This should be unsurprising as the privacy policies of most Indian fintech companies do not specify who they will be sharing the information with. Instead, they employ vague terminology to identify sharing arrangements such as ‘third-party’, ‘affiliates’ etc.
This is one of the many findings that we came across while analysing the privacy policies of 48 fintech companies that operate in India.
The study looked at how the privacy policies complied with the requirements of the existing data protection regime in India – the Information Technology (Reasonable Security Practices and Procedures and Sensitive Personal Data or Information) Rules, 2011.
The IT Rules, among other things, require that privacy policies specify the type of data being used, the purpose of collection, the third parties the data will be shared with, the option to withdraw consent and the grievance redressal mechanism.
The rules also require the privacy policy to be easily accessible as well as easy to understand. The problem is that they are not as comprehensive and specific as, say, the draft Personal Data Protection Bill, which is awaiting passage through parliament, and hence require the companies to do much less than privacy and data protection practices emerging globally.
Nevertheless, despite the limited requirements, none of the companies in our sample of 48 were fully compliant with the parameters set by the IT Rules.
While 95% of the companies did fulfil the basic requirement of actually formulating and having a privacy policy, two major players stood out as defaulters: Airtel Payments Bank and Bhim UPI, for which we were not able to locate a privacy policy.
Though a majority of the privacy policies contained the statement “we take your privacy and security seriously”, 43% of the companies did not provide adequate details of the reasonable security practices and procedures followed.
The requirement in which most companies did not provide information for was regarding a grievance redressal mechanism, where only 10% of the companies comply.
While 31% of the companies provided the contact of a grievance redressal officer (some without even mentioning the redressal mechanism), 37% of the companies provided contact details of a representative but did not specify if this person could be contacted in case of any grievance.
Throughout the study, it was noted that the wording of the IT Rules allowed companies to use ambiguous terms to ensure compliance without exposing their actual data practices. For example, Rule 5 (7) requires a fintech company to provide an option to withdraw consent. Twenty three percent of the companies allowed the user to opt out or withdraw from certain services such as mailing list, direct marketing and in app public forums but they did not allow the user to withdraw their consent completely. While several of 17 companies did provide the option to withdraw consent, they did not clarify whether the withdrawal also meant that the user’s data was no processed or shared.
However, when it came to data retention, most of the 27 companies that provided some degree of information about the retention policy stated that some data would be stored for perpetuity either for analytics or for complying with law enforcement. The remaining 21 companies say nothing about their data retention policy.
In local languages
The issue of ambiguity most clearly arises when the user is actually able to cross the first hurdle – reading an app’s privacy policy.
With fintech often projected as one of the drivers of greater financial inclusion in India, it is telling that only one company (PhonePe) had the option to read the privacy policy in a language other than English. With respect to readability, we noted that the privacy policies were difficult to follow not just because of legalese and length, but also because of fonts and formatting – smaller and lighter texts, no distinction between paragraphs etc. added to the disincentive to read the privacy policy.
Privacy policies act as a notice to individuals about the terms on which their data will be treated by the entity collecting data. However, they are a monologue in terms of consent where the user only has the option to either agree to it or decline and not avail the services. Moreover, even the notice function is not served when the user is unable to read the privacy policy.
They, thus, serve as mere symbols of compliance, where they are drafted to ensure bare minimum conformity to legal requirements. However, the responsibility of these companies lies in giving the user the autonomy to provide an informed consent as well as to be notified in case of any change in how the data is being handled (this could be when and whom the data is being shared with, if there has been a breach etc).
With the growth of fintech companies and the promise of financial inclusion, it is imperative that the people using these services make informed decisions about their data. The draft Personal Data Protection Bill – in its current form – would encumber companies processing sensitive personal data with greater responsibility and accountability than before. However, the Bill, similar to the IT Rules, endorses the view of blanket consent, where the requirement for change in data processing is only of periodic notice (Section 30 (2)), a lesson that needs to be learnt from the CreditVidya story.
In addition to blanket consent, the SPD/I Rules and well as the PDP Bill does not require the user to be notified in all cases of a breach. While the information that is provided to data subjects is necessary to be designed keeping the user in mind, neither the SPD/I Rules, nor the PDP Bill take into account the manner in which data flows operate in the context of ‘disruptive’ business models that are a hallmark of the ‘fintech revolution’.
Event Report: Community Discussion on Open Standards
Open standards are important for the growth and evolution of technology and practices for consumers and industries. They provide a range of tangible benefits, including, for instance, a reduction in cost of development for small businesses and organizations, facilitation of interoperability across different technologies in certain cases, and encouragement of competitiveness in the software and services market. Open standardization also encourages innovation, expansion in market access, transparency — along with a decrease in regulatory rigidity, as well as volatility in the market, and subsequently the surrounding economy, as well.
The importance of open standards is perhaps most strikingly evident when considering the ardent growth and impact the Internet — and the World Wide Web in particular — have been able to enjoy. The modern Internet has arguably been governed, at least for the most part, by the continuous development and maintenance of an array of inventive protocols and technical standards. Open standards are usually developed in a public-consultancy process, where the standards development organizations (“SDOs”) involved follow a multi-stakeholder model of decision-making. Multi-stakeholder models like this ensure equity to groups with varying interests, and also ensures that any resulting technology, protocol or standard which is developed is in accordance with the general consensus of those involved.
This event report highlights a community discussion on the state of open standardization in the age where immediately accessible cloud computing services are readily available to consumers — along with an imagined roadmap for the future; one which ensures steady ground for users as well as the open standards and open source software communities. Participants in the discussion focused on what they believed to be the key areas of open standardization, establishing a requirement for regulatory action in the open standards domain, while also touching upon the effects of market forces on stakeholders within the ecosystem, which ultimately guide the actions of software companies, service providers, users, and other consumers.
The event report can be accessed here.
Comments on the National Digital Health Blueprint
This submission presents comments by the Centre for Internet and Society (CIS), on the National Digital Health Blueprint (NDHB) Report, released on 15th July 2019 for publicconsulations. It must be noted at the outset that the time given for comments was less than three weeks, and such a short window of time is inadequate for all stakeholdersinvolved to comprehensively address the various aspects of the Report. Accordingly, on behalf of all other interested parties, we request more time for consultations.
We also note that the nature of data which would be subject to processing in the proposed digital framework pre-supposes a robust data protection regime in India, onewhich is currently absent. Accordingly, we also urge ceasing the implementation of the framework until the Personal Data Protection Bill is passed by the parliament. We wouldbe explaining our reasonings on this particular point below.
Click to download the full submission here.
Private Sector and the cultivation of cyber norms in India
The article by Arindrajit Basu was published by Nextrends India on August 5, 2019.
While the United Nations ‘Group of Governmental experts’ (GGE), tried and failed to establish a common law for governing the behavior of states in cyberspace, it is Big Tech who led the discussions on cyberspace regulations. Microsoft’s Digital Geneva Convention which devised a set of rules to protect civilian use of the internet was a notable initiative on that front. Microsoft was also a major driver of the Tech Accords — a public commitment made by over 100 companies “agreeing to defend all customers everywhere from malicious attacks by cyber-criminal enterprises and nation-states.” The Paris Call for Trust and Security in Cyberspace was a joint effort between the French government and Microsoft that brought in (as of today) 66 states, 347 private sector entities, including Indian business guilds such as FICCI and the Mobile Association of India and 139 organisations from civil society and academia from all over the globe.
However, the entry of Big tech into the business of framing regulation has raised eyeballs across jurisdictions. In India, the government has attempted to push back on the global private sector due to arguably extractive economic policies adopted by them, alongside the threats they pose to India’s democratic fabric. The Indian government has taken various steps to constrain Big Tech, although some of these policies have been hastily rolled out and fail to address the root of the problem.
I have identified two regulatory interventions that illustrate this trend. First, on intermediary liability, Rule 3(9) of the Draft of the Information Technology 2018 released by the Ministry of Electronics and Information Technology (MeiTy) last December. The rule follows the footsteps of countries like Germany and France by mandating that platforms use “automated tools or appropriate mechanisms, with appropriate controls, for proactively identifying and removing or disabling public access to unlawful information or content.” These regulations have resulted in criticism from both the private sector and civil society as they fail to address concerns around algorithmic discrimination, excessive censorship and gives the government undue power. Further, the regulations paint all the intermediaries with the same brush, thus not differentiating between platforms such as Whatsapp who thrive on end-to-end encryption and public platforms like Facebook.
Another source of discord between the government and the private sector has been the government’s localisation mandate, featuring in a slew of policies. Over the past year, the Indian government has introduced a range of policy instruments which
demand that certain kinds of data must be stored in servers located physically within India — termed “data localization.”
While this serves a number of policy objectives, the two which stand out are (1) the presently complex process for Indian law enforcement agencies to access data stored in the U.S. during criminal investigations, and (2) extractive economic models used by U.S. companies operating in India.
A study I co-authored earlier this year on the issue found that foreign players and smaller Indian private sector players were against this move due to the high compliance costs in setting up data centres.
On this question, we recommended a dual approach that involves mandatory sectoral localisation for critical sectors such as defense or payments data while adopting ‘conditional’ localisation for all other data. Under ‘conditional localisation,’
data should only be transferred to countries that (1)Agree to share the personal data of Indian citizens with law enforcement authorities based on Indian criminal procedure laws and (2) Have equivalent privacy and security safeguards.
These two instances demonstrate that it is important for the Indian government to engage with both the domestic and foreign private sector to carve out optimal regulatory interventions that benefit the Indian consumer and the private sector as a whole rather than a few select big players. At the same time, it is important for the private sector to be a responsible stakeholder and comply both with existing laws and accepted norms of ‘good behaviour.’
Going forward, there is no denying the role of the private sector in the development of emerging technologies. However, a balance must be struck through continued engagement and mutual respect to create a regulatory ecosystem that fosters innovation while respecting the rule of law with every stakeholder – government, private sector and civil society. India’s position could set the trend for other emerging economies coming online and foster a strategic digital ecosystem that works for all
stakeholders.
Comments to the ID4D Practitioners’ Guide
This post presents our comments to the ID4D Practitioners’ Guide: Draft For Consultation released by ID4D in June, 2019. CIS has conducted research on issues related to digital identity since 2012. This submission is divided into three main parts. The first part (General Comments) contains the high-level comments on the Practitioners’ Guide, while the second part (Specific Comments) addresses individual sections in the Guide. The third and final part (Additional Comments) does not relate to particulars in the Practitioners' Guide but other documents that it relies upon. We submitted these comments to ID4D on August 5, 2019. Read our comments here.
The Appropriate Use of Digital Identity
As governments across the globe implement new, foundational, digital identification systems (“Digital ID”), or modernize existing ID programs, there is dire need for greater research and discussion about appropriate uses of Digital ID systems. This significant momentum for creating Digital ID in several parts of the world has been accompanied with concerns about the privacy and exclusion harms of a state issued Digital ID system, resulting in campaigns and litigations in countries such as UK, India, Kenya, and Jamaica. Given the very large range of considerations required to evaluate Digital ID projects, it is necessary to think of evaluation frameworks that can be used for this purpose.
At RightsCon 2019 in Tunis, we presented working drafts on appropriate use of Digital ID by the partner organisations of this three-region research alliance - ITS from Brazil, CIPIT from Kenya, and CIS from India.
In the draft by CIS, we propose a set of principles against which Digital ID may be evaluated. We hope that these draft principles can evolve into a set of best practices that can be used by policymakers when they create and implement Digital ID systems, provide guidance to civil society examinations of Digital ID and highlight questions for further research on the subject. We have drawn from approaches used in documents such as the necessary and proportionate principles, the OECD privacy guidelines and scholarship on harms based approach.
Read and comment on CIS’s Draft framework here.
Download Working drafts by CIPIT, CIS, and ITS here.
Holding ID Issuers Accountable, What Works?
Together with the Institute of Technology & Society (ITS), Brazil, and the Centre for Intellectual Property and Information Technology Law (CIPIT), Kenya, CIS participated at a side event in RightsCon 2019 held in Tunisia, titled Holding ID Issuers Accountable, What Works?, organised by the Omidyar Network. The event was attended by researchers and advocates from nearly 20 countries. Read the event report here.
Design and Uses of Digital Identities - Research Plan
Read the research plan here.
Rethinking the intermediary liability regime in India
The blog post by Torsha Sarkar was published by CyberBRICS on August 12, 2019.
Introduction
In December 2018, the Ministry of Electronics and Information Technology (“MeitY”) released the Intermediary Liability Guidelines (Amendment) Rules (“the Guidelines”), which would be significantly altering the intermediary liability regime in the country. While the Guidelines has drawn a considerable amount of attention and criticism, from the perspective of the government, the change has been overdue.
The Indian government has been determined to overhaul the pre-existing safe harbour regime since last year. The draftversion of the e-commerce policy, which were leaked last year, also hinted at similar plans. As effects of mass dissemination of disinformation, propaganda and hate speech around the world spill over to offline harms, governments have been increasingly looking to enact interventionist laws that leverage more responsibility on the intermediaries. India has not been an exception.
A major source of these harmful and illegal content in India come through the popular communications app WhatsApp, despite the company’s enactment of several anti-spam measures over the past few years. Last year, rumours circulated on WhatsApp prompted a series of lynchings. In May, Reuters reported that clones and software tools were available at minimal cost in the market, for politicians and other interested parties to bypass these measures, and continue the trend of bulk messaging.
These series of incidents have made it clear that disinformation is a very real problem, and the current regulatory framework is not enough to address it. The government’s response to this has been accordingly, to introduce the Guidelines. This rationale also finds a place in its preliminarystatement of reasons.
While enactment of such interventionist laws has triggered fresh rounds of debate on free speech and censorship, it would be wrong to say that such laws were completely one-sided, or uncalled for.
On one hand, automated amplification and online mass circulation of purposeful disinformation, propaganda, of terrorist attack videos, or of plain graphic content, are all problems that the government would concern itself with. On the other hand, several online companies (including Google) also seem to be in an uneasy agreement that simple self-regulation of content would not cut it. For better oversight, more engagement with both government and civil society members is needed.
In March this year, Mark Zuckerberg wrote anop-ed for the Washington Post, calling for more government involvement in the process of content regulation on its platform. While it would be interesting to consider how Zuckerberg’s view aligns with those similarly placed, it would nevertheless be correct to say that online intermediaries are under more pressure than ever to keep their platforms clean of content that is ‘illegal, harmful, obscene’. And this list only grows.
That being said, the criticism from several stakeholders is sharp and clear in instances of such law being enacted – be it the ambitious NetzDG aimed at combating Nazi propaganda, hate speech and fake news, or the controversial new European Copyright Directive which has been welcomed by journalists but has been severely critiqued by online content creators and platforms as detrimental against user-generated content.
In the backdrop of such conflicting interests on online content moderation, it would be useful to examine the Guidelines released by MeitY. In the first portion we would be looking at certain specific concerns existing within the rules, while in the second portion, we would be pushing the narrative further to see what an alternative regulatory framework may look like.
Before we jump to the crux of this discussion, one important disclosure must be made about the underlying ideology of this piece. It would be unrealistic to claim that the internet should be absolutely free from regulation. Swathes of content on child sexual abuse, or terrorist propaganda, or even the hordes of death and rape threats faced by women online are and should be concerns of a civil society. While that is certainly a strong driving force for regulation, this concern should not override the basic considerations for human rights (including freedom of expression). These ideas would be expanded a bit more in the upcoming sections.
Broad, thematic concerns with the Rules
A uniform mechanism of compliance
Timelines
Rule 3(8) of the Guidelines mandates intermediaries, prompted by a court order or a government notification, to take down content relating to unlawful acts within 24 hours of such notification. In case they fail to do so, the safe harbour applicable to them under section 79 of the Information Technology Act (“the Act”) would cease to apply, and they would be liable. Prior to the amendment, this timeframe was 36 hours.
There is a visible lack of research which could rationalize that a 24-hour timeline for compliance is the optimal framework, for all intermediaries, irrespective of the kind of services they provide, or the sizes or resources available to them. As Mozilla Foundation has commented, regulation of illegal content online simply cannot be done in an one-size-fits-all approach, nor can regulation be made with only the tech incumbents in mind. While platforms like YouTube can comfortably remove criminal prohibited content within a span of 24 hours, this still can place a large burden on smaller companies, who may not have the necessary resources to comply within this timeframe. There are a few unintended consequences that would arise out of this situation.
One, sanctions under the Act, which would include both organisational ramifications like website blocking (under section 69A of the Act) as well as individual liability, would affect the smaller intermediaries more than it would affect the bigger ones. A bigger intermediary like Facebook may be able to withstand a large fine in lieu of its failure to control, say, hate speech on its platform. That may not be true for a smaller online marketplace, or even a smaller online social media site, targeted towards a very specific community. This compliance mechanism, accordingly, may just go on to strengthen the larger companies, and eliminating the competition from the smaller companies.
Two, intermediaries, in fear of heavy criminal sanctions would err on the side of law. This would mean that the decisions involved in determining whether a piece of content is illegal or not would be shorter, less nuanced. This would also mean that legitimate speech would also be under risk from censorship, and intermediaries would pay less heed to the technical requirements or the correct legal procedures required for content takedown.
Utilization of ‘automated technology’
Another place where the Guidelines assume that all intermediaries operating in India are on the same footing is Rule 3(9). This mandates these entities to proactively monitor for ‘unlawful content’ on their platforms. Aside the unconstitutionality of this provision, this also assumes that all intermediaries would have the requisite resource to actually set up this tool and operate it successfully. YouTube’s ContentID, which began in 2007, has already seen a whopping 100 million dollars investment by 2018.
Funnily enough, ContentID is a tool exclusively dedicated to finding copyright violation of rights-holder, and even then, it has been proven to be not infallible. The Guidelines’ sweeping net of ‘unlawful’ content include far many more categories than mere violations of IP rights, and the framework assumes that intermediaries would be able to set up and run an automated tool that would filter through all these categories of ‘unlawful content’ at one go.
The problems of AI
Aside the implementation-related concerns, there are also technical challenges related with Rule 3(9). Supervised learning systems (like the one envisaged under the Guidelines) use training data sets for pro-active filtering. This means if the system is taught that for ten instances of A being the input, the output would be B, then for the eleventh time, it sees A, it would give the output B. In the lingo of content filtering, the system would be taught, for example, that nudity is bad. The next time the system encounters nudity in a picture, it would automatically flag it as ‘bad’ and violating the community standards.
Except, that is not how it should work. For every post that is under the scrutiny of the platform operators, numerous nuances and contextual cues act as mitigating factors, none of which, at this point, would beunderstandable by a machine.
Additionally, the training data used to feed the system can be biased. A self-driving car who is fed training data from only one region of the country would learn the customs and driving norms of that particular region, and not the patterns that apply across the intended purpose of driving throughout the country.
Lastly, it is not disputed that bias would be completely eliminated in case the content moderation was undertaken by a human. However, the difference between a human moderator and an automated one, would be that there would be a measure of accountability in the first one. The decision of the human moderator can be disputed, and the moderator would have a chance to explain his reasons for the removal. Artificial intelligence (“AI”) is identified by the algorithmic ‘black box’ that processes inputs, and generates usable outputs. Implementing workable accountability standards for this system, including figuring out appeal and grievance redressal mechanisms in cases of dispute, are all problems that the regulator must concern itself with.
In the absence of any clarity or revision, it seems unlikely that the provision would actually ever see full implementation. Neither would the intermediaries know what kind of ‘automated technology’ they are supposed to use for filtering ‘unlawful content’, nor would there be any incentives for them to actually deploy this system effectively for their platforms.
What can be done?
First, more research is needed to understand the effect of compliance timeframes on the accuracy of content takedown. Several jurisdictions are operating now on different timeframes of compliance, and it would be a far more holistic regulation should the government consider the dialogue around each of them and see what it means for India.
Second, it might be useful to consider the concept of an independent regulator as an alternative and as a compromise between pure governmental regulation (which is more or less what the system is) or self-regulation (which the Guidelines, albeit problematically, also espouse through Rule 3(9)).
The UK White Paper on Harms, a piece of important document in the system of liability overhaul, proposes an arms-length regulator who would be responsible for drafting codes of conduct for online companies and responsible for their enforcement. While the exact merits of the system is still up for debate, the concept of having a separate body to oversee, formulate and also possiblyarbitrate disputes regarding content removal, is finding traction in several parallel developments.
One of the Transatlantic Working Group Sessions seem to discuss this idea in terms of having an ‘internet court’ for illegal content regulation. This would have the noted advantage of a) formulating norms of online content in a transparent, public fashion, something previously done behind closed doors of either the government or the tech incumbents and b) having specially trained professionals who would be able to dispose of matters in an expeditious manner.
India is not unfamiliar to the idea of specialized tribunals, or quasi-judicial bodies for dealing with specific challenges. In 2015, for example, the Government of India passed the Commercial Courts Act, by which specific courts were tasked to deal with matters of very large value. This is neither an isolated instance of the government choosing to create new bodies for dealing with a specific problem, nor would it be inimitable in the future.
There is no silver bullet when it comes to moderation of content on the web. However, in light of these parallel convergence of ideas, the appeal of an independent regulatory system as a sane compromise between complete government control and laissez-faireautonomy, is worth considering.
A judicial overreach into matters of regulation
The article by Gurshabad Grover was published in the Hindu on August 27, 2019.
The Madras High Court has been hearing a PIL petition since 2018 that initially asked the court to declare the linking of Aadhaar with a government identity proof as mandatory for registering email and social media accounts. The petitioners, victims of online bullying, went to the court because they found that law enforcement agencies were inefficient at investigating cybercrimes, especially when it came to gathering information about pseudonymous accounts on major online platforms. This case brings out some of the most odious trends in policymaking in India.
The first issue is how the courts, as Anuj Bhuwania has argued in the book Courting the People, have continually expanded the scope of issues considered in PILs. In this case, it is absolutely clear that the court is not pondering about any question of law. In what could be considered as abrogation of the separation of powers provision in the Constitution, the Madras High Court started to deliberate on a policy question with a wide-ranging impact: Should Aadhaar be linked with social media accounts?
After ruling out this possibility, it went on to consider a question that is even further out of its purview: Should platforms like WhatsApp that provide encrypted services allow forms of “traceability” to enable finding the originator of content? In essence, the court is now trying to regulate one particular platform on a very specific technical question, ignoring legal frameworks entirely. It is worrying that the judiciary is finding itself increasingly at ease with deliberations on policy and regulatory measures, and its recent actions remind us that the powers of the court also deserve critical questioning.
Government’s support
Second, not only are governments failing to assert their own powers of regulation in response to the courts’ actions, they are on the contrary encouraging such PILs. The Attorney General, K.K. Venugopal, who is representing the State of Tamil Nadu in the case, could have argued for the case’s dismissal by referring to the fact that the Ministry of Electronics and Information Technology has already published draft regulations that aim to introduce “traceability” and to increase obligations on social media platforms. Instead, he has largely urged the court to pass regulatory orders.
Third, ‘Aadhaar linking’ is becoming increasingly a refrain whenever any matter even loosely related to identification or investigation of crime is brought up. While the Madras High Court has ruled out such linking for social media platforms, other High Courts are still hearing petitions to formulate such rules. The processes that law enforcement agencies use to get information from platforms based in foreign jurisdictions rely on international agreements. Linking Aadhaar with social media accounts will have no bearing on these processes. Hence, the proposed ‘solution’ misses the problem entirely, and comes with its own threats of infringing privacy.
Problems of investigation
That said, investigating cybercrime is a serious problem for law enforcement agencies. However, the proceedings before the court indicate that the cause of the issues have not been correctly identified. While legal provisions that allow agencies to seek information from online platforms already exist in the Code of Criminal Procedure and the Information Technology Act, getting this information from platforms based in foreign jurisdictions can be a long and cumbersome process. For instance, the hurdles posed by the mutual legal assistance treaty between India and the U.S. effectively mean that it might take months to receive a response to information requests sent to U.S.-based platforms, if a response is received at all.
To make cybercrime investigation easier, the Indian government has various options. India should push for fairer executive agreements possible under instruments like the United States’ CLOUD Act, for which we need to first bring our surveillance laws in line with international human rights standards through reforms such as judicial oversight. India could use the threat of data localisation as a leverage to negotiate bilateral agreements with other countries to ensure that agencies have recourse to quicker procedures. As a first step, however, Indian courts must wash their hands of such questions. For its part, the Centre must engage in consultative policymaking around these important issues, rather than support ad-hoc regulation through court orders in PILs.
(Disclosure: The CIS is a recipient of research grants from Facebook.)
Linking Aadhaar with social media or ending encryption is counterproductive
The article was published in Prime Time on August 26, 2019.
The case began in Madras High Court and later Facebook moved the SC seeking transfer of the petition to the Apex court. The original petition was filed in July, 2018 and sought linking of Aadhaar numbers with user accounts to further traceability of messages.
Before we try and answer this question, we need to first understand the differences between the different types of data on social media and messaging platforms. If a crime happens on an end to end cryptographically secure channel like WhatsApp the police may request the following from the provider to help solve the case:
- Identity data: Phone numbers of the accused. Names and addresses of the accused.
- Metadata: Sender, receiver(s), time, size of message, flag identifying a forwarded messages, delivery status, read status, etc.
- Payload Data: Actual content of the text and multimedia messages.
Different countries have taken different approaches to solving different layers of the surveillance problem. Let us start with identity data. Some like India require KYC for sale of SIM cards while others like the UK allow anonymous purchases. Corporations also have policies when it comes to anonymous speech on their platforms – Facebook for instance enforces a soft real ID policy while Twitter does not crack down on anonymous speech. The trouble with KYC the old fashioned way is that it exposes citizens to further risk. Every possessor of your identity documents is a potential attack surface. Indian regulation should not result in Indian identity documents being available in the millions to foreign corporations. Technical innovations are possible, like tokenisation, Aadhaar paperless local e-KYC or Aadhaar offline QR code along with one time passwords. These privacy protective alternatives must be mandatory for all and the Aadhaar numbers must be deleted from previously seeded databases. Countries that don’t require KYC have an alternative approach to security and law enforcement. They know that if someone like me commits a crime, it would be easy to catch me because I have been using the same telecom provider for the last fifteen years. This is true of long term customers regardless if they are pre-paid or post-paid. The security risk lies in the new numbers without this history that confirms identity. These countries use targeted big data analytics to determine risk and direct surveillance operations to target new SIM cards. My current understanding is that when it comes to basic user data – all the internet giants in India comply with what they consider as legitimate law enforcement requests. Some proprietary and free and open source [FOSS] alternatives to services offered by the giants don’t provide such direct cooperation in India.
When it comes to payload data – it is almost impossible (meaning you will need supercomputers) to access the data unless the service/software provider breaks end-to-end cryptography. It is unwise, like some policy-makers are proposing, to prohibit end-to-end cryptography or mandate back doors because our national sovereignty and our capacity for technological self-determination depends on strong cryptography. A targeted ban or prohibition against proprietary providers might have a counterproductive consequence with users migrating to FOSS alternatives like Signal which won’t even give the police identity data. As a supporter of the free software movement, I would see this as a positive development but as a citizen I am aware that the fight against crime and terror will become harder. So government must pursue other strategies to getting payload data such as a comprehensive government hacking programme.
Meta-data is critical when it comes to separating the guilty from the innocent and apportioning blame during an investigation. For example, who was the originator of a message? Who got it and read it last? WhatsApp claims that it has implemented the Signal protocol faithfully meaning that they hold no meta-data when it comes to the messages and calls. Currently there is no regulation which mandates data retention for over the top providers but such requirements do exist for telecom providers. Just like access to meta-data provides some visibility into illegal activities it also provides visibility into legal activities. Therefore those using end-to-end cryptography on platforms with comprehensive meta-data retention policies will have their privacy compromised even though the payload data remains secure. Here is a parallel example to understand why this is important. Early last year, the Internet Engineering Task Force chose a version of TLS 1.3 that revealed less meta-data over one that provided greater visibility into the communications. This hardening of global open standards, through the elimination of availability of meta-data for middle-boxes, makes it harder for foreign governments to intercept Indian military and diplomatic communications via imported telecom infrastructure. Courts and policy makers across the world have to grapple with the following question: Are meta-data retention mandates for the entire population of users a “necessary and proportionate” legal measure to combat crime and terror. For me, it should not be illegal for a provider who voluntarily wishes to retain data, provided it is within legally sanctioned limits but it should not be requirement under law.
There are technical solutions that are yet to be properly discussed and developed as an alternative to blanket meta-data retention measures. For example, Dr. V Kamakoti has made a traceability proposal at the Madras High Court. This proposal has been critiqued by Anand Venkatanarayanan as being violative in spirit of the principles of end-to-end cryptography. Other technical solutions are required for those seeking justice and for those who wish to serve as informers for terror plots. I have proposed client side metadata retention. If a person who has been subjected to financial fraud wishes to provide all the evidence from their client, it should be possible for them to create a digital signed archive of messages for the police. This could be signed by the sender, the provider and also the receiver so that technical non-repudiation raises the evidentiary quality of the digital evidence. However, there may be other legal requirements such as the provision of notice to the sender so that they know that client side data retention has been turned on.
The need of the hour is sustained research and development of privacy protecting surveillance mechanisms. These solutions need to be debated thoroughly amongst mathematicians, cryptographers, scientists, technologists, lawyers, social scientists and designers so that solutions with the least negative impact can be rolled out either voluntarily by providers or as a result of regulation.
Future of Work in the ASEAN
Read the research paper: Download (PDF)
Authored by Aayush Rathi, Vedika Pareek, Divij Joshi, and Pranav Bidare
Research assistance by Sankalp Srivastava and Anjanaa Aravindan
Edited by Elonnai Hickok and Ambika Tandon
Supported by Tides Foundation
Introduction
The world of work, and its future, have attracted a lot of attention in recent times. The discussion has been provoked by the confluence of recent technological breakthroughs that portend to have wide-ranging implications on work and livelihoods. In what has been termed the “Fourth Industrial Revolution” or “Industry 4.0” , the discussion has engaged numerous stakeholders. However, no shared understanding of what this future of work will look like has materialised. Historical scholarship around technological change and its impact on the labour market was focussed in the context of high-income countries. Contemporaneously, however, research is being produced that outlines the possible futures of work in low and middle-income contexts. It is exigent to generate scholarship dedicated to low and middle-income contexts given that in addition to technological drivers, the future of work will be mediated through region and country specific factors such as socioeconomic,geopolitical and demographic change.
Kashmir’s information vacuum
The article by Aayush Rathi and Akriti Bopanna was published in the Hindu on August 29, 2019.
On August 4, around midnight, Jammu and Kashmir was thrust into a near total communication shutdown. In the continuing aftermath of the dilution of Article 370, cable television, cellular services, landline and Internet and even the postal services have been rendered inoperational. Even hospitals and fire stations have not been spared. While law enforcement personnel have been provided satellite phones, locals are having to queue up outside designated government offices and register the numbers they want to call. The blackout is all encompassing.
The erstwhile State of Jammu and Kashmir is accustomed to the flicking on of the “Internet killswitch”, but this indiscriminate embargo is unprecedented. The blocking of multi-point/two-way communication is quite frequent in Kashmir, with close to 55 instances of partial or complete Internet shutdowns being recorded just this year. Of the 347 cases of shutdown that have been imposed in India since 2012, 51% have been in Kashmir. The blocking of one-way communication media, such as cable television, however, is new. Even the measures adopted during the Kargil war in 1999 stopped short of blocking telephone lines.
Appearing for the incumbent government on a petition challenging the communications shutdown in Kashmir, the Attorney General of India, K.K. Venugopal, made the necessary-for-law-and-order argument.
However, recent research by Jan Rydzak looking exclusively at network shutdowns in India has shown no evidence backing this claim. On the contrary, network shutdowns have been shown to compel actors wanting to engage in collective action to substitute non-violent mobilisation for more violent means as the latter requires less coordination.
In dubious company
Network shutdowns have a limited and inconsistent effect on even structured, non-violent protests. Cross-country comparative research indicates that the shutdown of communication for achieving objectives of social control is usually the riposte of authoritarian regimes. The shroud of secrecy it creates allows for further controversial measures to be effected away from public scrutiny. Authoritarian regimes masquerading as liberal democracies are following suit. In 2016, the Turkish government had ordered the shutdown of over 100 media companies in the aftermath of a failed military coup. Earlier this year, Joseph Kabila’s government in the Democratic Republic of Congo had shut down Internet and SMS services for three weeks under the pretext of preventing the circulation of fake election results.
Mr. Venugopal further reassured the Supreme Court that the residents of Kashmir would experience the least amount of inconvenience. This line assumes that the primary use of telecommunication networks is for supposedly banal interpersonal interaction. What is forgotten is that these networks function both as an “infrastructure” and as medium of communication. Impacting either function has dire and simultaneous consequences on its use as the other. As an infrastructure, they are akin to a public utility and are foundational to the operation of critical systems such as water supply and finance.
In the Kashmir Valley, over half the business transactions are said to happen online. The payment of wages for the government-run employment guarantee scheme for unskilled manual labour is almost entirely made electronically — 99.56% in Jammu and Kashmir. The reliance on the Internet for bank-related transactions has meant that automated teller machines and banks are inoperative. What is telling is that the increasing recourse to network shutdowns as a law and order tool in India is also happening simultaneously with the government’s digitisation drive. Information flows are being simultaneously facilitated and throttled.
Ambiguous backing
Moreover, communication shutdowns have ambiguous legal backing. One approach imposes them as an order passed under Section 144 of the Code of Criminal Procedure. A colonial relic, Section 144 is frequently used for the imposition of curfew in ‘sensitive’ areas as a preventive measure against public demonstrations. This approach lacks procedural accountability and transparency. Orders are not mandated to be publicly notified; they do not identify the duration of the lockdown or envision an appeal mechanism.
Perhaps realising these challenges, the Temporary Suspension of Telecom Services (Public Emergency or Public Safety) Rules, 2017, notified under the Telegraph Act, do incorporate a review mechanism. However, reviewing officials do not have the authority to revoke a shutdown order even if it is deemed illegal. The grounds for effectuating any shutdown also have not been elaborated other than for ‘public emergency’ or ‘public safety’ — both these terms are undefined. Legislative backing, then, is being appropriated to normalise, not curb, communication shutdowns. Tellingly, the owner of an Internet service provider in Kashmir pointed out that with Internet shutdowns becoming so common, often the shape that an order takes is of a call from a government official, while the procedural documentation follows much later.
Treated as collateral damage in imposing communication blackouts are the fundamental freedoms of speech and expression, trade, and also of association. The imposition of Section 144 along with the virtual curfew is designed to restrict the freedom to assemble peacefully. Such preemptive measures assume that any assembly will be violent along with negating the potential utility of technological means in maintaining social order (such as responsible digital journalism checking the spread of rumours).
Most critically, this enables a complete information vacuum, the only salve from which is information supplied by the suppressor. Of the days leading up to August 5 and the days since, sparse information is publicly available. Local newspaper outlets in Kashmir are inoperational. This lack of information necessarily precludes effective democratic participation. Beneath the national security sentiments, a key motivation for network shutdown presents itself: that of political censorship through the criminalisation of dissent.
Submission to Global Commission on Stability of Cyberspace on the definition of Cyber Stability
The definition of cyberspace the GCSC provided was :
Stability of cyberspace is the condition where individuals and institutions can be reasonably confident in their ability to use cyberspace safely and securely, where the availability and integrity of services in cyberspace is generally assured, where change is managed in relative peace, and where tensions are resolved in a peaceful manner.
CIS gave detailed commentary on the definitions [attached] and suggested a new definition of cyber stability documented below:
Stability of cyberspace is the objective where individuals, institutions and communities are confident in the safety and security of cyberspace; the accessibility,availability and integrity of services in cyberspace can be relied upon and where change is managed and tensions ranging from external interference in sovereign processes to the use of force in cyberspace are resolved peacefully in line with the tenets of International Law,specifically the principles of the UN Charter and universally recognised human rights.
Cyber stability can only be fostered if key stakeholders in cyberspace conform to a due diligence obligation of not undertaking and preventing actions that may prevent cyber stability. The end goal of cyber stability must minimize or eliminate immaterial or peripheral incentives while preserving and potentially legitimizing those cyber offensive operations that can further effective deterrence and thereby foster stability, while also minimising any collateral damage to civilian life or property.
Doing Standpoint Theory
Three speech bubbles on different textures. Artist: Catalina Alzate
The article by Ambika Tandon and Aayush Rathi was published by GenderIT.org on September 1, 2019.
Standpoint theory holds the experiences of the marginalised as the source of ‘truth’ about structures of oppression, which is silenced by traditional objectivist research methods as they produce knowledge from the standpoint of voices in positions of power2. Feminist empiricism does not eschew traditional modes of knowledge production, but emphasises diversity of research participants for feminist (and therefore also rigorous) knowledge production3. Relativists have critiqued standpoint theory for its tendency to essentialise the experience of marginalised groups, and subsume them into one homogenous voice to achieve the goal of ‘emancipatory’ research4. Relativists instead focus on multiple standpoints, which could be Dalit women, lesbian women, or women with disabilities5. We will be discussing the practical applicability of these epistemologies to research practices in the field of technology and gender.
Standpoint theory holds the experiences of the marginalised as the source of ‘truth’ about structures of oppression, which is silenced by traditional objectivist research methods as they produce knowledge from the standpoint of voices in positions of power.
As part of the Feminist Internet Research Network, the Centre for Internet and Society is undertaking research on the digital mediation of domestic and care work in India. The project aims to assess shifts in the sector, including conditions of work, brought on by the entry of digital platforms. Our starting point for designing a methodology for the research was standpoint theory, which we thought to be the best fit as the goal of the project was to disrupt dominant narratives of women’s labour in relation to platformisation. In the context of dalit feminis, Rege warns that standpoint research risks producing a narrow frame of identity politics, although it is critical to pay attention to lived experience and the “naming of difference” between dalit women and savarna women6. She asserts that neither ‘women’ nor ‘dalit women’ is a homogenous category. While feminist researchers from outside these categories cannot claim to “speak for” those within, they can “reinvent” themselves as dalit feminists and ally themselves with their politics.
In order to address this risk of appropriating the voices of domestic workers (“speaking for”), we chose to directly work with a domestic workers’ union in Bengaluru called Stree Jagruti Smiti. Bengaluru is one of the two cities we are conducting research in (the other being Delhi, with very few registered unions). This is meant to radically destabilise power hierarchies and material relations within the research process, as benefits of participatory research tend to accumulate with the researchers rather than participants7.
Along with amplifying the voices of workers, a central objective of our project is to question the techno-solutionism that has accompanied the entry of digital platforms into the domestic work sector, which is unorganised and unregulated. To do so, we included companies and state labour departments as participants whose standpoint is to be interrogated. By juxtaposing the standpoints of stakeholders that have differential access to power and resources, the researcher is able to surface various conflicts and intersections in dominant and alternative narratives. This form of research also brings with it unique challenges, as researchers could find themselves mediating between the different stakeholders, while constantly choosing to privilege the standpoint of the least powerful - in this case the workers. Self-reflexivity then becomes necessary to ensure that the project does not slip into an absolutely relativist position, rather using the narratives of workers to challenge those of governments and private actors. This can also be done by ensuring that workers have agency to shape the agenda of researchers, thereby producing research which is instrumental in supporting grassroots campaigns and movements.
Self-reflexivity then becomes necessary to ensure that the project does not slip into an absolutely relativist position, rather using the narratives of workers to challenge those of governments and private actors.
Feminist participatory research itself, despite its many promises, is not a linear pathway to empowerment for participants8. At the very outset of the project, we were constantly asked the question by domestic workers and unions – why should we participate in this project? Researchers, in their experience, acquire information from the community throughout the process of data collection by positioning themselves as allies. However, as all such engagements are bound to limited timelines and budgets, researchers are then often absent at critical junctures where the community may need external support. We were also told that all too often, the output of the research itself does not make its way back to the participants, making it a one-way process of knowledge extraction. Being mindful of these experiences, we have integrated a feedback loop into our research design, which will allow us to design outputs that are accessible and useful to collectives of domestic workers.
Not only domestic workers and their organisations, many corporations operating these online portals and platforms often questioned the benefits of participating in the project. However, the manner of articulation differed. While attempting to reject the hierarchical nature of the researcher/participant relationship, we increasingly became aware that the underlying power equation was not a monolith. Rather, it varied across stakeholder groups and was explicitly contingent on the socially constructed positionalities already existing outside of the space of the interview. Companies, governments and workers all exemplified varying degrees of engagement with, knowledge of, and contributions to research. Interviews with workers and unions, and even some bootstrapped (i.e. without much external funding) , socially-minded companies, were often cathartic with an expectation of some benefits in return for opening themselves up to researchers. This was quite different for governments and larger companies, as conversations typically adhered to the patriarchal and classed notions of professionalism in sanitised, formal spaces9 and the strict dichotomy between public and personal spaces. Their contribution seemingly required lesser affective engagement from the interviewee, thereby resulting in lesser investment in the outcome of the research itself.
The cathartic nature of interviews also speak to the impossibility of the distanced, Platonic, school of research. We were often asked politically charged questions, our advice solicited and information sought. Workers and representatives from platform companies alike would question our motivations with the research and challenge us by inquiring about the benefits accruing to us. Again, both set of stakeholders would often ask differently about how other platforms were; workers already registered on a platform would wonder if another platform would be ‘better’ and representatives of platform companies would be curious about competition. This is perhaps a consequence of attempting to design a study that is of use and of interest to the workers we have been reaching out to.10 At times, we found ourselves at a place in the conversation where we were compelled to respond to political positions for the conversation to continue. There were interviews where notions of caste hierarchies (within oppressed classes) as a justification/complaint for engaging/having to engage in certain tasks would surface. Despite being beholden to a feminist consciousness that disregards the idea of the interviewer as neutral, we often found ourselves only hesitantly forthcoming. At times, it was to keep the interview broadly focused around the research subject, at others it was due to our own ignorance about the research artefact (in this instance, platforms mediating domestic work services). This underscores the challenges of seeing the interview as a value ridden space, where the contradictions between the interview as a data collection method and as a consciousness raising emerged - how could we share information about the artefact we were in the process of collecting data about?
We were often asked politically charged questions, our advice solicited and information sought.
The fostering of ‘rapport’11 has made its may into method, almost unknowingly. Often, respondents across stakeholder groups started from an initial place of hesitation, sometimes even suspicion. Several structural issues could be at work here - our inability in being able to accurately describe research itself, the class differences and at times, ideological ones as well. While with most participants, rapport was eventually established, its establishment was a laboured process. Especially given that we were using one-off, in-depth interviews as our method, securing an interview was contingent on the establishment of rapport. This isn’t to suggest that feminist research mandatorily requires the ‘doing of rapport’12, but that when it does, it’s a fortunate outcome and that feminist researchers engage with it more critically.
Building rapport creates an impression of having minimised the exploitation of the participant, however the underlying politics and pressures of building rapport need to be interrogated. Rapport, like research itself, is at times a performance; rapport is often not naturally occuring. Rather, rapport may also be built to conceal the very structural factors preventing it. For instance, during instances of ideological differences during the interview, we were at times complicit through our silence. This may have been to further a certain notion of ‘objectivity’ itself whereby the building and maintenance of rapport is essential to surfacing a participant’s real views. This then raises the questions: What are the ethical questions that the suppression of certain viewpoints and reactions pose? How does the building, maintenance and continuance of rapport inform the research findings? Rapport, then, comes in all shapes and sizes and its manifold forms implicate the research process differently. Another critical question to be addressed is - why does some rapport take less work than others? With platform companies, building rapport came by easier than it did with workers both on and off platforms. If understood as removing degrees of distance between the researcher and participants, several factors could play into the effort required to build rapport. For instance, language was a critical determinant of the ease of relationship-building. Being more fluent in English than in colloquial Hindi enabled clearer articulation of the research. Further, familiarity with the research process was, as expected, mediated along class lines. This influenced the manner in which we articulated research outcomes and objectives to workers with complete unfamiliarity with the meaning of research. Among workers, this unfamiliarity often resulted in distrust, which required the underlying politics of the research to be more critically articulated.
By and large, the feminist engagement with research methods has been quite successful in its resistance and transformation of traditional forms. Since Oakley’s conception of the interview as a deeply subjective space13 and Harding’s dialectical conception of masculinist science through its history14, the application of feminist critical theory has increasingly subverted assumptions around the averseness of research to political motivations. At the same time, it has made knowledge-production occur in a more equitable space. It is in this context that standpoint theory has had wide purchase, but challenges persist in its application. As the foregoing discussion outlines, we have been able to achieve some of the goals of feminist standpoint research while missing out on others. We also found the ‘multiple standpoints’ approach of relativists to be useful in a project involving multiple stakeholders - thereby also avoiding the risk of essentialisation of the identities of domestic workers. However, unlike the tendency of relativists to focus on each perspective as ‘equally valid truth’, we are choosing to focus on the conflicts and intersections between emerging discourses. Through this hybrid theoretical framework, we are seeking to make knowledge production more equitable. At the same time, the discussion around rapport shows that this may nevertheless happen in a limited fashion. Feminist research may never be fully non-extractive. The reflexivity exercised and choices made during the course of the research are key.
Unlike the tendency of relativists to focus on each perspective as ‘equally valid truth’, we are choosing to focus on the conflicts and intersections between emerging discourses.
Harding, S. (2003) The Feminist Standpoint Theory Reader: Intellectual and Political Controversies, Routledge.
M. Wickramasinghe, Feminist Research Methodology: Making meaning out of meaning-making, Zubaan, 2014
Pease, D. (2000) Researching profeminist men's narratives: participatory methodologies in a postmodern frame. In B. Fawcett, D. Featherstone, J. Fook ll)'ld A. Rossiter (eds) Restarching and Practising in Social Work: Postmodern Feminist Perspectives (London: Routledge).
Stanley, L. and Wise, S. (1983) Breaking Out: Feminist Consciousness and Feminist Research (London: Routledge and Kegan Paul).
Rege, S. 1998. ” Dalit Women Talk Differently: A critique of ‘Difference’ and Towards a Dalit Feminist Standpoint.” Economic and Political Weekly, Vol. 33, No.44, pp 39-48.
Heeks, R. and Shekhar, S. (2018) An Applied Data Justice Framework: Analysing Datafication and Marginalised Communities in Cities of the Global South. Working Paper Series, Centre for Development Informatics, University of Manchester.
Stone, E. and Priestley, M. (1996) Parasites, pawn and partners: disability research and the role of nondisabled researchers. British Journal of Sociology, 47(4), 699-716.
Evans, L. (2010). Professionalism, professionality and the development of education professionals. Br. J. Educ. Stud. 56, 20–38. doi:10.1111/j.1467-8527.2007.00392.x
Berger, R. (2015). Now I see it, now I don’t: researcher’s position and reflexivity in qualitative research. Qual. Res. 15, 219–234. doi:10.1177/1468794112468475; Pitts, M. J., and Miller-Day, M. (2007). Upward turning points and positive rapport development across time in researcher-participant relationships. Qual. Res. 7, 177–201. doi:10.1177/1468794107071409
Dunscombe, J., and Jessop, J. (2002). “Doing rapport, and the ethics of ’faking friendship’,” in Ethics in Qualitative Research, eds T. Miller, M. Birch, M. Mauthner, and J. Jessop (London: SAGE), 108–121.
Capturing Gender and Class Inequities: The CCTVisation of Delhi
Abstract
Cityscapes across the global South, following historical trends in the North, are increasingly being littered by closed-circuit television (CCTV) cameras. In this paper, we study the wholesale implementation of CCTV in New Delhi, a city notorious for incredibly high rates of crime against women. The push for CCTV, then, became one of many approaches explored by the state in making the city safer for women.
In this paper, we deconstruct this narrative of greater surveillance equating to greater safety by using empirical evidence to understand the subjective experience of surveilling and being surveilled. By focussing on gender and utilising work from feminist thought, we find that the experience of surveillance is intersectionally mediated along the axes of class and gender.The gaze of CCTV is cast upon those already marginalised to arrive at normative encumbrances placed by private, neoliberal interests on the urban public space. The politicisation of CCTV has happened in this context, and continues unabated in the absence of any concerted policy apparatus regulating it. We frame our findings utilising an analytical data justice framework put forth by Heeks and Shekhar (2019). This comprehensively sets out a social justice agenda that situates CCTV within the socio-political contexts that are intertwined in the development and implementation of the technology itself.
Click to download the full research paper
Examining the Constitutionality of the Ban on Broadcast of News by Private FM and Community Radio Stations
In the article, the authors also mapped chronologically the history of the development of community and private radio channels in India. As part of the legal analysis, the authors examined the prohibition on the touchstones of existing Indian jurisprudence on media freedom and speech rights. Finally, they also utilized some key points made by the Additional Solicitor General in the Shreya Singhal case, to propose an alternative regulatory framework that would address both the interests of the radio channels and the government.
In 1995, the Supreme Court declared airwaves to be public property in the seminal case of The Secretary, Ministry of Information and Broadcasting v Cricket Association of Bengal, and created the stepping stones for liberalization of broadcasting media from government monopoly. Despite this, community radio and private FM channels, in their nearly two decades of existence, have been unable to broadcast their own news content because of the Government’s persisting prohibition on the same.In this paper, we document the historical developments surrounding the issue, and analyse the constitutional validity of this prohibition on the touchstone of the existing jurisprudence on free speech and media freedom. Additionally, we also propose an alternative regulatory framework which would assuage the government’s apprehensions regarding radicalisation through radio spaces, as well as ensure that the autonomy of these stations is not curtailed.
Click to download the full paper by NLUD Journal of Legal Studies here.
Comparison of the Manila Principles to Draft of The Information Technology [Intermediary Guidelines(Amendment) Rules], 2018
Introduction
In December 2018, the Ministry of Electronics and Information Technology (MeitY) introduced amendments to the draft Information Technology [Intermediaries Guidelines (Amendment)] Rules, 2018 [“the 2018 Rules”]. The proposed changes ranged from asking intermediaries to proactively filter content using automated technology to prohibiting promotion of substances such as cigarettes and alcohol. In CIS's submission to the Government, we highlighted our various concerns with the proposed rules. Building on the same, this paper aims to assess how the new draft rules measure up to the best practices on Intermediary Liability as prescribed in the Manila Principles. These principles were formulated in 2015 by a coalition of civil society groups and experts, including CIS, in order to establish best practice to guide policies pertaining to intermediary liability.
Depending on their function, intermediaries have a varying hand in hosting activism and discourse that are integral to a citizen’s right to freedom of speech and expression. The Manila Principles are an attempt at articulating best practices that lead to the development of intermediary liability regimes which respect human rights.
Consequently, the paper examines the draft rules to assess their compatibility with the Manila Principles. It provides recommendations such that, where needed, the rules are aligned with the aforementioned principles. The assessment is done based on the insight into the rationale of the Manila Principles provided in its Background Paper.
Disclosure: CIS is a recipient of research grants from Facebook India.
Click to download the research paper which was edited by Elonnai Hickok and reviewed by Torsha Sarkar.
Designing a Human Rights Impact Assessment for ICANN’s Policy Development Processes
This report outlines the iterative research-and-design process carried out between November 2017 and July 2019, focusing on successes and lessons learned in anticipation of the ICANN Board’s long-awaited approval of the Work Stream 2 recommendations on Accountability. The process, findings, and recommendations will be presented by Akriti and Austin at CCWP-HR’s joint session with the Government Advisory Council at ICANN66 in Montreal during 2nd-8th November.
Click to download the full research paper here.
AI for Good
The report was edited by Elonnai Hickok.
The workshop was aimed at examining the current narratives around AI and imagining how these may transform with time. It raised questions about how we can build an AI for the future, and traced the implications relating to social impact, policy, gender, design, and privacy.
Methodology
The rationale for conducting this workshop in a design festival was to ensure a diverse mix of participants. The participants in the workshop came from varied educational and professional backgrounds who had different levels of understanding of technology. The workshop began with a discussion on the existing applications of artificial intelligence, and how people interact and engage with it on a daily basis. This was followed by an activity where the participants were provided with a form and were asked to conceptualise their own AI application which could be used for social good. The participants were asked to think about a problem that they wanted the AI application to address and think of ways in which it would solve the problem. They were also asked to mention who will use the application. It prompted participants to provide details of the AI application in terms of the form, colour, gender, visual design, and medium of interaction (voice/ text). This was intended to nudge the participants into thinking about the characteristics of the application, and how it will lend to the overall purpose. The form was structured and designed to enable participants to both describe and draw their ideas. The next section of the form gave them multiple pairs of principles. They were asked to choose one principle from each pair. These were conflicting options such as ‘Openness’ or ‘Proprietary’, and ‘Free Speech’ or ‘Moderated Speech’. The objective of this section was to illustrate how a perceived ideal AI that satisfies all stakeholders can be difficult to achieve, and that the AI developers at times may be faced with a decision between profitability and user rights.
Participants were asked to keep their responses anonymous. These responses were then collected and discussed with the group. The activity led to the participants engaging in a discussion on the principles mentioned in the form. Questions around where the input data to train the AI would come from, or what type of data the application will collect were discussed. The responses were used to derive implications on gender, privacy, design, and accessibility.

Responses

Analysis
Even as the responses were varied, they had a few key similarities and observations.
Participants’ Familiarity with AI
The participants’ understanding of AI was based on what they read and heard from various sources. While discussing the examples of AI, the participants were familiar with not just the physical manifestation of AI such as robots, but also AI software. However when asked to define an AI the most common explanations were, bots, software, and the use of algorithms to make decisions using large amounts of data. The participants were optimistic of the way AI could be used for social good. However, some of them showed concern about the implications on privacy.
Perception of AI Among Participants
With the workshop, our aim was to have the participants reflect on their perception of AI based on their exposure to the narratives around AI by companies and the government.
The participants were given the brief to imagine an AI that could solve a problem or be used for social good. Most participants considered AI to be a positive tool for social impact. It was seen as a problem solver. The ideas conceptualised by the participants varied from countering fake news, wildlife conservation, resource distribution, and mental health. This brought to focus the range of areas that were seen as pertinent for an AI intervention. Most of the responses dealt with concerns that affect humans directly, the one aimed at wildlife conservation being the only exception.
On being asked, who will use the AI application, it was interesting to note that all the responses considered different stakeholders such as individuals, non profits, governments and private companies to be the end user. However, it was interesting that through the discussion the harms that might be caused by the use of AI by these stakeholders were not brought up. For example, the use of AI for resource distribution did not take into consideration the fact that the government could provide unequal distribution based on the existing biased datasets. Several of the AI applications were conceptualised to work without any human intervention. For example, one of the ideas proposed was to use AI as a mental health counsellor which was conceptualised as a chatbot that would learn more about human psychology with each interaction. It was assumed that such a service would be better than a human psychologist who can be emotionally biased. Similarly, while discussing the idea behind the use of AI for preventing the spread of fake news, the participant believed that the indication coming from an AI would have greater impact than one coming from a human. They believed that the AI could provide the correct information and prevent the spread of fake news. By discussing these cases we were able to highlight that the complete reliance on technology could have severe consequences.
Form and Visual Design of the AI Concepts
In most cases, the participants decided the form and visual design of their AI concepts keeping in mind its purpose. For instance, the therapy providing AI mentioned earlier, was envisioned as a textual platform, while a ‘clippy type’ add on AI tool was thought of for detecting fake news. Most participants imagined the AI application to have a software form, while the legal aid AI application was conceptualised to have a human form. This revealed that the participants perceived AI to be both a software and a physical device such as a robot.
Accessibility of the Interfaces
The purpose of including the type of interface (voice or text) while conceptualising the AI application was to push the participants towards thinking about accessibility features. We aimed to have the participants think about the default use of the interface, both in terms of language and accessibility. The participants though cognizant of the need to have a large number of users, preferred to have only textual input into the interface, not anticipating the accessibility concerns.
The choices between access vs cost, and accessibility vs scalability were also questioned by the participants during the workshop. They enquired about the meaning of the terms as well as discussed the difficulty in having an all inclusive interface. Some of the responses consisted only of text inputs, especially for sensitive issues involving interactions, such as for therapy or helplines. This exercise made the participants think about the end user as well as the ‘AI for all’ narrative. We decided to add these questions that made the participants think about how the default ability, language, and technological capability of the user is taken for granted, and how simple features could help more people interact with the application. This discussion led to the inference that there is a need to think about accessibility by design during the creation of the application and not as an afterthought.
Biases Based on Gender
We intended for the participants to think about the inherent biases that creep into creating an AI concept. These biases were evident from deciding identifiably male names, to deciding a male voice when the application needed to be assertive, or a female voice and name for when it was dealing with school children. Most of the other participants either did not mention the gender or they said that the AI could be gender neutral or changeable.
These observations are also revealing of the existing narrative around AI. The popular AI interfaces have been noted to exemplify existing gender stereotypes. For example, the virtual assistants were given female identifiable names and default female voices such as Siri, Alexa, and Cortana. The more advanced AI were given male identifiable names and default male voices such as Watson, Holmes etc. Although these concerns have been pointed out by several researchers, there needs to be a visible shift towards moving away from existing gender biases.
Concerns around Privacy
Though the participants were aware of the privacy implications of data driven technologies, they were unsure of how their own AI concept could deal with questions of privacy. The participants voiced concerns about how they would procure the data to train the AI but were uncertain about their data processing practices. This included how they would store the data, anonymise the data, or prevent third parties from accessing it. For example, during the activity, it was pointed out to the participants that there would be sensitive data collected in applications such as therapy provision, legal aid for victims of abuse, and assistance for people with social anxiety. In these cases, the participants stated that they would ensure that the data was shared responsibly, but did not consider the potential uses or misuses of this shared data.
Choices between Principles
This part of the exercise was intended to familiarise the participants with certain ethical and policy questions about AI, as well as to look at the possible choices that AI developers have to make. Along with discussing the broader questions around the form and interface of AI, we wanted the participants to also look at making decisions about the way the AI would function. The intent behind this component of the exercise was to encourage the participants to question the practices of AI companies, as well as understand the implications of choices while creating an AI. As the language in this section was based on law and policy, we spent some time describing the terms to the participants. Even as some of the options presented by us were not exhaustive or absolute extremes, we placed this section to demonstrate the complexity in creating an AI that is beneficial for all. We intended for the participants to understand that an AI that is profitable to the company, free for people, accessible, privacy respecting, and open source, though desirable may be in competition with other interests such as profitability and scalability.
The participants were urged to think about how decisions regarding who can use the service, how much transparency and privacy the company will provide, are also part of building an AI. Taking an example from the responses, we talked about how having a closed proprietary software in case of AI applications such as providing legal aid to victims of abuse would deter the creation of similar applications. However, after the terms were explained, the participants mostly chose openness over proprietary software, and access over paid services.
Conclusion
The aim of this exercise was to understand the popular perception of AI. The participants had varied understanding of AI, but were familiar with the term. They also knew of the popular products that claim to use AI. Since the exercise was designed for people as an introduction to AI policy, we intended to keep questions around data practices out of the concept form. Eventually, with this exercise, we, along with the participants, were able to look at how popular media sells AI as an effective and cheaper solution to social issues. The exercise also allowed the participants to understand certain biases with gender, language, and ability. It also shed light on how questions of access and user rights should be placed before the creation of a technological solution. New technologies such as AI are being featured as problem solvers by companies, the media and governments. However, there is a need to also think about how these technologies can be exclusionary, misused, or how they amplify existing socio economic inequities.
We need a better AI vision
The blog post by Arindrajit Basu was published by Fountainink on October 12, 2019.
he dawn of Artificial Intelligence (AI) has policy-makers across the globe excited. In India, it is seen as a tool to overleap structural hurdles and better understand a range of organisational and management processes while improving the implementation of several government tasks. Notwithstanding the apparent enthusiasm in the government and private sectors, an adequate technological, infrastructural, and financial capacity to develop these models at scale is still in the works.
A number of policy documents with direct or indirect references to India’s AI future—to be powered by vast troves of data—have been released in the past year and a half. These include the National Strategy for Artificial Intelligence (which I will refer to as National Strategy) authored by NITI Aayog, the AI Taskforce Report, Chapter 4 of the Economic Survey, the Draft e-Commerce Bill and the Srikrishna Committee Report.
While they extol the virtues of data-driven analytics, references to the preservation or augmentation of India’s constitutional ethos through AI has been limited though it is crucial for safeguarding the rights and liberties of citizens while paving the way for the alleviation of societal oppression.
In this essay, I outline the variety of AI use cases that are in the works. I then highlight India’s AI vision by culling the relevant aspects of policy instruments that impact the AI ecosystem and identify lacunae that can be rectified. Finally, I attempt to “constitutionalise AI policy” by grounding it in a framework of constitutional rights that guarantee protection to the most vulnerable sections of society.
In the manufacturing industry, AI adoption is not uniform across all sectors. But there has been a notable transformation in electronics, heavy electricals and automobiles.
It is crucial to note that these cases, still emerging in India, have been implemented at scale in other countries such as the United Kingdom, United States and China. Projects were rolled out to the detriment of ethical and legal considerations. Hindsight should make the Indian policy ecosystem much wiser. By closely studying the research produced in these diverse contexts, Indian policy-makers should try to find ways around the ethical and legal challenges that cropped up elsewhere and devise policy solutions that mitigate the concerns raised.
***
Before anything else we need to define AI—an endeavour fraught with multiple contestations. My colleagues and I at the Centre for Internet & Society ducked this hurdle when conducting our research by adopting a function-based approach. An AI system (as opposed to one that automates routine, cognitive or non-cognitive tasks) is a dynamic learning system that allows for the delegation of some level of human decision-making to the system. This definition allows us to capture some of the unique challenges and prospects that stem from the use of AI.
The research I contributed to at CIS identified key trends in the use of AI across India. In healthcare, it is used for descriptive and predictive purposes.
For example, the Manipal Group of Hospitals tied up with IBM’s Watson for Oncology to aid doctors in the diagnosis and treatment of seven types of cancer. It is also being used for analytical or diagnostic services. Niramai Health Analytix uses AI to detect early stage breast cancer and Adveniot Tecnosys detects tuberculosis through chest X-rays and acute infections using ultrasound images. In the manufacturing industry, AI adoption is not uniform across all sectors. But there has been a notable transformation in the electronics, heavy electricals and automobiles sector gradually adopting and integrating AI solutions into their products and processes.
It is also used in the burgeoning online lending segment in order to source credit score data. As many Indians have no credit scores, AI is used to aggregate data and generate scores for more than 80 per cent of the population who have no credit scores. This includes Credit Vidya, a Hyderabad-based data underwriting start-up that provides a credit score to first time loan-seekers and feeds this information to big players such as ICICI Bank and HDFC Bank, among others. It is also used by players such as Mastercard for fraud detection and risk management. In the finance world, companies such as Trade Rays are being used to provide user-friendly algorithmic trading services.
AI is also being increasingly used in the education sector for providing services to students such as decision-making assistance and also for student-progress monitoring.
The next big development is in law enforcement. Predictive policing is making great strides in various states, including Delhi, Punjab, Uttar Pradesh and Maharashtra. A brainchild of the Los Angeles Police Department, predictive policing is the use of analytical techniques such as Machine Learning to identify probable targets for intervention to prevent crime or to solve past crime through statistical predictions.
Conventional approaches to predictive policing start with the mapping of locations where crimes are concentrated (hot spots) by using algorithms to analyse aggregated data sets. Police in Uttar Pradesh and Delhi have partnered with the Indian Space Research Organisation (ISRO) in a Memorandum of Understanding to allow ISRO’s Advanced Data Processing Research Institute to map, visualise and compile reports about crime-related incidents.
There are aggressive developments also on the facial recognition front. Punjab Police, in association with Gurugram-based start-up Staqu has started implementing the Punjab Artificial Intelligence System (PAIS) which uses digitised criminal records and automated facial recognition to retrieve information on the suspected criminal. At the national level, on June 28, the National Crime Records Bureau (NCRB) called for tenders to implement a centralised Automated Facial Recognition System (AFRS), defining the scope of work in broad terms as the “supply, installation and commissioning of hardware and software at NCRB.”
AI is also being increasingly used in the education sector for providing services to students such as decision-making assistance and also for student-progress monitoring. The Andhra Pradesh government had started collecting information from a range of databases and processes the information through Microsoft’s Machine Learning Platform to monitor children and devote student focussed attention on identifying and curbing school drop-outs.
In Andhra Pradesh, Microsoft collaborated with the International Crop Institute for Semi-Arid Tropics (ICRISAT) to develop an AI Sowing App powered by Microsoft’s Cortana Intelligence Suite. It aggregated data using Machine Learning and sent advisories to farmers regarding optimal dates to sow. This was done via text messages on feature phones after ground research revealed that not many farmers owned or were able to use smart phones. The NITI Aayog AI Strategy specifically cited this use case and reported that this resulted in a 10-30 per cent increase in crop yield. The government of Karnataka has entered into a similar arrangement with Microsoft.
Finally, in the defence sector, our research found enthusiasm for AI in intelligence, surveillance and reconnaissance (ISR) functions, cyber defence, robot soldiers, risk terrain analysis and moving towards autonomous weapons systems. These projects are being developed by the Defence Research and Development Organisation but the level of trust and support in AI-driven processes reposed by the wings of the armed forces is yet to be publicly clarified. India also had the privilege of leading the global debate on Lethal Autonomous Weapons Systems (LAWS) with Amandeep Singh Gill chairing the United Nations Group of Governmental Experts (UN-GGE) on the issue. However, ‘lethal’ autonomous weapons systems at this stage appear to be a speck in the distant horizon.
***
Along with the range of use cases described above, a patchwork of policy imperatives is emerging to support this ecosystem. The umbrella document is the National Strategy for Artificial Intelligence published by the NITI Aayog in June 2018. Despite certain lacunae in its scope, the existence of a cohesive and robust document that lends a semblance of certainty and predictability to a rapidly emerging sphere is in itself a boon. The document focuses on how India can leverage AI for both economic growth and social inclusion. The contents of the document can be divided into a few themes, many of which have also found their way into multiple other instruments.
NITI Aayog provides over 30 policy recommendations on investment in scientific research, reskilling, training and enabling the speedy adoption of AI across value chains. The flagship research initiative is a two-tiered endeavour to boost AI research in India. First, new centres of research excellence (COREs) will develop fundamental research. The COREs will act as feeders for international centres for transformational AI which will focus on creating AI-based applications across sectors.

This is an impressive theoretical objective but questions surrounding implementation and structures of operation remain to be answered. China has not only conceptualised an ecosystem but through the Three Year Action Plan to Promote the Development of New Generation Artificial Intelligence Industry, it has also taken a whole-of-government approach to propelling the private sector to an e-leadership position. It has partnered with national tech companies and set clear goals for funding, such as the $2.1 billion technology park for AI research in Beijing.
The contents of the NITI document can be divided into a few themes, many of which have also found their way into multiple other instruments. First, it proposes an “AI+X” approach that captures the long-term vision for AI in India. Instead of replacing the processes in their entirety, AI is understood as an enabler of efficiency in processes that already exist. NITI Aayog therefore looks at the process of deploying AI-driven technologies as taking an existing process (X) and adding AI to them (AI+X). This is a crucial recommendation all AI projects should heed. Instead of waving AI as an all-encompassing magic wand across sectors, it is necessary to identify specific gaps AI can seek to remedy and then devise the process underpinning this implementation.
A cacophony of policy instruments by multiple government departments seeks to reconceptualise data to construct a theoretical framework that allows for its exploitation for AI-driven analytics.
The AI-driven intervention to develop sowing apps for farmers in Karnataka and Andhra Pradesh are examples of effective implementation of this approach. Instead of other knee-jerk reactions to agrarian woes such as a hasty raising of Minimum Support Price, effective research was done in this use-case to identify a lack of predictability in weather patterns as a key factor in productive crop yields. They realised that aggregation of data through AI could provide farmers with better information on weather patterns. As internet penetration was relatively low in rural Karnataka, text messages to feature phones that had a far wider presence was indispensable to the end game.
***
This is in contrast to the ill-conceived path adopted by the Union ministry of electronics and information technology in guidelines for regulating social media platforms that host content (“intermediaries”). Rule 3(9) of the Draft of the Information Technology [Intermediary Guidelines (Amendment) Rules] 2018 mandates intermediaries to use “automated tools or appropriate mechanisms, with appropriate controls, for proactively identifying and removing or disabling public access to unlawful information or content”.
Proposed in light of the fake news menace and the unbridled spread of “extremist” content online, the use of the phrase “automated tools or appropriate mechanisms” is reflective of an attitude that fails to consider ground realities that confront companies and users alike. They ignore, for instance, the cost of automated tools: whether automated content moderation techniques developed in the West can be applied to Indic languages or grievance redress mechanisms users can avail of if their online speech is unduly restricted. This is thus a clear case of the “AI” mantra being drawn out of a hat without studying the “X” it is supposed to remedy.
The second focus of the National Strategy that has since morphed into a technology policy mainstay across instruments is on data governance, access and utilisation. The document says the major hurdle to the large scale adoption of AI in India is the difficulty in accessing structured data. It recommends developing big annotated data sets to “democratise data and multi-stakeholder marketplaces across the AI value chain”. It argues that at present only one per cent of data can be analysed as it exists in various unconnected silos. Through the creation of a formal market for data, aggregators such as diagnostic centres in the healthcare sector would curate datasets and place them in the market, with appropriate permissions and safeguards. AI firms could use available datasets rather than wasting effort sourcing and curating the sets themselves.
A cacophony of policy instruments by multiple government departments seeks to reconceptualise data to construct a theoretical framework that allows for its exploitation for AI-driven analytics.The first is “community data” and appears both in the Srikrishna Report that accompanied the draft Data Protection Bill in 2018 and the draft e-commerce policy.
But there appears to be some conflict between its usage in the two. Srikrishna endorses a collective protection of privacy by protecting an identifiable community that has contributed to community data. This requires the fulfilment of three key conditions: first, the data belong to an identifiable community; second, individuals in the community consent to being a part of it, and third, the community as a whole consents to its data being treated as community data. On the other hand, the Department of Promotion of Industry and Internal Trade’s (DPIIT) draft e-commerce policy looks at community data as “societal commons” or a “national resource” that gives the community the right to access it but government has ultimate and overriding control of the data. This configuration of community data brings into question the consent framework in the Srikrishna Bill.
The government’s attempt to harness data as a national resource for the development of AI-based solutions may be well-intentioned but is fraught with core problems in implementation.
The matter is further confused by treating “data as a public good”. This is projected in Chapter 4 of the 2019 Economic Survey published by the Ministry of Finance. It explicitly states that any configuration needs to be deferential to privacy norms and the upcoming privacy law. The “personal data” of an individual in the custody of a government is also a “public good” once the datasets are anonymised. At the same time, it pushes for the creation of a government database that links several individual databases, which leads to the “triangulation” problem, where matching different datasets together allows for individuals to be identified despite their anonymisation in seemingly disparate databases.
“Building an AI ecosystem” was also one of the ostensible reasons for data localisation—the government’s gambit to mandate that foreign companies store the data of Indian citizens within national borders. In addition to a few other policy instruments with similar mandates, Section 40 of the Draft Personal Data Protection Bill mandates that all “critical data” (this is to be notified by the government) be stored exclusively in India. All other data should have a live, serving copy stored in India even if transfer abroad is allowed. This was an attempt to ensure foreign data processors are not the sole beneficiaries of AI-driven insights.
The government’s attempt to harness data as a national resource for the development of AI-based solutions may be well intentioned but is fraught with core problems in implementation. First, the notion of data as a national resource or as a public good walks a tightrope with constitutionally guaranteed protections around privacy, which will be codified in the upcoming Personal Data Protection Bill. My concerns are not quite so grave in the case of genuine “public data” like traffic signal data or pollution data. However, the Economic Survey manages to crudely amalgamate personal data into the mix.
It also states that personal data in the custody of a government is a public good once the datasets are anonymised. This includes transactions data in the User Payments Interface (UPI), administrative data including birth and death records, and institutional data including data in public hospitals or schools on pupils or patients. At the same time, it pushes for a government database that will lead to the triangulation problem outlined above. The chapter also suggests that said data may be sold to private firms (unclear if this includes foreign or domestic firms). This not only contradicts the notion of public good but is also a serious threat to the confidentiality and security of personal data.
***
Therefore, along with the concerted endeavour to create data marketplaces, it is crucial for policy-makers to differentiate between public data and personal data individuals may consent to be made public. The parameters for clearly defining free and informed consent, as codified in the Draft Personal Data Protection Bill need to be strictly followed as there is a risk of de-anonymisation of data once it finds its way into the marketplace. Second, it is crucial for policy-makers to define clearly a community and parameters for what constitutes individual consent to be part of a community. Finally, along with technical work on setting up a national data marketplace, there must be protracted efforts to guarantee greater security and standards of anonymisation.
The National Strategy mentions that India should position itself as a “garage” for AI in emerging economies. This could mean Indian citizens are used as guinea pigs for AI-driven solutions at the cost of their rights.
Assuming that a constitutionally valid paradigm may be created, the excessive focus on data access by tech players dodges the question of the capabilities of analytic firms to process this data and derive meaningful insights from the information. Scholars on China, arguably the poster-child of data-driven economic growth, have sent mixed messages. Ding argues that despite having half the technical capabilities of the US, easy access to data gives China a competitive edge in global AI competition. On the contrary, Andrew Ng has argued that operationalising a sufficient number of relevant datasets still remains a challenge. Ng’s views are backed up by insiders at Chinese tech giant Tencent who say the company still finds it difficult to integrate data streams due to technical hurdles. NITI Aayog’s idea of a multi-stream data marketplace may theoretically be a solution to these potential hurdles but requires sustained funding and research innovation to be converted into reality.
The National Strategy suggests that government should create a multi-disciplinary committee to set up this marketplace and explore levers for its implementation. This is certainly the need of the hour. It also rightly highlights the importance of research partnerships between academia and the private sector, and the need to support start-ups. There is therefore an urgent need for innovative allied policy instruments that support the burgeoning start-up sector. Proposals such as data localisation may hurt smaller players as they will have to bear the increased fixed costs of setting up or renting data centres.
The National Strategy also incongruously mentions that India should position itself as a “garage” for the use of AI in emerging economies. This could mean Indian citizens are used as guinea pigs for AI-driven solutions at the cost of their fundamental rights. It could also imply that India should occupy a leadership position and work with other emerging economies to frame the global rights based discourse to seek equitable solutions for the application of AI that works to improve the plight of the most vulnerable in society.
***
Our constitutional ethos places us in a unique position to develop a framework that enables the actualisation of this equitable vision—a goal the policy instruments put out thus far appear to have missed. While the National Strategy includes a section on privacy, security and ethical implications of AI, it stops short of rooting it in fundamental rights and constitutional principles. As a centralised policy instrument, the National Strategy deserves praise for identifying key levers in the future of India’s AI ecosystem and, with the exception of the concerns I outlined above, it is at par with the policy-making thought process in any other nation.
When we start the process of using constitutional principles for AI governance, we must remember that as per Article 12, an individual can file a writ against the state for violation of a fundamental right if the action is taken under the aegis of a “public function”. To combat discrimination by private actors, the state can enact legislation compelling private actors to comply with constitutional mandates. In July, Rajeev Chandrashekhar, a Rajya Sabha MP, suggested a law to combat algorithmic discrimination along the lines of the Algorithmic Accountability Bill proposed in the US Senate. There are three core constitutional questions along the lines of the “golden triangle” of the Indian Constitution any such legislation will need to answer—those of accountability and transparency, algorithmic discrimination and the guarantee of freedom of expression and individual privacy.
Algorithms are developed by human beings who have their own cognitive biases. This means ostensibly neutral algorithms can have an unintentional disparate impact on certain, often traditionally disenfranchised groups.
In the MIT Technology Review, Karen Hao explains three stages at which bias might creep in. The first stage is the framing of the problem itself. As soon as computer scientists create a deep-learning model, they decide what they want the model to finally achieve. However, frequently desired outcomes such as “profitability”, “creditworthiness” or “recruitability” are subjective and imprecise concepts subject to human cognitive bias. This makes it difficult to devise screening algorithms that fairly portray society and the complex medley of identities, attributes and structures of power that define it.
The second stage Hao mentions is the data collection phase. Training data could lead to bias if it is unrepresentative of reality or represents entrenched prejudice or structural inequality. For example, most Natural Language Processing systems used for Parts of Speech (POS) tagging in the US are trained on the readily available data sets from the Wall Street Journal. Accuracy would naturally decrease when the algorithm is applied to individuals—largely ethnic minorities—who do not mimic the speech of the Journal.
According to Hao, the final stage for algorithmic bias is data preparation, which involves selecting parameters the developer wants the algorithm to consider. For example, when determining the “risk-profile” of car owners seeking insurance premiums, geographical location could be one parameter. This could be justified by the ostensibly neutral argument that those residing in inner-city areas with narrower roads are more likely to have scratches on their vehicles. But as inner cities in the US have a disproportionately high number of ethnic minorities or other vulnerable socio-economic groups, “pin code” becomes a facially neutral proxy for race or class-based discrimination.
***
The right to equality has been carved into multiple international human rights instruments and into the Equality Code in Articles 14-18 of the Indian Constitution. The dominant approach to interpreting the right to equality by the Supreme Court has been to focus on “grounds” of discrimination under Article 15(1), thus resulting in a lack of recognition of unintentional discrimination and disparate impact.
A notable exception, as constitutional scholar Gautam Bhatia points out, is the case of N.M. Thomas which pertained to reservation in promotions. Justice Mathew argued that the test for inequality in Article 16(4) is an effects-oriented test independent of the formal motivation underlying a specific act. Justice Krishna Iyer and Mathew also articulated a grander vision wherein they saw the Equality Code as transcending the embedded individual disabilities in class driven social hierarchies. This understanding is crucial for governing data driven decision-making that impacts vulnerable communities. Any law or policy on AI-related discrimination must also include disparate impact within its definition of “discrimination” to ensure that developers think about the adverse consequences even of well-intentioned decisions.
AI driven assessments have been challenged on grounds of constitutional violations in other jurisdictions. In 2016, the Wisconsin Supreme Court considered the legality of using risk assessment tools such as COMPAS for sentencing criminals. It affirmed the trial court’s findings and held that using COMPAS did not violate constitutional due process standards. Eric Loomis had argued that using COMPAS infringed both his right to an individualised sentence and to accurate information as COMPAS provided data for specific groups and kept the methodology used to prepare the report a trade secret. He additionally argued that the court used unconstitutional gendered assessments as the tool used gender as one of the parameters.
The Wisconsin Supreme Court disagreed with Loomis arguing that COMPAS only used publicly available data and data provided by the defendant, which apparently meant Loomis could have verified any information contained in the report. On the question of individualisation, the court argued that COMPAS provided only aggregate data for groups similarly placed to the offender. However, it went on to argue as the report was not the sole basis for a decision by the judge, a COMPAS assessment would be sufficiently individualised as courts retained the discretion and information necessary to disagree.
By assuming that Loomis could have genuinely verified all the data collected about similarly placed groups and that judges would exercise discretion to prevent the entrenchment of inequalities through COMPAS’s decision-making patterns, the judges ignored social realities. Algorithmic decision-making systems are an extension of unequal decision-making that re-entrenches prevailing societal perceptions around identity and behaviour. An instance of discrimination cannot be looked at as a single instance but as one in a menagerie of production systems that define, modulate and regulate social existence.
The policy-making ecosystem needs, therefore, to galvanise the “transformative” vision of India’s democratic fibre and study existing systems and power structures AI could re-entrench or mitigate. For example, in the matter of bank loans there is a presumption against the credit-worthiness of those working in the informal sector. The use of aggregated decision-making may lead to more equitable outcomes given that there is concrete thought on the organisational structures making these decisions and the constitutional safeguards provided.
Most case studies on algorithmic discrimination in Virgina Eubanks’ Automating Inequality or Safiya Noble’s Algorithms of Oppression are based on western contexts. There is an urgent need for publicly available empirical studies on pilot cases in India to understand the contours of discrimination. Primary research questions should explore three related subjects. Are specified ostensibly neutral variables being used to exclude certain communities from accessing opportunities and resources or having a disproportionate impact on their civil liberties? Is there diversity in the identities of the coders themselves? Are the training data sets used representative and diverse and, finally, what role does data driven decision-making play in furthering the battle against embedded structural hierarchies?
***
A key feature of AI-driven solutions is the “black box” that processes inputs and generates actionable outputs behind a veil of opacity to the human operator. Essentially, the black box denotes that aspect of the human neural decision-making function that has been delegated to the machine. A lack of transparency or understanding could lead to what Frank Pasquale terms a “Black Box Society” where algorithms define the trajectories of daily existence unless “the values and prerogatives of the encoded rules hidden within black boxes” are challenged.
Ex-post facto assessment is often insufficient for arriving at genuine accountability. For example, the success of predictive policing in the US was drawn from the fact that police have indeed found more crimes in areas deemed “high risk”. But this assessment does not account for the fact that this is a product of a vicious cycle through which more crime is detected in an area simply because more policemen are deployed. Here, the National Strategy rightly identifies that simply opening up code may not deconstruct the black box as not all stakeholders impacted by AI solutions may understand the code. The constant aim should be explicability which means the human developer should be able to explain how certain factors may be used to arrive at a certain cluster of outcomes in a given set of situations.
The requirement of accountability stems from the Right to Life provision under Article 21. As stated in the seven-judge bench in Maneka Gandhi vs. Union of India, any procedure established by law must be seen to be “fair, just and reasonable” and not “fanciful, oppressive or arbitrary.”
The Right to Privacy was recognised as a fundamental right by the nine-judge bench in K.S. Puttaswamy (Retd.) vs. Union of India. Mass surveillance can lead to the alteration of behavioural patterns which may in turn be used for the suppression of dissent by the State. Pulling vast tracts of data on all suspected criminals—as in facial recognition systems like PAIS—create a “presumption of criminality” that can have a chilling effect on democratic values.
Therefore, any use, particularly by law enforcement would need to satisfy the requirements for infringing on the right to privacy: the existence of a law, necessity—a clearly defined state objective—and proportionality between the state object and the means used restricting fundamental rights the least. Along with centralised policy instruments such as the National Strategy, all initiatives taken in pursuance of India’s AI agenda must pay heed to the democratic virtues of privacy and free speech and their interlinkages.
India needs a law to regulate the impact of Artificial Intelligence and enable its development without restricting fundamental rights. However, regulation should not adopt a “one-size-fits-all” approach that views all uses with the same level of rigidity. Regulatory intervention should be based on questions around power asymmetries and the likelihood of the use case adversely affronting human dignity captured by India’s constitutional ethos.
As an aspiring leader in global discourse, India can lay the rules of the road for other emerging economies not only by incubating, innovating and implementing AI powered technologies but by grounding it in a lattice of rich constitutional jurisprudence that empowers the individual.
The High Level Task Force on Artificial Intelligence (AI HLEG) set up by the European Commission in June 2018 published a report on “Ethical Guidelines for Trustworthy AI” earlier this year. They feature seven core requirements which include human agency and oversight; technical robustness and safety; privacy and data governance; transparency; diversity, non-discrimination and fairness; societal and environmental well-being; and accountability. While the principles are comprehensive, this document stops short of referencing any domestic or international constitutional law that helps cement these values. The Indian Constitution can help define and concretise each of these principles and could be used as a vehicle to foster genuine social inclusion and mitigation of structural injustice through AI.
At the centre of the vision must be the inherent rights of the individual. The constitutional moment for data driven decision-making emerges therefore when we conceptualise a way through which AI can be utilised to preserve and improve the enforcement of rights while also ensuring that data does not become a further avenue for exploitation.
National vision transcends the boundaries of policy and to misuse Peter Drucker, “eats strategy for breakfast”. As an aspiring leader in global discourse, India can lay the rules of the road for other emerging economies not only by incubating, innovating and implementing AI powered technologies but by grounding it in a lattice of rich constitutional jurisprudence that empowers the individual, particularly the vulnerable in society. While the multiple policy instruments and the National Strategy are important cogs in the wheel, the long-term vision can only be framed by how the plethora of actors, interest groups and stakeholders engage with the notion of an AI-powered Indian society.
Setting International Norms of Cyber Conflict is Hard, But that Doesn't Mean that We Should Stop Trying
The article by Arindrajit Basu and Karan Saini was published by Modern War Institute on September 30, 2019.
His words are important, and should be taken seriously by the legal and technical communities that are attempting to feed into the present global governance ecosystem. However, many of his arguments seem to suffer from an unjustified and dismissive skepticism of any form of global regulation in this space.
He believes that the unique features of cyberspace render governance through the application of international law close to impossible. Given the range of developments that are in the pipeline in the global cyber norms proliferation process, this is an excessively defeatist attitude toward modern international relations. It also unwittingly encourages the continued weaponization of cyberspace by fomenting a “no holds barred” battlespace, to the detriment of the trust that individuals can place in the security and stability of the ecosystem.
“The Fundamentals of Computer Science”
Singh argues that the “fundamentals of computer science” render rules of international humanitarian law (IHL)—which serve as the governing framework during armed conflict in other domains—inapplicable, and that lawyers and policymakers have gotten cyber horribly wrong. Singh theorizes that in the case of the United States having pre-positioned espionage malware in Russian military networks, that malware could have been “repurposed or even reinterpreted as an act of aggression.”
The possibility of a fabricated act of espionage being used as justification for an escalated response exists within the realm of analogous espionage, too. A reconnaissance operation that has been compromised can also be repurposed midway into a full-blown armed attack, or could be reinterpreted as justification for an escalatory response. However, international law states that self-defense can only be exercised when the “necessity of self-defense is instant, overwhelming, leaving no choice of means, and no moment of deliberation.” In order to legitimize any action taken under the guise of self-defense, the threat would have to be imminent and the response both necessary and proportionate. There is nothing inherently unique in the nature of cyber conflict that would render the traditional law of self-defense moot.
Further, the presumption that cyber operations are ambiguous and often uncontrollable, as Singh suggests, is flawed. An exploit that is considered “deployment-ready” is the result of an attacker’s attempts at fine-tuning variables—until it is determined that the particular vulnerability can be exploited in a manner that is considered to be reasonably reliable. An exploit may have to be worked upon for quite some time for it to behave exactly how the attacker intends it to. While it is true that there still may be unidentified factors that can potentially alter the behavior of a well-developed exploit, a skilled operator or malware author would nonetheless have a reasonable amount of certainty that an exploit code’s execution will result in the realization of only a certain possible set of predefined outcomes.
It is true that a number of remote exploits that target systems and networks may make use of unreliable vulnerabilities, where outcomes may not be fully apparent prior to execution—and sometimes even afterward. However, for most deployment-ready exploits, this would simply not be the case. In fact, the example of the infamous Stuxnet malware, which Singh uses in his article, helps buttress our point.
Singh questions whether India should have interpreted the widespread infection of systems within the region—which also happened to affect certain critical infrastructure—as an armed attack. This question can cursorily be dismissed since we now know that Stuxnet did not cause any deliberate damage to Indian computing infrastructure. A 2013 report by journalist Joseph Menn correctly states that “the only place deliberately affected [by Stuxnet] was an Iranian nuclear facility.” Therefore, for India to claim mere infection of systems located within the bounds of its territory as having been an armed attack, it would have to concretely demonstrate that the operators of Stuxnet caused “grave harm”—as described in IHL—purely by way of having infected those machines, through execution of malicious instructions programmed in the malware’s payload.
At the same time, it should not be dismissed that the act of the Stuxnet malware infecting a machine could very well be interpreted by a state as constituting an armed attack. However, given the current state of advancement in malware decompilation and reverse-engineering studies, the process of deducing instructions that a particular malicious program seeks to execute can in most cases be performed in a reasonably reliable manner. Thus, for a state to make such a claim, it would have to prove that the malware did indeed cause grave harm, that which meets the criteria of the “scale and effects” threshold laid down in Nicaragua v. United States—whether it was caused due to operator interaction or preprogrammed instructions—along with sufficient reasoning and evidence for attributing it to a state.
An analysis of the Stuxnet code made it apparent that operators were seeking out machines that had the Siemens STEP 7 or SIMATIC WinCC software installed. The authors of the malware quite clearly had prior knowledge that the nuclear centrifuges that they intended to target made use of a particular type of programmable logic controllers, which the STEP 7 and WinCC software interacted with. On the basis of this prior knowledge, the authors of Stuxnet made design choices by which, upon infection, target machines would communicate to the Stuxnet command-and-control server—including identifiers such as operating system version, IP address, workstation name, and domain name—whether or not the infected system had the STEP 7 or WinCC software installed. This allowed the operators of Stuxnet to easily identify and distinguish machines that they would ultimately attack for fulfilling their objectives. In effect, this gave them some amount of control over the scale of damage they would deliberately cause.
It has been theorized that the malware reached the nuclear facility in Iran through a flash drive. It may be true that widespread and unnecessary propagation of the worm—which could be described as it “going out of control”—was not something the operators had intended (as it would attract unwanted attention and raise alarm bells across the board). It has nonetheless been several years since Stuxnet was in action, and there have been no documented cases of Stuxnet having caused grave harm to Indian (or other) computers. For all purposes, it could be said that the risk of collateral damage was minimized as the control operators were able to direct the execution of damaging components of the malware, to a degree that could be interpreted as having complied with IHL—thereby making it a calculated cyberattack, with controllable effects.
However, if the adverse effects of the operation were to be indiscriminate (i.e., machines were tangibly damaged immediately upon being infected), and could not be controlled by the operator within reasonable bounds, then the rules of IHL would render the operation illegal—a red line that, among other declarations, the recent French statement on the application of international law to cyberspace recognizes.
“Bizarre and Regressive”: The Westphalian Precept of Territoriality
Singh’s next grievance is with the precept of territoriality and sovereignty in cyberspace. However, the reasoning he provides decrying this concept is unclear at best. The International Group of Experts authoring the Tallinn Manual argued that “cyber activities occur on territory and involve objects, or are conducted by persons or entities, over which States may exercise their sovereign prerogatives.” They continued to note that even though cyber operations can transcend territorial domains, they are conducted by “individuals and entities subject to the jurisdiction of one or more state.”
Contrary to Singh’s assertions, our reasoning is entirely in line with the “defend forward” and “persistent engagement” strategies adopted by the United States defense experts. In fact, Gen. Paul Nakasone, commander of US Cyber Command—whose interview Singh cites to explain these strategies—explicitly states in that interview that “we must ‘defend forward’ in cyberspace as we do in the physical domains. . . . [Naval and air forces] patrol the seas and skies to ensure that they are positioned to defend our country before our borders are crossed. The same logic applies in cyberspace.” This is a recognition of the Westphalian precept of territoriality in cyberspace—which includes the right to take pre-emptive measures against adversaries before the people and objects within a nation’s sovereign borders are negatively impacted.
Below-the-Threshold Operations
Singh also argues that most cyber operations would not reach the threshold armed attack to invoke IHL. He concludes, therefore, that applying the rules of IHL “bestows another garb of impunity upon rogue cyber attacks.” However, as discussed above, the application of IHL does not require a certain threshold of intensity, but the mere application of armed force that is attributable to a state.
Therefore, laying down “red lines” by, for example, applying the principle of distinction, which seeks to minimize damage to civilian life and property, actually works toward setting legal rules that seek to prevent the negative civilian fallout of cyber conflict. There appears to be no reason why any cyberattack by a state should harm civilians without the state using all means possible to avoid this harm. If there is an ongoing armed conflict, this entails compliance with the IHL principles of necessity and proportionality, ensuring that any collateral damage ensuing as a result of an operation is proportionate to the military advantage being sought.
Moreover, we agree that certain information operations may not cause any damage in terms of injury to human life or property. But IHL is not the only framework for governing cyber conflict. Ongoing cyber norms proliferation efforts are attempting to move beyond the rigid application of international law to account for the unique challenges of cyberspace. Despite the flaws in the process thus far, individuals from a variety of backgrounds and disciplines must engage meaningfully and shape effective regulation in this space. Singh’s “garb of impunity” exists when there are a lack of restrictions on collateral damage caused by cyber operations, to the detriment of civilian life and property alike.
Obstacles in Developing Customary International Law
His third argument is on the fetters limiting the development of customary international law in the cyber domain. This is a valid concern. Until recently, most states involved in cyber operations have adopted a stance of silence and ambiguity with regard to their legal position on the applicability of international law in cyberspace or their position on the Tallinn Manual.
This is due to multiple reasons: First, states are not certain if the rules of the Tallinn Manual protect their long-term interests of gaining covert operational advantages in the cyber domain, which acts as a disincentive for strongly endorsing the rules laid out therein. Second, even those states keen on applying and adhering to the manual may not be able to do so in the absence of technical and effective processes that censure other states that do not comply. Given this ambiguity, states have demonstrated a preference to engage in cyber operations and counteroperations that are below the threshold—in other words, those that do not bring IHL into play. However, as others have convincingly argued, it is incorrect to assume that the current trend of silence and ambiguity will continue.
Recent developments indicate that the variety of normative processes and actors alike may render the Tallinn Manual more relevant as a focal point in the discussions. The UK, France, Germany, Estonia, Cuba (backed by China and Russia), and the United States have all engaged in public posturing in advocacy of their respective positions regarding the applicability of international law in cyberspace, in varying degrees of detail—which is essentially customary international law in the making. The statements made by a number of delegations at the recently concluded first substantive session of the United Nations’ Open-Ended Working Group covered a broad range of issues, from capacity building to the application of international law, which is the first step towards fostering consensus among the variety of global actors.
Positive Conflict and the Future of Cyber Norms
The final argument—a theme that runs from the beginning of Singh’s article—is a stark criticism of Western-centric cyber policy processes. Despite attempts to foster inclusivity, efforts like those that produced the Tallinn Manual are still driven largely from and by the United States in an attempt to, as Singh describes it, keep “cyber offense fully potentiated.” This is an unfortunate reality, but one that is not limited solely to the cyber domain. For example, in an excellent paper written in 2001, retired US Air Force Maj. Gen. Charles Dunlap explained “that ‘lawfare,’ that is, the use of law as a weapon of war, is the newest feature of 21st century combat.”
We are presented therefore with two options: either sit back and witness the hegemonization of policy discourse by a limited number of powerful states, or actively seek to contest these assumptions by undertaking adversarial work across standards-setting bodies, multilateral and multi-stakeholder norms-setting forums, as well as academic and strategic settings. In a recent paper, international law scholar Monica Hakimi argues that international law can serve as a fulcrum for facilitating positive conflict in the short run between a variety of actors across industry, civil society, and military and civilian government entities, which can lead to the projection of shared governance endeavors in the long run. Despite its several flaws, the Tallinn Manual can serve as a this type of fulcrum for facilitating this conflict.
In writing a premature eulogy of efforts to bring to realization a set of norms in cyberspace, Singh dismisses that historically, global governance regimes have taken considerable time and effort to come into being and emerge after an arduous process of continuous prodding and probing. This process necessitates that any existing assumptions—and the bases on which they are constructed—are challenged regularly, so that we can enumerate and ultimately arrive at an agreeable definition for what works and what does not. Rejecting these processes in their entirety foments a global theater of uncertainty, with no benchmarks for cooperation that stakeholders in this domain can reasonably rely on.
Farming the Future: Deployment of Artificial Intelligence in the agricultural sector in India

Although agriculture is a critical sector for India’s economic development, it continues to face many challenges including a lack of modernization of agricultural methods, fragmented landholdings, erratic rainfalls, overuse of groundwater and a lack of access to information on weather, markets and pricing. As state governments create policies and frameworks to mitigate these challenges, the role of technology has often come up as a potential driver of positive change.
Farmers in the southern Indian states of Karnataka and Andhra Pradesh are facing significant challenges. For hundreds of years,these farmers have relied on traditional agricultural methods to make sowing and harvesting decisions, but now volatile weather patterns and shifting monsoon seasons are making such ancient wisdom obsolete. Farmers are unable to predict weather patterns or crop yields accurately, making it difficult for them to make informed financial and operational decisions associated with planting and harvesting. Erratic weather patterns particularly affect those farmers who reside in remote areas, cut off from meaningful accessto infrastructure and information. In addition to a lack of vital weather information, farmers may lack information about market conditions and may then sell their crops to intermediaries at below-market prices.
Against this backdrop, the state governments and local partners in southern India teamed up with Microsoft to develop predictive AI services to help smallholder farmers to improve their crop yields and give them greater price control. Since 2016 three applications have been developed and applied for use in these communities, two of which are discussed in this case study: the AI-sowing app and the price forecasting model.
Click to read the report here.
The Mother and Child Tracking System - understanding data trail in the Indian healthcare systems
This article was first published by Privacy International, on October 17, 2019
Case study of MCTS: Read
On October 17th 2019, the UN Special Rapporteur (UNSR) on Extreme Poverty and Human Rights, Philip Alston, released his thematic report on digital technology, social protection and human rights. Understanding the impact of technology on the provision of social protection – and, by extent, its impact on people in vulnerable situations – has been part of the work the Centre for Internet and Society (CIS) and Privacy International (PI) have been doing.
Earlier this year, PI responded to the UNSR's consultation on this topic. We highlighted what we perceived as some of the most pressing issues we had observed around the world when it comes to the use of technology for the delivery of social protection and its impact on the right to privacy and dignity of benefit claimants.
Among them, automation and the increasing reliance on AI is a topic of particular concern - countries including Australia, India, the UK and the US have already started to adopt these technologies in digital welfare programmes. This adoption raises significant concerns about a quickly approaching future, in which computers decide whether or not we get access to the services that allow us to survive. There's an even more pressing problem. More than a few stories have emerged revealing the extent of the bias in many AI systems, biases that create serious issues for people in vulnerable situations, who are already exposed to discrimination, and made worse by increasing reliance on automation.
Beyond the issue of AI, we think it is important to look at welfare and automation with a wider lens. In order for an AI to function it needs to be trained on a dataset, so that it can understand what it is looking for. That requires the collection large quantities of data. That data would then be used to train and AI to recognise what fraudulent use of public benefits would look like. That means we need to think about every data point being collected as one that, in the long run, will likely be used for automation purposes.
These systems incentivise the mass collection of people's data, across a huge range of government services, from welfare to health - where women and gender-diverse people are uniquely impacted. CIS have been looking specifically at reproductive health programmes in India, work which offers a unique insight into the ways in which mass data collection in systems like these can enable abuse.
Reproductive health programmes in India have been digitising extensive data about pregnant women for over a decade, as part of multiple health information systems. These can be seen as precursors to current conceptions of big data systems within health informatics. India’s health programme instituted such an information system in 2009, the Mother and Child Tracking System (MCTS), which is aimed at collecting data on maternal and child health. The Centre for Internet and Society, India, undertook a case study of the MCTS as an example of public data-driven initiatives in reproductive health. The case study was supported by the Big Data for Development network supported by the International Development Research Centre, Canada. The objective of the case study was to focus on the data flows and architecture of the system, and identify areas of concern as newer systems of health informatics are introduced on top of existing ones. The case study is also relevant from the perspective of Sustainable Development Goals, which aim to rectify the tendency of global development initiatives to ignore national HIS and create purpose-specific monitoring systems.
After being launched in 2011, 120 million (12 crore) pregnant women and 111 million (11 crore) children have been registered on the MCTS as of 2018. The central database collects data on each visit of the woman from conception to 42 days postpartum, including details of direct benefit transfer of maternity benefit schemes. While data-driven monitoring is a critical exercise to improve health care provision, publicly available documents on the MCTS reflect the complete absence of robust data protection measures. The risk associated with data leaks are amplified due to the stigma associated with abortion, especially for unmarried women or survivors of rape.
The historical landscape of reproductive healthcare provision and family planning in India has been dominated by a target-based approach. Geared at population control, this approach sought to maximise family planning targets without protecting decisional autonomy and bodily privacy for women. At the policy level, this approach was shifted in favour of a rights-based approach to family planning in 1994. However, targets continue to be set for women’s sterilisation on the ground. Surveillance practices in reproductive healthcare are then used to monitor under-performing regions and meet sterilisation targets for women, this continues to be the primary mode of contraception offered by public family planning initiatives.
More recently, this database - among others collecting data about reproductive health - is adding biometric information through linkage with the Aadhaar infrastructure. This data adds to the sensitive information being collected and stored without adhering to any publicly available data protection practices. Biometric linkage is aimed to fulfill multiple functions - primarily authentication of welfare beneficiaries of the national maternal benefits scheme. Making Aadhaar details mandatory could directly contribute to the denial of service to legitimate patients and beneficiaries - as has already been seen in some cases.
The added layer of biometric surveillance also has the potential to enable other forms of abuse of privacy for pregnant women. In 2016, the union minister for Women and Child Development under the previous government suggested the use of strict biometric-based monitoring to discourage gender-biased sex selection. Activists critiqued the policy for its paternalistic approach to reduce the rampant practice of gender-biased sex selection, rather than addressing the root causes of gender inequality in the country.
There is an urgent need to rethink the objectives and practices of data collection in public reproductive health provision in India. Rather than continued focus on meeting high-level targets, monitoring systems should enable local usage and protect the decisional autonomy of patients. In addition, the data protection legislation in India - expected to be tabled in the next session in parliament - should place free and informed consent, and informational privacy at the centre of data-driven practices in reproductive health provision.
This is why the systematic mass collection of data in health services is all the more worrying. When the collection of our data becomes a condition for accessing health services, it is not only a threat to our right to health that should not be conditional on data sharing but also it raises questions as to how this data will be used in the age of automation.
This is why understanding what data is collected and how it is collected in the context of health and social protection programmes is so important.
“Politics by other means”: Fostering positive contestation and charting ‘red lines’ through global governance in cyberspace
Arindrajit Basu's essay for this year's Digital Debates: The CyFy Journal was published jointly by Global Policy and ORF. It was written in response to a framing essay by Dennis Broeders under the governance theme. The article was edited by Gurshabad Grover. Arindrajit also acknowledges the contributions of the editorial team at ORF: Trisha, Akhil and Meher.
There is no silver bullet that will magically result in universally acknowledged rules of the road. Instead, through consistent probing and prodding, the global community must create inclusive processes to galvanize consensus to ensure that individuals across the world can repose trust and confidence in their use of global digital infrastructure.[2] This includes both ‘red lines’ applicable to clearly prohibited acts of cyberspace and softer norms for responsible state behaviour in cyberspace, that arise from an application of the tenets of International Law to cyberspace.
Infrastructure is political
Networked infrastructures typically originate when a series of technological systems with varying technical standards converge, or when a technological system achieves dominance over other self-contained technologies.[3] Through this process of convergence, networked infrastructures must adapt to a variety of differing political conditions, legal regulations and governance practices.[4] Internet infrastructure was never self-contained technology, but an amalgamation of systems, protocols, standards and hardware along with the standards bodies, private actors and states that define it.[5] The architecture has always been deeply socio-technical[6] and any attempt to severe the technology from the politics of internet governance would be a fool’s errand.
Politics catalyzed the development of the technological infrastructure that lead to the creation of the internet. During the heyday of nuclear brinkmanship between the USA and USSR, Paul Baran, an engineer with the US Department of Defense think tank RAND Corporation was tasked with building a means of communication that could continue running even if some parts were to be knocked out by a nuclear war.[7]
As Baran’s ‘Bomb proof network’ morphed into the US Department of Defense funded ARPANET, it was initially apparent that it was not meant for either mass or commercial use, but instead saw its nurturing in the US as a tool of strategic defense.[8]
This enabled the US to retain a disproportionate -- and till the 1990s, relatively uncontested -- influence on internet governance. As the internet rapidly expanded across the globe, various actors found that single state control over an invaluable global resource was unjust.[9] Others (9which included US Senator Ted Cruz), argued that the internet would be safer in the hands of the United States than an international forum whose processes could be reduced to stalemate as a result of politicized conflict between democratic and non-democratic states who seek to use online spaces as an instrument of suppression.[10] The ICANN and IANA transitions were therefore not rooted in technical considerations but much-needed geopolitical pressure from states and actors who felt ‘disregarded’[11] in the governance of the internet. An inclusive multi-stakeholder process fueled by inclusive geopolitical contestation is far more effective in the long run and has the potential of respecting the rights of ‘disregarded’ communities all across the globe far more than a unilateral process that ignores any voices of opposition.
It is now clear that despite its continued outsized influence, the United States is no longer the only major state player in global cyber governance. China has propelled itself as a major political and economic challenger to the United States across several regimes[12], including in the cyber domain. China’s export of the ‘information sovereignty’[13] doctrine at various cyber norms proliferation fora, including at the United Nations-Group of Governmental Experts (GGE), and regional forums like the Shanghai Co-operation (SCO), is an example of its desire to impose its ideological clout on global conceptions of the internet.
As a rising power, China’s aspirations in global internet governance are not limited to ideology. China is at an ‘innovation imperative’, where it needs to develop new technologies to retain its status and fuel long-term growth.[14] This locks it into direct economic, and therefore strategic competition with the United States that seeks to retain control over the same supply chains and continues to assert its economic and military superiority.
China has dominated the 5G space in an unprecedented way, and has been a product of a concerted ‘whole of government’ effort.[15] Beijing charted out an industrial policy that enabled the deployment of 5G networks as a key national priority.[16] China has also successfully weaponized global technical standard-setting efforts to promote its geo-economic interests.[17] Reeling from the failure of its domestic 3G standard that was ignored globally, China realised the importance of the ‘first-movers’ advantage’ in setting standards for companies and businesses.[18] Through an aggressive strategic push at a number of international bodies such as the International Telecommunications Union, China’s diplomatic pivot has allowed it to push standards established domestically with little external input, thereby giving Chinese companies the upper hand globally.[19]
Politics continues to frame the technical solutions that enable cybersecurity.19 Following Snowden’s revelations, some stakeholders in the global community have shaped their politics to frame the problem as one of protecting individuals’ data from governments and private companies looking to extract and exploit it. The technical solutions developed in this frame are encryption standards and privacy enhancing technologies. However, intelligence agencies continue to frame the problem differently: they see it as an issue of collecting and aggregating data in order to identify malicious actors and threat vectors. The technical solutions they devise are increased surveillance and data analysis -- problems the first framing intended to solve. The techno-political gap, both in academic scholarship and global norms proliferation efforts continues to jeopardize attempts at framing cybersecurity governance.[20] Instead of artificially depoliticizing technology, it is imperative that we ferment political contestation in a manner that holistically promulgates the perception that internet infrastructure can be trusted and utilised by individuals and communities around the world.
Fostering ‘red lines’ and diffusing ‘unpeace’ in cyberspace
‘Unpeace’ in cyberspace continues to ferment through ‘below the threshold’ operations that do not amount to the ‘use of force’ as per Article 2(4), or an ‘armed attack’ triggering the right of self-defense under Article 51 of the United Nations Charter. This makes the application of jus ad bellum (‘right to war’) inapplicable to most cyber operations.[21] However, the application of ‘jus in bello’ (law that governs the way in which warfare is conducted) or International Humanitarian Law (IHL) does not require armed force to be of a specific intensity but seeks to protect civilians and prevent unnecessary suffering. Therefore the principles of IHL that have evolved in The Geneva Conventions should be used as red lines that limit collateral damage as a result of cyber operations.[22] No state should conduct cyber operations that intend to harm civilians, and should us all means at its disposal to avoid this harm to civilians. It should act in line with the principles of necessity[23] and proportionality.[24]
Cultivating ‘red lines’ is easier said than done. The debate around the applicability of IHL to cyberspace was one of the reasons for the breakdown of the fifth UN-GGE in 2017.[25] States have also been reluctant to state their positions on the rules developed by the International Group of Experts (IGE) in the Tallinn Manual.[26] This is due to two main reasons. First, not endorsing the rules may allow them to retain operational advantages in cyberspace where they continue engaging in cyber operations without censure. Second, even those states who wish to apply and adhere to the rules hesitate to do so in the absence of effective processes that censure states that do not comply with the rules.
Both these issues stem from the difficulties in attributing a cyber attack to a state as cyber attacks are multi-stage, multi-step and multi-jurisdictional, which makes the attacker several degrees removed from the victim.[27] Technical challenges to attribution, however should not take away from international efforts that adopt an integrated and multi-disciplinary approach to attribution which must be seen as a political process working in conjunction with robust technical efforts.[28] The Cyber Peace Institute, which was set up earlier in September 2019, and adopts an ecosystem approach to studying cyber attacks, thereby improving global attribution standards may institutionally serve this function.[29] As attribution processes become clearer and hold greater political weight, an increasing number of states are likely to show their cards and abandon their policy of silence and ambiguity -- a process that has already commenced with a handful of states releasing clear statements on the applicability of international law in cyberspace.[30]
Below the threshold operations are likely to continue. However, the process of contestation should result in the international community drawing out norms that ensure that public trust and confidence in the security of global digital infrastructure is not eroded. This would include norms such as protecting electoral infrastructure or a prohibition on coercing private corporations to aid intelligence agencies in extraterritorial surveillance29 The development of these norms will take time and repeated prodding. However, given the entangled and interdependent nature of the global digital economy, protracted effort may result in universal consensus in some time.
The Future of Cyber Diplomacy
The recently rejuvenated UN driven norms formulation processes are examples of this protracted effort. Both the Group of Governmental Experts (GGE) and Open-Ended Working Group (OEWG) processes are pushing states towards publicly declaring their positions on multiple questions of cyber governance, which will only further certainty and predictability in this space. The GGE requires all member states to clearly chart out their position on the applicability of various questions of International Law, which will be included as an Annex to the final report and is definitely a step in the right direction.
There are multiple lessons from parliamentary diplomacy culminating in past global governance regimes that negotiators in these processes can borrow from.[31] As in the past, the tenets of international law can influence collective expectations and serve as a facilitative mechanism for chalking out bargaining points, and driving the negotiations within an inclusive, efficient and understandable framework.[32]
Both processes will be politicized as before with states seeking to use these as fora for furthering national interests. However, this is not necessarily a bad thing. Protracted contestation is preferable to unilateralism where a select group of states decides the future of cyber governance. The inclusive, public format of the OEWG running in parallel to the closed-door deliberations at the GGE enables concerted dialogue to continue. Most countries had voted for the resolutions setting up both these processes and while the end-game is unknown, it appears that states remain interested in cultivating cyber norms.
Of course, the USA and its NATO allies had voted against the resolution setting up the OEWG and Russia, China and the SCO allies had voted against the resolution resurrecting the GGE. However, given the economic interests of all states in a relatively stable cyberspace, it is clear that both these blocks desire global consensus on some rules of the road for responsible behaviour in cyberspace. This means that both processes may arrive at certain similar outcomes. These outcomes might over time evolve into norms or even crystallise into rules of customary international law if they are representative of the interests of a large number of states.
However, sole reliance on state-centric mechanisms to achieve a stable governance regime may be misplaced. As seen with Dupont’s contribution to the Montreal Protocol that banned the global use of Chloro-Fluoro-Carbons (CFCs)[33] or the International Committee of the Red Cross’s concerted efforts in rallying states to sign the Additional Protocols to the Geneva Conventions[34], norm-entrepreneurship and the mantle of leadership in norm-entrepreneurship need not be limited to state actors. Non-state actors often have the gifts of flexibility and strategic neutrality that make them a better fit for this role than states. Microsoft’s leadership and its ascent to this leadership mantle in the cyber governance space must therefore be taken heed off. The key role it played in charting out the CyberSecurity Tech Accords, Paris Call for Trust and Security in Cyberspace and its most recent initiative, the Cyber Peace Institute, must be commended. However, the success of its entrepreneurship relies on how well it can work both with multilateral mechanisms under the aegis of the United Nations and multi-stakeholder fora such as the Global Commission on Stability in Cyberspace. This will lead to a cohesive set of rules that adequately govern the conduct of both state and non-state actors in cyberspace.
It is unfortunate, however, that most governance efforts in cyberspace are driven by the United States or China or their allies. For example, only UK[35], France[36], Germany,[37] Estonia[38],Cuba[39] (backed by China and Russia), and the USA[40] have all engaged in public posturing advocating their ideological position on the applicability of International Law in cyberspace in varying degrees of detail with other countries largely remaining silent. Other emerging economies need to get into the game to make the process more representative and equitable.
More recently, India has begun to take a leadership role in the global debate on cross-border data transfers, spurred largely by their domestic political and policy ecosystem championing ‘digital nationalism.’ At the G20 summit in Osaka in July this year, India, alongside the BRICS grouping emphasized the development dimensions of data for emerging economies and pushed the notion of ‘data sovereignty’-broadly understood as the sovereign right of nations to govern data within their territories/jurisdiction in the national interest and for the welfare of its people.[41] Resisting calls from Western allies including the United States to get on board Japan’s initiative promoting the free flow of data across borders, Vijay Gokhale also mentioned that discussions on data flows must not take place at plurilateral forums outside the World Trade Organization as this would prevent inclusive discussions.[42]This form of posturing should be sustained by emerging economies like India and extended to the security domain as well through which the hegemony that a few powerful actors retain over the contours of cyber governance can be reduced.
To paraphrase Clausewitz, technological governance is the conduct of politics by other means. Internet infrastructure has become so deeply intertwined with the political ethos of most countries that it has become the latest front for geopolitical contestation among state and non-state actors alike. Politicizing cyber governance prevents a deracinated approach to the process that ignores simmering inequalities, power asymmetries and tensions that a limited technical lens prevents us from viewing.
The question is, not if but how cyber governance will be politicized. Will it be a politics of inclusion that protects the rights of the disregarded and adequately represents their voices in line with the requirements of International Law, or will it be a politics of convenience through which states and non-state actors utilise cyber governance for reaping strategic dividends? The global cyber policy ecosystem must continue the battle to ensure that the former remains essential.
Endnotes
[1] Arindrajit Basu and Elonnai Hickok (2018) “Cyberspace and External Affairs: A memorandum for India”, 8-13.
[2] In its draft definition of cyber stability, The Global Commission on the Stability of Cyberspace has adopted a bottom up user centric definition of Cyber Stability where individuals can be confident in the stability of cyberspace as opposed to an objective top-down determination of cybersecurity metrics.
[3] PN Edwards, GC Bowker Jackson SJ, R Williams 2009. Introduction: an agenda for infrastructure studies. J. Assoc. Inf. Syst.10(5):364–74
[4] Brian Larkin, “ The Politics and Poetics of Infrastructure” Annual Rev. Anthropol 2013,42:327-43
[5] Ibid.
[6] Kieron O’Hara and Wendy Hall, “Four Internets: The Geopolitics of Digital Governance” CIGI Report No.208, December 2018.
[7] Cade Metz, “Paul Baran, the link between nuclear war and the internet” Wired, 4th Sept. 2012.
[8] Kal Raustila (2016) “Governing the Internet” American Journal of International Law 110:3,491
[9] Samantha Bradshaw, Laura DeNardis, Fen Osler Hampson, Eric Jardine & Mark Raymond, The Emergence of Contention in Global Internet Governance 3 (Global Comm’n on Internet Governance, Paper Series No. 17, July 2015).
[10] Klint Finley, "The Internet Finally Belongs to Everyone”, Wired, March 18th, 2016.
[11] Richard Stewart (2014), Remedying Disregard in Global Regulatory Governance: Accountability, Participation and Responsiveness” AJIL 108:2
[12] Tarun Chhabra, Rush Doshi, Ryan Hass and Emilie Kimball, “Global China: Domains of strategic competition and domestic drivers” Brookings Institution, September 2019.
[13] According to this view, a state can manage and define its ‘network frontiers; through domestic legislation or state policy and patrol information at it state borders in any way it deems fit. Yuan Yi,. “网络空间的国界在哪 ” [Where Are the National Borders of cyberspace]? 学习时报.May 19, 2016.
[14] Anthea Roberts, Henrique Choer Moraes and Victor Ferguson (2019), “Toward a Geoeconomic Order in International Trade and Investment” (May 16, 2019).
[15] Eurasia Group (2018), “The Geopolitics of 5G”
[16] Ibid.( In 2013, the Ministry of Industry and Information Technology (MIIT), the National Development and Reform Commission (NDRC) and the Ministry of Science and technology (MOST) established the IMT-2020 5G Promotion Group to push for a government all-industry alliance on 5G.)
[17] Bjorn Fagersten&Tim Ruhlig (2019), "China’s standard power and it’s geopolitical implications for Europe” Swedish Institute for International Affairs.
[18] Alan Beattie, “Technology: how the US, EU and China compete to set industry standards” Financial Times, Jul 14th, 2019
[19] Laura Fitchner, Walter Pieters.,&Andre Herdero Texeira(2016). Cybersecurity as a Politikum: Implications of Security Discourses for Infrastructures. In Proceedings of the 2016 New Security Paradigms Workshop (36-48). New York: Association for Computing Machinery (ACM)
[20] Michael Crosston,” Phreak the Speak: The Flawed Communications within cyber intelligentsia” in Jan-Frederik Kremer and Benedikt Muller,”Cyberspace and International Relations: Theory, Prospects and Challenges (2013, Springer) 253.
[21] “Fundamental Principles of International Humanitarian Law".
[22] Veronique Christory “Cyber warfare: IHL provides an additional layer of protection” 10 Sept. 2019.
[23] See (The “principle of military necessity” permits measures which are actually necessary to accomplish a legitimate military purpose and are not otherwise prohibited by international humanitarian law. In the case of an armed conflict, the only legitimate military purpose is to weaken the military capacity of the other parties to the conflict.
[24] See Proportionality; The principle of proportionality prohibits attacks against military objectives which are “expected to cause incidental loss of civilian life, injury to civilians, damage to civilian objects, or a combination thereof, which would be excessive in relation to the concrete and direct military advantage anticipated”
[25] Declaration by Miguel Rodriguez, Representative of Cuba, At the final session of group of governmental experts on developments in the field of information and telecommunications in the context of international security (June 23 2017).
[26] Dan Efrony and Yuval Shany (2018), “ A Rule Book on the Shelf? Tallinn Manual 2.0 on Cyberoperations and Subsequent State Practice” AJIL 112:4
[27] David Clark and Susan Landau. “Untangling Attribution.” Harvard National Security Journal (Harvard University) 2 (2011
[28] Davis, John S., Benjamin Adam Boudreaux, Jonathan William Welburn, Jair Aguirre, Cordaye Ogletree, Geoffrey McGovern and Michael S. Chase. Stateless Attribution: Toward International Accountability in Cyberspace. Santa Monica, CA: RAND Corporation, (2017). At
[29] See “CyberPeace Institute to Support Victims Harmed by Escalating Conflicts in Cyberspace”.
[30] Dan Efrony and Yuval Shany (2018), “ A Rule Book on the Shelf? Tallinn Manual 2.0 on Cyberoperations and Subsequent State Practice” AJIL 112:4
[31] Arindrajit Basu and Elonnai Hickok (2018), “Conceptualizing an International Security architecture for cyberspace”.
[32] Monica Hakimi (2017), “The Work of International Law,” Harvard International Law Journal 58:1.
[33] James Maxwell and Forrest Briscoe (2007),” There’s money in the air: The CFC Ban and Dupont’s Regulatory Strategy” Business Strategy and the Environment 6, 276-286.
[34] Francis Buignon (2004). “The International Committee of the Red Cross and the development of international humanitarian law.” Chi. J. Int’l L.5: 19137
[35] Jeremy Wright, “Cyber and International Law in the 21st Century” Govt. UK.
[36] Michael Schmitt, “France’s Major Statement on International Law and Cyber: An Assessment” Just Security, September 16th, 2019.
[37] Nele Achten, "Germany’s Position on International Law in Cyberspace”, Lawfare, Oct 2, 2018,
[38] Michael Schmitt, “Estonia Speaks out on Key Rules for Cyberspace” Just Security, June 10, 2019.
[39] https://www.justsecurity.org/wp-content/uploads/2017/06/Cuban-Expert-Declaration.pdf
[40] https://www.justsecurity.org/wp-content/uploads/2016/11/Brian-J.-Egan-International-Law-and-Stabilityin-Cyberspace-Berkeley-Nov-2016.pdf
[41] Justin Sherman and Arindrajit Basu, "Fostering Strategic Convergence in US-India Tech Relations: 5G and Beyond”, The Diplomat, July 03, 2019.
[42] Aditi Agrawal, "India and Tech Policy at the G20 Summit”, Medianama, Jul 1, 2019.
Comments to the Code on Social Security, 2019
CIS is an 11-year old non-profit organisation that undertakes interdisciplinary research oninternet and digital technologies from policy and academic perspectives. Through itsdiverse initiatives, CIS explores, intervenes in, and advances contemporary discourse andregulatory practices around internet, technology, and society in India, and elsewhere.Current focus areas include cybersecurity, privacy, freedom of speech and artificialintelligence. CIS is also producing research at the intersection of labour, gender andtechnology.
CIS is grateful for the opportunity to put forth its views and comments. Our comments are captured in the prescribed format in the table, click here to view the full comments.
Comments to the United Nations Human Rights Commission Report on Gender and Privacy
HRC Gender Report - Consultation version: Read (PDF)
Submitted comments: Read (PDF)
The Centre for Internet and Society (CIS), India, is an 11-year old non-profit organisation that undertakes interdisciplinary research on internet and digital technologies from policy and academic perspectives. Through its diverse initiatives, CIS explores, intervenes in, and advances contemporary discourse and regulatory practices around internet, technology, and society in India,and elsewhere. Current focus areas include cybersecurity, privacy, freedom of speech, labour and artificial intelligence. CIS has been taking efforts to mainstream gender across its programmes, as well as develop specifically gender-focused research using a feminist approach.
CIS appreciates the efforts of Dr. Elizabeth Coombs, Chair, Thematic Action Stream Taskforce on “A better understanding of privacy”, and those of Professor Joseph Cannataci, Special Rapporteur on the Right to Privacy. We are also grateful for the opportunity to put forth our views and comment on the HRC Gender Report.
Department of Labour Interaction Program: Online Business Platforms
The blog post was edited by Ambika Tandon.
The meeting was called to hear and address the grievances of gig workers, (employed by online business platforms) in the presence of their employers. The meeting was presided by the esteemed Labour Minister, Shri. Suresh Kumar, and the Secretary to the Labour Department, Shri Manivannan. The Minister began by disclosing that union members and delivery partners employed by online delivery companies (Swiggy, Zomato, Ola, Flipkart, etc.) had approached his office, with several complaints pertaining to the legal treatment or lack thereof, of gig workers across the nation. They also further identified the day-to-day concerns that they had to face (i.e. health & pay-related issues) as a consequence of their non-recognition under the labour law frameworks in the country.
"The majority of the delivery boys that aggregators (e.g. Swiggy, Ola, Uber, etc.) employ are full-time workers who depend solely on these companies for their income." That was the refrain of most of the spokespeople supporting the cause of gig workers. These were some of the representatives who spoke on behalf of the gig workers employed by online aggregators:
- Mr. G. S. Kumar (Food Delivery Partners Association)
- Mr. Tanveer Pasha (Ola driver)
- Mr. M. Manjunath (Auto Chalaka Okkuta)
- Mr. Amit Gupta (Brand Strategist)
- Ms. Kaveri (Researcher)
- Mr. Basavaraj (Food Delivery Association)
"The delivery partners employed by online aggregators should be treated as full-time employees"
Mr. G.S Kumar, an office-bearer at the Food Delivery Partners Samithi set the context for the conversation, by identifying at the very outset that the term "delivery partners" is a misnomer and that they are largely full-time employees. They are further straddled with family commitments, health concerns, and dwindling pay structures. As such, he proclaimed that they are deserving of the protections statutorily available to employees (in the traditional sense of the term) under the extant labour legislations. It was also specifically highlighted by Mr. K.S. Kumar, that in status quo, delivery boys cannot avail of ESI, or PF benefits.
Furthermore, the protections the companies make available are also quite abysmal, for instance a Rs. 2 lakh accidental cover that's rarely ever paid. The practical exigencies of their itinerant lifestyles inhibit them from maintaining strict compliance with the protocols that are unfortunately condition precedents to obtaining the benefits they so desperately require. The language of these policies in the fine print often contains conditions that are quite hard to satisfy, and as such, the benefits remain inaccessible to the vast majority of drivers employed by these online business platforms. Adding value to this criticism of Mr. K.S. Kumar, Mr. Basavaraj later clarified that conditions such as requiring 24 hours of admittance for the processing of insurance claims, makes it nigh impossible for drivers plying the roads to ever materially avail of health or accidental insurance.
"Ola/Uber drivers face serious health risks, as they ply the roads of Bangalore, and require functional insurance"
Tanveer Pasha, a member of the Ola/Uber Drivers Association, discussed the lived experiences of these delivery boys who ply the road, travelling nearly fifteen to twenty kilometres for each trip in peak Bangalore traffic. He narrated stories of trauma and violence faced by drivers, such as instances of heart attacks and accidents, which made the conversation a little heated. The minister then deftly interjected, by requesting them to be solution-centric, while discussing their grievances, as this aids the government's ability to balance the competing interests of both the aggregators and the gig workers.
"A Government ombudsman is required to address the grievances of gig workers"
To that effect, M. Manjunath from the Auto and Taxi Association asserted that insurance is a basic right that should be provided to the employees. Amit Gupta, Brand Strategist, spoke on behalf of his sister, previously employed at Swiggy, and stated that an ombudsman empowered to take complaints, even from gig workers, should be created. He believed this was imperative given that aggregators are de facto free to violate the terms and conditions prescribed in the employment order, as they have the resources to see the case through in court, whereas employees don't have much recourse, outside of trade unions. He concluded that for these delivery partners devoid of the right to collectivize, it becomes crucially important to maintain at the very least, a Government ombudsman.
"Aggregators should not profit off of the positive network effects gained through delivery partners, and simultaneously deny their right to protest unfair business practices"
Ms. Kaveri, a researcher on the conditions of gig workers, brought to light some of the more egregious problems that are faced by these workers. For instance, they are removed from employment, at a moment's notice if they attempt to protest, and to that effect, she stated that Zomato had fired an employee that very day because he was supposed to participate in the meeting and make his case. She further specified that it was patently unfair to allow these aggregators to profit off of the positive network effects gained solely because of the delivery partners, and subsequently engage in cost-cutting practices like reducing the incentives that they receive.
In response to these claims, the Labour Minister invited representatives of online platforms to shed some clarity on the concerns raised by the gig workers they employ.
These were some of the representatives who spoke on behalf of the online aggregators:
- Mr. Manjunath (Flipkart)
- Mr. Panduranga (Legal Team, Swiggy)
- Mr. Ashok Kumar (Zomato)
"Flipkart does provide significant benefits to its fixed-term contractors"
Mr. Manjunath clarified his position on these issues, with regards to Flipkart, by stating that there is a tripartite classification amongst people who work there:
a) Full-time employees
b) Fixed Term Contractors (e.g. 8 or 10-month contract)
c) Interns
He further affirmed that even for fixed term contractors, Flipkart offers ESI, and PF benefits. He also specified that they don't hire more employees or fixed-term contractors during peak season, but rather hire only interns to meet demand, as it offers the inexperienced interns a chance to gain industry exposure as well.
"Swiggy empowers the agency of its delivery partners, and provides necessary benefits"
Mr. Panduranga, from the legal department at Swiggy, in direct response to the concerns about Swiggy, stated that the gig economy is emergent and that Swiggy and other such aggregators are merely technology platforms, facilitating end-to-end services (between different stakeholders, e.g. customer-driver-restaurant). In that sense, he clarified that the delivery partners they employ have the right to accept or deny deliveries and that there is no compulsion to commit to the work. Moreover, he specified that merely logging off the app frees up a delivery partner of his or her time. He opined that they have the freedom to work for multiple companies, and the process of joining and leaving is highly flexible. In that sense, he stated that a large number of students and after-office hours employees are the ones employing these apps as a means to generating quick cash flows (and as such, should not be treated as full-time employees). He also mentioned that there is up to 1 lakh for medical expenses, (which are currently being disbursed), and Rs. 5 lakhs for accidental death coverage as well. Mr. Ashok Kumar from Zomato also reaffirmed the statements of Mr. Panduranga.
"Incentive and disincentive structures coercively compel gig workers to work hours akin to full-time employees"
Mr. Basavaraj from the Food delivery Association/Samithi, along with all the other representatives clarified that it is extremely unlikely that the majority of gig workers are part-time and only in it for generating quick money. Instead, the majority of gig workers work 9-12-hour workdays, and in that sense, are really no different from traditional employees. Basavaraj stated that an examination of the travel logs of delivery partners will make it clear whether the majority of workers are part-time or full time. He also pointed out that incentive and disincentive structures coercively compel drivers to work long hours with poor working conditions. For example, drivers who don't operate during peak hours do not receive the incentives they are promised. Further, the manner of advertisement of these jobs is itself insidious, as the salary offering is inclusive of the money one would receive if they also met their incentive-targets. Basavaraj specified that the deceptive advertising of these companies is what leads to massive hordes of gig workers working, in essence, full-time jobs, and as such, they must require the protection of their rights enshrined under labour legislations.
There was also collective agreement from the spokespeople making a case on behalf of the gig workers, that the benefits provided on paper (health insurance for accident cases) are rarely ever provided, and that the process of acquiring the same is rife with hassles. However, this was met with fervent opposition from the spokespeople representing the online aggregators, who contended that these insurance payments were being sanctioned freely without inconvenience.
Concluding Observations of the Labour Minister
The Labour Minister, Shri. Suresh Kumar, identified that this is an emergent issue; one that requires serious consideration, as the gig economy is here to stay. He reaffirmed the social responsibility of the Government to inspect this matter and set up a legal framework, as it concerns the deprivation of agency for lakhs of people working as gig workers in the state, and across the country. He also affirmed that he is cognizant of the business interests at play. To that effect, he declared that the Deputy Labour Commissioner, Shri. Balakrishnan would examine the relevant data at hand, hold necessary meetings with both parties, and submit a report on the creation of a prospective framework to regulate gig economies within one month. He stated that the Government will set up a framework with governing rules and regulations, based on the report submitted. He concluded by emphasizing the necessity for both parties to be trusting of one another and not render the working dynamic adversarial, however oppositional their competing interests maybe, as trust is a constitutive component of conflict resolution.
Through the looking glass: Analysing transparency reports
Over the past decade, a few private online intermediaries, by rapid innovation and integration, have turned into regulators of a substantial amount of online speech. Such concentrated power calls for a high level of responsibility on them to ensure that the rights of the users online, including their rights to free speech and privacy, are maintained. Such responsibility may include appealing or refusing to entertain government requests that are technically or legally flawed, or resisting gag orders on requests. For the purposes of measuring a company’s practices regarding refusing flawed requests and standing up for user rights, transparency reporting becomes useful and relevant.Making information regarding the same public also ensures that researchers can build upon such data and recommend ways to improve accountability and enables the user to understand information about when and how governments are restricting their rights.
For some time in the last decade, Google and Twitter were the only major online platforms that published half-yearly transparency reports documenting the number of content take down and user information requests they received from law enforcement agencies. In 2013 however, that changed, when the Snowden leaks revealed, amongst other things, that these companies were often excessively compliant with requests from US’ intelligence operations, and allowed them backdoor surveillance access to user information. Subsequently, all the major Silicon Valley internet companies have been attempting to publish a variance or other of transparency reports, in hopes of re-building their damaged goodwill, and displaying a measure of accountability to its users.
The number of government requests for user data and content removal has also seen a steady rise. In 2014, for instance Google noted that in the US alone, they observed a 19% rise for the second half of the year, and an overall 250% jump in numbers since Google began providing this information. As per a study done by Comparitech, India sent the maximum number of government requests for content removal and user data in the period of 2009 - 2018.8 This highlights the increasing importance of accessible transparency reporting.
Initiatives analysing the transparency reporting practices of online platforms, like The Electronic Frontier Foundation (EFF)’s Who Has Your Back? reports, for instance, have developed a considerable body of work tracing these reporting practices, but have largely focused at them in the context of the United States (US). In our research, we found that the existing methodology and metrics to assess the transparency reports of online platforms developed by organisations like the EFF are not adequate in the Indian context. We identify two reasons for developing a new methodology:
- Online platforms make available vastly different information for US and India. For instance, Facebook breaks up the legal requests it receives for US into eight different classes (search warrants, subpoenas, etc.). Such a classification is not present for India. These differences are summarised in Annexure
- The legal regimes and procedural safeguards under which states can compel platforms to share information or take content down also differ. For instance, in India, an order for content takedown can be issued either under section 79 and its allied rules or under section 69A and its rules, each having their own procedures and relevant authorities. A summary of such provisions for Indian agencies is given in Annexure 3.
These differences may merit differences in the methodology for research into understanding the reporting practices of these platforms, depending on each jurisdiction’s legal context.
In this report, we would be analyzing the transparency reports of online platforms with a large Indian user-base, specifically focusing on data they publish about user information and takedown requests received from Indian governments’ and courts.
First, we detail our methodology for this report, including how we selected platforms whose transparency reports we analyse, and then specific metrics relating to information available in those reports. For the latter, we collate relevant metrics from existing frameworks, and propose a standard that can be applicable for our research.
In the second part, we present company-specific reports. We identify general trends in the data published by the company, and then compare the available data to the best practices of transparency reporting that we proposed.
Download the full report. The report was edited by Elonnai Hickok. Research assistance by Keying Geng and Anjanaa Aravindan.
CIS’ Comments to the Christchurch Call
Fifty one supporters, including India, and eight tech companies have jointly agreed to a set of non-binding commitments and ongoing collaboration to eliminate violent and extremist content online. Facebook, Microsoft, Twitter, Google, and Amazon are all among the online service provider signatories that released a joint statement welcoming the call and committing to a nine-point action plan.
The Call has been hailed by many as a step in the right direction, as it represents the first collaboration between governments and the private sector companies to combat the problem of extremist content online at this scale. However, the vagueness of the commitments outlined in the Call and some of the proposed mechanisms have raised concerns about the potential abuse of human rights by both governments and tech companies.
This response is divided into two parts - Part One examines the call through the lens of human rights, and Part Two thinks through the ways in which India can adhere to the commitments in the Call, and compares the current legal framework in India with the commitments outlined in the Call.
Click to read the comments here. The comments were prepared by Tanaya Rajwade, Elonnai Hickok, and Raouf Kundil Peedikayil and edited by Gurshabad Grover and Amber Sinha.
Reliance Jio is using SNI inspection to block websites
This blogpost was written by Gurshabad Grover and Kushagra Singh, and edited by Elonnai Hickok.
Background
In April this year, several Jio users were puzzled to find that Reddit and Telegram were being blocked by the ISP. Around the same time, Sushant Sinha was perplexed to note that those using Jio connections were unable to access IndianKanoon.com, the legal database he founded and runs.
These experiences of arbitrary web censorship are the natural conclusion of an opaque legal framework that allows the Government of India to order ISPs to block certain websites for its users. The Central Government draws such powers from sections 69A and 79 of the Information Technology (IT) Act and the rules issued thereunder. Notably, the “blocking rules” issued under Section 69A describe an executive-driven process, and further mandate the confidentiality of blocking orders issued to intermediaries. These rules have meant that it is next to impossible for netizens to know the complete list of websites blocked in India and the reasons for such blocking.
Pertinently, the blocking rules do not mandate ISPs to use any particular technical method to block websites. This has meant that Indian ISPs are at liberty to pick whatever filtering mechanism they wish, which has had implications for how internet users experience and circumvent web censorship. Researchers at IIIT-Delhi have already documented Indian ISPs are using two methods:
-
Domain Name System (DNS) based blocking
Users trying to access websites usually contact the ISP’s DNS directory to translate a human-parseable address like ‘example.com’ to its network address ‘93.184.216.34’. Some ISPs in India, like BSNL and MTNL, respond with incorrect network addresses to the users’ queries for websites they wish to block. -
Hypertext Transfer Protocol (HTTP) header based blocking
HTTP is the most popular way to transmit web pages. Since classic HTTP communication is unencrypted, ISPs can monitor for the website’s name that is attached (the HTTP Host header field) to such traffic. ISPs like Jio, Airtel and Vodafone monitor this field for names of websites they wish to block, intercept such requests, and return anything they wish as a response.
Generally, ISPs’ use of either method directs users to a censorship notice when they find that the user is trying to access a ‘blocked’ website.
Image 1: The notice served by Jio (through HTTP-header based filtering and injected response) when a user tries to access a blocked website.
In this blogpost, we document how Jio is using, in addition to HTTP-based blocking, another censorship method: Server Name Indication (SNI) inspection. First, we explain what the SNI is. Then, we detail how you can independently confirm that Jio is using information in the SNI to block website access. In the end, we explain the implications of Jio’s decision.
SNI Inspection
Transport Layer Security (TLS) is a cryptographic protocol for providing communication confidentiality and authenticity, commonly used for encrypting web traffic (as done in HTTPS). The SNI, defined first in RFC 4366 and then in RFC 6066, is an extension to TLS designed to facilitate the hosting of multiple HTTPS websites on the same server. While establishing a secure connection (a TLS Client Hello), a client just fills in the SNI attribute with the hostname of the website it wishes to connect to.
SNI, unfortunately, travels on the network in cleartext, i.e. network operators can not only see the websites you’re visiting, but also filter traffic based on this information. The use of SNI inspection in state-directed web censorship was not very common until recently. Only this year, the use of SNI inspection to censor websites was documented in China and South Korea.
In the Indian context, the aforementioned paper, the researchers note that in Indian ISPs they investigated (including Jio), they “observed fewer than five instances of HTTPS filtering which were actually due to manipulated DNS responses [...], and not because of SNI field in TLS [...].” However, as the next section documents, Jio is now in fact using SNI-inspection based filtering.
The test
To run our tests, we can take advantage of the fact that Google's server is configured to respond successfully to TLS connection attempts even if we send an SNI with a website’s name that it does not host on that server.
Using OpenSSL's s_client utility, we attempt to establish a TLS 1.3 connection with an IP address (216.58.196.174) corresponding to google.com. However, instead of specifying 'google.com' in the SNI, we specify a potentially blocked website (PBW) 1337x.be.openssl s_client -state -connect 216.58.196.174:443 -servername 1337x.be -tls1_3
Two important notes here:
-
We are not connecting to the PBW at all! This simple approach is allowing us to rule out other censorship methods (like DNS, HTTP, and even IP/TCP-level blocking) from interfering with our results.
-
We’re using TLS 1.3 to make our connections. This is because in older versions of TLS, the server passes its certificate to the client in cleartext. ISPs may also be using that information to block websites if older TLS versions are used. Using TLS 1.3 allows us to ensure that ISPs are indeed using SNI inspection to block websites.
We notice that when we specify a PBW in the SNI, we receive a TCP packet with the RST (reset) bit set almost immediately after the connection is established, which closes the established connection. Of course, a plausible explanation could be that the Google server itself might be resetting the connection upon realising that it does not host the PBW. However, this is neither the expected behaviour as per RFC 6066, nor do we notice the server doing so in all cases where we specify a SNI for a website that it is not hosted on the server. For example, when we specify facebook.com as the SNI, not only are we able to complete the TLS handshake but we're also able to make subsequent requests to the server after completing the handshake (albeit receiving an expected "not found" error in response).
You can find and compare the OpenSSL requests and responses for a PBW (1337x.be) and an uncensored website (facebook.com) here.
A caveat here is that we do not always notice such behaviour. For instance, while trying to detect such censorship, we found that connecting to one of Google’s IP address (216.58.196.174) resulted in connection resets. Whereas doing the same with a different IP address which google.com resolves to (172.217.161.14) resulted in successful connections. This seems to suggest that Jio has employed a limited number of middleboxes inspecting and filtering traffic based on the SNI.
Implications
The scale of users impacted by this technical choice is huge: according to data released by the Telecom Regulatory Authority of India last month, Jio is the most popular ISP in India. It currently serves 331.25 million internet subscribers in the country, which constitute 49.79% of internet subscribers in India. If Jio installs middleboxes at enough points across the regions it serves, all Jio customers potentially face SNI-based censorship.
The technical methods that ISPs use to implement website censorship have direct implications for how easily users can access blocked websites. Working around DNS spoofing, for example, can be fairly simple: one can change system settings to use to one of the many censorship-free DNS resolvers. The paper by IIIT-Delhi researchers also found that circumventing HTTP-based censorship is easy in India because of how ISPs are implementing the mechanism. The currently documented ways for clients to bypass SNI-based censorship is by either not specifying an SNI or specifying a modified SNI while connecting to the blocked website. However, both these approaches can be futile as the server hosting the website might close the connection upon observing such an SNI. To effectively circumvent SNI-based censorship, Jio users may have no choice but to resort to using Tor or VPNs to access blocked websites.
Another aspect is how the technical method chosen by ISPs can have implications for transparency in censorship. As pointed out in the beginning of the blogpost, the legal framework of web censorship in India lacks transparency, fails to make the Government accountable for its orders, and places no obligations on ISPs to be transparent about the websites they block or the methods they use for doing so. The choice of Jio to use SNI-inspection based filtering to implement web censorship aggravates this already-opaque system because it is technically impossible to serve censorship notices using this method. TLS is designed in a way that clients abort connections when they detect interception and on-path attacks. Thus, Jio can only create connection failures when it wishes to block websites using SNI inspection. Since users facing SNI-based censorship will not see censorship notices, they may be left confused as to whether the website they wish to access is unavailable, or being blocked by the ISP.
Image 2: Error users will face when Jio censors websites with SNI-based filtering.
The way forward
There is already ongoing work in the TLS working group at the Internet Engineering Task Force to encrypt the SNI. When there is wide deployment of encrypted SNI, we can expect SNI-inspection based filtering to be ineffective. However, the group currently faces several thorny design problems; of primary relevance in this context is how TLS connection attempts that use encrypted SNI should not “stick out”, i.e. such traffic should not be easily distinguishable from TLS connection attempts that use cleartext SNI. Traffic relying on implementations of encrypted SNI that “stick out” can be filtered out, as South Korean networks are doing already. Hopefully, we can expect that no Indian ISP will take such drastic measures.

Event Report: Consultation on Draft Information Technology (Fintech Security Standards) Rules
By: Anindya Kanan
Reviewed and Edited by: Vipul Kharbanda and Elonnai Hickok
Edited by: Arindrajit Basu
Introduction
The Centre for Internet and Society is in the process of drafting certain data security standards for Fintech entities. As part of the process of drafting, a consultation roundtable was organized to get inputs from industry executives, lawyers and policy experts working in this field. Their industry knowledge and experience of dealing with these regulatory issues. The regulatory framework for data protection by Fintech entities is currently governed by the generic data protection laws of India enumerated in section 43A of the Information Technology Act, 2000, as well as the Information Technology (Reasonable security practices and procedures and sensitive personal data or information) Rules, 2011 (SPDI Rules) issued under it. The problem is that the SPDI Rules lack any specific protocols to be followed by Fintech entities, whereby they can satisfy their obligations under section 43A of the IT Act.
Thus there is a need for a concrete framework for information security which can be used by entities working in this space. The SPDI rules refer ISO 27001 as one possible standard but certification under it isn't economically feasible for most small businesses to implement. The Draft Information Technology (Fintech Security Standards) Rules (“Fintech Rules”) being proposed by CIS is meant specifically to provide a mechanism for compliance to the smaller businesses in the fintech space. The schedule to the Draft fintech rules provides clear guidelines to be followed by a fintech entity to deem it to be in compliance with section 43A of the IT Act. As mentioned, the roundtable consultation was an effort to get inputs from independent sources including legal experts, academics and those working in the industry.
Session 1
This session dealt with the need for these fin-tech rules and how they address the shortcomings in the law as mentioned above. The session started with the drafter giving a brief introduction on the scope and objective of these rules as well as their importance. Then they went ahead with the reading of the rules with discussion on every section. The drafter then explained the objective behind that section and the participants gave their inputs on it. The various concerns raised by the participants during the session are given below.
Scope of Data protected by the draft fintech rules
The participants raised concerns that the draft Fintech Rules proposed by CIS only safeguard the confidentiality of sensitive personal data and information as defined in section 3(1) of the SPDI rules and not other data that may be in possession of a fintech entity. Thus they expressed a need to bring not just sensitive personal data within the ambit of these security standards but to expand the definition in the interest of data privacy of the users. It was clarified that though the review of the definition of sensitive personal data and information is outside the scope of the draft fintech rules ,the drafters have tried to include a wider ambit of data under it as Section 3(2) puts an obligation to also protect vital data and information. The drafters agreed to take this under review for future drafts.
Updation of the security standards
The schedule to the fintech rules drafted by CIS provides Information security practices which would provide reasonable levels of security from the currently known threats. But the threat environment is ever-changing as thousands of new malware are created each day and malicious actors are looking for vulnerabilities in every security infrastructure. Thus, even though the information security practices are adequate in the present day there is a real risk of them getting obsolete very fast. To counter this risk section Section 3(2)[1] provides for updation of these security standards from time to time. A concern was thus raised at this juncture about there not being a fixed timeline for upgradation to a new standard by the fin-tech entities. Further it was pointed out that there was no provision for a periodic audit and certification of the security practices unlike the SPDI rules{Section 8(4)} which are meant to ensure government oversight on the fin-tech firms.
The drafters then explained that these rules are meant as a positive obligation for the fin-tech entities to adopt on their own free will so as to show compliance with “reasonable security practices and procedures” and thus limit their liability in case of an action under 43A of the IT act. Thus oversight by the government through audits are excluded by design, further the individual companies have to decide on the time-frame for upgradation of their security practices based on the latest standards when they think is reasonable or expedient for them to do based on their individual case.
Example - Say there were two security standards one enacted in 2011 and the other in 2016 now a fin-tech entity in 2019 has to decide which one of the two would be reasonable to comply with to ensure effective data security. The reasonableness would also depend upon the specific technologies used or the type of information the firm handles or the type of users they have to name a few factors. Finally it would be up to the court to decide whether a firm’s practice was reasonable or not based on the individual case of that fintech entity. This was opposed by the industry executives as they wanted to have a fixed standard for compliance as later the interpretation of the court could go either way when deciding the case. Further the legal experts also favoured having fixed standards rather than one based on reasonableness. They felt that the courts would need an authoritative source and these rules could be that authoritative source for the courts to base their decisions on. This point was then taken under review for later drafts.
Miscellaneous
A concern was raised about there being no timeline for reporting the breach to the user but only for reporting it to CERT. The drafter replied with the standard being ”without undue delay” which would though based on this input be reviewed for later drafts. Another reason for not providing a firm time limit is so that fintech entities have the time to investigate the causes for the breach and are able to give a more complete picture to their customers when they are notified, so as not to cause undue panic amongst them. However, the drafters said that they would review this provision so that it is not misused.
A clarification was asked about the stage at which the rules became applicable (does this include beta testing as well?). The rules are extremely clear with their application being to any fintech entity handling sensitive personal data and information and thus would apply at all stages when any user data is used (including beta testing).
The participants also made suggestions with regards to introducing penalties and defining wrongful gain and wrongful loss in the specific context of data loss or misuse to bring more clarity on this issue.
The session came to a close with reiteration of the fact that these draft fintech rules are only an enabling provision to improve compliance rates by making it economically feasible for smaller fin-tech entities. This helps foster growth in a new and emerging field like fin-tech while also safeguarding user interests of privacy and data security.
Session 2
Session 2 dealt with the schedule of the Draft fintech rules which specified the actual technical requirements which the fin-tech entities would have to fulfil to comply with the rules. The session started with the drafters explaining how these rules would less onerous on the fin-tech entities as compared to ISO standards. The Draft security standards have simpler technical guidelines that place a lower and less granular threshold of technical compliance on the fintech entity, in addition to not requiring external ISO certification which comes with a prohibitively high financial cost. The session progressed with the drafter and the participants discussing each of the sections of the schedule. The concerns raised and the discussions following them are given below.
Limitation of scope to Information Security
A clarification was asked for the reason for limiting the scope of the rules to only infosec and not the whole of cybersecurity. The drafters said that as the rules specifically deal with compliance under section 43A of the IT Act which penalises entities in case of negligence in handling of data. Thus security standards for information security were thought to be adequate to fulfil this requirement and cybersecurity was deemed to thus be out of the scope of these draft fintech rules.
A concern was raised with regards to the physical security requirement under the schedule. Increasingly fintech entities are using commercial cloud storage providers for their data storage needs and thus are not in control of the physical premises where their data is stored and thus firms would be unable to comply with these requirements. After some discussion the consensus that was reached was that the fintech entity would have to indirectly ensure compliance by only opting for reputed or properly certified cloud providers but even in the case of a data breach on their end the fintech entity will have to prove in the court that it wasn’t negligent in choosing the cloud provider. A recommendation was floated to include the phrase “where applicable” in the clause for physical safety that only when a fintech entity has control over the physical infrastructure of its data storage systems would it be required to fulfil this obligation. This recommendation was taken for review for later drafts.
Based on the recommendations of the industry executives some parts of the schedule were omitted due to the requirements under them already being fulfilled through SPDI rules. For instance rules relating to Migration controls which deal with transfer of data from one system to another were omitted as they were thought to have been adequately dealt within SPDI rules.
Maintenance of standardised logs
Another concern was raised on the requirement of standardised Log entries by the industry executives. They pointed out that in general logging is a good practice to ensure that unauthorized access or malicious activity can be traced but the form of the logs would depend a lot on the system or the software one was using and thus having a standardised log for such different systems would not be possible. This suggestion was taken under review for later drafts. Further concerns were raised about the time period for log-retention and the drafters decided that they would address this issue in later drafts. It was recommended that access logs as well as end-user logs also be included under this requirements which was then flagged for review by the drafters.
Compliance with requirements for malware protection and wireless security
With regards to the requirements for malware protection and wireless security, the industry experts felt that the rules were very specific and inapplicable to a lot of systems that people in different parts of the fintech industry use. They also were of the view that these practices would get outdated pretty soon.
They further pointed out that the compliance standards in the draft were impractical especially for fintech entities working in co-working spaces or decentralised networks as the fintech entity would not be in control of the network hardware. The drafters explained that the draft fintech rules could be updated from time to time to tackle these issues. Alternatively, it was suggested that for niche areas like wireless security and malware protection, the rules can refer to a widely accepted standard or practices in the tech industry (FIPS and OWASP guidelines for secure coding practices were given as examples).
A general consensus was reached that the guidelines should focus more on concepts/abstractions of security practices rather than the specific mechanisms. However,the specific security mechanisms were considered to have their own benefits in the form of crystallizing the steps required to be taken for compliance.
Conclusion
The discussion was concluded with a note of thanks to all participants for their invaluable contribution to further the development of these security standards. The participants raised pertinent concerns about the structure as well as the framework of these rules and various parts of the draft which were welcomed by the drafters who flagged them for review for future versions. Furthermore participants gave crucial inputs on the changing nature of the industry and the need to have a more principle based approach to the technical framework. The discussion concluded on the consensus that there was a need for flexible guidelines which take into account the fast-changing nature the fintech industry as a whole and the unique nature of work that any entity does under it so as to not stifle growth but without compromising on the need for data security for the users of these services.
CIS will be circulating the draft guidelines publicly for wider stakeholder inputs.
India’s Role in Global Cyber Policy Formulation
The article by Arindrajit Basu was published in Lawfare on November 7, 2019. The article was reviewed and edited by Elonnai Hickok and Justin Sherman.
The onslaught of recent developments demonstrates how India can shape cyber policy debates. Among emerging economies, India is uniquely positioned to exercise leverage over multinational tech companies due to its sheer population size, combined with a rapid surge in users coming online and the country’s large gross domestic product. India occupies a key seat at the data governance table alongside other players like the EU, China, Russia and the United States — a position the country should use to promote its interests and those of other similarly placed emerging economies.
For many years, the Indian population has served as an economic resource for foreign, largely U.S.-based tech giants. Now, however, India is moving toward a regulatory strategy that reduces the autonomy of these companies in order to pivot away from a system that recently has been termed “data colonialism”—in which Western technologies use data-driven revenue bolstered by information extracted from consumers in the Global South to consolidate their global market power. The policy thinking underpinning India’s new grand vision still has some gaps, however.
Data Localization
Starting with a circular from the Reserve Bank of India in April 2018, the Indian government has introduced a range of policy instruments mandating “data localization”—that is, requiring that certain kinds of data must be stored in servers located physically within India. A snapshot of these policies is summarized in the table below.

(Source here. Design credit: Saumyaa Naidu)
While there are a number of reasons for this maneuver, two in particular are in line with India’s broader vision of data sovereignty—broadly defined as the sovereign right of nations to govern data within their territory and/or jurisdiction in order to support their national interest for the welfare of their citizens. First, there is an incentive to keep data within India’s jurisdiction because of the cumbersome process through which Indian law enforcement agencies must go during criminal investigations in order to access data stored in the U.S. Second, data localization undercuts the extractive economic models used by U.S. companies operating in India by which the data generated by Indian citizens is collected in India, stored in data centers located largely in the U.S., and processed and analyzed to derive commercially valuable insights.
Both foreign players and smaller Indian private-sector actors were against this move. A study on the issue that I co-authored earlier this year with Elonnai Hickok and Aditya Chawla found that one of the reasons for this resistance involved the high costs of setting up the data centers that are needed to comply with the requirement. President Trump echoed this sentiment when he explicitly opposed data localization during a meeting with Prime Minister Narendra Modi on the sidelines of the G-20 in June 2019.
At the same time, large Indian players such as Reliance and Paytm and Chinese companies like AliBaba and Xilink were in favor of localization—possibly because these companies could absorb the costs of setting up storage facilities while benefiting from the fixed costs imposed on foreign competition. In fact, some companies, such as AliBaba, have already set up storage facilities in India.
As my co-authors and I noted, data localization comes with various risks, both diplomatically and politically. So far, the issue has caused friction in U.S.-India trade relations. For example, before Secretary of State Mike Pompeo's trip to New Delhi in June, the Trump administration reportedly contemplated limiting H-1B visas for any country that implements a localization requirement. Further, on his trips to New Delhi, Commerce Secretary Wilbur Ross has regularly argued that data localization restrictions are a barrier to U.S. companies and stressed the need to eliminate such barriers. Further, data localization poses several technical challenges as well as security risks. Mirroring data across multiple locations, as India’s Draft Personal Data Protection Bill mandates, increases the number of physical data centers that need to be protected and thereby the number of vulnerable points that malicious actors can attack.
Recently, the Indian media have reported disagreements between policymakers over data localization, along with speculation that the data storage requirement in the Draft Personal Data Protection Bill could be limited only to critical data—a term not defined in the bill itself—or be left to sectoral regulators, officials from individual government departments.
Our paper recommended a dual approach. In our view, data localization policy should include mandatory localization for critical sectors such as defense or payments data, while also adopting “conditional” localization for all other data. Under conditional localization, data should only be transferred to countries that (a) agree to share the personal data of Indian citizens with law enforcement authorities based on Indian criminal procedure laws (examples of such a mechanism may be an executive data-sharing agreement under the CLOUD Act) and (b) have equivalent privacy and security safeguards. This approach would be in line with India’s overarching vision of data sovereignty and the goal of standing up to the hegemony of big tech and of U.S. internet regulations, while avoiding undue collateral damage to India’s global alliances.
Intermediary Liability
In line with the goal of ensuring that big tech is answerable to the rule of law, the Indian government has also sought to regulate the adverse social impacts of some speech hosted by platforms. Rule 3(9) of the Draft of the Information Technology Intermediaries Guidelines (Amendment) Rules, 2018, released by the Ministry of Electronics and Information Technology in December 2019, takes up the interventionist mission of laws like the NetzDg in Germany. The regulation would mandate that platforms use “automated tools or appropriate mechanisms, with appropriate controls, for proactively identifying and removing or disabling public access to unlawful information or content.” These regulations have prompted concerns from both the private sector and civil society groups that claim the proposal fails to address constitutional concerns about algorithmic discrimination, excessive censorship and inappropriate delegation of legislative powers under Indian law. Further, some observers object that the guidelines adopt a “one-size-fits-all” approach to classifying intermediaries that does not differentiate between platforms that thrive on end-to-end encryption like WhatsApp and public platforms like Facebook.
In many ways, these guidelines—likely to be notified (as an amendment to the Information Technology Act) as early as January 2020—put the cart before the horse. Before devising regulatory models appropriate for India’s geographic scale and population, it is first necessary to conduct empirical research about the vectors through which misinformation spreads in India and how misinformation impacts different social, economic and linguistic communities, along with pilot programs for potential solutions to the misinformation problem. And it is imperative that these measures be brought in line with constitutional requirements.
Community Data and “Data as a Public Good”
Another important question involves the precise meaning of “data” itself—an issue on which various policy documents have failed to deliver a consistent stance.
The first conceptualization of “community data” appears in both the Srikrishna Committee Report that accompanied the Draft Personal Data Protection Bill in 2018 and the draft e-commerce policy. However, neither policy provides clarity on the concept of data.
When defining community data, the Srikrishna Report endorses a collective protection of privacy as protecting an identifiable community that has contributed to community data. According to the Srikrishna Report, receiving collective protection requires the fulfillment of three key aspects. First, the data belong to an identifiable community. Second, the individuals in the community consent to being a part of the community. And third, the community as a whole consents to its data being treated as community data.
The draft e-commerce policy reconceptualizes the notion of community data as “societal commons” or a “national resource,” where the undefined ‘community” has rights to access data but the government has overriding control to utilize the data for welfare purposes. Unlike the Srikrishna Report, the draft e-commerce policy does not outline the key aspects of community data. This approach fails to demarcate a clear line between personal and nonpersonal data or to specify any practical guidelines or restrictions on how the government can use community data. For this reason, implementation of this policy could pose a threat to the right to privacy that the Indian Supreme Court recognized as a fundamental right in 2017.
The second idea is that of “data as a public good.” This is described in Chapter 4 of the 2019 Economic Survey Report—a document published by the Ministry of Finance along with the Annual Financial Budget. The report explicitly states that any data governance framework needs to be deferential to privacy norms and the soon-to-be-enacted privacy law. The report further states that “personal data” of an individual in the custody of a government is a “public good” once the datasets are anonymized.
However, the report’s recommendation of setting up a government database that links several individual databases together leads to the “triangulation” problem, in which individuals can be identified by matching different datasets together. The report further suggests that the same data can be sold to private firms (though it is unclear whether this includes foreign or domestic firms). This directly contradicts the characterization of a “public good”—which, by definition, must be nonexcludable and nonrivalrous—and is also at odds with the government’s vision of reining in big tech. The government has set up an expert committee to look into the scope of nonpersonal data, and the results of the committee’s deliberations are likely to influence the shape that India’s data governance framework takes across multiple policy instruments.
There is obviously a need to reassess and reevaluate the range of governance efforts and gambits that have emerged in the past year. With domestic cyber policy formulation pivots reaching a crescendo, we must consider how domestic cyber policy efforts can influence India’s approach to global debates in this space.
India’s Contribution to Global Cyber Policy Debates
As the largest democracy in the world, India is undoubtedly a key “digital decider” in shaping the future of the internet. Multilateral cyber policy formulation efforts remain polarized. The U.S. and its European allies continue to advocate for a free, rules-based conception of cyberspace with limited governmental interference. China and Russia, along with their Shanghai Cooperation Organisation allies, are pushing for a tightly regulated internet in which each state has the right to manage and define its “network frontiers” through domestic regulation free from external interference. To some degree, India is already influencing debate over the internet through its various domestic cyber policy movements. However, its participation in international debates has been lacking the vigor or coherence needed to clearly articulate India’s national interests and take up a global leadership role.
In shaping its contributions to global cyber policy formulation, India should focus its efforts on three key places: (a) internet governance forums that deliberate the governance of the technical architecture of the internet such as domain names, (b) cyber norms formulation processes that seek to establish norms to foster responsible behavior in cyberspace by states and nonstate actors in cyberspace, and (3) global debates on trade and cross-border data flows that seek to conceptualize the future of global digital trade relationships. As I discuss below, there are key divisions in Indian policy in each of these forums. To realize its grand vision in the digital sphere, India needs to do much more to make its presence felt.
Internet Governance Forums
India’s stance on a variety of issues at internet governance forums has been inconsistent, switching repeatedly between multilateral and multistakeholder visions for internet governance. A core reason for this uncertainty is the participation of multiple Indian government ministries, which often disagree with each other. At global internet governance forums, India has been represented either by the Department of Electronics and Information Technology (now renamed to Ministry of Electronics and Information Technoloft or the Department of Telecommunications (under the Ministry of Communications and Information Technology) or by the Ministry of External Affairs (MEA).
As my colleagues have documented in a detailed paper, India has been vocal in global internet governance debates at forums including the International Telecommunications Union, the Internet Governance Forum and the U.N. General Assembly. However, the Indian stance on multistakeholderism has been complex, with the MEA advocating for a multilateral stance while the other departments switched between multistakeholderism and “nuanced multilateralism”—which calls for multistakeholder participation in policy formulation but multilateral implementation. The paper also argues that there has been a decline recently in the vigor of Indian participation at forums such as the 2018 meeting of the Working Group on Enhanced Co-operation (WGEC 2.0), due to key personnel changes. For example, B.N. Reddy, who was a skilled and experienced negotiator for the MEA in previous forums, was transferred to another position before WGEC 2.0, and the delegation that attended the meeting did not make its presence felt as strongly or skillfully.
Cyber Norms for Responsible State Behavior in Cyberspace
With the exception of two broad and unoriginal statements at the 70th and 71st sessions of the U.N. General Assembly, India has yet to make public its position on the multilateral debate on the proliferation of norms for responsible state behavior in cyberspace. During the substantive session of the Open-Ended Working Group held in September, India largely reaffirmed points made by other states, rather than carving out a new or original approach. The silence and ambiguity is surprising, as India has been represented on four of the five Groups of Governmental Experts (GGEs) set up thus far and has also been inducted into the 2019-2021 GGE that is set to revamp the global cyber norms process. (Due to the GGE’s rotational membership policy, India was not a member of the fourth GGE that submitted its report in 2015.)
However, before becoming an evangelist of any particular norms, India has some homework to do domestically. It has yet to advance a clear, coherent and detailed public stance outlining its views on the application of international law to cyberspace. This public stance is necessary for two reasons. First, a well-reasoned statement that explains India’s stance on core security issues—such as the applicability of self-defense, countermeasures and international humanitarian law—would show India’s appetite for offensive and defensive strategies for external adversaries and allies alike. This would serve as the edifice of a potentially credible cyber deterrence strategy. Second, developing a public stance would help India to take advantage of the economic, demographic and political leverage that it holds and to assume a leadership role in discussions. The U.K., France, Germany, Estonia, Cuba (backed by China and Russia) and the U.S. have all made their positions publicly known with varying degrees of detail.
Data Transfers
Unlike in other forums, Indian policy has been clearer in the cross-border data transfer debate. This is a foreign policy extension of India’s emphasis on localization and data sovereignty in domestic policy instruments. At the G-20 Summit in Osaka, India and the rest of the BRICS group (Brazil, Russia, China and South Africa) stressed the role that data play in economic development for emerging economies and reemphasized the need for data sovereignty. India did not sign the Osaka Declaration on the Digital Economy that kickstarted the “Osaka Track”—a process whereby the 78 signatories agreed to participate in global policy discussions on international rule-making for e-commerce at the World Trade Organization (WTO). This was a continuation of India’s sustained efforts opposing the e-commerce moratorium at the WTO.
The importance of cross-border data flows in spurring the global economy found its way into the Final G-20 Leaders Declaration—which India signed. Foreign Secretary Vijay Gokhale argued that international rule-making on data transfers should not take place in plurilateral forums outside the WTO. Gokhale claimed that limiting the debate to the WTO would ensure that emerging economies have a say in the framing of the rules. The clarity expressed by the Indian delegation at the G-20 should be a model for more confident Indian leadership in this global cyber policy development space.
Looking Forward
India is no newcomer to the idea of normative leadership. To overcome material shortcomings in the nation’s early years, Jawaharlal Nehru, the first Indian prime minister, engineered a normative pivot in world affairs by championing the sovereignty of countries that had gained independence from colonial rule. In the years immediately after independence, the Indian foreign policy establishment sought to break the hegemony of the United States and the Soviet Union by advancing a foreign policy rooted in what came to be known as “nonalignment.”
Making sound contributions to foreign policy in cyberspace requires a variety of experts—international lawyers, computer scientists, geopolitical strategists and human rights advocates. Indian civil society and academia are brimming with tech policy enthusiasts from a variety of backgrounds who could add in-depth substance to the government’s cyber vision. Such engagement has begun to some extent at the domestic level: Most government policies are now opened up to consultation with stakeholders Yet there is still room for greater transparency in this process.
India's cyber vision is worth fighting for. The continued monetization of data dividends by foreign big tech at the expense of India’s socioeconomic development needs to be countered. This can be accomplished by predictable and coherent policymaking that balances economic growth and innovation with the fundamental rights and values enshrined in the Indian Constitution, including the right to equality, freedom of speech and expression, and the right to life. But inherent contradictions in the conceptualization of personal data, delays in tabling the Personal Data Protection Bill, and uncertain or rushed approaches in several other regulatory policies are all fettering the realization of this vision. On core geopolitical issues, there exists an opportunity to set the rule-shaping agenda to favor India’s sovereign interests. With global cyber policy formulation in a state of flux, India has the economic, demographic and intellectual leverage to have a substantial impact on the debate and recraft the narrative in favor of the rapidly emerging Global South.
Guest post: Before cyber norms, let’s talk about disanalogy and disintermediation
By: Pukhraj Singh
Reviewed and Edited by: Elonnai Hickok, Arindrajit Basu, and Karan Saini
The ongoing decoupling of norms
In September 2019, the French ministry of defense published a document stating its views on the applicability of international law to cyber operations. While it makes an unequivocal espousal of the rules-based order in cyberspace, some of the distinctions made by the paper within the ambit of international law could be of interest to technical experts.
The document makes two key contributions. First, it addresses two modes of power projection within cyberspace: cyber operations acting as a force multiplier in a hot war that is strictly delineated by kinetic and geographical redlines; and below-threshold, single-domain “dematerialized” operations leveraging cyber intrusions. Secondly, the document has made an attempt to gently decouple itself from the Tallinn Manual on some aspects.
In an unrelated development, Microsoft joined hands with a group of peers within the technology industry, civil society and government to set up the CyberPeace Institute – a private sector initiative to strengthen the rules-based order.
It is an outcome of the sustained, unrelenting effort of Microsoft in thwarting what it believes to be the unchecked weaponization of cyberspace. Suffering a major reputational loss after the Snowden leaks, the company has gradually cultivated fiercely contrarian positions on issues like state-enabled surveillance.
Microsoft’s daring contests and cases against the US government have been intimately recorded in the recently released book Tools and Weapons, authored by its chief legal officer Brad Smith.
Seen through the lens of the future, the aforementioned developments highlight the ongoing readjustment of the legal discourse on cyber operations to account for its incongruous technical dynamics.
As the structures of cyber power are peeled layer-by-layer, the need to address this technical divergence in the overly legal interpretations of cyber norms would only increase.
Disanalogy & disintermediation
Take the case of two fundamental dimensions – disanalogy and disintermediation – which have the potential to alter our understanding of how power is wedded with cyberspace.
Disanalogy is a logical postulation that challenges the primacy of “reasoning by analogy” using which international law is mapped to cyber conflict. Disintermediation highlights how the power dynamics of cyberspace have disrupted statism.
Understanding when and how the realization that international law is reasonably applicable to cyber operations dawned upon the international community leads one to an unending maze. It becomes a cyclical process where one set of initiatives only cross-reference the others, in a self-fulfilling sort of way.
The notes of the 2013 session of the United Nations’ Governmental Group of Experts, affirming the sanctity of international law in cyberspace, look like an exercise in teleology.
Not to be distracted by the deeply philosophical nature of war, Kubo Mačák of the University of Exeter did point out that “the unique teleological underpinning of the law of war” should be considered before it is exported to new normative frameworks.
The deductive process inspired by reasoning by analogy that lies at the heart of the cyber norms discourse has not undergone much scrutiny.
In his 2013 talk at NATO’s CCDCOE, Selmer Bringsjord, cognitive sciences professor at the Rensselaer Polytechnic Institute, introduced the idea of disanalogy. Citing the general schema of an analogical argument, Bringsjord arrived at a disproof divorcing the source domain (the just war theory for conventional war) and target domain (just war theory for cyberwar).
He mapped jus in bello in a conventional war across the dimensions of Control, Proportionality, Accessibility, and Discrimination.
Bringsjord further added that these source attributes would not be evident in the target domain for two reasons: the inevitable digitization of every analog object and its interfaces; and the inherent propensity of artificial intelligence to wage attacks on its own.
In a supporting paper, he exhorts that while “Augustine and Aquinas (and their predecessors) had a stunningly long run…today’s world, based as it is on digital information and increasingly intelligent information-processing, points the way to a beast so big and so radically different, that the core of this duo’s insights needs to be radically extended.”
Celebrated malware reverse engineer Thomas Dullien, too, is of the opinion that machine learning and artificial intelligence are more suited for cyber offence as it has remained a “stable-in-time distribution.”
Brandon Valeriano of the Marine Corps University has drawn upon the case of incendiary balloons to question the overreliance on reasoning by analogy. Sadly, such viewpoints remain outliers.
Senior computer scientist David Aucsmith wrote in Bytes, Bombs and Spies that “one of the major challenges in cyberspace is the disintermediation of government.” He adds that while cyberspace has become the “global center of gravity for all aspects of national power,” it further removes the government from the “traditional functions of safety and security.”
The commercialized nature of the Internet is obvious to many. But steadily over the years, the private sector has also acquired vast swathes of cyber power in a manner that strangely mirrors the military concepts of counterintelligence, defense and deterrence.
In Tools and Weapons, Brad Smith recalls a meeting of top technology executives at the White House. As the executives pushed for surveillance reform after the Snowden leaks, Obama defensively retorted that “the companies at the table collectively had far more data than the government.” The “signals intelligence” capabilities of Google and Microsoft rival that of a nation state.
Former deputy director of the NSA Chris Inglis writes in Bytes, Bombs and Spies:
In cyberspace, a small change in configuration of the target machine, system, or network can often negate the effectiveness of a cyber weapon against it. This is not true with weapons in other physical domains…The nature of target-weapon interaction with kinetic weapons can usually be estimated on the basis of physics experimentation and calculation. Not so with cyber weapons. For offensive cyber operations, this extreme “target dependence” means that intelligence information on target characteristics must be precise, high-volume, high-quality, current, and available at the time of the weapon’s use.
Inglis argues that fielding “ubiquitous, real-time and persistent” intelligence, surveillance and reconnaissance (ISR) frameworks is crucial for mustering the ability to produce cyber effects at a place and time of choosing.
Daniel Moore of King’s College London broadly categorizes cyber operations into event-based and presence-based.
The ISR framework envisioned by Inglis pre-positions implants with presence-based operations to make sure that the adversarial infrastructure -- perpetually in a state of flux -- remains primed for event-based operations. Falling prey to an analogy, this is as challenging as a group of river-rafters trying to keep their raft still at one position in a raging torrent of water.
However, it is worthy to note that a major component of such an ISR framework would manifest over privately-owned infrastructure.
It is exactly why the commercial threat intelligence industry lead by the likes of Fireeye, Kaspersky and Crowdstrike has flourished the way it has.
Joe Slowik, principal adversary hunter at Dragos, Inc., corroborates it: “An entire ecosystem of defense and security developed within the private space…essentially, private (defensive) ‘armies’ grew up and proliferated in the cyber security space over the course of many years.”
Jason Healey of Columbia’s School of International and Public Affairs has another way of looking at it: “In counterinsurgency, host nation must take lead & U.S. role is to provide aid & support. USG not seen as legitimate, may lack the local & cultural knowledge, & lack sufficient resources. In cyberspace, the private sector, esp tech & security companies, are the host nation (sic)”.
Initiatives like the CyberPeace Institute and Cybersecurity Tech Accord are to be seen as emerging geopolitical formations pivoted around the power vacuum created by growing disintermediation.
While Microsoft avows the applicability of international law, the decreasing technological dependence on it to enforce the rules-based order may herald data-driven normative frameworks solely originating from the private sector.
Take the specific case of fashionable “black-letter rules” – like barring cyber actors from hacking into adversary’s election infrastructure – variedly promulgated by the Tallinn Manual, Microsoft and Global Commission on the Stability of Cyberspace. They could very well act as impediments to the success of the norms process.
Cyber actors can be variedly be divided into various capability tiers: A, B, C or D Teams, etc. Such categorizations could be derived from multiple variables like operational structure, concept of operations, capabilities and toolchains, and operating budget, etc.
In what may sound paradoxical, mindless enforcement of such rules creates an inherently inequitable environment where actors would be compelled to flout them. Targeting and target discrimination are possibly the most expensive components of the cyber offensive toolchain. As intelligence analyst Grugq said, “You need a lot of people to have a small numbers of hackers hacking.”
The ability to avoid a vulnerable target or an attack surface without sacrificing the initiative is a luxury that only an A-team could afford, further disincentivizing smaller players from participating in confidence-building measures.
In such cases, the private sector could lead the way in the neutral and transparent interpretation of the dynamics and thresholds of power projection in cyberspace. Companies, not countries, have the vantage point and commercial interest to create a level playing field.
Taking the original case of France’s new dossier on cyber operations, its gradual rollback from the strictly black-and-white world of, say, the Tallinn Manual hints at a larger devolution of legally interpreted cyber operations, influenced by technical incongruities like disanalogy and disintermediation.
While the said document answers many questions relating to the applicability of international law to cyber operations with uncanny confidence, the devil still lies in the details.
For example, it talks about creating militaristic cyber effects by altering the confidentiality and availability of data on adversarial systems, but skirts around integrity – as if the three dimensions of data security are not symbiotic. Such picket-fencing may be trying to carefully avoid the legal ambiguity on information operations, post-ICJ US vs Nicaragua.
Ask any cyber operator, can a cyber operation proceed without sabotaging the integrity of log artifacts or other such stealthy or deceptive maneuvering?
It also postulates the export of “non-international armed conflict” to the territory of consenting nation states, as if such factors are completely controllable.
Discussed earlier, a majority of the cyber-ISR frameworks manifest over globally scattered private infrastructure. And almost every layer of the computing architecture is now network-enabled.
In cyberspace, the ‘territory’ of a nation state expands and contracts in real time. It may exist online as the sum of all the global information flows, across the many millions of interfaces, associated with it at any given moment. The sheer emergent complexity of this organism has baffled many.
The adversarial environment fluxes at such a rapid pace that taking “territorial” sanctity into account during an ongoing operation is nigh impossible. This, in fact, is the very premise of Defend Forward.
The French document is a good attempt at decoupling cyber operations from legal strictures, but it should be seen as the mere beginning of that process.
Cognitive cyber offence
Lastly, the complete absence of the cognitive dimension in the norms process is something that should be outrightly addressed.
Keith Dear, a research fellow at Oxford’s Changing Character of War Program, feels that war – as “a continuation of politics by other means” – is essentially persuasive and has predominantly psychological effects. They get aggravated more so by the scale and speed of cyber-enabled behavioral modelling.
The threat landscape is at a stage where we are going to see the increasing exploitation of cyber-cognitive attack surfaces – the cost-benefits are now heavily tilted towards their side. It is like what conventional cyber operations used to be 20 years ago: cheap and easy over scale and speed.
The cyber norms community only considers the first or second order effects of cyberattacks. The reality is that causation could be separated by many, many degrees – also missing out on the fact that a cyberattack is generally an indiscernible mixture of not just effects, but also perceptions. Every cyber operation could be deemed as an information operation even after full denouement.
We have only begun to understand the significance of the cognitive dimension. Leading thinkers like former Secretary of the Navy Richard Danzig had for long proposed perceptive instead of spatial redlines for cyber conflict, aptly capturing its emergent properties.
His suggested baseline was: “The United States cannot allow the insecurity of our cyber systems to reach a point where weaknesses in those systems would likely render the United States unwilling to make a decision or unable to act on a decision fundamental to our national security.”
Danzig’s paradigm neatly fits into the Defend Forward philosophy of the US Cyber Command. Former director of the NSA Michael Hayden once said that Stuxnet had the “whiff of August 1945,” while former NSA exploitation engineer Dave Aitel labelled it as the “announcement of a team.” The theatres of war, frameworks for deterrence and parameters for proportional response may turn out to be purely perceptive in nature.
As the cyber option gets increasingly expended by militaries, we have come to understand that the esoteric cognitive parameters of digital conflict could be crucial enough to decide victory or defeat.
Conclusion
As the United Nations’ Governmental Group of Experts’ dialogue came to a grinding halt in 2016, Michelle Markoff, former deputy coordinator for Cyber Issues in the US State Department, gave a candid account of what went wrong.
She also went on to recommend “interleaving strategies” like defence, declaratory policies, alliance activities, and norms of behaviour. It is interesting to note all the four dimensions proffered by her neatly fit into the remit of the private sector when it comes to fostering cyber stability.
The threat intelligence industry, by its indirect participation in the great power play, is already carving a rudimentary framework for declaratory signaling. Private sector alliances – by being more open and neutral about attack attribution, adversarial intent and capabilities, and targeting criteria – may lower the incentives while increasing the costs of cyber actions. That may force various actors to the negotiating table.
The emergence of customary international law in cyberspace, as a precursor to effective normative frameworks, is a necessity that may squarely fall on the shoulders of corporations. In that sense, diplomatic initiatives and alliance activities by Microsoft and others must be keenly observed.
Pukhraj Singh is a cyber threat intelligence analyst who has worked with the Indian government and security response teams of global companies. He blogs at www.pukhraj.me. Views posited are the author’s alone.
Introducing the Cybersecurity Visuals Media Handbook
Handbook concept, content and design by: Padmini Ray Murray and Paulanthony George
Blog post authored by: Saumyaa Naidu and Arindrajit Basu
With inputs from: Karan Saini
Edited by: Shweta Mohandas

The need for intervention in the cybersecurity imagery in media publications was realised during a brainstorming workshop that was conducted by CIS with illustrators, designers, and cybersecurity researchers. The details and learnings from the workshop can be read here. The discusisons led to the initiative of creating a media handbook in collaboration with the designers at Design Beku, and the researchers at CIS.
This handbook was conceived to be a concise guide for media publications to understand the specific concepts within cybersecurity and use it as a reference to create visuals that are more informative, relevant, and look beyond stereotypes.
The limits of visibility and the need for relevant cybersecurity imagery
Due to the "limits of visibility" and relative complexity inherent in any representation of cybersecurity, objects and concepts in this field have no immediate visual representation. A Google Search of the term cybersecurity reveals padlocks, company logos, and lines of numbers indicating code-stereotypes that have very little with the substantive discourse prevailing in cybersecurity policy circles. This stereotype can be further understood by exploring the portrayal of a 'hacker' in the media, both in newspapers and popular culture.
Shires argues that a dominant association with ‘danger’ has made the hacker image a "rich repository of noir influences". Therefore, a hacker is usually depicted as a male figure in a dark-coloured hoodie, with no considerations of spatial, temporal, or cultural contexts.
Visuals influence various actors in any conflict. In traditional non-cyber domains, spatial representations of conflict often omit the blood and gore that is a core facet of reality, and therefore, in some ways ‘legitimize war.’ An impersonal, unrealistic depiction of cybersecurity threats vectors or substantive discussions have two key negatives.
First, it re-entrenches the notion of cybersecurity as distant and undecipherable discourse that eludes the individual. This undermines the critical importance of the participatory nature of the process. The goal of decision-making around cybersecurity should focus on individuals feeling secure and not be driven by policy-makers who decide technical parameters without broader consultation..
Second, it undermines the concept being discussed in the news article. If the visual is accompanying an op-ed, often the visual serves as a trigger for comprehending the content of the op-ed. Presently, op-eds on the global agreements in cyberspace, attribution of cyber attacks, and ‘total surveillance’ by Pegasus are depicted very similarly. These over-simplifications are inaccurate and undermine the nuances of the substantive content in each case, thereby impacting negatively the influence that each piece can have on public awareness and on the state of cybersecurity discourse.
Realistic descriptions of cybersecurity enable a granular understanding of threat vectors. There is also a need for signalling that celebrates and encourages greater diversity in this space. Cybersecurity discourse globally remains dominated by experts who are white and male. Explicitly re-conceptualizing these visuals to celebrate a variety of identities could be a push for other countries and communities (especially in the Global South)
This would enable the hitherto ‘disregarded communities’ in global cybersecurity discourse to understand and participate in the policy-making process.Our design handbook aims to guide media-persons in facilitating these goals.
An initial design brief for the media handbook was arrived at through our conversations with the designers at Design Beku. It was decided that the handbook would be concise and use a lighter tone in terms of language and be more visual than textual. For greater access, a digital, interactive format was seen as the most suitable option.
In order to scope the existing visuals, a sampling of cybersecurity coverage under different subjects in various media publications over the last one year was carried out. This included both global and Indian publications such as Livemint, Scroll, Tech Crunch, Motherboard - Vice, and the Economist. Research and op-eds by CIS researchers were also considered to broadly determine the most relevant subjects within cybersecurity.
The subjects selected based on the coverage were Cyberwarfare (Data Localisation), Cyber Attacks, Blockchain, Misinformation, Data Protection, Ethical Hacking, and Internet shutdowns. It was also gathered that there are several sub-topics within these subjects which would be indicated in the handbook.
The structure of the handbook was detailed out further to include a panorama image comprising illustrations that would speak to all the selected subjects, and text to explain the intention and process of making these illustrations. The handbook would begin with introducing its purpose, and go on to describe the concepts within each illustration, along with recommendations for illustrators working on such images. It would also consist of the definitions for each cybersecurity concept being visualised.
The handbook and accompanying illustrations were conceptualised and designed by Padmini Ray Murray and Paulanthony George from Design Beku. It was our great privilege to be a part of this process. We would also like to thank Karan Saini for his invaluable inputs that helped us commission this publication.
A draft of the handbook is hereby being published here. This would be followed by a final version which will be in the form of an interactive web platform for both desktop and mobile devices.
We thank the Hewlett Foundation for funding this research.
Annexure
Data Localisation
Data localisation can broadly be defined as 'any legal limitation on data moving globally and compelling it to remain locally’. These policies can take a variety of forms. This could include a specific requirement to locally store copies of data, local content production requirements, or imposing conditions on cross border data transfers that in effect act as a localization mandate.
Cyber Attacks/Warfare
Terms: Critical infrastructure, state-sponsored attackers, disruption and/or espionage, attribution, data leaks, bugs, zero days, misconfigurations
Cyber attacks are a hostile act using computer or related networks or systems, and intended to disrupt and/or destroy an adversary’s critical cyber systems, assets, or functions. The intended effects of cyber attack are not necessarily limited to the targeted computer systems or data themselves.
Blockchain
Terms: Crypto-currency, immutable infrastructure, node compromise
Blockchain is a list of records linked using cryptography. It relies on three core elements in order to function effectively-decentralization, proof of work consensus and practical immutability.
Misinformation
Terms: Propagation and spread, large-scale & inauthentic coordinated activities
The concerted spread of inaccurate information through one (or more) of four methods of propagation-doctored or manipulated primary information, genuine information shared in a false context,selective or misleading use of information and the misinterpretation of information.
Data Protection
Terms: Cryptographic protection, access controls, privacy
Data Protection is protection through legal means accorded to private data from misuse by private or state actors. It includes processes such as collection and dissemination of data and technology, the public perception and expectation of privacy, and the political and legal underpinnings surrounding that data.
Ethical Hacking
Terms: Diverse representation, and normalization/de-otherization of an “ethical hacker”
The term implies an ethical responsibility on the part of the hacker which compels them to inform the maintainers of a particular system about any discovered security flaws or vulnerabilities. While the ethics of "ethical hacking" differ for each individual, ethical hackers traditionally practice their craft out of a moral imperative. Ethical hackers are also described as independent computer security professionals who evaluate the system’s security and report back to the owners with the vulnerabilities they found and instructions for how to remedy them.
Internet shutdowns
An internet shutdown is an intentional disruption of internet or electronic communications, rendering them inaccessible or effectively unusable, for a specific population or within a location, often to exert control over the flow of information.
The interactive version of the handbook can be accessed here. The print versions of the handbook can be accessed at: Single Scroll Printing, Tiled-Paste Printing.
Draft Security Standards for The Financial Technology Sector in India
By: Vipul Kharbanda
with inputs from: Prem Sylvester
Information security standards provide a framework for the secure development, implementation and maintenance of information systems and technology architecture. Regulatory policies often cite several information security standards as a baseline that is to be complied with in order to ensure the adequate protection of information systems as well as associated architecture. Information security standards for the financial industry provide consideration to the specific risks and threats that financial institutions may face, making them an integral part of the process of ensuring business and operational sanctity.
There is an urgent economic interest in ensuring robust security of the financial technology sector within the country. This interest is amplified considerably due to the policy push seeking to shift India towards the realisation of a ‘cashless society’. This recent policy push has in part led to the ubiquitous adoption of technology-centric financial services such as PayTM, PhonePe, Mobikwik and others. The current landscape with respect to security standards for financial institutions in India appears to be multi-pronged; with multiple standards in place for companies to implement.
The report can be accessed in full here.
Blockchain: A primer for India
Cybersecurity Visuals Media Handbook: Launch Event
The existing cybersecurity imagery in media publications has been observed to be limited in its communication of the discourse prevailing in cybersecurity policy circles, relying heavily on stereotypes such as hooded men, padlocks, and binary codes.
In order to enable a clearer, more nuanced representation of cybersecurity concepts, we, at CIS, along with Design Beku are launching the Cybersecurity Visuals Media Handbook. This handbook has been conceived to be a concise guide for media publications to understand the specific concepts within cybersecurity and use it as a reference to create visuals that are more informative, relevant, and look beyond stereotypes.
We will be launching the interactive digital handbook on 6th December, 2019, at the Centre for Internet and Society, Bangalore, at 6 pm. The event would include a discussion on the purpose, process, and concepts behind this illustrated guide by CIS researchers and Design Beku.
The launch will be followed by a panel discussion on Digital Media Illustrations & the Politics of Technology. We will be joined by Padmini Ray Murray, Paulanthony George, and Kruthika N S in the panel. It will be moderated by Saumyaa Naidu.
Padmini Ray Murray
Padmini founded the Design Beku collective in 2018 to help not-for-profit organisations explore their potential through research-led design and digital development. Trained as an academic researcher, Padmini currently as the head of communications at Obvious, a design studio. She regularly gives talks and publishes on the necessity of technology and design to be decolonial, local, and ethical.
Paulanthony George
Paulanthony hates writing bios in the third person.
My research focuses on the relationships between made objects, the maker and the behaviour of making, in the context of spreadable digital media (and behaviours stemming from it). I study internet memes inside and outside of India and phenomenon such as dissent, satire, free expression and ambivalent behaviour fostered by them. The research is at the intersection of digital ethnography, culture studies, human-computer interaction, humour studies and critical theory. I spend my time watching people. I draw them, the way they are, the way some people want to be and sometimes I have interesting conversations with them.
Kruthika N S
Kruthika NS is a lawyer at LawNK and researcher at the Sports Law & Policy Centre, Bengaluru. She uses art as a medium to explore the intersections of the law and society, with gender justice featuring as the central theme of her work. Her art has included subjects such as the #MeToo movement in India, and the feminist principles of the internet, among several other doodles.
Saumyaa Naidu
Saumyaa is a designer and researcher at the Centre for Internet and Society.
Agenda
6:00 - 6:15 pm - Introduction
6:15 - 6:45 pm - Presentation on the Media Handbook by Paulanthony George
6:45 - 7:00 pm - Tea/ Coffee
7:00 - 8:00 pm - Panel discussion on Digital Media Illustrations & the Politics of Technology
8:00 - 8:30 pm - Tea/ Coffee and Snacks
The interactive version of handbook can be accessed here. The print versions of the handbook can be accessed at: Single Scroll Printing, Tiled-Paste Printing.
Project on Gender, Health Communications and Online Activism with City University
It is funded by the Global Challenges Research Fund. Ambika Tandon, Policy Officer at CIS, conducted fieldwork for the project in May and June 2019 as a research assistant.
The goal of the project is to advance research on how new communication technologies (ICTs) can be used to create awareness of gender equality and sexual and reproductive rights. It aims to assess how the use of technologies, by women's groups and feminist NGOs can empower women in developing countries to advance citizen and human rights with the intent to influence policy at the global and local level. More information on the preliminary findings of the project can be found in the downloadable presentation."
You may find Dr. Carolina Matos's presentation here.
A Deep Dive into Content Takedown Timeframes
In this report, we will consider one such question by examining the appropriate time frame for an intermediary to respond to a government content removal request. The way legislations around the world choose to frame this answer has wider ramifications on issues of free speech and ease of carrying out operations for intermediaries. Through the course of our research, we found, for instance:
- An one-size-fits-all model for illegal content may not be productive. The issue of regulating liability online contain several nuances, which must be considered for more holistic law-making. If regulation is made with only the tech incumbents in mind, then the ramifications of the same would become incredibly burdensome for the smaller companies in the market.
- Determining an appropriate turnaround time for an intermediary must also consider the nature and impact of the content in question. For instance, the Impact Assessment on the Proposal for a Regulation of the European Parliament and of the Council on preventing the dissemination of terrorist content online cites research that shows that one-third of all links to Daesh propaganda were disseminated within the first one-hour of its appearance, and three-fourths of these links were shared within four hours of their release. This was the basic rationale for the subsequent enactment of the EU Terrorism Regulation, which proposed an one-hour time-frame for intermediaries to remove terrorist content.
- Understanding the impact of specific turnaround times on intermediaries requires the law to introduce in-built transparency reporting mechanisms. Such an exercise, performed periodically, generates useful feedback, which can be, in turn used to improve the system.
Click to download the research paper by Torsha Sarkar (with research assistance from Keying Geng and Merrin Muhammed Ashraf; edited by Elonnai Hickok, Akriti Bopanna, and Gurshabad Grover; inputs from Tanaya Rajwade)
RTI Application to the Ministry of Information and Broadcasting on content code violations by radio stations
Background
In 1995, the Supreme Court of India, in the case of The Secretary, Ministry of Information and Broadcasting v Cricket Association of Bengal, declared airwaves to be public property. The judgment formed the stepping stones to liberalizing the broadcasting media, and freeing up the sector from government monopoly.
Despite the fact that more than two decades have passed since the judgment, community and private FM channels continue to face a government embargo from curating and broadcasting news and content on current affairs. The Phase III FM Policy and the Grant of Permission Agreement (GoPA) for community radios broadly restrict these radio channels from broadcasting news, with two exceptions. FM and community radio stations can still broadcast updates on a few categories of content that the regulations classify as “non-news”, such as sports, …, etc. Additionally, they can rebroadcast the All India Radio (AIR) news bulletin verbatim.
Application under the Right to Information Act
To further our research, we sought information on the extent of radio stations’ compliance with the content code and the use of Government’s oversight mechanism (examination of recordings of their broadcasts). On October 23rd, I filed an RTI with the Ministry of Information and Broadcasting (MI&B) asking for information regarding instances where these channels had violated the content restrictions placed on them.
The text of the application is reproduced below:
To:
Shri Yogendra Trehan
Central Public Information Officer (RTI)
Dy. Director (FM)
Director (DS II), Room No 116, A Wing,
Shastri Bhawan, New Delhi, 110001
Sir,
Subject: Information on private FM radio licenses and violations
This is to request you to provide the following information under the Right to Information 2005.
Period of information requested: 10 years (2010 to 2019)
1. Number of instances where an FM radio channel was suspended from broadcasting due to violation of conditions 11.1, 11.2 or 12.1 of the Phase 3 FM Policy (i.e content related violations)
2. Number of instances where an FM radio channel permission was revoked due to violation of conditions 11.1, 11.2 or 12.1 of the Phase 3 FM Policy (i.e content related violations).
3. Number of instances where the 5 year or 10 year license renewal application of an FM radio channel was rejected due to content related violations.
4. Number of examinations of the recordings of content broadcast on FM radio stations.
[...]
To the best of my belief, the details sought for fall within your authority. Further, as provided under section 6(3) of the Right to Information Act (RTI Act), in case this application does not fall within your authority, I request you to transfer the same in the designated time (5 days) to the concerned authority and inform me of the same immediately.
To the best of my knowledge, the information sought does not fall within the restrictions contained in sections 8 and 9 of the RTI Act, and any provision protecting such information in any other law for the time being in force is inapplicable due to section 22 of the RTI Act.
Please provide me this information in electronic form, via the e-mail address provided above. This to certify that I, Torsha Sarkar, am a citizen of India.
Date: 23rd October, 2019
Place: Bengaluru, Karnataka
The FM Cell of Ministry of Information and Broadcasting (MIB) responded to the application on November 21st with information regarding the same. Their response is reproduced below:
In so far as FM Cell of this Ministry is concerned, it is stated that,no channel was suspended from broadcasting or permission was revoked due to violation of conditions 11.1, 11.2 or 12.1 of the Phase -lll FM policy. No instances ln so far as FM Cell of this Ministry is concerned, it is stated where the 5 year or 10 year license renewal application of an FM radio channel or 12.1 of the Phase -lll FM policy. 17 instances of complaints regarding violation of content code by private FM radio stations were received and suitable action in terms of the Grant of Permission Agreement has been taken by the Government after examination of the recordings of broadcast.
Conclusion
As the MIB’s records show, there are nearly 380 private FM channels and 185 community FM channels in India as of August 2019. In the face of such numbers, there have been mere seventeen instances of the private FM channels violating the content code in the last ten years, and none of these were serious enough for their broadcasting licenses to be revoked or them to face suspension.
The low number of complaints against radio stations can be interpreted in a number of ways: However, coupled with the fact there is an onerous process of obtaining a license and permissions for broadcasting, one interpretation can be that the numbers are generally indicative of the fact that radio station operators are generally compliant with the content code.
--
The text of the RTI Application was drafted by Raouf Kundil Peedikayil, who interned with CIS. This blogpost was edited by Gurshabad Grover and Elonnai Hickok.
In Twitter India’s Arbitrary Suspensions, a Question of What Constitutes a Public Space
The article by Torsha Sarkar was published in the Wire on December 7, 2019.
On October, 26 2019, Twitter suspended the account of senior advocate Sanjay Hegde. The reason? He had previously put up the famous photo of August Landmesser refusing to do the Nazi salute in a sea of crowd in the Blohm Voss shipyard.
According to the social media platform, the image violated Twitter’s ‘hateful imagery’ guidelines, despite the photo being around for decades and usually being recognised as a sign of resistance against blind authoritarianism.

August Landmesser. Photo: Public Domain
Twitter briefly revoked the suspension on October 27, but promptly suspended Hegde’s account again. This time, the action was prompted by Hegde quote-tweeting parts of a poem by Gorakh Pandey, titled ‘Hang him’, which was written in protest of the first death penalties given to two peasant revolutionaries in an independent India. This time, Hegde was informed that his account would not be restored.
Spurred by what he believed was Twitter’s arbitrary exercise of power, he proceeded to file a legal notice with Twitter, and asked the Ministry of Electronics and Information Technology (MeitY) to intervene in the matter. It is the subject matter of this ask that becomes of interest.
In his complaint, Hegde first outlines how the content shared by him did not violate any of Twitter’s community guidelines. He then goes on to highlight how his fundamental right of dissemination and receipt of information under Article 19(1)(a) were obstructed by the action of Twitter. Here, he places reliance to several key decisions of the Indian and the US Supreme court on media freedom, which provided thrust to his argument that a citizen’s right to free speech is meaningless if control was concentrated in the hands of a few private parties.
Vertical or horizontal?
One of the first things we learn about fundamental rights is that they are enforceable against the government, and that they allow the individual to have a remedy against the excesses of the all-powerful state. This understanding of fundamental rights is usually called the ‘vertical’ approach – where the state, or the allied public authority is at the top and the individual, a non-public entity is at the bottom.
However, there is another, albeit underdeveloped, thread of constitutional jurisprudence that argues that in certain circumstances these rights can be claimed against another private entity. This is called the ‘horizontal’ application of fundamental rights.
In that note, Hegde’s contention essentially becomes this – claiming an enforceable remedy against the private entity for supposedly violating his fundamental right. This is clearly an ask for the Centre to consider a horizontal application of Article 19(1)(a) against large social media companies.
What could this mean?
Lawyer Gautam Bhatia has argued that there are several ways in which a fundamental right can be enforced against another private entity. It must be noted that he derives this classification on the touchstone of existing judicial decisions, which is different from seeking an executive intervention. Nevertheless, it is interesting to consider the logic of his arguments as a thought exercise. Bhatia points out that one of the ways in which fundamental rights can be applied to a private entity is by assimilating the concerned entity as a ‘state’ as per Article 12.
There is a considerable amount of jurisprudence on the nature of the test to determine whether the assailed entity is state. In 2002, the Supreme Court held that for an entity to be deemed state, it must be ‘functionally, financially and administratively dominated by or under the control of the Government’. If we go by this test, then a social media platform would most probably not come within the ambit of Article 12.
However, there is a thread of recent developments that might be interesting to consider. Earlier this year, a federal court of appeals in the US ruled that the First Amendment prohibits President Donald Trump, who used his Twitter for government purposes, from blocking his critics. The court further held that when a public official uses their account for official purposes, then the account ceases to be a mere private account. This judgment has a sharp bearing in the current discussion, and the way social media platforms may have to operate within the tenets of constitutional protections of free speech.
Although the opinion of the federal court clearly noted that they did not concern themselves with the application of the First Amendment rights to the social media platforms, one cannot help but wonder – if the court rules that certain spaces in a social media account are ‘public’ by default, and that politicians cannot exclude critiques from those spaces, then can the company itself block or impede certain messages? If the company does it, can an enforceable remedy then be made against them?

A US court ruled that Donald Trump cannot block people on his Twitter account. Photo: Reuters
What can be done?
Of course, there is no straight answer to this question. On one hand, social media platforms, owing to the enormous concentration of power and opaque moderating policies, have become gatekeepers of online speech to a large extent. If such power is left unchecked, then, as Hegde’s request demonstrates, a citizen’s free speech rights are meaningless.
On the other hand, if we definitively agree that in certain circumstances, citizens should be allowed to claim remedies against these companies’ arbitrary exercise of power, then are we setting ourselves for a slippery slope? Would we make exceptions to the nature of spaces in the social media based on who is using it? If we do, then what would be the extent to which we would limit the company’s power of regulating speech in such space? How would such limitation work in consonance with the company’s need to protect public officials from targeted harassment?
At this juncture, given the novelty of the situation, our decisions should also be measured. One way of addressing this obvious paradigm shift is by considering the idea of oversight structures more seriously.
I have previously written about the possibility of having an independent regulator as a compromise between overtly stern government regulation and allowing social media companies to have free reign over the things that go on their platforms. In light of the recent events, this might be a useful alternative to consider.
Hegde had also asked the MeitY to issue guidelines to ensure that any censorship of speech in these social media platforms is to be done in accordance with the principles of Article 19.
If we presume that certain social media platforms are large and powerful enough to be treated akin to public spaces, then having an oversight authority to arbitrate and ensure the enforcement of constitutional principles for future disputes may just be the first step towards more evidence-based policymaking.
ICANN takes one step forward in its human rights and accountability commitments
The article was first published on Article 19 on December 16, 2019
ICANN is the international non-profit organization that brings together various stakeholders to create policies aimed at coordinating the Domain Name System. Some of these stakeholders include representatives from government, civil society, academia, the private sector, and the technical community.
During the recently concluded 66th International Meeting of the Internet Corporation for Assigned Names and Numbers (ICANN) in Montreal (Canada); the ICANN board adopted by consensus the recommendations contained within the Work Stream 2 (WS2) Final Report. This report was generated as part of steps towards accountability after the September 30th 2016 U.S. government handing over of its unilateral control over ICANN, through its previous stewardship role of the Internet Assigned Names and Numbers Authority (IANA).
The Workstream 2 Recommendations on Accountability are seen as a big step ahead in the incorporation of human rights in ICANN’s various processes, with over 100 recommendations on aspects ranging from diversity to transparency. An Implementation Team has been constituted which comprises the Co-chairs and the rapporteurs from the WS2 subgroups. They will primarily help the ICANN organization in interpreting recommendations of the groups where further clarification is needed on how to implement the same. As the next step, an Implementation Assessment Report has recently been published which looks at the various resources and steps needed. The steps are categorized into actions meant for one of the 3; the ICANN Board, Community and the ICANN organization itself. These will be funded by ICANN’s General Operating Fund, the Board and the org.
The report is divided into the following 8 issues: 1) Diversity, 2) Guidelines for Good Faith, 3) Recommendations for a Framework of Interpretation for Human Rights, 4) Jurisdiction of Settlement of Dispute Issues, 5) Recommendations for Improving the ICANN Office of the Ombudsman, 6) Recommendations to increase SO/ AC Accountability, 7) Recommendations to increase Staff Accountability and 8) Recommendations to improve ICANN Transparency.
This blog will take a look at the essential human rights related considerations of the report and how the digital rights community can get involved with the effectuation of the recommendations.
Diversity
The core issues concerning the issue of diversity revolve around the need for a uniform definition of the parameters of diversity and a community discussion on the ones already identified; geographic representation, language, gender, age, physical disability, diverse skills and stakeholder constituency. An agreed upon definition of all of these is necessary before its Board approval and application consistently through the various parts of ICANN. In addition, it is also required to formulate a standard template for diversity data collection and report generation. This sub group’s recommendations are estimated to be implemented in 6-18 months. Many of the recommendations need to be analyzed for compliance with the General Data Protection Regulation (GDPR) such as collecting of information relating to disability. For now, the GDPR is only referenced with no further details on how steps considered will either comply or contrast the law.
Good faith Guidelines
The Empowered Community (EC) which includes all the Supporting Organizations, At-Large-Advisory-Committee and Government Advisory Council, are called upon to conceptualize guidelines to be followed when individuals from the EC are participating in Board Removal Processes. Subsequent to this, the implementation will take 6-12 months.
Framework of Interpretation for Human Rights
Central to the human rights conversation and finally approved, is the Human Rights Framework of Interpretation. However the report does not give a specific timeline for its implementation, only mentioning that this process will take more than 12 months. The task within this is to establish practices of how the core value of respecting human rights will be balanced with other core values while developing ICANN policies and execution of its operations. All policy development processes, reviews, Cross Community Working Group recommendations will need a framework to consider and incorporate human rights, in tandem with the Framework of Interpretation. It will also have to be shown that policies and recommendations sent to the Board have factored in the FOI.
Transparency
The recommendations focus on the following four key areas as listed below:
1. Improving ICANN’s Documentary Information Disclosure Policy (DIDP).
2. Documenting and Reporting on ICANN’s Interactions with Governments.
3. Improving Transparency of Board Deliberations.
4. Improving ICANN’s Anonymous Hotline (Whistleblower Protection).
The bulk of the burden for implementation is put on ICANN org with the community providing oversight and ensuring ICANN lives up to its commitments under various policies and laws. Subsequent to this, the implementation will take 6-12 months.
How the ICANN community can contribute to this work
This is a defining moment on the future of ICANN and there are great opportunities for the ICANN multistakeholder community to continue shaping the future of the Internet. Some of the envisioned actions by the community include:
- monitoring and assessing the performance of the various ICANN bodies, and acting on the recommendations that emerge from those accountability processes. This will only be done through collaborative formulation of processes and procedures for PDPS, CCWGs etc to incorporate HR considerations and subsequently implementation of the best practices suggested for improving SO/ACs accountability and transparency;
- conducting diversity assessments to inform objectives and strategies for diversity criteria;
- supporting contracted parties through legal advice for change in their agreements when it comes to choice of law and venue recommendations;
- contributing to conversations where the Ombudsman can expand his/her involvement that go beyond current jurisdiction and authority
Pegasus snoopgate, an opportune moment to revisit legal framework governing state surveillance framework
This article by Gurshabad Grover and Tanaya Rajwade was published in the Indian Express on December 25, 2019. The authors would like to thank Arindrajit Basu for his comments and suggestions.
In early November, it became clear that several lawyers and human rights activists had been targeted by spyware that allowed attackers unfettered access to information stored on victims’ phones. On November 29, in the Rajya Sabha, the Minister of Electronics and Information Technology was repeatedly asked whether any Indian agency had commissioned the attack vector ‘‘Pegasus” that was used in the attacks from the Israeli firm NSO. Where a categorical response would have sufficed, the minister chose to muddy the waters through vague assertions such as “standard operating procedures have been followed”.
There are cogent reasons pointing towards an Indian law enforcement agency’s hand in procuring Pegasus. First, NSO maintains that it only sells services and software to state agencies. Second, some of the known Indian targets of the vulnerability are human rights activists. These individuals work on India-specific issues and hardly qualify as serious threats in the eyes of a foreign government.
The government derives some of its powers to conduct electronic surveillance from Section 69 of the Information Technology (IT) Act. The procedures for such surveillance are defined in the IT (Procedure and Safeguards for Interception, Monitoring and Decryption of Information) Rules, 2009. It is these rules, and not the parent Act that define the terms “interception” and “monitoring” as “acquisition of the contents of any information through the use of any means” and “to view or to inspect or listen to or record information”, respectively. These all-encompassing definitions seemingly permit authorised law enforcement agencies to use Pegasus-like tools.
However, the IT Act also penalises unauthorised access to computers without the owner’s permission. These provisions, namely section 43 and 66, do not carve out an exception for law enforcement agencies. As lawyer Raman Chima highlighted recently, any action explicitly prohibited under the Act cannot be justified by procedures laid out in subordinate legislation. Therefore, no law enforcement agency can “hack” devices, though they may “intercept” or “monitor” through other means. Additionally, the Supreme Court’s privacy verdict held any invasion of privacy by the state must be based on a law. As some of the agencies authorised to conduct surveillance (like the Intelligence Bureau) do not have statutory backing, surveillance by them is unconstitutional.
The use of spyware gives the state access to private conversations, including privileged communications with lawyers. Such an infringement of rights may be justified for militants suspected of actively planning an armed attack. For academicians and human rights activists, the use of broad surveillance without any evidence or anticipation of such activities is unfathomable in a democracy.
With the popularity of end-to-end encryption, surveillance may require the exploitation of vulnerabilities on end-users’ devices. The Pegasus snoopgate is an opportune moment to revisit the legal framework governing the state surveillance framework. It is crucial to dismantle state agencies that run surveillance operations despite lacking statutory authority. For other agencies, there is a need to introduce judicial and parliamentary oversight. Depending on the concerns of law enforcement, it may be necessary to enact legislation permitting “hacking” into devices on extremely limited grounds.
Unfortunately, the government has taken a massive leap backwards by ignoring the standards laid down by the Supreme Court and Justice Srikrishna Committee’s recommendations, and introducing unconstitutional surveillance enablers in the Data Protection Bill. Now is the time for Parliament to guarantee the privacy and security of Indians.
Grover and Rajwade are researchers at the Centre for Internet and Society (CIS). Views are personal. Disclosure: CIS is a recipient of research grants from Facebook.
How safe is your harbour? Discussions on intermediary liability and user rights
Background
The Manila Principles outline three kinds of liability regimes that countries follow while regulating intermediaries; expansive protections against liability, conditional immunity and primary liability. Post Avneesh Bajaj, India has been following the second model, where intermediaries are provided safe harbour for the acts of their users. In December 2018, the Ministry of Electronics and Information Technology (MeitY), released a draft of the Information Technology (Intermediary Guidelines (Amendment) Rules), 2018. These rules raised a host of concerns in the way they envision liability and user rights in the digital domain. The proposed amendments may mark a departure from the current model by creating cumbersome obligations for intermediaries to avail safe harbour.
At the Centre for Internet and Society (CIS), we have been closely examining some of the draft rules to decipher the changed regime. Our research has focussed on the impact of mandating automated content filtering, shortened turnaround times for intermediaries to take content down, and the traceability of originators of information.
As part of our ongoing work, we are hosting this event to contribute to the discussion around the nuances of the rules and the future of intermediary liability in India. As such, this event will begin with a brief analysis of the proposed amendments. We will also address the restrictions these would place on freedom of expression online and the way intermediaries do their business, among others. Subsequently, we would be having sessions on particular aspects of the rules. Finally, we would dedicate the last session on contemplating the future of intermediary liability regime in India.
Panels
Automated content filtering
One of the more controversial and stringent rules introduced in the proposed amendments is Rule 3(9) which necessitates the use of automated technology in filtering content. The draft rule does not specify the scope of the content to be detected, the technologies to be used, or any procedural safeguards that accompany the deployment of the technology. The discussion on the rule will, thus, centre around the legal validity of the proposal, the effect on different scales of intermediaries, and the consequences of intermediaries’ compliance on the exercise of freedom of expression in India.
Panelists: Kanksshi Agarwal (Senior Researcher, Centre for Policy Research); Nayantara Ranganathan (Independent researcher); Shashank Mohan (Counsel, Software Freedom Law Centre); Moderator: Akriti Bopanna (Policy Officer, CIS)
Content takedown
In this session, we will examine S.69 and S.79 of the IT Act that permit the Government to mandate intermediaries to remove/block content. Our discussion will focus on the procedural flaws of the law, issues of due process, and the lack of transparency in the legal process of content takedown. Additionally, we will discuss findings from our research on the feasibility of a specific turnaround time, and regulatory factors that need to be considered before fixing an appropriate takedown timeframe.
Panelists: Bhavna Jha (Research Associate, IT for Change); Divij Joshi (Technology Policy Fellow, Mozilla); Moderator: Torsha Sarkar (Policy Officer, CIS)
Traceability
The draft Intermediary Guidelines propose requiring intermediaries to enable traceability of originators of information. While this move is ostensibly to crack down on misinformation and fake news, there are questions regarding its feasibility and effects on platform architecture. More importantly, it poses grave dangers for the freedom of expression and privacy of users. The discussion will be centred around how traceability interacts with the Constitution and other laws in India, the litigation around it, possible methods to implement traceability (by or without breaking encryption) and what it means for the larger debate on intermediary liability and free speech.
Panelists: Aditi Agrawal (Senior Research Associate, MediaNama); Anand Venkatanarayanan (Cybersecurity researcher); G S Madhusudan (Principal Scientist, IIT Madras); Moderator: Tanaya Rajwade (Policy Officer, CIS)
Future of intermediary liability in India
The panel will bring together the threads from the previous discussions and discuss the ways in which the draft intermediary guidelines represent a departure from the current model of intermediary liability in India, and its potential effects on similar regulation in other countries. We will discuss the nature of changes, especially as they relate to classification of intermediaries, and whether they are within the scope of S.79 of the IT Act and the intermediary guidelines. We will also aim to address the effects of legislation and jurisprudence in related areas such as data protection and competition law. Finally, we will discuss regulatory frameworks for intermediary liability that should be considered in India.
Panelists: Alok Prasanna (Senior Resident Fellow, Vidhi Centre for Legal Policy); Sarvjeet Singh (Executive Director, Centre for Communication Governance); Tanya Sadana (Principal Associate, Ikigai Law); Udbhav Tiwari (Public Policy Advisor, Mozilla); Moderator: Gurshabad Grover (Research Manager, CIS)
RSVP
To register for the event, please RSVP here.
Note that this is a research event. Please ignore social media messages that have erroneously identified this event as a protest.
Comments to National Security Council on National Cybersecurity Strategy 2020
Approach and Key Principles:
India’s 2020 strategy will need to account for key vectors that have come to define cyberspace including:
- Increased power held by non-state actors - both private corporations and terrorist groups
- Augmented capacity of states to use cyberspace as a tool of external power projection-both through asymmetric warfare, and alleged interference via the spread of misinformation
- The progression of norms formulation processes in cyberspace that have failed to attain consensus due to disagreement on the application of specific standards of International Law to cyberspace.
- Legality: Capabilities, measures, and processes for cyber security must be legally defined and backed.
- Necessity and Proportionality: Any measure taken for the purpose of ‘cyber security’ that might have implications for fundamental rights must be necessary, and proportionate to the infringement.
- Transparency: Transparency must be a key principle with clear standards to resolve situations where there is a conflict of interests.
- Accountability and Oversight: Capabilities, measures and processes must be held accountable through capable and funded bodies and mechanisms.
- Human Rights: Security of the individual, the community, society, and the nation must be achieved through through promoting a ‘feeling of being secure’ that must stem from a rights-respecting framework.
- Free and fair digital economy: Pursue both domestic and geo-strategic policies and actions that enable a free and fair digital economy.
The strategy should be based on the following:
- Evidence based: Regular audits of the state of cyber security in India to inform action and policy.
- Appropriate metrics: Key metrics are needed to measure, track, and communicate cyber security in India.
- Funding: Funding for cyber security needs to be built into the budget.
Pillars of Strategy
Secure
Key Defensive Measures: Technical defense measures such as:
- Testing and auditing of hardware and software
- Identification of threat intelligence vectors and existing vulnerabilities, particularly in systems designated as Critical Information Infrastructure (CII)
- Outline scenarios in which retaliatory operations may be taken and their nature,scope and limits
Designing a credible deterrence strategy, which includes:
- Articulation of the nature, scale and permissible limits of retaliatory or escalatory measures undertaken AND
- An exposition of how this matches with the application of key tenets of International Law in cyberspace
Offensive Measures: If India pursues cyber offensive capabilities, this must be done in accordance with the principles articulated above. This includes ensuring that the surveillance regime in India is inline with international human rights norms.
Emerging Technologies: Emerging technologies must meet high security standards before they are scaled and deployed. Creation of sandboxes should not be an exception.
Developing attribution capabilities: If India pursues attribution capabilities, this must be through multi-stakeholder collaboration, should not risk military escalation, and must demonstrate compliance with evidentiary requirements of Indian criminal law and requirements in International Law on State Responsibility.
Process for response: Define clear roles for the response protocol to a cyber attack including detection, mitigation and response.
Strengthen
Regulatory Requirements
- Legal and Technical Security Standards: Develop harmonised and robust legal and technical security standards across sectors for crucial issues - encryption and breach notifications etc. Promote industry wide adoption of standards developed by BIS and encourage participation at standard setting fora.
- Cross border sharing of data: Focus on a solution to the MLAT process - potentially including the negotiation of an executive agreement under the CLOUD Act.
Coordinated Vulnerability Disclosure: Improve the processes for disclosing security vulnerabilities to the Government by stakeholders outside the government.
Incentives: Develop incentives for strong cyber security practices such as cyber insurance programmes, certifications and seals, and tax incentives.
Education and End User Awareness: Develop solutions to aid users to understand and manage their digital security.
Harmonization and interoperability: Harmonize legislation, legal provisions, and department mandates and processes related to cyber security.
Synergise
Engage in processes at the regional and global level to prevent potential misunderstandings, define shared understandings, and identify areas of collaboration. This can take place through:
- Norms: Clarify India’s understanding of the applicability of international law to cyber space and engage in norms processes and contribute to the articulation of a development dimension for cyber norms.
- CBMs: Focus on political and legal measures around transparency, cooperation, and stability in the region and globally.
How India Censors The Web
A paper authored by Kushagra Singh, Gurshabad Grover and Varun Bansal is now available on arXiv.
Executive Summary
Our work presents the largest study of web censorship in India, both in terms of number of censorship mechanisms that we test for, and the number of potentially-blocked websites. We compile a list of potentially blocked websites from three sources: (i) Published and leaked Government orders issued under section 69A of the IT Act, (ii) Court orders for blocking websites made public via RTIs, and (iii) User reports collected and published by the Internet Freedom Foundation. We pass this list to our tests and run them from connections of six different ISPs (Jio, Airtel, Vodafone, MTNL, BSNL, and ACT), which together serve more than 98% of Internet users in India. Our findings not only confirm that ISPs are using different techniques to block websites, but also demonstrate that different ISPs are not blocking the same websites.
In terms of censorship methods, our results confirm that ISPs in India are at liberty to use any technical filtering mechanism they wish: there was, in fact, no single mechanism common across ISPs. We observe ISPs to be using a melange of techniques for blocking access, including DNS poisoning\ and HTTP host inspection. Our tests also discern the use of SNI inspection being employed by the largest ISP in India (Jio) to block HTTPS websites, the use of which is previously undocumented in the Indian context.
Our study also records large inconsistencies in website blocklists of different Indian ISPs. From our list of 4379 potentially blocked websites, we find that 4033 appear in at least one ISP’s blocklist. In terms of absolute numbers, we notice that ACT blocks the maximum number of websites (3721). Compared to ACT, Airtel blocks roughly half the number of websites (1892). Perhaps most surprisingly, we find that only 1115 websites out of the 4033 (just 27.64%) are blocked by all six ISPs. Simply stated, we find conclusive proof that Internet users in India can have wildly different experiences of web censorship.
Analysing inconsistencies in blocklists also makes it clear that ISPs in India are (i) not properly complying with website blocking (or subsequent unblocking orders), and/or (ii) arbitrarily blocking websites without the backing of a legal order. This has important legal ramifications: India’s net neutrality regulations, codified in the license agreements that ISPs enter with the Government of India, explicitly prohibit such behaviour.
Our study also points to how the choice of technical methods used by ISPs to censor websites can decrease transparency about state-ordered censorship in India. While some ISPs were serving censorship notices, other ISPs made no such effort. For instance, Airtel responded to DNS queries for websites it wishes to block with NXDOMAIN. Jio used SNI-inspection to block websites, a choice which makes it technically impossible for them to serve censorship notices. Thus, the selection of certain technical methods by ISPs exacerbate the concerns created by the opaque legal process that allows the Government to censor websites.
Web censorship is a curtailment of the right to freedom of expression guaranteed to all Indians. There is an urgent need to reevaluate the legal and technical mechanisms of web censorship in India to make sure the curtailment is transparent, and the actors accountable.
The paper can be accessed on arXiv.
Update (12 June 2020): The paper will appear at the 12th ACM Conference on Web Science (WebSci '20). The updated paper can be accessed here.
Internet shutdowns: Its legal and commercial dimensions in Kashmir
This article by Gurshabad Grover appeared on ETVBharat on February 10, 2020. The author would like to thank Kanav Khanna for his research assistance. The article was edited by Arindrajit Basu and translated into various languages by the ETVBharat team. You can also read it in Gujarati, Hindi, Kannada, Odia, and Urdu.
On 4 August 2019, the Central Government ordered the suspension of telecommunication and internet services in Jammu and Kashmir. Suddenly, roughly a crore citizens found themselves unable to exercise their basic freedoms of expression and association online. According to the Software Freedom Law Centre’s Internet Shutdown Tracker, Jammu and Kashmir endured 180 partial or complete internet shutdowns in the last seven years. These astonishing numbers indicate that communication blockades in the state are a common occurrence, but perhaps even Kashmiris did not anticipate that they are entering the longest internet shutdown ever imposed by a democratic country.
It is no secret that the internet has become an essential tool for democratic participation. The loss of the network infrastructure also causes both social and economic harm: students are denied access to critical educational resources, hospitals and emergency services face an administrative catastrophe, and local business can crumble. As recent work by the scholar Jan Rydzak demonstrates, shutting down the internet may not even be ensuring public order and peace, as the government would readily claim. Rydzak argues that access to the internet allows wide coordination that is necessary to demonstrate a peaceful protest, and that internet shutdowns may thus be fueling violent protests rather than curbing them.
When the internet shutdown, among other state action, was challenged by Kashmiri Times editor Anuradha Bhasin, the Supreme Court (SC) did have an opportunity to consider these factors when deciding on the legality of the shutdown. The concerns of civil society were made severe in this particular situation because the Government failed, in a total disregard for the rule of law, failed to publish the internet shutdown orders or present them before the court. In its final order on 10 January this year, the SC did affirm basic constitutional principles and sets progressive precedent for future cases.
First and foremost, the Court affirms that the Constitution, through Article 19, protects the “freedom of speech and expression and the freedom to practice any profession or carry on any [...] occupation over the medium of internet.” Second, the Court recognised that internet shutdowns cannot be imposed indefinitely, must be reviewed by the executive every week and that the orders are subject to judicial review. In that regard, the SC may pave for strengthened challenges to internet shutdowns in the future. However, as several scholars have noted, besides ordering the restoration of some essential services, the Court does fall short of providing relief to Kashmiri citizens in the case. Soon after the SC delivered this judgment, the government of Jammu and Kashmir issued orders to internet service providers to restore 2G internet services but only permit access to 301 websites. Besides the fact that the list arbitrarily includes and excludes services, major communication services were notably from the list. Most importantly, this piece of ‘internet regulation’ makes little sense when you consider either the internet or the regulations governing it.
In the technical sense, the regulations completely misunderstand how the modern web functions. When one connects to a website, the websites in turn often make the system download critical resources from other servers. If internet service providers permit only specific websites, the content from other unwhite listed sources still remains inaccessible. A recent experiment by Rohini Lakshané and Prateek Waghre confirms this empirically: out of the 301 websites in the list, only 126 were usable in some form. While the order seems like a necessary consequence of the SC order, there is also little legislative basis for the order. The order cites the Temporary Suspension of Telecom Services (Public Emergency or Public Safety) Rules issued in 2017 under the colonial-era Indian Telegraph Act. These regulations do permit the Government to shut down telecom and internet services but do not allow the government to issue orders that allow ‘whitelists’ such as this one. The Information Technology (IT) Act, namely through Section 69A, allows the Central Government and courts to order the blocking of certain websites. Even the license agreements issued by the government to internet service providers only allow the Government to order the blocking certain online resources on the grounds of national security. Therefore, the order of a ‘whitelist’ of websites has no basis in law because it turns the logic of only blocking websites on its head.
After Kashmiris found a way to circumvent the ‘whitelist’ by using virtual private networks (VPNs), reports emerged that security forces were forcing Kashmiris to uninstall these applications. All this, of course, despite the fact that there is no law preventing the use of VPNs or the circumvention of internet censorship in general.
It has now been around seven months since internet and telecom services were suspended in Kashmir. This long-standing deprivation of basic rights to Kashmiris is wrong that perhaps even the future cannot correct. After months of a complete shutdown, the Government can make better amends than restoring only limited and partial access. As we march onto the next decade, the world is watching. History will not judge kindly those who occluded civil liberties through a facile ritual incantation of ‘public order’ and ‘national security’.
Comments to the Personal Data Protection Bill 2019
Please view our general comments below, or download as PDF here.
Our comments and recommendations can be downloaded as PDF here.
We have also prepared an annotated version of the Bill, where our detailed comments and recommendations can be viewed alongside the Bill, available as PDF here.
General Comments
1. Executive notification cannot abrogate fundamental rights
In 2017, the Supreme Court in K.S. Puttaswamy v Union of India [1] held the right to privacy to be a fundamental right. While this right is subject to reasonable restrictions, the restrictions have to meet a three fold requirement, namely (i) existence of a law; (ii) legitimate state aim; (iii) proportionality.Under the 2018 Bill, the exemption to government agencies for processing of personal data from the provisions of the Bill in the ‘interest of the security of the State’ [2] was subject to a law being passed by Parliament. However, under Clause 35 of the present Bill, the Central Government is merely required to pass a written order exempting the government agency from the provisions of the Bill.Any restriction on the right to privacy will have to comply with the conditions prescribed in Puttaswamy I. An executive order issued by the central government authorising any agency of the government to process personal data does not satisfy the first requirement laid down by the Supreme Court in Puttaswamy I — as it is not a law passed by Parliament. The Supreme Court while deciding upon the validity of Aadhar in K.S. Puttaswamy v Union of India [3] noted that “an executive notification does not satisfy the requirement of a valid law contemplated under Puttaswamy. A valid law in this case would mean a law passed by Parliament, which is just, fair and reasonable. Any encroachment upon the fundamental right cannot be sustained by an executive notification.”
2. Exemptions under Clause 35 do not comply with the legitimacy and proportionality test
The lead judgement in Puttaswamy I while formulating the three fold test held that the restraint on privacy emanate from the procedural and content based mandate of Article 21 [4]. The Supreme Court in Maneka Gandhi v Union India [5] had clearly established that “mere prescription of some kind of procedure cannot ever meet the mandate of Article 21. The procedure prescribed by law has to be fair, just and reasonable, not fanciful, oppressive and arbitrary” [6]. The existence of a law is the first requirement; the second requirement is that of ‘legitimate state aim’. As per the lead judgement this requirement ensures that “the nature and content of the law which imposes the restriction falls within the zone of reasonableness mandated by Article 14, which is a guarantee against arbitrary state action” [7]. It is established that for a provision which confers upon the executive or administrative authority discretionary powers to be regarded as non-arbitrary, the provision should lay down clear and specific guidelines for the executive to exercise the power [8]. The third test to be complied with is that the restriction should be ‘proportionate,’ i.e. the means that are adopted by the legislature are proportional to the object and needs sought to be fulfilled by the law. The Supreme Court in Modern Dental College & Research Centre v State of Madhya Pradesh [9] specified the components of proportionality standards —
- A measure restricting a right must have a legitimate goal;
- It must be a suitable means of furthering this goal;
- There must not be any less restrictive, but equally effective alternative; and
- The measure must not have any disproportionate impact on the right holder
Clause 35 provides extensive grounds for the Central Government to exempt any agency from the requirements of the bill but does not specify the procedure to be followed by the agency while processing personal data under this provision. It merely states that the ‘procedure, safeguards and oversight mechanism to be followed’ will be prescribed in the rules.The wide powers conferred on the central government without clearly specifying the procedure may be contrary to the three fold test laid down in Puttaswamy I, as it is difficult to ascertain whether a legitimate or proportionate objective is being fulfilled [10].
3. Limited powers of Data Protection Authority in comparison with the Central Government
In comparison with the last version of the Personal Data Protection Bill, 2018 prepared by the Committee of Experts led by Justice Srikrishna, we witness an abrogation of powers of the Data Protection Authority (Authority), to be created, in this Bill. The powers and functions that were originally intended to be performed by the Authority have now been allocated to the Central Government. For example:
- In the 2018 Bill, the Authority had the power to notify further categories of sensitive personal data. Under the present Bill, the Central Government in consultation with the sectoral regulators has been conferred the power to do so.
- Under the 2018 Bill, the Authority had the sole power to determine and notify significant data fiduciaries, however, under the present Bill, the Central Government has in consultation with the Authority been given the power to notify social media intermediaries as significant data fiduciaries.
In order to govern data protection effectively, there is a need for a responsive market regulator with a strong mandate and resources. The political nature of the personal data also requires that the governance of data, particularly the rule-making and adjudicatory functions performed by the Authority are independent of the Executive.
4. No clarity on data sandbox
The Bill contemplates a sandbox for “ innovation in artificial intelligence, machine-learning or any other emerging technology in public interest.” A Data Sandbox is a non-operational environment where the analyst can model and manipulate data inside the data management system. Data sandboxes have been envisioned as a secure area where only a copy of the company’s or participant companies’ data is located [11]. In essence, it refers to the scalable and creation platform which can be used to explore an enterprise’s information sets. On the other hand, regulatory sandboxes are controlled environments where firms can introduce innovations to a limited customer base within a relaxed regulatory framework, after which they may be allowed entry into the larger market after meeting certain conditions. This purportedly encourages innovation through the lowering of entry barriers by protecting newer entrants from unnecessary and burdensome regulation. Regulatory sandboxes can be interpreted as a form of responsive regulation by governments that seek to encourage innovation – they allow selected companies to experiment with solutions within an environment that is relatively free of most of the cumbersome regulations that they would ordinarily be subject to, while still subject to some appropriate safeguards and regulatory requirements. Sandboxes are regulatory tools which may be used to permit companies to innovate in the absence of heavy regulatory burdens. However, these ordinarily refer to burdens related to high barriers to entry (such as capital requirements for financial and banking companies), or regulatory costs. In this Bill, however, the relaxing of data protection provisions for data fiduciaries would lead to restrictions of the privacy of individuals. Limitations to a fundamental rights on grounds of ‘fostering innovation’ is not a constitutional tenable position, and contradict the primary objectives of a data protection law.
5. The primacy of ‘harm’ in the Bill ought to be reconsidered
While a harms based approach is necessary for data protection frameworks, such approaches should be restricted to the positive obligations, penal provisions and responsive regulation of the Authority. The Bill does not provide any guidance on either the interpretation of the term ‘harm,’ [12] or on the various activities covered within the definition of the term. Terms such as ‘loss of reputation or humiliation’ ‘any discriminatory treatment’ are a subjective standard and are open to varied interpretations. This ambiguity in the definition will make it difficult for the data principal to demonstrate harm and for the DPA to take necessary action as several provisions are based upon harm being caused or likely to be caused.Some of the significant provisions where ‘harm’ is a precondition for the provision to come into effect are —
- Clause 25: Data Fiduciary is required to notify the Authority about the breach of personal data processed by the data fiduciary, if such breach is likely to cause harm to any data principal. The Authority after taking into account the severity of the harm that may be caused to the data principal will determine whether the data principal should be notified about the breach.
- Clause 32 (2): A data principal can file a complaint with the data fiduciary for a contravention of any of the provisions of the Act, which has caused or is likely to cause ‘harm’ to the data principal.
- Clause 64 (1): A data principal who has suffered harm as a result of any violation of the provision of the Act by a data fiduciary, has the right to seek compensation from the data fiduciary.
Clause 16 (5): The guardian data fiduciary is barred from profiling, tracking or undertaking targeted advertising directed at children and undertaking any other processing of personal data that can cause significant harm to the child.
6. Non personal data should be outside the scope of this Bill
Clause 91 (1) states that the Act does not prevent the Central Government from framing a policy for the digital economy, in so far as such policy does not govern personal data. The Central Government can, in consultation with the Authority, direct any data fiduciary to provide any anonymised personal data or other non-personal data to enable better targeting of delivery of services or formulation of evidence based policies in any manner as may be prescribed.It is concerning that the data protection bill has specifically carved out an exception for the Central Government to frame policies for the digital economy and seems to indicate that the government plans to freely use any and all anonymized and/or non-personal data that rests with any data fiduciary that falls under the ambit of the bill to support the digital economy including for its growth, security, integrity, and prevention of misuse. It is unclear how the government, in practice, will be able to compel organizations to share this data. Further, there is a lack of clarity on the contours of the definition of non-personal data and the Bill does not define the term. It is also unclear whether the Central Government can compel the data fiduciary to transfer/share all forms of non-personal data and the rights and obligations of the data fiduciaries and data principals over such forms of data. Anonymised data refers to data which has ‘ irreversibly’ been converted into a form in which the data principal cannot be identified. However, as several instances have shown ‘ irreversible’ anonymisation is not possible. In the United States, the home addresses of taxi drivers were uncovered and in Australia individual health records were mined from anonymised medical bills [13]. In September 2019, the Ministry of Electronics and Information Technology, constituted an expert committee under the chairmanship of Kris Gopalkrishnan to study various issues relating to non-personal data and to deliberate over a data governance framework for the regulation of such data.The provision should be deleted and the scope of the bill should be limited to protection of personal data and to provide a framework for the protection of individual privacy. Until the report of the expert committee is published, the Central Government should not frame any law/regulation on the access and monetisation of non-personal/ anonymised data nor can they create a blanket provision allowing them to request such data from any data fiduciary that falls within the ambit of the bill. If the government wishes to use data resting with a data fiduciary; it must do so on a case to case basis and under formal and legal agreements with each data fiduciary.
7. Steps towards greater decentralisation of power
We propose the following steps towards greater decentralisation of powers and devolved jurisdiction —
- Creation of State Data Protection Authorities: A single centralised body may not be the appropriate form of such a regulator. We propose that on the lines of central and state commissions under the Right to Information Act, 2005, state data protection authorities are set up which are in a position to respond to local complaints and exercise jurisdiction over entities within their territorial jurisdictions.
- More involvement of industry bodies and civil society actors: In order to lessen the burden on the data protection authorities it is necessary that there is active engagement with industry bodies, sectoral regulators and civil society bodies engaged in privacy research. Currently, the Bill provides for involvement of industry or trade association, association representing the interests of data principals, sectoral regulator or statutory Authority, or an departments or ministries of the Central or State Government in the formulation of codes of practice. However, it would be useful to also have a more active participation of industry associations and civil society bodies in activities such as promoting awareness among data fiduciaries of their obligations under this Act, promoting measures and undertaking research for innovation in the field of protection of personal data.
8. The Authority must be empowered to exercise responsive regulation
In a country like India, the challenge is to move rapidly from a state of little or no data protection law, and consequently an abysmal state of data privacy practices to a strong data protection regulation and a powerful regulator capable of enabling a state of robust data privacy practices. This requires a system of supportive mechanisms to the stakeholders in the data ecosystem, as well as systemic measures which enable the proactive detection of breaches. Further, keeping in mind the limited regulatory capacity in India, there is a need for the Authority to make use of different kinds of inexpensive and innovative strategies.We recommend the following additional powers for the Authority to be clearly spelt out in the Bill —
- Informal Guidance: It would be useful for the Authority to set up a mechanism on the lines of the Security and Exchange Board of India (SEBI)’s Informal Guidance Scheme, which enables regulated entities to approach the Authority for non-binding advice on the position of law. Given that this is the first omnibus data protection law in India, and there is very little jurisprudence on the subject from India, it would be extremely useful for regulated entities to get guidance from the regulator.
- Power to name and shame: When a DPA makes public the names of organisations that have seriously contravened data protection legislation, this is a practice known as “naming and shaming.” The UK ICO and other DPAs recognise the power of publicity, as evidenced by their willingness to co-operate with the media. The ICO does not simply post monetary penalty notices (MPNs or fines) on its websites for journalists to find, but frequently issues press releases, briefs journalists and uses social media. The ICO’s publicity statement on communicating enforcement activities states that the “ICO aims to get media coverage for enforcement activities.”
- Undertakings: The UK ICO has also leveraged the threats of fines into an alternative enforcement mechanism seeking contractual undertakings from data controllers to take certain remedial steps. Undertakings have significant advantages for the regulator. Since an undertaking is a more “co-operative”solution, it is less likely that a data controller will change it. An undertaking is simpler and easier to put in place. Furthermore, the Authority can put an undertaking in place quickly as opposed to legal proceedings which are longer.
9. No clear roadmap for the implementation of the Bill
The 2018 Bill had specified a roadmap for the different provisions of the Bill to come into effect from the date of the Act being notified [14]. It specifically stated the time period within which the Authority had to be established and the subsequent rules and regulations notified.The present Bill does not specify any such blueprint; it does not provide any details on either when the Bill will be notified or the time period within within which the Authority shall be established and specific rules and regulations notified. Considering that 25 provisions have been deferred to rules that have to be framed by the Central Government and a further 19 provisions have been deferred to the regulations to be notified by the Authority the absence and/or delayed notification of such rules and regulations will impact the effective functioning of the Bill.The absence of any sunrise or sunset provision may disincentivise political or industrial will to support or enforce the provisions of the Bill. An example of such a lack of political will was the establishment of the Cyber Appellate Tribunal. The tribunal was established in 2006 to redress cyber fraud. However, it was virtually a defunct body from 2011 onwards when the last chairperson retired. It was eventually merged with the Telecom Dispute Settlement and Appellate Tribunal in 2017.We recommend that Bill clearly lays out a time period for the implementation of the different provisions of the Bill, especially a time frame for the establishment of the Authority. This is important to give full and effective effect to the right of privacy of the
individual. It is also important to ensure that individuals have an effective mechanism to enforce the right and seek recourse in case of any breach of obligations by the data fiduciaries.For offences, we suggest a system of mail boxing where provisions and punishments are enforced in a staggered manner, for a period till the fiduciaries are aligned with the provisions of the Act. The Authority must ensure that data principals and fiduciaries have sufficient awareness of the provisions of this Bill before bringing the provisions for punishment are brought into force. This will allow the data fiduciaries to align their practices with the provisions of this new legislation and the Authority will also have time to define and determine certain provisions that the Bill has left the Authority to define. Additionally enforcing penalties for offences initially must be in a staggered process, combined with provisions such as warnings, in order to allow first time and mistaken offenders from paying a high price. This will relieve the fear of smaller companies and startups who might fear processing data for the fear of paying penalties for offences.
10. Lack of interoperability
In its current form, a number of the provisions in the Bill will make it difficult for India’s framework to be interoperable with other frameworks globally and in the region. For example, differences between the draft Bill and the GDPR can be found in the grounds for processing, data localization frameworks, the framework for cross border transfers, definitions of sensitive personal data, inclusion of the undefined category of ‘critical data’, and the roles of the authority and the central government.
11. Legal Uncertainty
In its current structure, there are a number of provisions in the Bill that, when implemented, run the risk of creating an environment of legal uncertainty. These include: lack of definition of critical data, lack of clarity in the interpretation of the terms ‘harm’ and ‘significant harm’, ability of the government to define further categories of sensitive personal data, inclusion of requirements for ‘social media intermediaries’, inclusion of ‘non-personal data’, framing of the requirements for data transfers, bar on processing of certain forms of biometric data as defined by the Central Government, the functioning between a consent manager and another data fiduciary, the inclusion of an AI sandbox and the definition of state. To ensure the greatest amount of protection of individual privacy rights and the protection of personal data while also enabling innovation, it is important that any data protection framework is structured and drafted in a way to provide as much legal certainty as possible.
Endnotes
1. (2017) 10 SCC 641 (“Puttaswamy I”).
2. Clause 42(1) of the 2018 Bill states that “Processing of personal data in the interests of the security of the State shall not be permitted unless it is authorised pursuant to a law, and is in accordance with the procedure established by such law, made by Parliament and is necessary for, and proportionate to such interests being achieved.”
3. (2019) 1 SCC 1 (“Puttaswamy II”)
4. Puttaswamy I, supra, para 180.
5. (1978) 1 SCC 248.
6. Ibid para 48.
7. Puttaswamy I supra para 180.
8. State of W.B. v. Anwar Ali Sarkar, 1952 SCR 284; Satwant Singh Sawhney v A.P.O AIR 1967 SC1836.
9. (2016)7 SCC 353.
10. Dvara Research “Initial Comments of Dvara Research dated 16 January 2020 on the Personal Data Protection Bill, 2019 introduced in Lok Sabha on 11 December 2019”, January 2020, https://www.dvara.com/blog/2020/01/17/our-initial-comments-on-the-personal-data-protection-bill-2019/ (“Dvara Research”).
11. “A Data Sandbox for Your Company”, Terrific Data, last accessed on January 31, 2019, http://terrificdata.com/2016/12/02/3221/.
12. Clause 3(20) — “harm” includes (i) bodily or mental injury; (ii) loss, distortion or theft of identity; (ii) financial loss or loss of property; (iv) loss of reputation or humiliation; (v) loss of employment; (vi) any discriminatory treatment; (vii) any subjection to blackmail or extortion; (viii) any denial or withdrawal of service,benefit or good resulting from an evaluative decision about the data principal; (ix) any restriction placed or suffered directly or indirectly on speech, movement or any other action arising out of a fear of being observed or surveilled; or (x) any observation or surveillance that is not reasonably expected by the data principal.
13. Alex Hern “Anonymised data can never be totally anonymous, says study”, July 23, 2019 https://www.theguardian.com/technology/2019/jul/23/anonymised-data-never-be-anonymous-enough-study-finds.
14. Clause 97 of the 2018 Bill states“(1) For the purposes of this Chapter, the term ‘notified date’ refers to the date notified by the Central Government under sub-section (3) of section 1. (2)The notified date shall be any date within twelve months from the date of enactment of this Act. (3)The following provisions shall come into force on the notified date-(a) Chapter X; (b) Section 107; and (c) Section 108. (4)The Central Government shall, no later than three months from the notified date establish the Authority. (5)The Authority shall, no later than twelve months from the notified date notify the grounds of processing of personal data in respect of the activities listed in sub-section (2) of section 17. (6)The Authority shall no, later than twelve months from the date notified date issue codes of practice on the following matters-(a) notice under section 8; (b) data quality under section 9; (c) storage limitation under section 10; (d) processing of personal data under Chapter III; (e) processing of sensitive personal data under Chapter IV; (f ) security safeguards under section 31; (g) research purposes under section 45; (h) exercise of data principal rights under Chapter VI; (i) methods of de-identification and anonymisation; (j) transparency and accountability measures under Chapter VII. (7)Section 40 shall come into force on such date as is notified by the Central Government for the purpose of that section.(8)The remaining provision of the Act shall come into force eighteen months from the notified date.”
Law and Politics of Global Governance Course Outline
INTRODUCTION
Since 1945, a crude amalgamation of transnational regulatory agencies, standard-setting bodies and inter-governmental organisations has wielded considerable influence in shaping the civil, political, social and economic conditions for human beings across the globe. Yet, the project of global governance as articulated by the UN Charter, Bretton Woods institutions, and many other international instruments has struggled to move past its inherently undemocratic character. Democratic states are governed by a legislature, an executive and an independent judiciary, all guided by a constitution that reflects the will of the people. The ‘liberal, international order’, which reflects the post-War aspiration for a “democratic peace” neither has corresponding institutions nor mechanisms that render it accountable to the global public. The lack of direct linkages between the governance structures and the governed resulted in the manipulation of multilateral regimes by powerful interest groups, states and non-state actors. The international order today has incubated an “underclass” of vulnerable communities, including refugees, indigenous populations, agricultural labourers and blue-collar workers -- that Richard Stewart has appropriately termed ‘the disregarded.
During the past decade, populist leaders have latched onto the outbreak of discontent among the disregarded and jettisoned multilateral, rules-based cooperation for policies favouring protectionism and isolationism. Withdrawal from treaties and processes , rejection of human rights norms and the stonewalling of processes at the international level have cast a grim shadow on the future of multilateralism.
As India takes up its rightful position as a norm enterpreneur in the global order, she must ask herself what sort of an order does she want to shape? A modest derivation of the established order that was driven largely by the super-powers of the time, or a new world order-shaped by the leaders of today? Are there values from the old order that continue to be applicable in today’s day and age? Can International Law be conceptualized as an instrument that accomplishes more than mere virtue-signalling for the elite?
All these are tough questions-questions that budding lawyers from the global South should be equipped to grapple with. This course does not seek to provide any answers -indeed a silver bullet solution might prove to be elusive. Neither does it seek to frame the questions-students are expected to figure this out for themselves. Indeed, the journey to framing the right questions would mark half the battle won. Instead, we hope to stimulate intellectual thought and provoke discord so that the voices of the hitherto disregarded are never silenced again.
The course starts off by quickly recapping some of the basics of International Law and International Relations. It then moves onto the structure and functioning of existing institutions with a bid to provoke critique of the same. We then look separately at two sides of the global governance architecture-the Bretton Woods driven international economic order and the UN driven human rights regime-both of which are under considerable threat. We then dedicate a unit solely to pontificating on the future of International Law in an era of lucrative deals.
We then zoom in a little bit-looking at India’s role in this cacophony and how we can pave a way forward for ourselves in a manner that serves our national interest and benefits the most vulnerable. In the final unit, we look at technology-which holds the key to international relations for the next century. A new Iron Curtain is rising as a clash of values, interests and institutions are coming to the fore again to determine the future of cyberspace. Lessons from the last seven decades (and the first six units of this course) might have to be unlearned and reformed. Not doing so makes us run the risk of entrenched redundancy.
Click to read the full course outline here
Content takedown and users' rights
This article was first published at the Leaflet. It has subsequently been republished by Scroll.in, Kashmir Observer and the CyberBRICS blog.
Introduction
Last year, several Jio users from different states reported that sites like Indian Kanoon, Reddit and Telegram were inaccessible through their connections. While attempting to access the website, the users were presented with a notice that the websites were blocked on orders from the Department of Telecommunications (DoT). When contacted by the founder of Indian Kanoon, Reliance Jio stated that the website had been blocked on orders of the government, and that the order had been rescinded the same evening. However, in response to a Right to Information (RTI) request, the DoT said they had no information about orders relating to the blocking of Indian Kanoon.
Alternatively, consider that the Committee to Protect Journalists (CPJ) expressed concern last year that the Indian government was forcing Twitter to suspend accounts or remove content relating to Kashmir. They reported that over the last two years, the Indian government suppressed a substantial amount of information coming from the area, and prevented Indians from accessing more than five thousand tweets.
These instances are symptomatic of a larger problem of opaque and arbitrary content takedown in India, enabled by the legal framework under the Information Technology (IT) Act. The Government derives its powers to order intermediaries (entities storing or transmitting information on behalf of others, a definition which includes internet service providers and social media platforms alike) to block online resources through section 69A of the IT Act and the rules [“the blocking rules”] notified thereunder. Apart from this, section 79 of the IT Act and its allied rules also prescribe a procedure for content removal. Conversations with one popular intermediary revealed that the government usually prefers to use its powers under section 69A, possibly because of the opaque nature of the procedure that we highlight below.
Under section 69A, a content removal request can be sent by authorised personnel in the Central Government not below the rank of a Joint Secretary. The grounds for issuance of blocking orders under section 69A are: “the interest of the sovereignty and integrity of India, defence of India, the security of the state, friendly relations with foreign states or public order or for preventing incitement to the commission of any cognisable offence relating to the above.” Specifically, the blocking rules envisage the process of blocking to be largely executive-driven, and require strict confidentiality to be maintained around the issuance of blocking orders. This shrouds content takedown orders in a cloak of secrecy, and makes it impossible for users and content creators to ascertain the legitimacy or legality of the government action in any instance of blocking.
Issues
The Supreme Court had been called to determine the constitutional validity of section 69A and the allied rules in Shreya Singhal v Union of India. The petitioners had contended that as per the procedure laid down by these rules, there was no guarantee of pre-decisional hearing afforded to the originator of the information. Additionally, the petitioners pointed out that the safeguards built into section 95 and 96 of the Code of Criminal Procedure (CrPC), which allow state governments to ban publications and persons to initiate legal challenges to those actions respectively, were absent from the blocking procedures. Lastly, the petitioners assailed rule 16 of the blocking rules, which mandated confidentiality of blocking procedures, on the grounds that it was affecting their fundamental rights.
The Court, however, found little merit in these arguments. Specifically, the Court found that section 69A was narrowly drawn and had sufficient procedural safeguards, which included the grounds of issuance of a blocking order being specifically drawn, and mandating that the reasons of the website blocking be in writing, thus making it amenable to judicial review. Further, the Court also found that the provision of setting up of a review committee saved the law from being constitutional infirmity. In the Court’s opinion, the mere absence of additional safeguards, as the ones built into the CrPC, did not mean that the law was unconstitutional.
But do the ground realities align with the Court’s envisaged implementation of these principles? Apar Gupta, a counsel for the petitioners, pointed out that there was no recorded instance of pre-decisional hearing being granted to show that this safeguard contained in the rules was actually being implemented. However, Gautam Bhatia read Shreya Singhal to make an important advance: that the right of hearing be mandatorily extended to the ‘originator’, i.e. the content creator.
Additionally, Bhatia also noted that the Court, while upholding the constitutionality of the procedure under section 69A, held that the “reasons have to be recorded in writing in such blocking order so that they may be assailed in a writ petition under Article 226 of the Constitution.”
There are two important takeaways from this. Firstly, he argued that the broad contours of the judgment invoke an established constitutional doctrine — that the fundamental right under Article 19(1)(a) does not merely include the right of expression, but also the right of access to information. Accordingly, the right of challenging a blocking order was not only vested in the originator or the concerned intermediary, but may rest with the general public as well. And secondly, by the doctrine of necessary implication, it followed that for the general public to challenge any blocking order under Article 226, the blocking orders must be made public. While Bhatia concedes that public availability of blocking orders may be an over-optimistic reading of the judgment, recent events suggest that even the commonly-expected result, i.e. that the content creators having the right to a hearing, has not been implemented by the Government.
Consider the blocking of the satirical website DowryCalculator.com in September 2019 on orders from the government. The website displayed a calculator that suggests a ‘dowry’ depending on the salary and education of a prospective groom: even if someone misses the satire, the contents of the website are not immediately relatable to any grounds of removal listed under section 69A of the IT Act.
Tanul Thakur, the creator of the website, was not granted a hearing despite the fact that he had publicly claimed the ownership of the website at various times and that the website had been covered widely by the press. The information associated with the domain name also publicly lists Thakur’s name and contact information. Clearly, the government made no effort to contact Thakur when passing the order. Perhaps even more worryingly, when he tried to access a copy of the blocking order by filing a RTI, the MeitY cited the confidentiality rule to deny him the information.
This incident documents a fundamental problem plaguing the rules: the confidentiality clause is still being used to deny disclosure of key information on content takedown orders. The government has also used the provision to deny citizens a list of blocked websites , as responses to RTI requests have proven time and again.
Clearly, the Supreme Court’s rationale in considering Section 69A and the blocking rules as constitutional is not one that is implemented in reality. The confidentiality clause is preventing legal challenges to content blocking in totality: content creators are unable access the orders, and hence are unable to understand the executive’s reasoning in ordering their content to be blocked from public access.
As we noted earlier, the grounds of issuing a blocking order under section 69A pertain to certain reasonable restrictions on expression permitted by Article 19(2), which are couched in broad terms. The government’s implementation of section 69A and the rules make it impossible for any judicial review or accountability on the conformity of blocking orders with the mentioned grounds under the rules, or any reasonable restriction at all.
The Way Forward
From the opacity of proceedings under the law, to the lack of information regarding the same on public domain, the Indian content takedown regime leaves a lot to be desired from both the government and intermediaries at play.
First, we believe the Supreme Court’s decision in Shreya Singhal v. Union of India casts an obligation on the government to attempt to contact the content creator if they are passing a content takedown order to an intermediary. Second, even if the content creator is unavailable for a hearing at that instance, the confidentiality clause should not be used to prevent future disclosure of information to the content creator, so that affected citizens can access and challenge these orders.
While we wait for legal reform, intermediaries can also step up to ensure the rights of users online are upheld. On receiving formal orders, intermediaries should assess the legality of the received request. This should involve ensuring that only authorised agencies and personnel have sent the content removal orders, that the order specifically mentions what provision the government is exercising the power under, and that the content removal requests relate to the grounds of removal that are permissible under section 69A. For instance, intermediaries should refuse to entertain content removal requests under section 69A of the IT Act if they relate to obscenity, a ground not covered by the provision.
The representatives of the intermediary should also push for the committee to grant a hearing to the content creator. Here, the intermediary can act as a liaison between the uploader and the governmental authorities.
The Supreme Court’s recent decision in Anuradha Bhasin v. Union of India offers a glimmer of hope for user rights online. While the case primarily challenged the orders imposing section 144 of the CrPC and a communication blockade in Jammu and Kashmir, the final decision does affirm the fundamental principle that government-imposed restrictions on the freedom of expression and assembly must be made available to the public and affected parties to enable challenges in a court of law.
The judiciary has yet another opportunity to consider the provision and the rules: late last year, Tanul Thakur approached the Delhi High Court to challenge the orders passed by the government to ISPs to block his website. One hopes that the future holds robust reforms to the content takedown regime.
We live in an era where the ebb and flow of societal discourse is increasingly channeled through intermediaries on the internet. In the absence of a mature, balanced and robust framework that enshrines the rule of law, we risk arbitrary modulation of the marketplace of ideas by the executive.
Torsha Sakar and Gurshabad Grover are researchers at the Centre for Internet and Society.
Disclosure: The Centre for Internet and Society is a recipient of research grants from Facebook and Google.
How the Data Protection Bill Regulates Social Media Platforms
This opinion piece by Tanaya Rajwade and Gurshabad Grover was published in the Wire on 17 February 2020. The authors would like to thank Arindrajit Basu and Pallavi Bedi for their comments and suggestions.
The Personal Data Protection Bill was tabled in the Lok Sabha in December following much anticipation and debate
The tabled Bill significantly differs from the one proposed by the Justice Srikrishna Committee, especially when it comes to provisions relating to governmental access to citizens’ data, with (retd) Justice Srikrishna going so far as to call it ‘dangerous’ and capable of creating ‘an Orwellian state’.
What has gone under the radar, perhaps, amidst this is the implications of the ‘social media intermediary’ construct that the Bill introduces, and the proposal to require certain social media platforms to provide users the option to voluntarily verify their accounts.
Section 26 defines ‘social media intermediary’ as a service that facilitates online interaction between two or more ‘users’ and allows users to disseminate media. While e-commerce, internet service providers, search engines, and email services are explicitly excluded from the definition, this term is broad enough to cover messaging services like WhatsApp, Telegram and Signal.
The Bill further provides for certain social media intermediaries to be designated as ‘significant data fiduciaries.’
Apart from the generic obligations that the Bill proposes for significant data fiduciaries, Section 28(3) requires these designated entities to provide users with an account verification mechanism.
Scope and permissibility
Clearly, the intended effect of the provisions is outside the ambit of what we generally understand by ‘data protection.’ Perhaps the drafters also recognised this, and therefore awkwardly included ‘laying down norms for social media intermediaries’ in the preamble.
The fundamental issue here is that the obligation conflicts with a core tenet of similar legislation globally that has been emphasised in the Bill as well: data minimisation, i.e. the principle that organisations should not collect more information than needed to fulfill their purpose. The verification requirement is essentially a State diktat coercing social media companies into collecting more information about their users than is necessary.
Another way to look at the provision is as a move to indirectly expand the amount of information available to the government. Interestingly, the intention behind Section 28(3) is not mentioned in the Bill or its Statement of Objects and Reasons. The legitimate aim required to justify privacy infringements by the State as laid down in Puttaswamy v. Union of India has not been sufficiently clarified in the case of this provision.
Therefore, this provision could very well flounder on being subjected to constitutional scrutiny.
Excessive delegation: Is the devil in the detail?
Another striking feature of the provisions is that several important decisions are left to the executive. The Bill gives the Centre the power to designate certain social media intermediaries as ‘significant data fiduciaries’ if they have with users higher than notified thresholds, whose ‘actions have, or are likely to have a significant impact on electoral democracy, security of the State, public order or the sovereignty and integrity of India’.
We can contrast this with the fact that the general power to classify entities as significant data fiduciaries lies with the Data Protection Authority (DPA). However, when it comes to social media intermediaries, the DPA is reduced to a paper tiger, with only consultation (and not even concurrence) being sought from the DPA.
This concentration of power in the hands of the government should be viewed in conjunction with the obvious conflict of interest created by the Bill: the government would be incentivised to designate platforms which attract dissenting speech, thereby increasing their obligations and concomitant costs.
The classification criterion is also problematic as ‘significant impact on electoral democracy’ is a subjective standard. Such powers could be a case of excessive delegation to the executive, possibly having an arbitrary impact on all growing social media platforms. Given this ambiguity, social media platforms may be incentivised to err on the side of caution and to apply harsher content moderation practices to police dissenting speech.
‘Voluntary’ verification of users
The Bill requires intermediaries to extend to users the option to verify their accounts, and verified accounts are to be provided a mark that shall be visible to all users. The manner in which platforms are supposed to facilitate this verification is yet another critical matter that is left to delegated legislation. If the history of Aadhaar is any indication, such delegation may result in rules that compromise the stated ‘voluntary’ nature of the provision.
Even if left truly voluntary, this obligation may have an adverse impact on the exercise of freedom of expression online. Almost all leading social media platforms rely on user insights to drive personalised advertisement services that generate most of their revenue. These platforms have normalised private-actor surveillance of human behaviour, and seek to collect as much information as possible about users and non-users alike.
For instance, despite criticism, Facebook has a ‘real name’ policy, going as far as collecting information from users’ friends and third-parties to verify the ‘real’ identities of its users. Therefore, platforms like Facebook may incentivise the verification of accounts by increasing the visibility and reach of content created by ‘verified’ accounts, thereby eroding the legitimacy of pseudonymous expression.
The proposal is in sharp contrast with EU’s General Data Protection Regulation, which has led to rulings in Germany that Facebook’s ‘real name’ policy violates the law. The primary motivation of data protection legislation is to limit the personal and social harms that arise out of such indiscriminate collection of information. Unfortunately, instead of mitigating these, the Bill may very well end up entrenching these harms.
Legitimising surveillance
It is also relevant to note that the intermediary guidelines proposed by the MeitY were criticised for placing onerous requirements on ‘intermediaries’, a term in the Information Technology (IT) Act that remains a Procrustean bed for almost all internet services. Since the IT Act does not provide a separate definition of ‘social media intermediary’ and only defines an ‘intermediary’, the inclusion of the provision in the Bill may be a more convenient, albeit misplaced, effort to classify intermediaries and subsequently carve out specific obligations.
However, as we point out, this classification is outside the scope of the PDP Bill and would be better suited in the IT Act. The proposed provisions lack a clear and legitimate aim that is sought to be achieved from user account verification, and an excessive delegation of powers to the executive.
The provisions also need to be looked at in conjunction with Section 35 of the Bill, which empowers the Central government to exempt any government agency from obligations relating to processing of personal data in the interest of security of the State where necessary.
This provision marks a significant dilution of the Bill proposed by the Srikrishna Committee, which clearly incorporated the Supreme Court’s ruling in Puttaswamy v. Union of India: any invasion into privacy by the government must be authorised by law, be necessary for a legitimate state purpose and be proportional to the said goal. If the Bill is passed in its current form, exempted law enforcement and intelligence agencies would be able to demand data from social media intermediaries, including information on the ‘real identity’ of users, with little safeguards.
Unfortunately, it seems that several provisions of the Bill, including the schema relating to social media platforms, seek to legitimise disproportionate forms of state surveillance rather than curbing the power of the government to invade citizens’ privacy.
Tanaya Rajwade and Gurshabad Grover are researchers at the Centre for Internet and Society (CIS). Views are the authors’ alone.
Disclosure: The CIS is a recipient of research grants from Facebook.
Divergence between the General Data Protection Regulation and the Personal Data Protection Bill, 2019
Our note on the divergence between the General Data Protection Regulation and the Personal Data Protection Bill can be downloaded as a PDF here.
The European Union’s General Data Protection Regulation (GDPR), replacing the 1995 EU Data Protection Directive came into effect in May 2018. It harmonises the data protection regulations across the European Union. In India, the Ministry of Electronics and Information Technology had constituted a Committee of Experts (chaired by Justice Srikrishna) to frame recommendations for a data protection framework in India. The Committee submitted its report and a draft Personal Data Protection Bill in July 2018 (2018 Bill). Public comments were sought on the bill till October 2018. The Central Government revised the Bill and introduced the revised version of the Personal Data Protection Bill (PDP Bill) on December 11, 2019 in the Lok Sabha.
The PDP Bill has incorporated certain aspects of the GDPR, such as requirements for notice to be given to the data principal, consent for processing of data, establishment of a data protection authority, etc. However, there are some differences and in this note we have highlighted the areas of divergence between the two. It only includes provisions which are common to the GDPR and the PDP Bill. It does not include the provisions on (i) Appellate Tribunal, (ii) Finance, Account and Audit; and (iii) Non- Personal Data.
Comparison of the Personal Data Protection Bill with the General Data Protection Regulation and the California Consumer Protection Act
Our note on the comparison of the Personal Data Protection Bill with the General Data Protection Regulation an the California Consumer Protection Act can be downloaded as a PDF here
The European Union’s General Data Protection Regulation (GDPR), replacing the 1995 EU Data Protection Directive came into effect in May 2018. It harmonises the data protection regulations across the European Union. In 2018, California passed the Consumer Protection Act (CCPA), to enhance the privacy protection of residents of California. The CCPA came into effect from January 1, 2020, however, the California Attorney General has not begun enforcing the law as yet. The Attorney General will be allowed to take action six months after the rules are finalised, or on July 1, 2020, whichever is earlier
While the PDP Bill incorporates several concepts of the CCPA and the GDPR, there are also significant areas of divergence. We have prepared the following charts to compare the PDP Bill with the GDPR and the CCPA on the following points: (i) Jurisdiction and scope (ii) Rights of the Data Principal; (iii) Obligations of the Data Fiduciaries; (iv) Exemptions; (v) Data Protection Authority; and (vi) Breach of Personal Data. It is not a comprehensive list of all requirements under the three regulations.
The charts are based on the comparative charts prepared by the Future of Privacy Forum.
Governing ID: Introducing our Evaluation Framework
With the rise of national digital identity systems (Digital ID) across the world, there is a growing need to examine their impact on human rights. In several instances, national Digital ID programmes started with a specific scope of use, but have since been deployed for different applications, and in different sectors. This raises the question of how to determine appropriate and inappropriate uses of Digital ID. In April 2019, our research began with this question, but it quickly became clear that a determination of the legitimacy of uses hinged on the fundamental attributes and governing structure of the Digital ID system itself. Our evaluation framework is intended as a series of questions against which Digital ID may be tested. We hope that these questions will inform the trade-offs that must be made while building and assessing identity programmes, to ensure that human rights are adequately protected.
Rule of Law Tests
Foundational Digital ID must only be implemented along with a legitimate regulatory framework that governs all aspects of Digital ID, including its aims and purposes, the actors who have access to it, etc. In the absence of this framework, there is nothing that precludes Digital IDs from being leveraged by public and private actors for purposes outside the intended scope of the programme. Our rule of law principles mandate that the governing law should be enacted by the legislature, be devoid of excessive delegation, be clear and accessible to the public, and be precise and limiting in its scope for discretion. These principles are substantiated by the criticism that the Kenyan Digital ID, the Huduma Namba, was met with when it was legalized through a Miscellaneous Amendment Act, meant only for small or negligible amendments and typically passed without any deliberation. These set of tests respond to the haste with which Digital ID has been implemented, often in the absence of an enabling law which adequately addresses its potential harms.
Rights based Tests
Digital ID, because of its collection of personal data and determination of eligibility and rights of users, intrinsically involves restrictions on certain fundamental rights. The use of Digital ID for essential functions of the State, including delivery of benefits and welfare, and maintenance of civil and sectoral records, enhance the impact of these restrictions. Accordingly, the entire identity framework, including its architecture, uses, actors, and regulators, must be evaluated at every stage against the rights it is potentially violating. Only then will we be able to determine if such violation is necessary and proportionate to the benefits it offers. In Jamaica, the National Identification and Registration Act, which mandated citizens’ biometric enrolment at the risk of criminal sanctions, was held to be a disproportionate violation of privacy, and therefore unconstitutional.
Risk based Tests
Even with a valid rule of law framework that seeks to protect rights, the design and use of Digital ID must be based on an analysis of the risks that the system introduces. This could take the form of choosing between a centralized and federated data-storage framework, based on the effects of potential failure or breach, or of restricting the uses of the Digital ID to limit the actors that will benefit from breaching it. Aside from the design of the system, the regulatory framework that governs it should also be tailored to the potential risks of its use. The primary rationale behind a risk assessment for an identity framework is that it should be tested not merely against universal metrics of legality and proportionality, but also against an examination of the risks and harms it poses. Implicit in a risk based assessment is also the requirement of implementing a responsive mitigation strategy to the risks identified, both while creating and governing the identity programme.
Digital ID programmes create an inherent power imbalance between the State and its residents because of the personal data they collect and the consequent determination of significant rights, potentially creating risks of surveillance, exclusion, and discrimination. The accountability and efficiency gains they promise must not lead to hasty or inadequate implementation.
Document Actions

