Blog
Indian Intermediary Liability Regime: Compliance with the Manila Principles on Intermediary Liability
The report was edited by Elonnai Hickok and Swaraj Barooah
The report is an examination of Indian laws based upon the background paper to the Manila Principles as the explanatory text on which these recommendations have been based, and not an assessment of the principles themselves. To do this, the report considers the Indian regime in the context of each of the principles defined in the Manila Principles. As such, the explanatory text to the Manila Principles recognizes that diverse national and political scenario may require different intermediary liability legal regimes, however, this paper relies only on the best practices prescribed under the Manila Principles.
The report is divided into the following sections
- Principle I: Intermediaries should be shielded by law from liability for third-party content
- Principle II: Content must not be required to be restricted without an order by a judicial authority
- Principle III: Requests for restrictions of content must be clear, be unambiguous, and follow due process
- Principle IV: Laws and content restriction orders and practices must comply with the tests of necessity and proportionality
-
Principle V: Laws and content restriction policies and practices must respect due process
-
Principle VI: Transparency and accountability must be built into laws and content restriction policies and practices
-
Conclusion
DIDP Request #30 - Employee remuneration structure at ICANN
We have requested ICANN to disclose information pertaining to the income of each employee based on the following grounds. We had hoped this information will increase ICANN's transparency regarding their remuneration policies however ths was not the case, they either referred to their earlier documents who do not have concrete information or stated that the relevant documents were not in their possession. Their response to the respective questions were:
Average salary across designations
ICANN responded by referring to their FY18 Remuneration Practices document which states, “ICANN uses a global compensation expert consulting firm to provide comprehensive benchmarking market data (currently Willis Towers Watson, Mercer and Radford). The market study is conducted before the salary review process. Estimates of potential compensation adjustments typically are made during the budgeting process based on current market data. The budget is then approved as part of ICANN’s overall budget planning process.”
Average salary for female and male employees
ICANN responded by saying “ICANN org’s remuneration philosophy and practice is not based upon gender” which is why they said that they have “no documentary information in ICANN org’s possession, custody or control that is responsive to this request.” However, the exact average salaries of female and male employees was not provided nor any information that could that could give us an idea as to whether the remuneration of their employees was in accordance with the above claim.
Bonuses - frequency at which it is given and upon what basis
ICANN responded by referring to “Discretionary At-Risk Component” section in their FY18 Remuneration Practices document which states,”The amount of at-risk pay an individual can earn is based on a combination of both the achievement of goals as well as the behaviors exhibited in achieving those goals… The Board has approved a framework whereby those with ICANN Org are eligible to earn an at-risk payment of up to 20 percent of base compensation as at-risk payment based on role and level in the organization, with certain senior executives eligible for up to 30 percent.” The duration over which the employees are eligible to receive an “at-risk” payment was given to be “twice a year".
Average salary across regions for the same region
ICANN responded by saying,”compensation may vary across the regions based on currency differences, the availability of positions in a given region, market conditions, as well as the type of positions that are available in a given region. “ They also added that they have no documentary information in their possession, custody or control that is responsive to this request.
The request filed by Paul Kurian may be found here. ICANN's response can be read here.
Design Concerns in Creating Privacy Notices
This blog post was edited by Elonnai Hickok.
The Role of Design in Enabling Informed Consent
Currently, privacy notices and choice mechanisms, are largely ineffective. Privacy and security researchers have concluded that privacy notices not only fail to help consumers make informed privacy decisions but are mostly ignored by them. [1] They have been reduced to being a mere necessity to ensure legal compliance for companies. The design of privacy systems has an essential role in determining whether the users read the notices and understand them. While it is important to assess the data practices of a company, the communication of privacy policies to users is also a key factor in ensuring that the users are protected from privacy threats. If they do not read or understand the privacy policy, they are not protected by it at all.
The visual communication of a privacy notice is determined by the User Interface (UI) and User Experience (UX) design of that online platform. User experience design is broadly about creating the logical flow from one step to the next in any digital system, and user interface design ensures that each screen or page that the user interacts with has a consistent visual language and styling. This compliments the path created by the user experience designer. [2] UI/UX design still follows the basic principles of visual communication where information is made understandable, usable and interesting with the use of elements such as colours, typography, scale, and spacing.
In order to facilitate informed consent, the design principles are to be applied to ensure that the privacy policy is presented clearly, and in the most accessible form. A paper by Batya Friedman, Peyina Lin, and Jessica K. Miller, ‘Informed Consent By Design’, presents a model of informed consent for information systems. [3] It mentions the six components of the model; Disclosure, Comprehension, Voluntariness, Competence, Agreement, Minimal Distraction. The design of a notice should achieve these components to enable informed consent. Disclosure and comprehension lead to the user being ‘informed’ while ‘consent’ encompasses voluntariness, competence, and agreement. Finally, The tasks of being informed and giving consentshould happen with minimal distraction, without diverting users from their primary taskor overwhelming them with unnecessary noise.[4]
UI/UX design builds upon user behaviour to anticipate their interaction with the platform. It has led to practices where the UI/UX design is directed at influencing the user to respond in a way that is desired by the system. For instance, the design of default options prompts users to allow the system to collect their data when the ‘Allow’ button is checked by default. Such practices where the interface design is used to push users in a particular direction are called “dark patterns”.[5] These are tricks used in websites and apps that make users buy or sign up for things that they did not intend to. [6] Dark patterns are often followed as UI/UX trends without the consequences on users being questioned. This has had implications on the design of privacy systems as well. Privacy notices are currently being designed to be invisible instead of drawing attention towards them.
Moreover, most communication designers believe that privacy notices are beyond their scope of expertise. They do not consider themselves accountable for how a notice comes across to the user. Designers also believe that they have limited agency when it comes to designing privacy notices as most of the decisions have been already taken by the company or the service. They can play a major role in communicating privacy concerns at an interface level, but the issues of privacy are much deeper. Designers tend to find ways of informing the user without compromising the user experience, and in the process choose aesthetic decisions over informed consent.
Issues with Visual Communication of Privacy Notices
The ineffectiveness of privacy notices can be attributed to several broad issues such as the complex language and length, their timing, and location. In 2015, the Center for Plain Language [7] published a privacy-policy analysis report [8] for TIME.com [9], evaluating internet-based companies’ privacy policies to determine how well they followed plain language guidelines. The report concluded that among the most popular companies, Google and Facebook had the more accessible notices, while Apple, Uber, and Twitter were ranked as less accessible. The timing of notices is also crucial in ensuring that it is read by the users. The primary task for the user is to avail the service being offered. The goals of security and privacy are valued but are only secondary in this process. [10] Notices are presented at a time when they are seen as a barrier between the user and the service. People thus, choose to ignore the notices and move on to their primary task. Another concern is disassociated notices or notices which are presented on a separate website or manual. The added effort of going to an external website also gets in the way of the users which leads to them not reading the notice. While most of these issues can be dealt with at the strategic level of designing the notice, there are also specific visual communication design issues that are required to be addressed.
Invisible Structure and Organisation of Information
Long spells of text with no visible structure or content organisation is the lowest form of privacy notices. These are the blocks of text where the information is flattened with no visual markers such as a section separator, or contrasting colour and typography to distinguish between the types of content. In such notices, the headings and subheadings are also not easy to locate and comprehend. For a user, the large block of text appears to be pointless and irrelevant, and they begin to dismiss or ignore it. Further, the amount of time it would take for the user to read the entire text and comprehend it successfully, is simply impractical, considering the number of websites they visit regularly.

The privacy policy notice by Apple [11] with no use of colours or visuals.

The privacy policy notice by Twitter [12] no visual segregator
Visual Contrast Between Front Interface and Privacy Notices
The front facing interface of an app or website is designed to be far more engaging than the privacy notice pages. There is a visible difference in the UI/UX design of the pages, almost as if the privacy notices were not designed at all. In case of Uber’s mobile app, the process of adding a destination, selecting the type of cab and confirming a ride has been made simple to do for any user. This interface has been thought through keeping in mind the users’ behaviour and needs. It allows for quick and efficient use of the service. As opposed to the process of buying into the service, the privacy notice on the app is complex and unclear.


Uber mobile app screenshots of the front interface (left) and the policy notice page (right)
Gaining Trust Through the Initial Pitch
A pattern in the privacy notices of most companies is that they attempt to establish credibility and gain confidence by stating that they respect the users’ privacy. This can be seen in the introductory text of the privacy notices of Apple and LinkedIn. The underlying intent seems to be that since the company understands that the users’ privacy is important, the users can rely on them and not read the full notice.

Introduction text to Apple’s privacy policy notice [13]

Introduction text to LinkedIn’s privacy policy notice [14]
Low Navigability
The text heavy notices need clear content pockets which can be navigated through easily using mechanisms such as menu bar. Navigability of a document allows for quick locating of sections, and moving between them. Several companies miss to follow this. Apple and Twitter privacy notices (shown above), have low navigability as the reader has no prior indication of how many sections there are in the notice. The reader could have summarised the content based on the titles of the sections if it were available in a table of contents or a menu. Lack of a navigation system leads to endless scrolling to reach the end of the page.
Facebook privacy notice, on the other hand is an example of good navigability. It uses typography and colour to build a clear structure of information that can be navigated through easily using the side menu. The menu doubles up as a table of contents for the reader. The side menu however, does not remain visible while scrolling down the page. This means while the user is reading through a section, they cannot switch to a different section from the menu directly. They will need to click on the ‘Return to top’ button and then select the section from the menu.

Navigation menu in the Facebook Data Policy page [15]
Lack of Visual Support
Privacy notices can rely heavily on visuals to convey the policies more efficiently. These could be visual summaries or supporting infographics. The data flow on the platform and how it would affect the users can be clearly visualised using infographics. But, most notices fail to adopt them. The Linkedin privacy notice [16] page shows a video at the beginning of its privacy policy. Although this could have been an opportunity to explain the policy in the video, LinkedIn only gives an introduction to the notice and follows it with a pitch to use the platform. The only visual used in notices currently are icons. Facebook uses icons to identify the different sections so that they can be located easily. But, apart from being identifiers of sections, these icons do not contribute to the communication of the policy. It does not make reading of the full policy any easier.
Icon Heavy ‘Visual’ Privacy Notices
The complexity of privacy notices has led to the advent of online tools and generators that create short notices or summaries for apps and websites to supplement the full text versions of policies. Most of these short notices use icons as a way of visually depicting the categories of data that is being collected and shared. iubenda [17], an online tool, generates policy notice summary and full text based on the inputs given by the client. It asks for the services offered by the site or app, and the type of data collection. Icons are used alongside the text headings to make the summary seem more ‘visual’ and hence more easily consumable. It makes the summary more inviting to read, but does not reduce the time for reading.
Another icon-based policy summary generator was created by KnowPrivacy. [18] They developed a policy coding methodology by creating icon sets for types of data collected, general data practices, and data sharing. The use of icons in these short notices is more meaningful as they show which type of data is collected or not collected, shared or not shared at a glance without any text. This facilitates comparison between data practices of different apps.

Icon based short policy notice created for Google by KnowPrivacy [19]
Initiatives to Counter Issues with the Design of Privacy Notices
Several initiatives have called out the issues with privacy notices and some have even countered them with tools and resources. The TIME.com ranking of internet-based companies’ privacy policies brought attention to the fact that some of the most popular platforms have ineffective policy notices. A user rights initiative called Terms of Services; Didn’t Read [20] rates and labels websites’ terms & privacy policies. There is also the Usable Privacy Policy Project which develops techniques to semi-automatically analyze privacy policies with crowdsourcing, natural language processing, and machine learning. [21] It uses artificial intelligence to sift through the most popular sites on the Internet, including Facebook, Reddit, and Twitter, and annotate their privacy policies. They realise that it is not practical for people to read privacy policies. Thus, their aim is to use technology to extract statements from the notices and match them with things that people care about. However, even AI has not been fully successful in making sense of the dense documents and missed out some important context. [22]
One of the more provocative initiatives is the Me and My Shadow ‘Lost in Small Print’ [23] project. It shows the text for the privacy notices of companies like LinkedIn, Facebook, WhatsApp, etc. and then ‘reveals’ the data collection and use information that would closely affect the users.
Issues with notices have also been addressed by standardising their format, so people can interpret the information faster. The Platform for Privacy Preferences Project (P3P) [24] was one of the initial efforts in enabling websites to share their privacy practices in a standard format. Similar to KnowPrivacy’s policy coding, there are more design initiatives that are focusing on short privacy notice design. An organisation offering services in Privacy Compliance and Risk Management Solutions called TrustArc, [25] is also in the process of designing an interactive icon-based privacy short notice.

TrustArc’s proposed design [26] for the short notice for a sample site
Most efforts have been done in simplifying the notices so as to decode the complex terminology. But, there have been very few evaluations and initiatives to improve the design of these notices.
Recommendations
Multilayered Privacy Notices
One of the existing suggestions on increasing usability of privacy notices are multilayered privacy notices. [27] Multilayered privacy notices comprise a very short notice designed for use on portable digital devices where there is limited space, condensed notice that contains all the key factors in an easy to understand way, and a complete notice with all the legal requirements. [28] Some of the examples above use this in the form of short notices and summaries. The very short notice layer consists of who is collecting the information, primary uses of information, and contact details of the organisation.[29] Condensed notice layer covers scope or who does the notice apply to, personal information collected, uses and sharing, choices, specific legal requirements if any, and contact information. [30] In order to maintain consistency, the sequence of topics in the condensed and the full notice must be same. Words and phrases should also be consistent in both layers. Although an effective way of simplifying information, multi-layered notices must be reconsidered along with the timing of notices. For instance, it could be more suitable to show very short notices at the time of collection or sharing of user data.
Supporting Infographics
Based on their visual design, the currently available privacy notices can be broadly classified into 4 categories; (i) the text only notices which do not have a clearly visible structure, (ii) the text notices with a contents menu that helps in informing of the structure and in navigating, (iii) the notices with basic use of visual elements such as icons used only to identify sections or headings, (iv) multilayered notices or notices with short summary before giving out the full text. There is still a lack of visual aid in all these formats. The use of visuals in the form of infographics to depict data flows could be more helpful for the users both in short summaries and complete text of policy notices.
Integrating the Privacy Notices with the Rest of the System
The design of privacy notices usually seems disconnected to the rest of the app or website. The UI/UX design of privacy notices requires as much attention as the consumer-facing interface of a system. The contribution of the designer has to be more than creating a clean layout for the text of the notice. The integration of privacy notices with the rest of the system is also related to the early involvement of the designer in the project. The designer needs to understand the information flows and data practices of a system in order to determine whether privacy notices are needed, who should be notified, and about what. This means that decisions such as selecting the categories to be represented in the short or condensed notice, the datasets within these categories, and the ways of representing them would all be part of the design process. The design interventions cannot be purely visual or UI/UX based. They need to be worked out keeping in mind the information architecture, content design, and research. By integrating the notices, strategic decisions on the timing and layering of content can be made as well, apart from the aesthetic decisions. Just as the aim of the front face of the interface in a system makes it easier for the user to avail the service, the policy notice should also help the user in understanding the consequences, by giving them clear notice of the unexpected collection or uses of their data.
Practice Based Frameworks on Designing Privacy Notices
There is little guidance available to communication designers for the actual design of privacy notices which is specific to the requirements and characteristics of a system. [31] The UI/UX practice needs to be expanded to include ethical ways of designing privacy notices online. The paper published by Florian Schaub, Rebecca Balebako, Adam L. Durity, and Lorrie Faith Cranor, called, ‘A Design Space for Effective Privacy Notice’ in 2015 offers a comprehensive design framework and standardised vocabulary for describing privacy notice options. [32] The objective of the paper is to allow designers to use this framework and vocabulary in creating effective privacy notices. The design space suggested has four key dimensions, ‘timing’, ‘channel’, ‘modality’ and ‘control’. [33] It also provides options for each of these dimensions. For example, ‘timing’ options are ‘at setup’, ‘just in time’, ‘context-dependent’, ‘periodic’, ‘persistent’, and ‘on demand’. The dimensions and options in the design space can be expanded to accommodate new systems and interaction methods.
Considering the Diversity of Audiences
For the various mobile apps and services, there are multiple user groups who use them. The privacy notices are hence not targeted to one kind of an audience. There are diverse audiences who have different privacy preferences for the same system. [34] The privacy preferences of these diverse groups of users’ must be accommodated. In a typical design process for any system, multiple user personas are identified. The needs and behaviour of each persona is used to determine the design of the interface. Privacy preferences must also be observed as part of these considerations for personas, especially while designing the privacy notices. Different users may need different kinds of notices based on which data practices affect them.[35] Thus, rather than mandating a single mechanism for obtaining informed consent for all users in all situations, designers need to provide users with a range of mechanisms and levels of control. [36]
Ethical Framework for Design Practitioners
An ethical framework is required for design practitioners that can be followed at the level of both deciding the information flow and the experience design. With the prevalence of ‘dark patterns’, the visual design of notices is used to trick users into accepting it. Design ethics can play a huge role in countering such practices. Will Dayable, co-director at Squareweave, [37] a developer of web and mobile apps, suggests that UI/UX designers should “Design Like They’re (Users are) Drunk”. [38] He asks designers to imagine the user to be in a hurry and still allow them access to all the information necessary for making a decision. He concludes that good privacy UX and UI is about actually trying to communicate with users rather than trying to slip one past them. In principle, an ethical design practice would respect the rights of the users and proactively design to facilitate informed consent.
Reconceptualising Privacy Notices
Based on the above recommendations, a guiding sample for multilayered privacy notices has been created. Each system would need its own structure and mechanisms for notices, which are integrated with its data practice, audiences, and medium, but this sample notice provides basic guidelines for creating effective and accessible privacy notices. The aesthetic decisions would also vary based on the interface design of a system.

Sample Fixed Icon for Privacy Notifications
A fixed icon can appear along with all privacy notifications on the system, so that the users can immediately know that the notification is about a privacy concern. This icon should capture attention instantly and suggest a sense of caution. Besides its use as a call to attention, the icon can also lead to a side panel for privacy implications from all actions that the user takes.

Sample Very Short Notice on Desktop and Mobile Platforms
The very short notices can be shown when an action from the user would lead to data collection or sharing. The notice mechanism should be designed to provide notices at different times tailored to a user’s needs in that context. The styling and placement of the ‘Allow’ and ‘Don’t Allow’ buttons should not be biased towards the ‘Allow’ option. The text used in very short and condensed notice layers should be engaging yet honest in its communication.

Sample Summary Notice
The summary or the condensed notice layer should allow the user to gauge at a glance, how the data policy is going to affect them. This can be combined with a menu that lists the topics covered in the full notice. The menu would double up as a navigation mechanism for users. It should be visible to users even as they scroll down to the full notice. The condensed notice can also be supported by an infographic depicting the flow of data in the system.

Sample Navigation Menu
All the images in this section use sample text for the purpose of illustrating the structure and layout
The full notice can be made accessible by creating a clear information hierarchy in the text. The menu which is available on the side while scrolling down the text would facilitate navigation and familiarity with the structure of the notice.
Conclusion
The presentation of privacy notices directly influences the decisions of users online and ineffective notices make users vulnerable to their data being misused. But currently, there is little conversation about privacy and data protection among designers. Design practice has to become sensitive to privacy and security requirements. Designers need to take the accountability of creating accessible notices which are beneficial to the users, rather than to the companies issuing them. They must prioritise the well-being of users over aesthetics and user experience even. The aesthetics of a platform must be directed at achieving transparency in the privacy notice by making it easily readable.
The design community in India has a more urgent task at hand of building a design practice that is informed by privacy. Comparing the privacy notices of Indian and global companies, Indian companies have an even longer way to go in terms of communicating the notices effectively. Most Indian companies such as Swiggy, [39] 99acres, [40] and Paytm [41] have completely textual privacy policy notices with no clear information hierarchy or navigation. Ola Cabs [42] provides an external link to their privacy notice, which opens as a pdf, making it even more inaccessible. Thus, there is a complete lack of design input in the layout of these notices.
Designers must engage in conversations with technologists and researchers, and include privacy and other user rights in design education in order to prepare practitioners for creating more valuable digital platforms.
- https://www.ftc.gov/system/files/documents/public_comments/2015/10/00038-97832.pdf
- https://www.fastcodesign.com/3032719/ui-ux-who-does-what-a-designers-guide-to-the-tech-industry
- https://vsdesign.org/publications/pdf/Security_and_Usability_ch24.pdf
- https://vsdesign.org/publications/pdf/Security_and_Usability_ch24.pdf
- https://fieldguide.gizmodo.com/dark-patterns-how-websites-are-tricking-you-into-givin-1794734134
- https://darkpatterns.org/
- https://centerforplainlanguage.org/
- https://centerforplainlanguage.org/wp-content/uploads/2016/11/TIME-privacy-policy-analysis-report.pdf
- http://time.com/3986016/google-facebook-twitter-privacy-policies/
- https://www.safaribooksonline.com/library/view/security-and-usability/0596008279/ch04.html
- https://www.apple.com/legal/privacy/en-ww/?cid=wwa-us-kwg-features-com
- https://twitter.com/privacy?lang=en
- https://www.apple.com/legal/privacy/en-ww/?cid=wwa-us-kwg-features-com
- https://www.linkedin.com/legal/privacy-policy
- https://www.facebook.com/privacy/explanation
- https://www.linkedin.com/legal/privacy-policy
- http://www.iubenda.com/blog/2013/06/13/privacypolicyforandroidapp/
- http://knowprivacy.org/policies_methodology.html
- http://knowprivacy.org/profiles/google
- https://tosdr.org/
- https://explore.usableprivacy.org/
- https://motherboard.vice.com/en_us/article/a3yz4p/browser-plugin-to-read-privacy-policy-carnegie-mellon
- https://myshadow.org/lost-in-small-print
- https://www.w3.org/P3P/
- http://www.trustarc.com/blog/2011/02/17/privacy-short-notice-designpart-i-background/
- http://www.trustarc.com/blog/?p=1253
- https://www.ftc.gov/system/files/documents/public_comments/2015/10/00038-97832.pdf
- https://www.informationpolicycentre.com/uploads/5/7/1/0/57104281/ten_steps_to_develop_a_multilayered_privacy_notice__white_paper_march_2007_.pdf
- https://www.informationpolicycentre.com/uploads/5/7/1/0/57104281/ten_steps_to_develop_a_multilayered_privacy_notice__white_paper_march_2007_.pdf
- https://www.informationpolicycentre.com/uploads/5/7/1/0/57104281/ten_steps_to_develop_a_multilayered_privacy_notice__white_paper_march_2007_.pdf
- https://www.ftc.gov/system/files/documents/public_comments/2015/10/00038-97832.pdf
- https://www.ftc.gov/system/files/documents/public_comments/2015/10/00038-97832.pdf
- https://www.ftc.gov/system/files/documents/public_comments/2015/10/00038-97832.pdf
- https://www.safaribooksonline.com/library/view/security-and-usability/0596008279/ch04.html
- https://www.ftc.gov/system/files/documents/public_comments/2015/10/00038-97832.pdf
- https://vsdesign.org/publications/pdf/Security_and_Usability_ch24.pdf
- https://www.squareweave.com.au/
- https://iapp.org/news/a/how-ui-and-ux-can-ko-privacy/
- https://www.swiggy.com/privacy-policy
- https://www.99acres.com/load/Company/privacy
- https://pages.paytm.com/privacy.html
- https://s3-ap-southeast-1.amazonaws.com/ola-prod-website/privacy_policy.pdf
CIS contributes to ABLI Compendium on Regulation of Cross-Border Transfers of Personal Data in Asia
The compendium contains 14 detailed reports written by legal practitioners, legal scholars and researchers in their respective jurisdictions, on the regulation of cross-border data transfers in the wider Asian region (Australia, China, Hong Kong SAR, India, Indonesia, Japan, South Korea, Macau SAR, Malaysia, New Zealand, Philippines, Singapore, Thailand, and Vietnam).
The compendium is intended to act as a springboard for the next phase of ABLI's project, which will be devoted to the in-depth study of the differences and commonalities between Asian legal systems on these issues and – where feasible – the drafting of recommendations and/or policy options to achieve convergence in this area of law in Asia.
The chapter titled Jurisdictional Report India was authored by Amber Sinha and Elonnai Hickok. The compendium can be accessed here.
Comments on the Draft National Policy on Official Statistics
Edited by Swaraj Barooah. Download a PDF of the submission here
Preliminary
CIS appreciates the Government’s efforts in realising the importance of the need for high quality statistical information enshrined in the Fundamental Principles of Official Statistics as adopted by the UN General Assembly in January 2014. CIS is grateful for the opportunity to put forth its views on the draft policy. This submission was made on 31st May, 2018.
First, this submission highlights some general defects in the draft policy: there is lack of principles guiding data dissemination policies; there are virtually no positive mandates set for Government bodies for secure storage and transmission of data; and while privacy is mentioned as a concern, it has been overlooked in designing the principles of the implementation of surveys. Then, this submission puts forward specific comments suggesting improvements to various sections in the draft policy.
CIS would also like to point out the short timeline between the publication of the draft policy (18th May, 2018), and the deadline set for the stakeholders to submit their comments (31st May, 2018). Considering that the policy has widespread implications for all Ministries, citizens, and State legislation rights (proposed changes include a Constitutional Amendment), it is necessary that such call-for-comments are publicised widely, and enough time is given to the public so that the Government can receive well-researched comments.
General Comments
Data dissemination
For data dissemination, the draft policy does not stress upon a general principle or set of principles, and often disregards principles specified in the Fundamental Principles of Official Statistics, which are the very principles the Government intends to draw its policies on official statistics from. Rather it relies on context-specific provisions that fail to summarise and articulate a general philosophy for the dissemination of official statistics, and fails to practically embody some stated goals. The first principle on Official Statistics, as realised by the United Nations General Assembly, clearly states that: “[...] official statistics that meet the test of practical utility are to be compiled and made available on an impartial basis by official statistical agencies to honour citizens’ entitlement to public information.”
Let us compare this with Section 5.1.7 (9) of the draft policy, which refers to policies regarding core statistics: it mentions a data “warehouse” to be maintained by the NSO which should be accessible to private and public bodies. While this does point towards an open data policy, such a vision has not been articulated in any part thereof.
The draft policy, at the outset, should have general guiding principles of publishing data openly and freely (once it meets the utility test, and it has been ensured that individual privacy will not be violated by the publishing of such statistics). This should serve well to inform further regulations and related policies governing the use and publishing of statistics, like the Statistical Disclosure Control Report.
A general commitment to a well-articulated policy on data dissemination will ensure easy-to-follow principles for the various Ministries that will refer to the document. The additional principles that come with open data principles should also be described by the policy document: a commitment to publishing data in a machine-readable format, making it available in multiple data formats (.txt, .csv, etc.), and including its metadata.
Data storage and usage
In the absence of a regime for data protection, it is absolutely necessary that a national policy on statistics provide positive mandates for the encryption of all digitally-stored personal and sensitive information collected through surveys. Even though the current draft of the policy mentions the need to protect confidential information, it sets no mandatory requirements on the Government to ensure the security of such information, especially on digital platforms.
Additionally, all transmission of potentially sensitive information should be done with the digital signatures of the employee/Department/Ministry authorising said transmission. This will ensure the integrity and authenticity of the information, and provide with an auditable trail of the information flowing between entities in the various bodies.
Data privacy
It is appreciable that Section 5.7.9 of the draft policy notes, “[a]ll statistical surveys represent a degree of privacy invasion, which is justified by the need for an alternative public good, namely information.” However, all statistical surveys may not be proportionate in their invasiveness, even if they might serve a legitimate public goal in the future.
The draft policy does not address how privacy concerns can be taken into account while designing the survey itself. A necessary outcome of the realisation of the possible privacy violations that may arise due to surveys is that all data collection be “minimally intrusive”, the data be securely stored (see previous comment section, ‘Data storage and usage’), and the surveyed users have control over the data even after they have parted with their information.
Since the policy deals extensively with the implementation of surveys, the following should details should be clearly laid out in the policy:
- The extent to which an individual has control over the data they have provided to the surveying agency.
- The means of redressal available to an individual who feels that his/her privacy has been violated through the publication of certain statistical information
Specific Comments
Section 5.1: Dichotomising official statistics as core statistics and other official statistics
Comments
The reasons for dichotomising official statistics has not been appropriately substantiated with evidence, considering the wide implications of policy proposals that arise from the definition of “core statistics.”
Firstly, the descriptions of what constitutes “core statistics” casts too wide a net by only having a single vague qualitative criterion, i.e. “national importance.” All the other characteristics of the “core statistics” are either recommendations or requirements as to how the data will be handled and thus, pose no filter to what can constitute “core statistics.” The wide net is apparent in the fact that even the initially-proposed list of “core statistics”, given in Annex-II of the policy, has 120 categories of statistics.
Secondly, the policy does not provide reasons for why the characteristics of “core statistics”, highlighted in Section 5.1.5, should not apply to all official statistics at the various levels of Government. Therefore, the utility of the proposed dichotomy has also not been appropriately substantiated with illustrative examples of how “core statistics” should be considered qualitatively different from all official statistics.
This definition may lead to widespread disagreement between the States and the Centre, because Section 5.2 proposes that “core statistics” be added to the Union List of the Seventh Schedule of the Constitution. How the proposal may affect Centre-State responsibilities and relations pertaining to the collection and dissemination of statistics is elaborated in the next section.
Recommendations
The policy should not make a forced dichotomy between “core” and (ipso facto) non-core statistics. If a distinction is to be made for any reason(s) (such as for the purposes of delineating administrative roles) then such reason must be clearly defined, along with a clear explanation for why such a dichotomy would alleviate the described problem. The definitions should have tangible and unambiguous qualitative criteria.
Section 5.2: Constitutional amendment in respect of core statistics
Comments
The main proposal in the section is that the Seventh Schedule of the Constitution be amended to include “core statistics” in the Union List. This would give the Parliament the legislative competence to regulate the collection, storage, publication and sharing of such statistics, and the Central Government the power to enforce such legislation. Annex-II provides a tentative list of what would constitute “core statistics”; as is apparent, this list is wide-ranging and consists over 120 items which span the gamut of administrative responsibilities.
The list includes items such as “Landholdings Number, area, tenancy, land utilisation [...]” (S. No. 21), and “Statistics on land records” (S. No. 111) while most responsibilities of land regulation currently lie with the States. Similarly, items in Annex-II venture into statistics related to petroleum, water, agriculture, electricity, and industry; some of which are in the Concurrent or State List.
Statistics are metadata. There is no reason for why the administration of a particular subject lie with the State, and the regulation of data about such subject should lie with solely with the Central Government. It is important to recognise that adding the vaguely defined “core statistics” to the Union List, while enabling the Central Government to execute and plan such statistical exercises, will also prevent the States from enacting any legislation that regulates the management of statistics regarding its own administrative responsibilities.
The regulation of State Government records in general has been a contentious issue, and its place in our federal structure has been debated several times in the Parliament: the enactment of Public Records Act, 1993; the Right to Information Act, 2005; and the Collection of Statistics Act, 2008 are predicated on an assumption of such competence lying with the Parliament. However, it is equally important to recognise the role States have played in advancing transparency of Government records. For example, State-level Acts analogous to the Right to Information Act existed in Tamil Nadu and Karnataka before the Central Government enactment.
Recommendations
We strongly recommend that “statistics” be included in the Concurrent List, so that States are free to enact progressive legislation which advances transparency and accountability, and is not in derogation of Parliamentary legislation.
The Ministry should view this statistical policy document as a venue to set the minimum standards for the collection, handling and publication of statistics regarding its various functions. If the item is added to the Concurrent List, the States, through local legislation, will only have the power to improve on the Central standards since in a case of conflict, State-levels laws will be superseded by Parliamentary ones.
Section 5.3: Mechanism for regulating core statistics including auditing
Comments
The draft policy in Section 5.3.2 says, “[...] The Committee will be assisted by a Search Committee headed by the Vice-Chairperson of the NITI Aayog, in which a few technical experts could be included as Members.” The non-commital nature of the word ‘could’ in this statement detracts from the importance of having technical experts on this committee, by making their inclusion optional. The policy also does not specify who has the power to include technical experts as Members in the Search Committee. The statement should include either a minimum number of a specific number or members, and not use the non-committal word “could”
The National Statistical Development Council, as mentioned in 5.3.9, is supposed to “handle Centre-State relations in the areas of official statistics, the Council should be represented by Chief Ministers of six States to be nominated by the Centre” (Section 5.3.10). The draft does not elaborate on the rationale behind including just six states in the Council. It does not recommend any mechanism on the basis of which Centre will nominate states in the council.
Recommendations
The policy should recommend a minimum number of technical experts who must be included in the search committee, along with a clear process for how such members are to be appointed.
Additionally, the policy appropriately recognises the great diversity in India and the unique challenges faced by each State. Thus, each State has its unique requirements. Since in Section 5.3.11, the policy recommends that council meet at a low frequency of at least once in a year, all States should be represented in the Council.
Section 5.4: Official Machinery to implement directions on core statistics
Comments
The functions of Statistics Wing in the MOSPI, laid out in Section 5.4.7, include advisory functions which overlap with functions of National Statistical Commission (NSC) mentioned in Section 5.3.5. Some regulatory functions of Statistics Wing, like “conducting quality checks and auditing of statistical surveys/data sets”, overlap with the regulatory functions of NSC mentioned in Section 5.3.7.
In section 5.3.1, the draft policy explicitly mentions that “what is feasible and desirable is that production of official statistics should continue with the Government, whereas the related regulatory and advisory functions could be kept outside the Government”. But Statistics Wing is a part of the government and it also has regulatory and advisory functions. It will adversely affect the power of NSC as an autonomous body.
There are inconsistencies in the draft-policy regarding the importance and need of a decentralized statistical system. In section 3 [Objectives], it has been emphasized that the Indian Statistical System shall function within decentralized structure of the system. But, in section 5.4.15, the draft says that decentralized statistical system poses a variety of problems, and advocates for a unified statistical system. Again, in section 5.15, draft emphasizes the development of sub-national statistical systems. These views are inconsistent and create confusion regarding the nature of statistical system that policy wants to pursue.
Recommendations
The functions of the NSC should be kept in its exclusive domain. Any such overlapping functions should be allocated to one agency taking into consideration the Fundamental Principles on Official Statistics.
The inconsistencies regarding the decentralisation philosophy of the statistical system should be addressed.
Section 5.5: Identifying statistical products required through committees
Comments
While Section 5.5.2 recognises data confidentiality as a goal for statistical coordination, it does not take into account the violation of privacy that might occur due to the sharing of data. For example, a certain individual might agree to share personal information with a particular Ministry, but have apprehensions about it being shared with other Ministries or private parties.
Recommendations
We recommend that point 4 in Section 5.5.2 be read as, “enabling sharing of data without compromising the privacy of individuals and the confidentiality/security of data.”The value of of the individual privacy stems from both the recent Supreme Court judgment that affirmed privacy as a Fundamental Right, and also Principle 6 of the of the Fundamental Principles of Official Statistics. Realising privacy as a goal in this section will add a realm of individual control that is already articulated in Section 5.7.9.
Annex-VII: Guidelines on Outsourcing statistical activities
Comments
Section 6 defines “sensitive information” in an all-inclusive manner and does not leave space for further inclusion of any information that may be interpreted as sensitive. For example, biometric data has not been listed as “sensitive information”.
Section 9.1, draft says, “[t]he identity of the Government agency and the Contractor may be made available to informants at the time of collection of data”. It is imperative that informants have the right to verify the identity of the Government agency and the Contractor before parting with their personal information.
Recommendations
The definition of “sensitive information” should be broad-based with scope for further inclusion of any kind of data that may be deemed “sensitive.”
Section 9.1 must mandate that the identity of the Government agency and the Contractor be made available to informants at the time of collection of data.
Section 9.6 can be redrafted to state that each informant must be informed of the manner in which the informant could access the data collected from the informant in a statistical project, as also of the measures taken to deny access on that information to others, except in the cases specified by the policy.
Section 10.2 can be improved to state that if information exists in a physical form that makes the removal of the identity of informants impracticable (e.g. on paper), the information should be recorded in another medium and the original records must be destroyed.
Network Disruptions Report by Global Network Initiative
The report by Global Network Initiative can be read here.
However S.144 of the Criminal Procedure Code as well Section 5 of the Telegraph Act are still used as legal grounds. The former targets unlawful assembly while the latter gives authorities the right to prevent transmission of messages, applicable to messages sent over the Internet as well. A case in the Gujarat High Court challenging the validity of using S.144 of the CrPC was dismissed essentially stating the Government could use the section to enforce shutdowns to maintain law and order.
The right to Internet has been accepted as a fundamental right by the United Nations and one which, cannot be disassociated from the exercise of freedom of expression and opinion and the right to peaceful assembly. These are rights guaranteed by the Constitution, affirmed in the Universal Declaration of Human Rights and thus should be provided, both, online and offline. Online movements are unpredictable and dynamic making Governments fearful of their lack of control over content hosting websites. Their fear becomes their de facto perception of online services resulting in network shutdowns regardless of the reality on ground.
Given the rising importance of this issue, Global Network Initiative has published a report on such Network Disruptions by Jan Rydzak . A former Google Policy fellow and now a PhD candidate at the University of Arizona, he, conducts research on the nexus between technology and protest. The report, which uses India as a case study calls for more attention on network disruptions, the 'new form of digital repression' and delves into its impact on human rights. Rydzak aims at widening the gambit of affected rights by discussing the civil and political rights of freedom of assembly, right to equality, religious belief and such. These are ramifications not widely discussed so far and helps shine a light on the collateral damage incurred due to these shutdowns. Through a multitude of interviews with various stakeholders, the author brings to forefront the human rights implications of network disruptions on different groups of individuals such as women, immigrants and certain ethnic groups. These dangers are even more when it comes to vulnerable populations and the report does a comprehensive analysis of all of the above.
NITI Aayog Discussion Paper: An aspirational step towards India’s AI policy
The 115-page discussion paper attempts to be an all encompassing document looking at a host of AI related issues including privacy, security, ethics, fairness, transparency and accountability. The paper identifies five focus areas where AI could have a positive impact in India. It also focuses on reskilling as a response to the potential problem of job loss due the future large-scale adoption of AI in the job market. This blog is a follow up to the comments made by CIS on Twitter on the paper and seeks to reflect on the National Strategy as a well researched AI roadmap for India. In doing so, it identifies areas that can be strengthened and built upon.
Identified Focus Areas for AI Intervention
The paper identifies five focus areas—Healthcare, Agriculture, Education, Smart Cities and Infrastructure, Smart Mobility and Transportation, which Niti Aayog believes will benefit most from the use of AI in bringing about social welfare for the people of India. Although these sectors are essential in the development of a nation, the failure to include manufacturing and services sectors is an oversight. Focussing on manufacturing is fundamental not only in terms of economic development and user base, but also regarding questions of safety and the impact of AI on jobs and economic security. The same holds true for the service sector particularly since AI products are being made for the use of consumers, not just businesses. Use of AI in the services sector also raises critical questions about user privacy and ethics. Another sector the paper fails to include is defense, this is worrying since India is chairing the Group of Governmental Experts on Lethal Autonomous Weapons Systems (LAWS) in 2018. Across sectors, the report fails to look at how AI could be utilised to ensure accessibility and inclusion for the disabled. This is surprising, as aid for the differently abled and accessibility technology was one of the 10 domains identified in the Task Force Report on AI published earlier this year. This should have been a focus point in the paper as it aims to identify applications with maximum social impact and inclusion.
In its vision for the use of AI in smart cities, the paper suggests the adoption of a sophisticated surveillance system as well as the use of social media intelligence platforms to check and monitor people’s movement both online and offline to maintain public safety. This is at variance with constitutional standards of due process and criminal law principles of reasonable ground and reasonable suspicion. Further, use of such methods will pose issues of judicial inscrutability. From a rights perspective, state surveillance can directly interfere with fundamental rights including privacy, freedom of expression, and freedom of assembly. Privacy organizations around the world have raised concerns regarding the increased public surveillance through the use of AI. Though the paper recognized the impact on privacy that such uses would have, it failed to set a strong and forward looking position on the issue - such as advocating that such surveillance must be lawful and inline with international human rights norms.
Harnessing the Power of AI and Accelerating Research
One of the ways suggested for the proliferation of AI in India was to increase research, both core and applied, to bring about innovation that can be commercialised. In order to attain this goal the paper proposes a two-tier integrated approach: the establishment of COREs (Centres of Research Excellence in Artificial Intelligence) and ICTAI (International Centre for Transformational Artificial Intelligence). However the roadmap to increase research in AI fails to acknowledge the principles of public funded research such as free and open source software (FOSS), open standards and open data. The report also blames the current Indian Intellectual Property regime for being “unattractive” and averse to incentivising research and adoption of AI. Section 3(k) of Patents Act exempts algorithms from being patented, and the Computer Related Inventions (CRI) Guidelines have faced much controversy over the patentability of mere software without a novel hardware component. The paper provides no concrete answers to the question of whether it should be permissible to patent algorithms, and if yes, to to what extent. Furthermore, there needs to be a standard either in the CRI Guidelines or the Patent Act, that distinguishes between AI algorithms and non-AI algorithms. Additionally, given that there is no historical precedence on the requirement of patent rights to incentivise creation of AI, innovative investment protection mechanisms that have lesser negative externalities, such as compensatory liability regimes would be more desirable. The report further failed to look at the issue holistically and recognize that facilitating rampant patenting can form a barrier to smaller companies from using or developing AI. This is important to be cognizant of given the central role of startups to the AI ecosystem in India and because it can work against the larger goal of inclusion articulated by the report.
Ethics, Privacy, Security and Safety
In a positive step forward, the paper addresses a broader range of ethical issues concerning AI including transparency, fairness, privacy and security and safety in more detail when compared to the earlier report of the Task Force. Yet despite a dedicated section covering these issues, a number of concerns still remain unanswered.
Transparency
The section on transparency and opening the Black Box has several lacunae. First, AI that is used by the government, to an acceptable extent, must be available in the public domain for audit, if not under Free and Open Source Software (FOSS). This should hold true in particular for uses that impinge on fundamental rights. Second, if the AI is utilised in the private sector, there currently exists a right to reverse engineer within the Indian Copyright Act, which is not accounted for in the paper. Furthermore, if the AI was involved both in the commission of a crime or the violation of human rights, or in the investigations of such transgressions, questions with regard to judicial scrutability of the AI remain. In addition to explainability, the source code must be made circumstantially available, since explainable AI alone cannot solve all the problems of transparency. In addition to availability of source code and explainability, a greater discussion is needed about the tradeoff between a complex and potentially more accurate AI system (with more layers and nodes) vs. an AI system which is potentially not as accurate but is able to provide a human readable explanation. It is interesting to note that transparency within human-AI interaction is absent in the paper. Key questions on transparency, such as whether an AI should disclose its identity to a human have not been answered.
Fairness
With regards to fairness, the paper mentions how AI can amplify bias in data and create unfair outcomes. However, the paper neither suggests detailed or satisfactory solutions nor does it deal with biased historical data in an Indian context. More specifically, there seems to be no mention of regulatory tools to tackle the problem of fairness, such as:
- Self-certification
- Certification by a self-regulatory body
- Discrimination impact assessments
- Investigations by the privacy regulator
Such tools will proactively need to ensure inclusion, diversity, and equity in composition and decisions.
Additionally, with reference to correcting bias in AI, it should be noted that the technocratic view that as an AI solution continues to be trained on larger amounts of data , systems will self correct, does not fully recognize the importance of data quality and data curation, and is inconsistent with fundamental rights. Policy objectives of AI innovation must be technologically nuanced and cannot be at the cost of intermediary denial of rights and services.
Further, the paper does not deal with issues of multiple definitions and principles of fairness, and that building definitions into AI systems may often involve choosing one definition over the other. For instance, it can be argued that the set of AI ethical principles articulated by Google are more consequentialist in nature involving a a cost-benefit analysis, whereas a human rights approach may be more deontological in nature. In this regard, there is a need for interdisciplinary research involving computer scientists, statisticians, ethicists and lawyers.
Privacy
Though the paper underscores the importance of privacy and the need for a privacy legislation in India - the paper limits the potential privacy concerns arising from AI to collection, inappropriate use of data, personal discrimination, unfair gain from insights derived from consumer data (the solution being to explain to consumers about the value they as consumers gain from this), and unfair competitive advantage by collecting mass amounts of data (which is not directly related to privacy). In this way the paper fails to discuss the full implications on privacy that AI might have and fails to address the data rights necessary to enable the right to privacy in a society where AI is pervasive. The paper fails to engage with emerging principles from data protection such as right to explanation and right to opt-out of automated processing, which directly relate to AI. Further, there is no discussion on the issues such as data minimisation and purpose limitation which some big data and AI proponents argue against. To that extent, there is a lack of appreciation of the difficult policy questions concerning privacy and AI. The paper is also completely silent on redress and remedy. Further the paper endorses the seven data protection principles postulated by the Justice Srikrishna Committee. However CIS has pointed out that these principles are generic and not specific to data protection. Moreover, the law chapter of IEEE’s ‘Global Initiative on Ethics of Autonomous and Intelligent Systems’ has been ignored in favor of the chapter on ‘Personal Data and Individual Access Control in Ethically Aligned Design’ as the recommended international standard. Ideally, both chapters should be recommended for a holistic approach to the issue of ethics and privacy with respect to AI.
AI Regulation and Sectoral Standards
The discussion paper’s approach towards sectoral regulation advocates collaboration with industry to formulate regulatory frameworks for each sector. However, the paper is silent on the possibility of reviewing existing sectoral regulation to understand if they require amending. We believe that this is an important solution to consider since amending existing regulation and standards often takes less time than formulating and implementing new regulatory frameworks. Furthermore, although the emphasis on awareness in the paper is welcome, it must complement regulation and be driven by all stakeholders, especially given India’s limited regulatory budget. The over reliance on industry self-regulation, by itself, is not advisable, as there is an absence of robust industry governance bodies in India and self-regulation raises questions about the strength and enforceability of such practices. The privacy debate in India has recognized this and reports, like the Report of the Group of Experts on Privacy, recommend a co-regulatory framework with industry developing binding standards that are inline with the national privacy law and that are approved and enforced by the Privacy Commissioner. That said, the UN Guiding Principles on Business and Human Rights and its “protect, respect, and remedy” framework should guide any self regulatory action.
Security and Safety of AI Systems
In terms of security and safety of AI systems the paper seeks to shift the discussion of accountability being primarily about liability, to that of one about the explainability of AI. Furthermore, there is no recommendation of immunities or incentives for whistleblowers or researchers to report on privacy breaches and vulnerabilities. The report also does not recognize certain uses of AI as being more critical than others because of their potential harm to the human. This would include uses in healthcare and autonomous transportation. A key component of accountability in these sectors will be the evolution of appropriate testing and quality assurance standards. Only then, should safe harbours be discussed as an extension of the negligence test for damages caused by AI software. Additionally, the paper fails to recommend kill switches, which should be mandatory for all kinetic AI systems. Finally, there is no mention of mandatory human-in-the-loop in all systems where there are significant risks to safety and human rights. Autonomous AI is only viewed as an economic boost, but its potential risks have not been explored sufficiently. A welcome recommendation would be for all autonomous AI to go through human rights impact assessments.
Research and Education
Being a government think-tank, the NITI Aayog could have dealt in detail with the AI policies of the government and looked at how different arms of the government are aiming to leverage AI and tackle the problems arising out of the use of AI. Instead of tabulating the government’s role in each area and especially research, the report could have also listed out the various areas where each department could play a role in the AI ecosystem through regulation, education, funding research etc. In terms of the recommendations for introducing AI curriculums in schools, and colleges, the government could also ensure that ethics and rights are part of the curriculum - especially in technical institutions. A possible course of action could include corporations paying for a pan-Indian AI education campaign.This would also require the government to formulate the required academic curriculum that is updated to include rights and ethics.
Data Standards and Data Sharing
Based on the amount of data the Government of India collects through its numerous schemes, it has the potential to be the largest aggregator of data specific to India. However the paper does not consider the use of this data with enough gravity. For example, the paper recommends Corporate Data Sharing for “social good” and making government datasets from the social sector available publicly. Yet this section does not mention privacy enhancing technologies/standards such as pseudonymization, anonymization standards, differential privacy etc. Additionally there should be provisions that allow the government to prevent the formation of monopolies by regulating companies from hoarding user data. The open data standards could also be applicable to the private companies, so that they can also share their data in compliance with the privacy enhancing technologies mentioned above. The paper also acknowledges that AI Marketplaces require monitoring and maintenance of quality. It recognises the need for “continuous scrutiny of products, sellers and buyers”, and proposes that the government enable these regulations in a manner that private players could set up the marketplace. This is a welcome suggestion, but the legal and ethical framework of the AI Marketplace requires further discussion and clarification.
An AI Garage for Emerging Economies
The discussion paper also qualifies India as an “ideal test-bed” for trying out AI related solutions. This is problematic since questions of regulation in India with respect to AI have yet to be legally clarified and defined and India does not have a comprehensive privacy law. Without a strong ethical and regulatory framework, the use of new and possibly untested technologies in India could lead to unintended and possibly harmful outcomes.The government's ambition to position India as a leader amongst developing countries on AI related issues should not be achieved by using Indians as test subjects for technologies whose effects are unknown.
Conclusion
In conclusion, NITI Aayog’s discussion paper represents a welcome step towards a comprehensive AI strategy for India. However, the trend of inconspicuously releasing reports (this and the AI Task Force) as well as the lack of a call for public comments, seems to be the wrong way to foster discussion on emerging technologies that will be as pervasive as AI.
The blanket recommendations were provided without looking at its viability in each sector. Furthermore, the discussion paper does not sufficiently explore or, at times, completely omits key areas. It barely touched upon societal, cultural and sectoral challenges to the adoption of AI — research that CIS is currently in the process of undertaking.Future reports on Indian AI strategy should pay more attention to the country’s unique legal context and to possible defense applications and take the opportunity to establish a forward looking, human rights respecting, and holistic position in global discourse and developments. Reports should also consider infrastructure investment as an important prerequisite for AI development and deployment. Digitised data and connectivity as well as more basic infrastructure, such as rural electricity and well-maintained roads, require more funding to more successfully leverage AI for inclusive economic growth. Although there are important concerns, the discussion paper is an aspirational step toward India’s AI strategy.
Why NPCI and Facebook need urgent regulatory attention
The article was published in the Economic Times on June 10, 2018.
As the network effects compound, disruptive acceleration hurtle us towards financial utopia, or dystopia. Our fate depends on what we get right and what we get wrong with the law, code and architecture, and the market.
The Internet, unfortunately, has completely transformed from how it was first architected. From a federated, generative network based on free software and open standards, into a centralised, environment with an increasing dependency on proprietary technologies.
In countries like Myanmar, some citizens misconstrue a single social media website, Facebook, for the internet, according to LirneAsia research. India is another market where Facebook could still get its brand mistaken for access itself by some users coming online. This is Facebook put so many resources into the battle over Basics, in the run-up to India’s network neutrality regulation. an odd corporation.
On hand, its business model is what some term surveillance capitalism. On the other hand, by acquiring WhatsApp and by keeping end-toend (E2E) encryption “on”, it has ensured that one and a half billion users can concretely exercise their right to privacy. At the time of the acquisition, WhatsApp founders believed Facebook’s promise that it would never compromise on their high standards of privacy and security. But 18 months later, Facebook started harvesting data and diluting E2E.
In April this year, my colleague Ayush Rathi and I wrote in Asia Times that WhatsApp no longer deletes multimedia on download but continues to store it on its servers. Theoretically, using the very same mechanism, Facebook could also be retaining encrypted text messages and comprehensive metadata from WhatsApp users indefinitely without making this obvious.
My friend, Srikanth Lakshmanan, founder of the CashlessConsumer collective, is a keen observer of this space. He says in India, “we are seeing an increasing push towards a bank-led model, thanks to National Payments Corporation of India (NPCI) and its control over Unified Payments Interface (UPI), which is also known as the cashless layer of the India Stack.”
NPCI is best understood as a shape shifter. Arundhati Ramanathan puts it best when she says “depending on the time and context, NPCI is a competitor. It is a platform. It is a regulator. It is an industry association. It is a profitable non-profit. It is a rule maker. It is a judge. It is a bystander.”
This results in UPI becoming, what Lakshmanan calls, a NPCI-club-good rather than a new generation digital public good. He also points out that NPCI has an additional challenge of opacity — “it doesn’t provide any metrics on transaction failures, and being a private body, is not subject to proactive or reactive disclosure requirements under the RTI.”
Technically, he says, UPI increases fragility in our financial ecosystem since it “is a centralised data maximisation network where NPCI will always have the superset of data.” Given that NPCI has opted for a bank-led model in India, it is very unlikely that Facebook able to leverage its monopoly the social media market duopoly it shares with in the digital advertising market to become a digital payments monopoly.
However, NCPI and Facebook both share the following traits — one, an insatiable appetite for personal information; two, a fetish for hypercentralisation; three, a marginal commitment to transparency, and four, poor track record as a custodian of consumer trust. The marriage between these like-minded entities has already had a dubious beginning.
Previously, every financial technology wanting direct access to the NPCI infrastructure had to have a tie-up with a bank. But for Facebook and Google, as they are large players, it was decided to introduce a multi-bank model. This was definitely the right thing to do from a competition perspective. But, unfortunately, the marriage between the banks and the internet giant was arranged by NPCI in an opaque process and WhatsApp was exempted from the full NPCI certification process for its beta launch.
Both NPCI and Facebook need urgent regulatory attention. A modern data protection law and a more proactive competition regulator is required for Facebook. The NPCI will hopefully also be subjected to the upcoming data protection law. But it also requires a range of design, policy and governance fixes to ensure greater privacy and security via data minimisation and decentralisation; greater accountability and transparency to the public; separation of powers for better governance and open access policies to prevent anti-competitive behaviour.
Comments on the Draft Digital Communications Policy
Preliminary
On 1st May 2018, the Department of Telecommunications of the Ministry of Communications released the Draft Digital Communications Policy for comments and feedback. We laud the Government’s attempts to realise the socio-economic potential of India by increasing access to Internet, and drafting a comprehensive policy while adequately keeping in mind the various security and privacy concerns that arise due to online communication. On behalf of the Centre for Internet & Society (CIS), we thank the Department of Telecommunications for the opportunity to submit its comments on the draft policy.
We would like to point out two concerns with the consultation process: (i) a character-limit imposed on the comments to each section, due to which this submission has to sacrifice on providing comprehensive references to research; and (ii) issues with signing in on the MyGov where this consultation was hosted. We strongly recommend that the consultation process be liberal in accepting content, and allow for multiple types of submissions.
Comments
Connect India: Creating a Robust Digital Communication Infrastructure
Propel India: Enabling Next Generation Technologies and Services through Investments, Innovation, Indigenous Manufacturing and IPR Generation
On Strategies
2.2 (a) ii. Simplifying licensing and regulatory frameworks whilst ensuring appropriate security frameworks for IoT/ M2M / future services and network elements incorporating international best practices
The process of “simplifying” licensing and regulatory regime is currently vague, and the intentions remain unclear. Simplifying licences without clear intentions can lead to losing the necessary nuance in the license agreements required to maintain competitive markets. In recent months, the industry has already witnessed a dilution of provisions which were placed to ensure healthy competition in the sector. For example, on May 31st, new norms were announced by DoT under which now allow an operator to hold 35% of the total spectrum as opposed to the earlier regulation which only allowed for holding a maximum 25% of the total spectrum.
2.3 (d) (iii) Providing financial incentives for the development of Standard Essential Patents(SEPs) in the field of digital communications technologies
This is a welcome step by the government to incentivise the development of SEPs in the country. However, this appreciable step will only yield results in the long term - and realistically speaking, not before a decade. It is equally necessary to improve the environment of licensing of SEPs in the short-term. The government should take initiative for creation of government-controlled patent pools for SEPs, which will solve issues of licensing for SEP holders, and also improve transparency of information relating to SEPs. Specifically, we recommend that the government initiate the formation of a patent pool of critical mobile technologies and apply a five percent compulsory license.
Secure India: Ensuring Digital Sovereignty, Safety and Security of Digital Communications
On Strategies
3.1 Harmonising communications law and policy with the evolving legal framework and jurisprudence relating to privacy and data protection in India
We welcome the Ministry’s intention to amend licence agreements to include data protection and privacy provisions. In the same vein, the Ministry should also consider removing provisions from licenses that prevent the operator from using certain encryption methods in its network. For example, Clause 2.2 (vii) of the License Agreement between DoT & ISP prohibits bulk encryption. Additionally, in the License Agreement, encryption with only up to 40-bit in RSA (or equivalent) is normally permitted. Similarly, Clause 37.1 of the Unified Service License Agreement prohibits bulk encryption. These provisions must be revised to ensure that ISPs and other service providers can employ more cryptographically secure methods.
When regulating on encryption, we recommend that the government only set positive minimum mandates for the storage and transmission of data, and not set upper limits on the number of bits or on the quality of cryptographical method. In pursuance of the same goals, we also recommend adding point ‘iii’ to 3.1 (b): “promoting the use of encryption in private communication by providing positive minimum mandates for strong encryption in (or along with) the data protection framework.”
3.2 (a) Recognising the need to uphold the core principles of net neutrality
Like other goals of the draft policy, the target for ensuring and enforcing net neutrality principles has been set as 2022. However, this goal is achievable by as early as December 2018. We suggest that the Government take the first step towards this goal by accepting the net neutrality principles proposed by the TRAI and its recommendations to the government which have been pending with the Ministry since November 2017. The government may additionally take into consideration CIS’ position on net neutrality.
The vaguely worded “appropriate exclusions and exceptions” carved out to net-neutrality principles in the policy need urgent elaboration. Given the vague boundaries between different control layers in digital communication, content regulation is very easy to slip into, and needs to be consciously avoided by the government.
3.3 (f) ii. Facilitating lawful interception agencies with state of the art lawful intercept and analysis systems for implementation of law and order and national security
There is no clarity in policy on how the government plans to meet the goal of “[f]acilitating lawful interception agencies with state of the art lawful intercept and analysis systems for implementation of law and order and national security.” It has been recently suggested that some legal provisions that enable targeted communication surveillance might be violative of the privacy guidelines laid out in the recent Supreme Court judgment that affirmed the Right to Privacy. Additionally, mass surveillance, prime facie, does not meet the “proportionality test.” Therefore, the policy documents needs details as to how the Ministry will aid intelligence agencies, and whether these interception details will be known to ISPs, TSPs and the public via reflection in the various License Agreements.
Comments on the Telecom Commercial Communications Customer Preference Regulations
Preliminary
This submission presents comments by the Centre for Internet & Society (“CIS”), India on ‘The Telecom Commercial Communications Customer Preference Regulations, 2018’ which were released on 29th May 2018 for comments and counter-comments.
CIS appreciates the intent and efforts of Telecom Regulatory Authority of India (TRAI) to curb the problem of Unsolicited Commercial Communication (UCC), or spam. Spam messages are constant irritants for telecom subscribers. Acknowledging the same, TRAI has proposed regulations which aim to empower subscribers in effectively dealing with UCC. CIS is grateful for the opportunity to put forth its views and comments on the regulations. This submission was made on 18th June 2018. This text has been slightly edited for readability.
The first part of the submission highlights some general issues with the regulations. While TRAI has offered a technological solution to the menace of UCC, the policy documents have no accompanying technical details. TRAI has not made a compelling case for why Distributed Ledger Technologies (DLTs) should be used for storing data instead of a distributed database. There is no clarity on the technical aspects of the proposed DLTs: the participating nodes in the network, how these nodes arrive at a consensus, whether they are independent of each other, are questions that remain unanswered. The draft regulations also mention curbing Robocalls, but technical challenges associated with the same have not been discussed. Spam which is non-commercial in nature remains out of the scope of the current regulations.
The second part of this submission puts forth specific comments related to various sections of the draft and suggests improvements therein. While CIS appreciates the extension of the deadline from 11th June to 18th June, we would like to highlight that the Draft was released on 29th May, and despite the extension, the time to submit comments remains less than a month. Considering the fact that the draft regulations hold significance for the entire telecom industry and nearly 1.5 billion subscribers, TRAI should have granted at least a month’s time for the stakeholder’s sound scrutiny.
General Comments
Distributed Ledger Technology (DLT)
The draft greatly emphasizes the fact that data regarding Consent, Complaints, Headers, Preferences, Content Template Register and Entities are stored on distributed ledgers. The intent is to keep data cryptographically secure with no centralized point of control. However, the regulations do not go into the technical details of the working of these distributed ledgers leading to several potential pitfalls.
As per the draft, every access provider has to establish distributed ledgers for Complaints, Consent, Content, Preference, Header, Entities and so on. There are specific entities mentioned which will act as nodes in the network, and these nodes are preselected.
Whenever a sender seeks to send commercial communications across a list of subscribers, the list is ‘scrubbed’ against the DL-Consent and DL-Preference, to check whether the subscriber has given consent and registered their preference. The sender can only send the commercial communication to the numbers which are present in the scrubbed list.
The objective of these regulations is to protect consumers’ rights but the consumer, i.e., the subscriber, is not a node in the distributed ledger. Since the primary benefits of decentralization are gained when the trust is devolved to the individual subscribers, and the individual users are not specified as participating nodes in the ledger, the justification behind a distributed ledger is unclear.
Additionally, the proposed regime requires the subscriber to place her trust in the access provider to register the complaint, thus offers no tangible benefit over the current regulation. While there are penalties for non-compliant Access Providers (APs), there are no business incentives for APs to expend the extra amount of resources required in for effective implementation of this technology, to act in the users’ interest. This builds a system where APs interests clash with subscribers, but they are nonetheless required to be the guardian of the subscribers’ concerns.
Further, the nodes are entities constituted by the access providers (APs), and there is no mechanism to ensure that they behave independently of each other. In such case, it is wholly possible that all nodes on a distributed ledger are run by the same entity, thus defeating the purpose of establishing consensus. The proposed regulations do not address this scenario.
One solution would be to add subscribers as nodes to the DLT network. But this would be impractical as the technical challenges associated therein, including generating public-private key pairs of each user, the computational complexity of the network, are immense. If this is indeed the intention of TRAI, this has not been spelled out clearly in the draft regulations. Additionally, in such a scenario, there would be no requirement for mandating every AP to maintain their own DLT for customer preference and consent artifacts.
Considering the points mentioned above, we request TRAI to publish the technical specifications of DLTs, which addresses the following issues:
- Who can participate in the network other than the entities mentioned in the regulations? Are these participating entities independent of each other? If not, then how will the conflict of interest be resolved?
- What is the consensus algorithm used in the DLTs?
- Will the code to implement DLTs be open-source?
Our recommendations are three-fold in this regard:
If distributed ledger is used, then, mechanisms should be devised to ensure the integrity of the consensus. For this, participating nodes in the network must be independent of each other. Aforementioned points regarding consensus protocol should be taken into consideration as well.
In place of DLTs, we recommend the use of a distributed database with signature-based authentication and encryption of the data to be stored. The immutability and non-repudiation of data can be achieved in this way. Distributed ledgers such as DL-consent, DL-preference, DL-complaints are instances where authentication of data and subscriber can be done using simplers means such as OTP verification, etc. So, such ledgers need not necessarily utilize DLTs.
The regulations should mandate the open-source publication of the implementation of the DLTs. This will enable interoperability, add transparency to the functioning of the regulations, and enable security audits to ensure accountability of the APs.
Broadening the scope of the Regulations to non-commercial communication
The proposed regulations attempt to specifically curb unsolicited commercial communications as defined in Regulation 2(bt). But, there are other forms of communication which are unsolicited and non-commercial, including political messages and market surveys.
We recommend that the scope of the regulations should be broadened to include both commercial and non-commercial communications. And both of these should be grouped under the category of Institutional Communications. Wherever needed, changes should be made to the regulations dealing with UCC to suit the specific requirements of dealing with unsolicited non-commercial communications as well. At the same time, the regulations should ensure that individual communications are not brought within their ambit.
Technical challenges in combating Robocalls
Robocalls are defined in Regulation 2(ba) and in Schedule IV, provision 3, it has been clubbed with other kinds of spam. However, there are some specific technical challenges in regulating robocalls. Right now, ‘block listing’ is a prevalent model where one can identify a number and then block it so that it cannot be used further. But with robocalls, spoofing of other numbers is easily achievable which makes the blocking of the real identity of caller difficult. The proposed regulations do not adequately address this challenge.
The Alliance for Telecommunications Industry Solutions, with working groups of the Internet Engineering Task Force (IETF), has been working on a different approach to solve this problem. They are working on standards for all mobile and VoIP calling services which would enable them to do cryptographic digital call signing, “so calls can be validated as originating from a legitimate source, and not a spoofed robocall system. The protocols, known as ‘STIR’ and ‘SHAKEN,’ are in industry testing right now through ATIS's Robocalling Testbed, which has been used by companies like Sprint, AT&T, Google, Comcast, and Verizon so far”.
TRAI should take into account these developments and propose a specific regime accordingly. One possible way forward, for now, could be the banning of robocalls unless there is explicit opt-in by subscribers.
Registration of content-template
The draft envisages a distributed ledger system for registration of content template which would have both a fixed part and a variable part. The content template needs to be registered by the content template registrar, which would be an authorized entity.
Problematically, the content template is defined to include the fixed part as well as the variable part. Further, Schedule I, provision 4(3)(e) mandates that content template registration functions should be utilized to extract fixed and the variable portion from actual messages offered for delivery or already delivered. The variable portion of the message contains information specific to a customer, as defined in regulation 2(q)(ii). In addition to privacy concerns with accessing the variable part, there is no functional reason for variable portions to be extracted from the actual message, as only the fixed portion needs to be verified.
The hash of the fixed portion of the message can be used to identify whether a user has received UCC or not. We, therefore, recommend that the variable portion of the message shall not be made accessible to entities because it is not required for the identification of a message as UCC.
‘Safe and Secure Manner’
Throughout the draft, reference is made to the data collected being stored and/or exchanged in a ‘safe and secure manner’, without any clarification as to what this term implies.
We recommend that the term be defined as ‘measures in accordance with reasonable security practices and procedures’ as given in section 43A of the Information Technology Act, 2008 read with section 8 of the Information Technology (Reasonable security practices and procedures and sensitive personal data or information) Rules, 2011.
Bulk Registration
In India, evidence suggests that major victims of spam are the elderly and people with limited financial capacities. In such cases, consent and preference registration on behalf of these people by one person may help in the successful control of UCC.
Some telecom service providers argued against this by emphasizing the individual choice of a subscriber. However, in cases where there is authorization given by the customer, the primary user can register consent on his/her behalf. Similarly, since corporate connections are by definition owned and paid for by corporates, bulk registration in those situations can be also be done.
We recommend that given the situation in India, the provision for bulk registration be incorporated in the regulations for specific scenarios, as mentioned above. An authorization template giving the nominee power to register on behalf of a class can be incorporated to this effect. Also, an opt-out option must be incorporated in case an individual choice differs from the choice registered in the bulk-registration.
Specific Comments
Inferred Consent [Regulation 2(k)(II)(A)]
Comments
Regulation 2(k)(ii)(a) of the Draft defines consent as “voluntary permission given by the customer to the sender to receive commercial communication”. However, the draft also includes, “inferred consent”, which is defined as consent that can be “reasonably inferred from the customer’s conduct or the business and the relationship between the individual and the sender”.
When consent is derived from the customer’s conduct, rather than being given explicitly, it defeats its ‘voluntary nature’. The provision of consent being ‘reasonably inferred’ from the customer’s conduct is also vague, and there is no indication given in the draft as to what kind of conduct would lead to a reasonable inference of implied consent. The definition can also be interpreted to mean that customer’s conduct will be subject to monitoring, which raises privacy concerns.
Recommendations
Consent shall not be derived from the customer’s conduct unless the person provides it explicitly. We recommend amendment to the definition of ‘inferred consent’ accordingly.
Three years history to be stored in DL-Complaints [Regulations 24(3) and 24(4)]
Regulation 24(3) and (4) states that the DL-Ledger for Complaints (DL-Complaints) shall record ‘three years history’ of both the complainant and the sender, with details of complaints made, date, time and status of the resolution of the complaint. It is not clear from the regulation whether the mentioned set of data is exhaustive or not.
Recommendations
We recognize that the legislative intent behind drafting Regulation 24(3) and (4) was to curb frivolous or false complaints, which has already been a concern of TRAI. Storing both the complainant and the sender’s history, in such cases, may aid in resolving these.
The responsibility of the APs to ensure that the devices support the requisite permissions [Regulation 34]
Comments
Regulation 34 mandates that the APs are to ensure that the devices “registered in the network” shall support the requisite permissions of the Apps under this regulations.
In terms of jurisdiction, regulation of the functioning of electronic devices (which can be phones, tablets or smart watches) is outside the scope of the proposed regulations, and probably out of TRAI's regulatory competence.
Even if TRAI can impose the regulation on end devices, this regulation puts the burden on the APs to ensure that devices support the pertinent app permissions. Considering that TRAI itself has been weighing legal recourse against device manufacturers on similar grounds, it is unclear why TRAI assumes that APs have any legal or technical method to ensure control of a device which has neither been manufactured by them nor is it under their physical or remote control.
In modern smartphones, the end-user has full control over most app installations and permissions. This practice is consistent with a consumer's autonomy over the device and its functioning. Considering the fact that TRAI has not implemented basic security features in the 'Do Not Disturb' app, TRAI is putting at risk the privacy of millions of device owners by legally mandating permissions for an app with the second proviso. The proviso further gives TRAI the power to order APs to derecognize devices from their network. This regulation is draconic and inimical to the rights of consumers, who are at risk of losing network access and connectivity because of their device choice, which is a completely different business and market.
Recommendations
Reporting unsolicited messages or calls is a consumer right, and the regulations are in furtherance of the same goals. TRAI should enable consumer rights by giving subscribers the option to report spam and has no reason to force users to report spam possibly through legal overreach and privacy invasion. Accordingly, we recommend the removal of Regulation 34.
Additional Suggestions
Consumer and subscriber
The usage of the terms ‘customer’ and ‘subscriber’ in Regulation 3(1) implies that the terms have two different meanings. This interpretation, however, clashes with the actual definition given in Regulation 2(u) and 2(bk), whereby a customer is a subscriber. This is an inconsistent interpretation.
Either the definition of a ‘customer’ must be clarified or differentiated from that of a ‘subscriber’ in regulation 2, or regulation 3 must be amended to indicate what its actual object of regulation is - the customer or the subscriber.
Drafting misnumbering
There are a few instances of misnumbering of regulations and reference regulations which are non-existent.
Regulations 25(5)(b) and (c) make a reference to regulation 25(3)(a), which does not exist in the given draft. A bare reading of regulation 25, however, indicate that the intention was to refer to regulation 25(5)(a), and as such, this misnumbering should be rectified.
Regulation 34 makes a reference to regulation 7(2), which again, does not exist. In such case, either regulation 34 or regulation 7(2) must be amended to keep a consistent interpretation.
Ambiguous terms
‘Allocation and assignment principles and policies’ - Provision 4(1)(a) of Schedule I of the regulations indicate that header assignment should be done on the basis of ‘allocation and assignment principles and policies’, without any clarification to the meaning of this term. We recommend an amendment to this provision accordingly.
The AI Task Force Report - The first steps towards India’s AI framework
The blog post was edited by Swagam Dasgupta. Download PDF here
The Task Force’s Report, released on March 21st 2018, is a result of the combined expertise of members from different sectors and examines how AI will benefit India. It sheds light on the Task Force’s perception of AI, the sectors in which AI can be leveraged in India, the challenges endemic to India and certain ethical considerations. It concludes with a set of policy recommendations for the government to leverage AI for the next five years. While acknowledging AI as a social and economic problem solver, the Report attempts to answer three policy questions:
- What are the areas where government should play a role?
- How can AI improve quality of life and solve problems at scale for Indian citizens?
- What are the sectors that can generate employment and growth by the use of AI technology?
This blog will look at how the Task Force answered these three policy questions. In doing so, it gives an overview of salient aspects and reflects on the strengths and weaknesses of the Report.
Sectors of Relevance and Challenges
In order to navigate the outlined questions, the Report looks at ten sectors that it refers to as ‘domains of relevance to India’. Furthermore, it examines the use of AI along with its major challenges, and possible solutions for each sector. These sectors include: Manufacturing, FinTech, Agriculture, Healthcare, Technology for the Differently-abled, National Security, Environment, Public Utility Services, Retail and Customer Relationship, and Education. While these ten domains are part of the 16 domains of focus listed in the AITF’s web page, it would have been useful to know the basis on which these sectors were identified. A particular strength of the identified sectors is the consideration of technology for the differently abled as well as the recognition to the development of AI systems in spoken and sign languages in the Indian context.
Some of the problems endemic to India that were recognized include infrastructural barriers, managing scale and innovation, and the collection, validation and distribution of data. The Task Force also noted the lack of consumer awareness, and inability of technology providers to explain benefits to end users as further challenges. The Task Force — by putting the onus on the individual — seems to hint that the impediment to the uptake of technology is the inability of individuals to understand the benefits of the technology, rather than aspects such as poor design, opacity, or misuse of data and insights. Furthermore, although the Report recognizes the challenges associated to data in India and highlights the importance of quality and quantity of data; it overlooks the importance of data curation in creatinge reliable AI systems.
Although the Report examines challenges to AI in each sector, it fails to include all challenges that require addressal. For example, the report fails to acknowledge challenges such as the lack of appropriate certification systems for AI driven health systems and technologies. In the manufacturing sector, the Report fails to highlight contextual challenges associated with the use of AI. This includes the deployment of autonomous vehicles compared to the use of industrial robots.
On the use of AI in retail, the Report while examining consumer data and its respective regulatory policies, identified the issues to be related to the definition, discrimination, data breaches, digital products and safety awareness and reporting standards. In this, the Report is limited in its understanding of what categories of data can lead to discrimination and restricts mechanisms for transparency and accountability to data breaches. The Report could have also been more forward looking in its position on security — including security by design and security by default. Furthermore, these issues were noted only in the context of the retail sector and ideally should have been discussed across all sectors.
The challenges for utilizing AI for national security could have been examined beyond cost and capacity to include associated ethical and legal challenges such as the need for legal backing. The use of AI in national security demands clear accountability and oversight as it is a ground for legitimate state interference with fundamental rights such as privacy and freedom of expression. As such, there is a need for human rights impact assessments, as well as a need for such uses to be aligned with international human rights norms. Government initiatives that allow country wide surveillance and AI decisions based on such data should ideally be implemented only after a comprehensive privacy law is in place and India’s surveillance regime has been revisited.
Recognizing the potential of AI for the benefit of the differently abled is one of the key takeaways from this section of the Report. Furthermore, it also brings in the need for AI inclusivity. AI in natural language generation and translation systems have the potential to help the large number of youth that are disabled or deprived. Therefore, AI could have a large positive impact through inclusive growth and empowerment.
Although the Report examines each of the ten domains in an attempt to provide an insight into the role the government can play, there seems to be a lack of clarity in terms of the role that each department will and is playing with respect to AI. Even the section which lays down the relevant ministries for each of the ten domains failed to include key ministries and departments. For example, the Report does not identify the Ministry of Education, nor does it list the Ministry of Law for national security. The Report could have also identified government departments which would be responsible for regulation and standardization. This could include the Medical Council of India (healthcare), CII (manufacture and retail), RBI (Fintech) etc. The Report also does not recognize other developments around AI emerging out the government. For example, the Draft National Digital Communications Policy (published on May 1, 2018) seeks to empower the Department of Telecommunication to provide a roadmap for AI and robotics. Along similar lines, the Department of Defence Production has also created a task force earlier this year to study the use of AI to accelerate military technology and economic growth. The government should look at building a cohesive AI government body, or clearly delineating the role of each ministry, in order to ensure harmonization going forward.
Areas in need of Government Intervention
The Report also lists out the grand challenges where government intervention is required. This includes data collection and management and the need for widespread expertise contributing to research, innovation, and response. However, while highlighting the need for AI experts from diverse backgrounds, it fails to include experts from law and policy into the discussion. While identifying manufacturing, agriculture, healthcare and public utility to be places where government intervention is needed, the Report failed to examine national security beyond an important domain to India and as a sector where government intervention is needed.
Participation in International Forums
Another relevant concern that the Report underscores is India’s scarce participation as researchers, AI developers and government engagement in global discussions around AI. The Report states that although efforts were being made by Indian universities to increase their presence in international AI conferences, they were lagging behind other nations. On the subject of participation by the government it recommends regular presence in International AI policy forums. Hence, emphasising the need for India’s active participation in global conversations around AI and international rulemaking.
Key Enablers to AI
The Report while analysing the key enablers for AI deployment in India states that positive societal attitudes will be the driving force behind the proliferation of AI. Although relying on positive social attitudes alone will not help in increasing the trust on AI, steps such as making algorithms that are used by public bodies public, enacting a data protection law etc. will be important in enabling trust beyond highlighting success stories.
Data and Data Marketplaces
While the Report identifies data as a challenge where government intervention is needed, it also points to the Aadhaar ecosystem as an enabler. It states that Aadhaar will help in the proliferation of AI in three ways: one as a creator of jobs as related to the collection and digitization of data, two as a collector of reliable data, and three as a repository of Indian data. However, since the very constitutionality of Aadhaar is yet to be determined by the Supreme Court, the task force should have used caution in identifying Aadhaar as a definitive solution. Especially while making statements that the Aadhaar along with the SC judgement has created adequate frameworks to protect consumer data. Additionally, the Task Force should have recognized the various concerns that have been voiced about Aadhaar, particularly in the context of the case before the Supreme Court.
This section also proposes the creation of a Digital Data Marketplace. A data marketplace needs to be framed carefully so as to not create a situation where privacy becomes a right available to only those who can afford it. It is concerning that the discussion on data protection and privacy in the Report is limited to policies and guidelines for businesses and not centered around the individual.
Innovation and Patents
The Report states that the Indian startups working in the field of AI must be encouraged, and industry collaborations and funding must be taken up as a policy measure. One of the ways in which this could be achieved is by encouraging innovations, and one of the ways to do so is by adding a commercial incentive to it, such as through IP rights. Although the Report calls for a stronger IP regime that protects and incentivises innovation, it remains ambiguous as to which aspect of IP rights — patents, trade secrets and copyrights — need significant changes. If the Report is specifically advocating for stronger patent rights in order to match those of China and US, then it shows that the the task force fails to understand the finer aspects of Indian patent law and the history behind India’s stance on patenting. This includes the fact that Indian patent law excludes algorithms from being patented. Indian patent law, by providing a higher threshold for patenting computer related inventions (CRIs), ensures that only truly innovative patents are granted. Given the controversies over CRIs that have dotted the Indian patent landscape, the task force would have done well to provide more clarity on the ‘how’ and ‘why’ of patenting in this sector, if that is their intent with this suggestion.
Ethical AI framework
Responsible AI
In terms of establishing an ethical AI framework, the Task Force suggests measures such as making AI explainable, transparent, and auditable for biases. The Report addresses the fact that currently with the increase in human and AI interaction there is a need to have new standards set for the deployment of AI as well as industrial standards for robots. However, the Report does not go into details of how AI could cause further bias based on various identifiers such as gender and caste, as well as the myriad concerns around privacy and security. This is especially a concern given that the Report envisions widespread use of AI in all major sectors. In this way, the Report looks at data as both a challenge and an enabler, but fails to dedicate time towards explaining the various ethical considerations behind the collection and use of data in the context of privacy, security and surveillance as well as account for unintended consequences. In laying out the ethical considerations associated with AI, the report does not make a distinction between the use of AI by the public sector and private sector. As the government is responsible for ensuring the rights of citizens and holds more power than the citizenry, the public sector needs to be more accountable in their use of AI. This is especially so in cases where AI is proposed to be used for sovereign functions such as national security.
Privacy and Data
The Report also recognises the significance of the implementation of the Aadhaar Act, the privacy judgement and the proposed data protection laws, on the development and use of AI for India. Yet, the Report does not seem to recognize the importance of a robust and multi-faceted privacy framework as it assumes that the Aadhaar Act and the Supreme Court Judgement on privacy and potential privacy law have already created a basis for safe and secure utilization and sharing of customer data. Although the Report has tried to be an expansive examination of various aspects of AI for India, it unfortunately has not looked in depth at the current issues and debates around AI privacy and ethics and makes policy recommendations without appearing to fully reflect on the implementation and potential impact of the same. Similar to the discussion paper by the Niti Aayog, this Report does not consider the emerging principles of data protection such as right to explanation and right to opt-out of automated processing, which directly relate to AI. Furthermore, there is a lack of discussion on issues such as data minimisation and purpose limitation which some big data and AI proponents argue against.
Liability
On the question of liability, the Report only states that specific liability mechanisms need to be worked out for certain categories of machines. The Report does not address the questions of liability that should be applicable to all AI systems, and on whom the duty of care lies, not only in case of robots but also in the case of automated decision making etc. Thus, there is a need for further thinking on mechanisms for determining liability and how these could apply to different types of AI (deep learning models and other machine learning models) and AI systems.
AI and Employment
On the topic of jobs and employment, the Report states that AI will create more jobs than it takes as a result of an increase in the number of companies and avenues created by AI technologies. Additionally, the Report provides examples of jobs where AI could replace the human (autonomous drivers, industrial robots etc,) but does not go as far as envisioning what jobs could be created directly from this replacement. Though the Report recognizes emerging forms of work such as crowdsourcing platforms like Mturk, it fails to examine the impact of such models of work on workers and traditional labour market structures and processes. Going forward, it will be important that the government and the private sector undertake the necessary steps to ensure that fair, protected, and fulfilling jobs are created simultaneously with the adoption of AI. This will include revisiting national and organizational skilling programmes, labor laws, social benefit schemes, relevant economic policies, and exploring best practices with respect to the adoption and integration of AI in work.
Education and Re-skilling
The task force emphasised the need for a change in the education curriculum as well as the need to reskill the labour force to ensure an AI ready future. This level of reskilling will be a massive effort, and a thorough review and audit of existing skilling programmes in India is needed before new skilling programmes are established and financed. The Report also clarifies that the statistics used were based on a study on the IT component of the industry, and that a similar study was required to analyse AI’s effect on the automation component. Going forward, there is the need for a comprehensive study of the labour intensive sectors and formal and informal sectors to develop evidence based policy responses.
Policy Recommendations
The Task Force, in its policy recommendations, notes that the successful adoption of AI in India will depend on three factors: people, process and technology. However, it does not explain these three factors any further.
National Artificial Intelligence Mission
The most significant suggestion made in the Report is for the establishment of the National Artificial Intelligence Mission (N-AIM) — a centralised nodal agency for coordinating and facilitating research, collaboration and providing economic impetuous to AI startups. The mission with a budget allocation of Rs 1,200 crore over five years aims, among other things, to look at various ways to encourage AI research and deployment. Some of the suggestions include targeting and prototyping AI systems and setting up of a generic AI test bed. These suggestions seems to draw inspiration from other countries such as the US DARPA Challenge and Japan’s sandbox for self driving trucks. The establishment of N-AIM is a welcome step to encourage both AI research and development on a national scale. The availability of public funds will encourage more AI research and development.Additionally, government engagement in AI projects has thus far been fragmentedand a centralised body will presumably bring about better coordination and harmonization. Some of the initiatives such as Capture the flag competition that seeks to centre around the provision for real datasets to catalyze innovation will need to be implemented with appropriate safeguards in place.
Other recommendations
There are other suggestions that are problematic — particularly that of funding “an inter-disciplinary large data integration center in pilot mode to develop an autonomous AI Machine that can work on multiple data streams in real time and provide relevant information and predictions to public across all domains.” Before such a project is developed and implemented there are a number of factors where legal clarity is required; a few being: data collection and use, accuracy and quality of the AI system. There is also a need to ensure that bias and discrimination have been accounted for and fairness, responsibility and liability have been defined with consideration that this will be a government driven AI system. Additionally, such systems should be transparent by design and should include redress mechanisms for potential harms that may arise. This can be through the presence of a human in the loop, or the existence of a kill switch. These should be addressed through ethical principles, standards, and regulatory frameworks.
The recommendations propose establishing operation standards for data storage and privacy, communication standards for autonomous systems, and standards to allow for interoperability between AI based systems. A significant lacuna in this list is the development of safety, accuracy, and quality standards for AI algorithms and systems.
Similarly, although the proposed public private partnership model for research and startups is a good idea, this initiative should be undertaken only after questions such as the implications of liability, ownership of IP and data, and the exclusion of critical sectors are thought through.
Furthermore, the suggestion to ‘fund a national level survey on identification of cluster of clean annotated data necessary for building effective AI systems’ needs to recognize the existing initiatives around open data or use this as a starting place. The Report does not clarify if this survey would involve identifying data.
Conclusion
The inconspicuous release of the Report as well as the lack of a call for public comments results in the fact that the Report does not incorporate or reflect on the sentiments of the public or draw upon the expertise that exists in India on the topic or policies around emerging technologies, which will have a pervasive and wide effect on society. The need for multi stakeholder engagement and input cannot be understated. Nonetheless, the Report of the Task Force is a welcome step towards understanding the movement towards an definitive AI policy. The task force has attempted answering the three policy questions keeping people, process and technology in mind. However, it could have provided greater details about these indices. The Report, which is meant for a wider audience, would have done well to provide greater detail, while also providing clarity on technical terms. On a definitional plane, a list of technologies that the task force perceived as AI for this Report, could have also helped keep it grounded on possible and plausible 5 year recommendations.
Compared to the recent Niti Aayog Discussion Paper, this Report misses out on a detailed explanation on AI and ethics, however, it does spend some considerable amount of time on education and the use of AI for the differently abled. Additionally, the Report’s statement on the democratization of development and equal access as well as assigning ownership and framing transparent rules for usage of the infrastructure is a positive step towards making AI inclusive. Overall, the Report is a progressive step towards laying down India’s path forward in the field of Artificial Intelligence. The emphasis on India’s involvement in International rulemaking gives India an opportunity to be a leader of best practice in international forums by adopting forward looking and human rights respecting practices. Whether India will also become a strong contender in the AI race, with policies favouring the development of a socio-economically beneficial, and ethical-AI backed industries and services is yet to be seen.
The Task Force consists of 18 members in total. Of these, 11 members are from the field of AI technology both research and industry, three from the civil services, one from healthcare research, one with and Intellectual property law background, and two from a finance background. The specializations of the members are not limited to one area as the members have experience or education in various areas relevant to AI. https://www.aitf.org.in// There is a notable lack of members from Civil Society. It may also be noted that only 2 of the 18 members are women
The Report on the Artificial Intelligence Task Force, Pg. 1,http://dipp.nic.in/sites/default/files/Report_of_Task_Force_on_ArtificialIntelligence_20March2018_2.pdf
The Artificial Intelligence Task Force https://www.aitf.org.in/
The Report on the Artificial Intelligence Task Force, Pg. 8
The Report on the Artificial Intelligence Task Force, Pg. 9,10.
The Report on the Artificial Intelligence Task Force, Pg. 9
Artificial Intelligence in the Healthcare Industry in India https://cis-india.org/internet-governance/files/ai-and-healtchare-report
Artificial Intelligence in the Manufacturing and Services Sector https://cis-india.org/internet-governance/files/AIManufacturingandServices_Report _02.pdf
The Report on the Artificial Intelligence Task Force, Pg. 21.
Submission to the Committee of Experts on a Data Protection Framework for India, Centre for Internet and Society https://cis-india.org/internet-governance/files/data-protection-submission
The Report on the Artificial Intelligence Task Force, Pg. 22
Draft National Digital Communications Policy-2018, http://www.dot.gov.in/relatedlinks/draft-national-digital-communications-policy-2018
Task force set up to study AI application in military,https://indianexpress.com/article/technology/tech-news-technology/task-force-set-up-to-study-ai-application-in-military-5049568/
It is not just technical experts that are needed, ethical, technical, and legal experts as well as domain experts need to be part of the decision making process.
The Report on the Artificial Intelligence Task Force, Pg. 31
Constitutional validity of Aadhaar: the arguments in Supreme Court so far, http://www.thehindu.com/news/national/constitutional-validity-of-aadhaar-the-arguments-in-supreme-court-so-far/article22752084.ece
CIS Submission to TRAI Consultation on Free Data http://trai.gov.in/Comments_FreeData/Companies_n_Organizations/Center_For_Internet_and_Society.pdf
The Report on the Artificial Intelligence Task Force, Pg. 30
Section 3(k) of the patent act describes that a mere mathematical or business method or a computer programme or algorithm cannot be patented.
Patent Office Reboots CRI Guidelines Yet Again: Removes “novel hardware” Requirement
https://spicyip.com/2017/07/patent-office-reboots-cri-guidelines-yet-again-removes-novel-hardware-requirement.html
The Report on the Artificial Intelligence Task Force, Pg. 37
The Report on the Artificial Intelligence Task Force, Pg. 7
The Report on the Artificial Intelligence Task Force, Pg. 8
National Strategy for Artificial Intelligence: http://niti.gov.in/writereaddata/files/document_publication/NationalStrategy-for-AI-Discussion-Paper.pdf
Meaningful information and the right to explanation,Andrew D Selbst Julia Powles, International Data Privacy Law, Volume 7, Issue 4, 1 November 2017, Pages 233–242
The Principle of Purpose Limitation and Big Data, https://www.researchgate.net/publication/319467399_The_Principle_of_Purpose_Limitation_and_Big_Data
For example a lesser threshold of minimum wages, no job secuirity etc, https://blogs.scientificamerican.com/guilty-planet/httpblogsscientificamericancomguilty-planet20110707the-pros-cons-of-amazon-mechanical-turk-for-scientific-surveys/
The Report on the Artificial Intelligence Task Force, Pg. 41
Report of Artificial Intelligence Task Force Pg, 46, 47
The DARPAChallenge https://www.darpa.mil/program/darpa-robotics-challenge
Japan may set regulatory sandboxes to test drones and self driving vehicles http://techwireasia.com/2017/10/japan-may-set-regulatory-sandboxes-test-drones-self-driving-vehicles/
Mariana Mazzucato in her 2013 book The Entrepreneurial State, argued that it was the government that drives technological innovation. In her book she stated that high-risk discovery and development were made possible by government spending, which the private enterprises capitalised once the difficult work was done.
https://tech.economictimes.indiatimes.com/news/technology/govt-of-karnataka-launches-centre-of-excellence-for-data-science-and-artificial-intelligence/61689977,https://analyticsindiamag.com/amaravati-world-centre-for-ai-data/
The Report on the Artificial Intelligence Task Force, Pg. 47
Report of Artificial Intelligence Task Force Pg. 49
The Report on the Artificial Intelligence Task Force, Pg. 47
The AI task force website has a provision for public comments although it is only for the vision and mission and the domains mentioned in the website.
National Strategy for Artificial Intelligence: http://niti.gov.in/writereaddata/files/document_publication/NationalStrategy-for-AI-Discussion-Paper.pdf
CIS contributes to the Research and Advisory Group of the Global Commission on the Stability of Cyberspace (GCSC)
Chaired by Marina Kaljurand, and Co-Chaired by Michael Chertoff and Latha Reddy, the Commission comprises 26 prominent Commissioners who are experts hailing from a wide range of geographic regions representing multiple communities including academia industry, government, technical and civil society.
As a part of their efforts, the GCSC sent out a call for proposals for papers that sought to analyze and advance various aspects of the cyber norms debate.
Elonnai Hickok and Arindrajit Basu’s paper ‘ Conceptualizing an International Security Architecture for Cyberspace’ was selected by the Commissioners and published as a part of the Briefings of the Research and Advisory Group.
Arindrajit Basu represented CIS at the Cyberstability Hearings held by the GCSC at the sidelines of the GLOBSEC forum in Bratislava-a multilateral conference seeking to advance dialogue on various issues of international peace and security.
The published paper and the Power Point may be accessed here.
The agenda for the hearings is reproduced below
GCSC HEARINGS, 19 MAY 2018
HEARINGS: TOWARDS INTERNATIONAL CYBERSTABILITY
Venue: “Habsburg” room, Grand Hotel River Park 15:00-15:15
Welcome Remarks by Marina Kaljurand, Chair of the Global Commission on the Stability of Cyberspace (GCSC) and former Foreign Minister of Estonia 15:15-16:45
Hearing I: Expert Hearing
This session focuses on the topic Cyberstability and the International Peace and Security Architecture and includes scene settings, food-for-thought presentations on the new GCSC commissioned research, briefings and open statements by government and nongovernmental speakers.
“Scene setting: ”Cyber Diplomacy in Transition” by Carl Bildt, former Prime Minister of Sweden
“Commissioned Research I: Lessons learned from three historical case studies on establishing international norms” by Arindrajit Basu, Centre for Internet and Society, India
Commission Research II: The “pre-normative” framework and options for cyber diplomacy” by Elana Broitman, New America Foundation
“Some Remarks on current thinking within the United Nations”, by Renata Dwan, Director United Nations Institute for Disarmament Research (UNIDIR) (Registered Statements by Government Advisors) (Statements by other experts)
(Open floor discussion) 16:45-17:15
Coffee Break
ICANN Diversity Analysis
The by-laws of The Internet Corporation for Assigned Names and Numbers (ICANN) state that it is a non-profit public-benefit corporation which is responsible at the overall level, for the coordination of the “global internet's systems of unique identifiers, and in particular to ensure the stable and secure operation of the internet's unique identifier systems”.[1]Previously, this was overseen by the Internet Assigned Number Authority (IANA) under a US Government contract but in 2016, the oversight was handed over to ICANN, as a global multi-stakeholder body.[2] Given the significance of the multistakeholder nature of ICANN, it is imperative that stakeholders continue to question and improve the inclusiveness of its processes. The current blog post seeks to focus on the diversity of participation at the ICANN process.
As stakeholders are spread across the world, much of the communication discussing the work of ICANN takes place over email. Various [or X number of ] mailing lists inform members of ICANN activities and are used for discussions between them from policy advice to organizational building matters. Many of these lists are public and hence can be subscribed to by anyone and also can be viewed by non-members through the archives.
CIS analysed the five most active mailing lists amongst the working group mailing lists from January 2016 to May 2018, namely:
- Outreach & Engagement,
- Technology,
- At-Large Review 2015 - 2019,
- IANA Transition & ICANN Accountability, and
- Finance & Budget mailing lists.
We looked at the diversity among these active participants by focusing on their gender, stakeholder grouping and region. In order to arrive at the data, we referred to public records such as the Statement of Interests which members have to give to the Generic Names Supporting Organization(GNSO) Council if they want to participate in their working groups. We also used, where available, ICANN Wiki and the LinkedIn profiles of these participants. Given below are some of the observations we made subsequent to surveying the data. We acknowledge that there might be some inadvertent errors made in the categorization of these participants, but are of the opinion that our inference from the data would not be drastically affected by a few errors.
The following findings were observed:
- A total of 218 participants were present on the 5 mailing lists that were looked at.
- Of these,, 92 were determined to be active participants (participants who had sent more than the median number of mails in their working group) out of which 75 were non-staff members.
Among the active non-staff participants:
- Out of the 75 participants, 56 (74.7%) were male and 19 (25.3%) were female.


- 57.3% were identified to be members of the industry and technological community and 1.3% were identified as government representatives. 8.0% were representatives from Academia, 25.3% represented civil society and the remaining 8.0% were from fields that were uncategorizable with respect to the above, but were related to law and consultancy.

- Only 14.7% of the participants were from Asia while the majority belonged to Africa and then North America with 24% and 22.7% participation respectively
- Within Asia, we identified only one active participant from China.
Concerns
- The vast number of the people participating and as an extension, influencing ICANN work are male constituting three fourth of the participants.
- The mailing list are dominated by individuals from industry.. This coupled with the relative minority presence of the other stakeholders creates an environment where concerns emanating from other sections of the society could be overshadowed.
- Only 14.7% of the participants were from Asia, which is concerning since 48.7% of internet users worldwide belong to Asia.[3]
- China which has the world’s largest population of internet users (700 million people)[4] had only one active participant on these mailing lists.
ICANN being a global multistakeholder organization should ideally have the number of representatives from each region be proportionate to the number of internet users in that region. In addition to this, participation of women on these mailing lists need to increase to ensure that there is inclusive contribution in the functioning of the organization. We did not come across any indication of participation of individuals of non binary genders.
[1] https://cis-india.org/telecom/knowledge-repository-on-internet-access/icann
[2] https://www.icann.org/news/announcement-2016-10-01-en
[3] https://www.internetworldstats.com/stats.htm
[4] https://www.internetworldstats.com/stats3.htm
CIS submitted a response to a Notice of Enquiry by the US Government on International Internet Policy Priorities
The notice was based on different areas and we commented on the following three areas; The Free Flow of Information and Jurisdiction, The Multi-stakeholder Approach to Internet Governance, Privacy and Security. The submission was made by Swagam Dasgupta and Akriti Bopanna. Read the submission here.
The submission broadly covered the following aspects:
The Free Flow of Information and Jurisdiction
- What are the challenges to the free flow of information online?
- Which foreign laws and policies restrict the free flow of information online? What is the impact on U.S companies and users in general?
- Have courts in other countries issued internet-related judgments that apply national laws to the global internet? What have the effects been on users?
- What are the challenges to freedom of expression online?
- What should be the role of all stakeholders globally—governments, companies, technical experts, civil society and end users — in ensuring free expression online?
- What role can NTIA play in helping to reduce restrictions on the free flow of information over the internet and ensuring free expression online?
- In which international organizations or venues might NTIA most effectively advocate for the free flow of information and freedom of expression? What specific actions should NTIA and the U.S. Government take?
Multistakeholder Approach to Internet Governance
- Does the multistakeholder approach continue to support an environment for the internet to grow and thrive? If so, why? If not, why not?
- Are there public policy areas in which the multistakeholder approach works best? If yes, what are those areas and why? Are there areas in which the multistakeholder approach does not work effectively? If there are, what are those areas and why?
- Should the IANA Stewardship Transition be unwound? If yes, why and how? If not, why not?
- What should be NTIA’s priorities within ICANN and the GAC?
- Are there barriers to engagement at the IGF? If so, how can we lower these barriers?
- Are there improvements that can be made to the IGF’s structure?
Privacy and Security
- In what ways are cybersecurity threats harming international commerce? In what ways are the responses to those threats harming international commerce?
DIDP #31 Diversity of employees at ICANN
This data is being requested to verify ICANN’s claim of being an equal opportunities employer. ICANN’s employee handbook states that they “...provide equal opportunities and are committed to the principle of equality regardless of race, colour, ethnic or national origin, religious belief, political opinion or affiliation, sex, marital status, sexual orientation, gender reassignment, age or disability.” The data on the diversity of employees based on race and nationality of their employees will depict how much they have stuck to their commitment to delivering equal opportunities to personnel in ICANN and potential employees.
The request filed by CIS can be accessed here
The Centre for Internet and Society’s Comments and Recommendations to the: Indian Privacy Code, 2018
Click to download the file here
As India moves towards greater digitization, and technology becomes even more pervasive, there is a need to ensure the privacy of the individual as well as hold the private and public sector accountable for the use of personal data. Towards enabling public discourse and furthering the development a privacy framework for India, a group of lawyers and policy analysts backed by the Internet Freedom Foundation (IFF) have put together a draft a citizen's bill encompassing a citizen centric privacy code that is based on seven guiding principles.[1] This draft builds on the Citizens Privacy Bill, 2013 that had been drafted by CIS on the basis of a series of roundtables conducted in India.[2] Privacy is one of the key areas of research at CIS and we welcome this initiative and hope that our comments make the Act a stronger embodiment of the right to privacy.
Section by Section Recommendations
Preamble
Comment: The Preamble specifies that the need for privacy has increased in the digital age, with the emergence of big data analytics.
Recommendation: It could instead be worded as ‘with the emergence of technologies such as big data analytics’, so as to recognize the impact of multiple technologies and processes including big data analytics.
Comment: The Preamble states that it is necessary for good governance that all interceptions of communication and surveillance be conducted in a systematic and transparent manner subservient to the rule of law.
Recommendation: The word ‘systematic’ is out of place, and can be interpreted incorrectly. It could instead be replaced with words such as ‘necessary’, ‘proportionate’, ‘specific’, and ‘narrow’, which would be more appropriate in this context.
Chapter 1
Preliminary
Section 2: This Section defines the terms used in the Act.
Comment: Some of the terms are incomplete and a few of the terms used in the Act have not been included in the list of definitions.
Recommendations:
- The term “effective consent” needs to be defined. The term is first used in the Proviso to Section 7(2), which states “Provided that effective consent can only be said to have been obtained where...:”It is crucial that the Act defines effective consent especially when it is with respect to sensitive data.
- The term “open data” needs to be defined. The term is first used in Section 5 that states the exemptions to the right to privacy. Subsection 1 clause ii states as follows “the collection, storage, processing or dissemination by a natural person of personal data for a strictly non-commercial purposes which may be classified as open data by the Privacy Commission”. Hence the term open data needs to be defined in order to ensure that there is no ambiguity in terms of what open data means.
- The Act does not define “erasure”, although the term erasure does come under the definition of destroy (Section 2(1)(p)). There are some provisions that use the word erasure , hence if erasure and destruction mean different acts then the term erasure needs to be defined, otherwise in order to maintain uniformity the sections where erasure is used could be substituted with the term “destroy” as defined under this Act.
- The definition of “sensitive personal data” does not include location data and identification numbers. The definition of sensitive data must include location data as the Act also deals in depth with surveillance. With respect to identification numbers, the Act needs to consider identification numbers (eg. the Aadhaar number, PAN number etc.) as sensitive information as this number is linked to a person's identity and can reveal sensitive personal data such as name, age, location, biometrics etc. Example can be taken from Section 4(1) of the GDPR[3] which identifies location data as well as identification numbers as sensitive personal data along with other identifies such as biometric data, gender race etc.
- The Act defines consent as the “unambiguous indication of a data subject’s agreement” however, the definition does not indicate that there needs to be an informed consent. Hence the revised definition could read as follows “the informed and unambiguous indication of a data subject’s agreement”. It is also unclear how this definition of consent relates to ‘effective consent’. This relationship needs to be clarified.
- The Act defines ‘data controller’ in Section 2(1)(l) as “ any person including appropriate government..”. In order to remove any ambiguity over the definition of the term person, the definition could specify that the term person means any natural or legal person.
- The Act defines ‘data processor’ in Section (2(1)(m) as “means any person including appropriate government”. In order to remove any ambiguity over the definition of the term ‘any person’, the definition could specify that the term person means any natural or legal person.
CHAPTER II
Right to Privacy
Section 5: This section provides exemption to the rights to privacy.
Comment: Section 5(1)(ii) states that the collection, storage, processing or dissemination by a natural person of personal data for a strictly non-commercial purposes are exempted from the provisions of the right to privacy. This clause also states that this data may be classified as open data by the Privacy Commission. This section hence provides individuals the immunity from collection, storage, processing and dissemination of data of another person. However this provision fails to state what specific activities qualify as non commercial use.
Recommendation: This provision could potentially be strengthened by specifying that the use must be in the public interest. The other issue with this subsection is that it fails to define open data. If open data was to be examined using its common definition i.e “data that can be freely used, modified, and shared by anyone for any purpose”[4] then this section becomes highly problematic. As a simple interpretation would mean that any personal data that is collected, stored, processed or disseminated by a natural person can possibly become available to anyone. Beyond this, India has an existing framework governing open data. Ideally the privacy commissioner could work closely with government departments to ensure that open data practices in India are in compliance with the privacy law.
CHAPTER III
Protection of Personal Data
PART A
Notice by data controller
Section 6: This section specifies the obligations to be followed by data controllers in their communication, to maintain transparency and lays down provisions that all communications by Data Controllers need to be complied with.
Comment: There seems to be a error in the Proviso to this section. The proviso states “Provided that all communications by the Data Controllers including but not limited to the rights of Data Subjects under this part shall may be refused when the Data Controller is, unable to identify or has a well founded basis for reasonable doubts as to the identity of the Data Subject or are manifestly unfounded, excessive and repetitive, with respect to the information sought by the Data Subject ”.
Recommendation: The proviso could read as follows “The proviso states “Provided that all communications by the Data Controllers including but not limited to the rights of Data Subjects under this part may be refused when the Data Controller is…”. We suggest the use of the ‘may’ as this makes the provision less limiting to the rights of the data controller.
Additionally, it is not completely clear what ‘included but not limited to...’ would entail. This could be clarified further.
PART B
CONSENT OF DATA SUBJECTS
Section 10: This section talks about the collection of personal data.
Comment: Section 10(3) lays down the information that a person must provide before collecting the personal data of an individual.
Comment: Section 10(3)(xi) states as follows “the time and manner in which it will be destroyed, or the criteria used to Personal data collected in pursuance of a grant of consent by the data subject to whom it pertains shall, if that consent is subsequently withdrawn for any reason, be destroyed forthwith: determine that time period;”. There seems to be a problem with the sentence construction and the rather complex sentence is difficult to understand.
Recommendation: This section could be reworked in such as way that two conditions are clear, one - the time and manner in which the data will be destroyed and two the status of the data once consent is withdrawn.
Comment: Section 10(3)(xiii) states that the identity and contact details of the data controller and data processor must be provided. However it fails to state that the data controller should provide more details with regard to the process for grievance redressal. It does not provide guidance on what type of information needs to go into this notice and the process of redressal. This could lead to very broad disclosures about the existence of redress mechanisms without providing individuals an effective avenue to pursue.
Recommendation: As part of the requirement for providing the procedure for redress, data controllers could specifically be required to provide the details of the Privacy Officers, privacy commissioner, as well as provide more information on the redressal mechanisms and the process necessary to follow.
Section 11:This section lays out the provisions where collection of personal data without prior consent is possible.
Comment: Section 11 states “Personal data may be collected or received from a third party by a Data Controller the prior consent of the data subject only if it is:..”. However as the title of the section suggests the sentence could indicate the situations where it is permissible to collect personal data without prior consent from the data subject”. Hence the word “without” is missing from the sentence. Additionally the sentence could state that the personal data may be collected or received directly from an individual or from a third party as it is possible to directly collect personal data from an individual without consent.
Recommendation:The sentence could read as “Personal data may be collected or received from an individual or a third party by a Data Controller without the prior consent of the data subject only if it is:..”.
Comment: Section 11(1)(i) states that the collection of personal data without prior consent when it is “necessary for the provision of an emergency medical service or essential services”. However it does not specify the kind or severity of the medical emergency.
Recommendation: In addition to medical emergency another exception could be made for imminent threats to life.
Section 12: This section details the Special provisions in respect of data collected prior to the commencement of this Act.
Comment: This section states that all data collected, processed and stored by data controllers and data processors prior to the date on which this Act comes into force shall be destroyed within a period of two years from the date on which this Act comes into force. Unless consent is obtained afresh within two years or that the personal data has been anonymised in such a manner to make re-identification of the data subject absolutely impossible. However this process can be highly difficult and impractical in terms of it being time consuming, expensive particularly, in cases of analog collections of data. This is especially problematic in cases where the controller cannot seek consent of the data subject due to change in address or inavailability or death. This will also be problematic in cases of digitized government records.
Recommendation: We suggest three ways in which the issue of data collected prior to the Act can be handled. One way is to make a distinction on the data based on whether the data controller has specified the purpose of the collection before collecting the data. If the purpose was not defined then the data can be deleted or anonymised. Hence there is no need to collect the data afresh for all the cases. The purpose of the data can also be intimated to the data subject at a later stage and the data subject can choose if they would like the controller to store or process the data.The second way is by seeking consent afresh only for the sensitive data. Lastly, the data controller could be permitted to retain records of data, but must necessarily obtain fresh consent before using them. By not having a blanket provision of retrospective data deletion the Act can address situations where deletion is complicated or might have a potential negative impact by allowing storage, deletion, or anonymisation of data based on its purpose and kind.
Comment: Section (2)(1)(i) of the Act states that the data will not be destroyed provided that effective consent is obtained afresh within two years. However as stated earlier the Act does not define effective consent.
Recommendation: The term effective consent needs to be defined in order to bring clarity to this provision.
PART C
FURTHER LIMITATIONS ON DATA CONTROLLERS
Section 16: This section deals with the security of personal data and duty of confidentiality.
Comment: Section 16(2) states “ Any person who collects, receives, stores, processes or otherwise handles any personal data shall be subject to a duty of confidentiality and secrecy in respect of it.” Similarly Section 16(3) states “data controllers and data processors shall be subject to a duty of confidentiality and secrecy in respect of personal data in their possession or control. However apart from the duty of confidentiality and secrecy the data collectors and processors could also have a duty to maintain the security of the data.” Though it is important for confidentiality and secrecy to be maintained, ensuring security requires adequate and effective technical controls to be in place.
Recommendation: This section could also emphasise on the duty of the data controllers to ensure the security of the data. The breach notification could include details about data that is impacted by a breach or attach as well as the technical details of the infrastructure compromised.
Section 17: This section details the conditions for the transfer of personal data outside the territory of India.
Comment: Section 17 allows a transfer of personal data outside the territory of India in 3 situations- If the Central Government issues a notification deciding that the country/international organization in question can ensure an adequate level of protection, compatible with privacy principles contained in this Act; if the transfer is pursuant to an agreement which binds the recipient of the data to similar or stronger conditions in relation to handling the data; or if there are appropriate legal instruments and safeguards in place, to the satisfaction of the data controller. However, there is no clarification for what would constitute ‘adequate’ or ‘appropriate’ protection, and it does not account for situations in which the Government has not yet notified a country/organisation as ensuring adequate protection. In comparison, the GDPR, in Chapter V[5], contains factors that must be considered when determining adequacy of protection, including relevant legislation and data protection rules, the existence of independent supervisory authorities, and international commitments or obligations of the country/organization. Additionally, the GDPR allows data transfer even in the absence of the determination of such protection in certain instances, including the use of standard data protection clauses, that have been adopted or approved by the Commission; legally binding instruments between public authorities; approved code of conduct, etc. Additionally, it allows derogations from these measures in certain situations: when the data subject expressly agrees, despite being informed of the risks; or if the transfer is necessary for conclusion of contract between data subject and controller, or controller and third party in the interest of data subject; or if the transfer is necessary for reasons of public interest, etc. No such circumstances are accounted for in Section 17.
Recommendation: Additionally, data controllers and processors could be provided with a period to allow them to align their policies towards the new legislation. Making these provisions operational as soon as the Act is commenced might put the controllers or processors guilty of involuntary breaching the provisions of the Act.
Section 19: This section states the special provisions for sensitive personal data.
Comment: Section 19(2) states that in addition to the requirements set out under sub-clause (1), the Privacy Commission shall set out additional protections in respect of:i.sensitive personal data relating to data subjects who are minors; ii.biometric and deoxyribonucleic acid data; and iii.financial and credit data.This however creates additional categories of sensitive data apart from the ones that have already been created.[6] These additional categories can result in confusion and errors.
Recommendation: Sensitive data must not be further categorised as this can lead to confusion and errors. Hence all sensitive data could be subject to the same level of protection.
Section 20: This section states the special provisions for data impact assessment.
Comment: This section states that all data impact assessment reports will be submitted periodically to the State Privacy commission. This section does not make provisions for instances of circumstances in which such records may be made public. Additionally the data impact assessment could also include a human rights impact assessment.
Recommendation: The section could also have provisions for making the records of the impact assessment or relevant parts of the assessment public. This will ensure that the data controllers / processors are subjected to a standard of accountability and transparency. Additionally as privacy is linked to human rights the data impact assessment could also include a human rights impact assessment. The Act could further clarify the process for submission to State Privacy Commissions and potential access by the Central Privacy Commission to provide clarity in process.
Section 20 requires controllers who use new technology to assess the risks to the data protection rights that occur from processing. ‘New technology’ is defined to include pre-existing technology that is used anew. Additionally, the reports are required to be sent to the State Privacy Commission periodically. However, there is no clarification on the situations in which such an assessment becomes necessary, or whether all technology must undergo such an assessment before their use. Additionally, the differentiation between different data processing activities based on whether the data processing is incidental or a part of the functioning needs to be clarified. This differentiation is necessary as there are some data processors and controllers who need the data to function; for instance an ecommerce site would require your name and address to deliver the goods, although these sites do not process the data to make decisions. This can be compared to a credit rating agency that is using the data to make decisions as to who will be given a loan based on their creditworthiness. Example can taken from the GDPR, which in Article 35, specifies instances in which a data impact assessment is necessary: where a new technology, that is likely to result in a high risk to the rights of persons, is used; where personal aspects related to natural persons are processed automatically, including profiling; where processing of special categories of data (including data revealing ethnic/racial origin, sexual orientation etc), biometric/genetic data; where data relating to criminal convictions is processed; and with data concerning the monitoring of publicly accessible areas. Additionally, there is no requirement to publish the report, or send it to the supervising authority, but the controller is required to review the processor’s operations to ensure its compliance with the assessment report.
Recommendation: The reports could be sent to a central authority, which according to this Act is the Privacy Commission, along with the State Privacy Commission. Additionally there needs to be a differentiation between the incidental and express use of data. The data processors must be given at least a period of one year after the commencement of the Act to present their impact assessment report. This period is required for the processors to align themselves with the provisions of the Act as well as conduct capacity building initiatives.
PART C
RIGHTS OF A DATA SUBJECT
Section 21: This section explains the right of the data subject with regard to accessing her data. It states that the data subject has the right to obtain from the data controller information as to whether any personal data concerning her is collected or processed. The data controller also has to not only provide access to such information but also the personal data that has been collected or processed.
Comment: This section does not provide the data subject the right to seek information about security breaches.
Recommendation: This section could state that the data subject has the right to seek information about any security breaches that might have compromised her data (through theft, loss, leaks etc.). This could also include steps taken by the data controller to address the immediate breach as well as steps to minimise the occurrence of such breaches in the future.[7]
CHAPTER IV
INTERCEPTION AND SURVEILLANCE
Section 28: This section lists out the special provisions for competent organizations.
Comment: Section 28(1) states ”all provisions of Chapter III shall apply to personal data collected, processed, stored, transferred or disclosed by competent organizations unless when done as per the provisions under this chapter ”.This does not make provisions for other categories of data such as sensitive data.
Recommendation: This section needs to include not just personal data but also sensitive data, in order to ensure that all types of data are protected under this Act.
Section 30: This section states the provisions for prior authorisation by the appropriate Surveillance and Interception Review Tribunal.
Comment: Section 30(5) states “any interception involving the infringement of the privacy of individuals who are not the subject of the intended interception, or where communications relate to medical, journalistic, parliamentary or legally privileged material may be involved, shall satisfy additional conditions including the provision of specific prior justification in writing to the Office for Surveillance Reform of the Privacy Commission as to the necessity for the interception and the safeguards providing for minimizing the material intercepted to the greatest extent possible and the destruction of all such material that is not strictly necessary to the purpose of the interception.” This section needs to state why these categories of communication are more sensitive than others. Additionally, interceptions typically target people and not topics of communication - thus medical may be part of a conversation between two construction workers and a doctor will communicate about finances.
Recommendation: The section could instead of singling out “medical, journalistic, parliamentary or legally privileged material” state that “any interception involving the infringement of the privacy of individuals who are not the subject of the intended interception may be involved, shall satisfy additional conditions including the provision of specific prior justification in writing to the Office for Surveillance Reform of the Privacy Commission.
Section 37: This section details the bar against surveillance.
Comment: Section 37(1) states that “no person shall order or carry out, or cause or assist the ordering or carrying out of, any surveillance of another person”. The section also prohibits indiscriminate monitoring, or mass surveillance, unless it is necessary and proportionate to the stated purpose. However, it is unclear whether this prohibits surveillance by a resident of their own residential property, which is allowed in Section 5, as the same could also fall within ‘indiscriminate monitoring/mass surveillance’. For instance, in the case of a camera installed in a residential property, which is outward facing, and therefore captures footage of the road/public space.
Recommendation: The Act needs to bring more clarity with regard to surveillance especially with respect to CCTV cameras that are installed in private places, but record public spaces such as public roads. The Act could have provisions that clearly define the use of CCTV cameras in order to ensure that cameras installed in private spaces are not used for carrying out mass surveillance. Further, the Act could address the use of emerging techniques and technology such as facial recognition technologies, that often rely on publicly available data.
CHAPTER V
THE PRIVACY COMMISSION
Section 53: This section details the powers and functions of the Privacy Commission.
Comment: Section 53(2)(xiv) states that the Privacy Commission shall publish periodic reports “providing description of performance, findings, conclusions or recommendations of any or all of the functions assigned to the Privacy Commission”. However this Section does not make provisions for such reporting to happen annually and to make them publicly available, as well as contain details including financial aspects of matters contained within the Act.
Recommendation: The functions could include a duty to disclose the information regarding the functioning and financial aspects of matters contained within the Act. Categories that could be included in such reports include: the number of data controllers, number of data processors, number of breaches detected and mitigated etc.
CHAPTER IX
OFFENCES AND PENALTIES
Sections 73 to 80: These sections lay out the different punishments for controlling and processing data in contravention to the provisions of this Act.
Comment: These sections, while laying out different punishments for controlling and processing data in contravention to the provisions of this Act, mets out a fine extending upto Rs. 10 crore. This is problematic as it does not base these penalties on the finer aspects of proportionality, such as offences that are not as serious as the others.
Recommendation: There could be a graded approach to the penalties based on the degree of severity of the offence.This could be in the form of name and shame, warnings and penalties that can be graded based on the degree of the offence.
----------------------------------------------------------------------
Additional thoughts: As India moves to a digital future there is a need for laws to be in place to ensure that individual's rights are not violated. By riding on the push to digitization, and emerging technologies such as AI, a strong all encompassing privacy legislation can allow India to leapfrog and use these emerging technologies for the benefit of the citizens without violating their privacy. A robust legislation can also ensure a level playing field for data driven enterprises within a framework of openness, fairness, accountability and transparency.
[1] These seven principles include: Right to Access, Right to Rectification, Right to Erasure And Destruction of Personal Data,Right to Restriction Of Processing, Right to Object, Right to Portability of Personal Data,Right to Seek Exemption from Automated Decision-Making.
[2]The Privacy (Protection) Bill 2013: A Citizen’s Draft, Bhairav Acharya, Centre for Internet & Society, https://cis-india.org/internet-governance/blog/privacy-protection-bill-2013-citizens-draft
[3]General Data Protection Regulation, available at https://gdpr-info.eu/art-4-gdpr/.
[4] Antonio Vetro, Open Data Quality Measurement Framework: Definition and Application to Open Government Data, available at https://www.sciencedirect.com/science/article/pii/S0740624X16300132
[5] General Data Protection Regulation, available at https://gdpr-info.eu/chapter-5/.
[6] Sensitive personal data under Section 2(bb) includes, biometric data; deoxyribonucleic acid data;
sexual preferences and practices;medical history and health information;political affiliation;
membership of a political, cultural, social organisations including but not limited to a trade union as defined under Section 2(h) of the Trade Union Act, 1926;ethnicity, religion, race or caste; and
financial and credit information, including financial history and transactions.
[7] Submission to the Committee of Experts on a Data Protection Framework for India, Amber Sinha, Centre for Internet & Society, available at https://cis-india.org/internet-governance/files/data-protection-submission
The Potential for the Normative Regulation of Cyberspace: Implications for India
The standards of international law combined with strategic considerations drive a nation's approach to any norms formulation process. CIS has already produced work with the Research and Advisory Group (RAG) of the Global Commission on the Stability of Cyberspace (GCSC), which looks at the negotiation processes and strategies that various players may adopt as they drive the cyber norms agenda.
This report focuses more extensively on the substantive law and principles at play and looks closely at what the global state of the debate means for India
With the cyber norms formulation efforts in a state of flux,India needs to advocate a coherent position that is in sync with the standards of international law while also furthering India's strategic agenda as a key player in the international arena.
This report seeks to draw on the works of scholars and practitioners, both in the field of cybersecurity and International Law to articulate a set of coherent positions on the four issues identified in this report. It also attempts to incorporate, where possible, state practice on thorny issues of International Law. The amount of state practice that may be cited differs with each state in question.
The report provides a bird’s eye-view of the available literature and applicable International Law in each of the briefs and identifies areas for further research, which would be useful for the norms process and in particular for policy-makers in India.Historically, India had used the standards of International Law to inform it's positions on various global regimes-such as UNCLOS and legitimize its position as a leader of alliances such as the Non-Aligned Movement and AALCO. However, of late, India has used international law far less in its approach to International Relations. This Report therefore explores how various debates on international law may be utilised by policy-makers when framing their position on various issues. Rather than creating original academic content,the aim of this report is to inform policy-makers and academics of the discourse on cyber norms.In order to make it easier to follow, each Brief is followed by a short summary highlighting the key aspects discussed in order to allow the reader to access the portion of the brief that he/she feels would be of most relevance. It does not advocate for specific stances but highlights the considerations that should be borne in mind when framing a stance.
The report focuses on four issues which may be of specific relevance for Indian policy-makers. The first brief, focuses on the Inherent Right of Self-Defense in cyberspace and its value for crafting a stable cyber deterrence regime. The second brief looks at the technical limits of attributability of cyber-attacks and hints at some of the legal and political solutions to these technical hurdles. The third brief looks at the non-proliferation of cyber weapons and the existing global governance framework which india could consider when framing its own strategy. The final brief looks at the legal regime on counter-measures and outlines the various grey zones in legal scholarship in this field. It also maps possible future areas of cooperation with the cyber sector on issues such as Active Cyber Defense and the legal framework that might be required if such cooperation were to become a reality.Each brief covers a broad array of literature and jurisprudence and attempts to explore various debates that exist both among international legal academics and the strategic community.
The ongoing global stalemate over cyber norms casts a grim shadow over the future of cyber-security. However, as seen with the emergence of the nuclear non-proliferation regime, it is not impossible for consensus to emerge in times of global tension. For India, in particular, this stalemate presents an opportunity to pick up the pieces and carve a leadership position for itself as a key norm entrepreneur in cyberspace.
Lining up the data on the Srikrishna Privacy Draft Bill
The article was published in Economic Times on July 30, 2018
Non-consensual processing is permitted in the bill as long it is “necessary for any function of the” Parliament or any state legislature. These functions need not be authorised by law.
Or alternatively “necessary for any function of the state authorised by law” for the provision of a service or benefit, issuance of any certification, licence or permit.
Fortunately, however, the state remains bound by the eight obligations in chapter two i.e., fair and reasonable processing, purpose limitation, collection limitation, lawful processing, notice and data quality and data storage limitations and accountability. This ground in the GDPR has two sub-clauses: one, the task passes the public interest test and two, the loophole like the Indian bill that possibly includes all interactions the state has with all persons.
The “necessary” test appears both on the grounds for non-consensual processing, and in the “collection limitation” obligation in chapter two of the bill. For sensitive personal data, the test is raised to “strictly necessary”. But the difference is not clarified and the word “necessary” is used in multiple senses.
Under the “collection limitation” obligation the bill says “necessary for the purposes of processing” which indicates a connection to the “purpose limitation” obligation. The “purpose limitation” obligation, however, only requires the state to have a purpose that is “clear, specific and lawful” and processing limited to the “specific purpose” and “any other incidental purpose that the data principal would reasonably expect the personal data to be used for”. It is perhaps important at this point to note that the phrase “data minimisation” does not appear anywhere in the bill.
Therefore “necessary” could broadly understood to mean data Parliament or the state legislature requires to perform some function unauthorised by law, and data the citizen might reasonably expect a state authority to consider incidental to the provision of a service or benefit, issuance of a certificate, licence or permit.
Or alternatively more conservatively understood to mean data without which it would be impossible for Parliament and state legislature to carry out functions mandated by the law, and data without it would be impossible for the state to provide the specific service or benefit or issue certificates, licences and permits. It is completely unclear like with the GDPR why an additional test of “strictly necessary” is — if you will forgive the redundancy — necessary.
After 10 years of Aadhaar, the average citizen “reasonably expects” the state to ask for biometric data to provide subsidised grain. But it is not impossible to provide subsidised grain in a corruption-free manner without using surveillance technology that can be used to remotely, covertly and non-consensually identify persons. Smart cards, for example, implement privacy by design. Therefore a “reasonable expectation” test is not inappropriate since this is not a question about changing social mores.
When it comes to persons that are not law abiding the bill has two exceptions — “security of the state” and “prevention, detection, investigation and prosecution of contraventions of law”. Here the “necessary” test is combined with the “proportionate” test.
The proportionate test further constrains processing. For example, GPS data may be necessary for detecting someone has jumped a traffic signal but it might not be a proportionate response for a minor violation. Along with the requirement for “procedure established by law”, this is indeed a well carved out exception if the “necessary” test is interpreted conservatively. The only points of concern here is that the infringement of a fundamental right for minor offences and also the “prevention” of offences which implies processing of personal data of innocent persons.
Ideally consent should be introduced for law-abiding citizens even if it is merely tokenism because you cannot revoke consent if you have not granted it in the first place. Or alternatively, a less protective option would be to admit that all egovernance in India will be based on surveillance, therefore “necessary” should be conservatively defined and the “proportionate” test should be introduced as an additional safeguard.
Spreading unhappiness equally around
The article was published in Business Standard on July 31, 2018.
There is a joke in policy-making circles — you know you have reached a good compromise if all the relevant stakeholders are equally unhappy. By that measure, the B N Srikrishna committee has done a commendable job since there are many with complaints.
Some in the private sector are unhappy because their demonisation of the European Union’s General Data Protection Regulation (GDPR) has failed. The committee’s draft data protection Bill is closely modelled upon the GDPR in terms of rights, principles, design of the regulator and the design of the regulatory tools like impact assessments. With 4 per cent of global turnover as maximum fine, there is a clear signal that privacy infringements by transnational corporations will be reigned in by the regulator. Getting a law that has copied many elements of the European regulation is good news for us because the GDPR is recognised by leading human rights organisations as the global gold standard. But the bad news for us is that the Bill also has unnecessarily broad data localisation mandates for the private sector.
Some in the fintech sector are unhappy because the committee rejected the suggestion that privacy be regulated as a property right. This is a positive from the human rights perspective, especially because this approach has been rejected across the globe, including the European Union. Property rights are inappropriate because a natural law framing of the enclosure of the commons into private property through labour does not translate to personal data. Also in comparison to patents — or “intellectual property” — the scale of possible discreet property holdings in personal information is several orders higher, posing unimaginable complexity for regulation, possibly creating a gridlock economy.
The section of civil society opposed to Aadhaar is unhappy because the UIDAI and all other state agencies that wish to can process data non-consensually. A similar loophole exists in the GDPR. Remember the definition of processing includes “operations such as collection, recording, organisation, structuring, storage, adaptation, alteration, retrieval, use, alignment or combination, indexing, disclosure by transmission, dissemination or otherwise making available, restriction, erasure or destruction”. This means the UIDAI can collect data from you without your consent and does not have to establish consent for the data it has collected in the past. There is a “necessary” test which is supposed to constrain data collection. But for the last 10 odd years, the UIDAI has deemed it “necessary” to collect biometrics to give the poor subsidised grain. Will those forms of disproportionate non-consensual data collection continue? Most probably because the report recommends that the UIDAI continue to play the role of the regulator with heightened powers. Which is like trusting the fox with
the henhouse.
Employees should be unhappy because the Bill has an expansive ground under which employers can nonconsensually harvest their data. The Bill allows for non-consensual processing of any data “necessary” for recruitment, termination, providing any benefit or service, verifying the attendance or any other activity related to the assessment of the performance”. This is permitted when consent is not an appropriate basis or would involve disproportionate effort on the part of the employer. This is basically a surveillance provision for employers. Either this ground should be removed like in the GDPR or a “proportionate” test should also be introduced otherwise disproportionate mechanisms like spyware on work computers will be installed by employees without providing notice.
Some free speech activists are unhappy because the law contains a “right to be forgotten” provision. They are concerned that this will be used by the rich and powerful to censor mainstream and alternative media. On the face of the “right to be forgotten” in the GDPR is a much more expansive “right to erasure”, whilst the Bill only provides for a more limited "right to restrict or prevent continuing disclosure”. However, the GDPR has a clear exception for “archiving purposes in the public interest, scientific or historical research purposes or statistical purposes”. The Bill like the GDPR does identify the two competing human rights imperatives — freedom of expression and the right to information. However, by missing the “public interest” test it does not sufficiently social power asymmetries.
Privacy and security researchers are unhappy because re-identification has been made an offence without a public interest or research exception. It is indeed a positive that the committee has made re-identification a criminal offence. This is because the de-identification standards notified by the regulator would always be catching up with the latest mathematical development. However, in order to protect the very research that the regulator needs to protect the rights of individuals, the Bill should have granted the formal and non-formal academic community immunity from liability and criminal prosecution.
Lastly but also most importantly, human rights activists are unhappy because the committee again like the GDPR did not include sufficiently specific surveillance law fixes. The European Union has historically handled this separately in the ePrivacy Regulation. Maybe that is the approach we must also follow or maybe this was a missed opportunity. Overall, the B N Srikrishna committee must be commended for producing a good data protection Bill. The task before us is to make it great and to have it enacted by Parliament at the earliest.
Anti-trafficking Bill may lead to censorship
The article was published in Livemint on July 24, 2018.
The legislative business of the monsoon session of Parliament kicked off on 18 July with the introduction of the Trafficking of Persons (Prevention, Protection and Rehabilitation) Bill, 2018, in the Lok Sabha. The intention of the Union government is to “make India a leader among South Asian countries to combat trafficking” through the passage of this Bill. Good intentions aside, there are a few problematic provisions in the proposed legislation, which may severely impact freedom of expression.
For instance, Section 36 of the Bill, which aims to prescribe punishment for the promotion or facilitation of trafficking, proposes a minimum three-year sentence for producing, publishing, broadcasting or distributing any type of material that promotes trafficking or exploitation. An attentive reading of the provision, however, reveals that it has been worded loosely enough to risk criminalizing many unrelated activities as well.
The phrase “any propaganda material that promotes trafficking of person or exploitation of a trafficked person in any manner” has wide amplitude, and many unconnected or even well-intentioned actions can be construed to come within its ambit as the Bill does not define what constitutes “promotion”. For example, in moralistic eyes, any sexual content online could be seen as promoting prurient interests, and thus also promoting trafficking.
Rather than imposing a rigorous standard of actual and direct nexus with the act of trafficking or exploitation, a vaguer standard which includes potentially unprovable causality, including by actors who may be completely unaware of such activity, is imposed. This opens the doors to using this provision for censorship and imposes a chilling effect on any literary or artistic work which may engage with sensitive topics, such as trafficking of women.
In the past, governments have been keen to restrict access to online escort services and pornography. In June 2016, the Union government banned 240 escort sites for obscenity even though it cannot do that under Section 69A or Section 79 of the Information Technology Act, or Section 8 of the Immoral Traffic (Prevention) Act. In July 2015, the government asked internet service providers (ISPs) to block 857 pornography websites sites on grounds of outraging “morality” and “decency”, but later rescinded the order after widespread criticism. If historical record is any indication, Section 36 in this present Bill will legitimize such acts of censorship.
Section 39 proposes an even weaker standard for criminal acts by proposing that any act of publishing or advertising “which may lead to the trafficking of a person shall be punished” (emphasis added) with imprisonment for 5-10 years. In effect, the provision mandates punishment for vaguely defined actions that may not actually be connected to the trafficking of a person at all. This is in stark contrast to most provisions in criminal law, which require mens rea (intention) along with actus reus (guilty act). The excessive scope of this provision is prone to severe abuse, since without any burden of showing a causal connect, it could be argued that anything “may lead” to the trafficking of a person.
Another by-product of passing the proposed legislation would be a dramatic shift in India’s landscape of intermediary liability laws, i.e., rules which determine the liability of platforms such as Facebook and Twitter, and messaging services like Whatsapp and Signal for hosting or distributing unlawful content.
Provisions in the Bill that criminalize the “publication” and “distribution” of content, ignore that unlike the physical world, modern electronic communication requires third-party intermediaries to store and distribute content. This wording can implicate neutral communication pipeways, such as ISPs, online platforms, mobile messengers, which currently cannot even know of the presence of such material unless they surveil all their users. Under the proposed legislation, the fact that human traffickers used Whatsapp to communicate about their activities could be used to hold the messaging service criminally liable.
By proposing such, the Bill is in direct conflict with the internationally recognized Manila Principles on Intermediary Liability, and in dissonance with existing principles of Indian law, flowing from the Information Technology Act, 2000, that identify online platforms as “safe harbours” as long as they act as mere conduits. From the perspective of intermediaries, monitoring content is unfeasible, and sometimes technologically impossible as in the case of Whatsapp, which facilitates end-to-end encrypted messaging. And as a 2011 study by the Centre for Internet & Society showed, platforms are happy to over-comply in favour of censorship to escape liability rather than verify actual violations. The proposed changes will invariably lead to a chilling effect on speech on online platforms.
Considering these problematic provisions, it will be a wise move to send the Bill to a select committee in Parliament wherein the relevant stakeholders can engage with the lawmakers to arrive at a revised Bill, hopefully one which prevents human trafficking without threatening the Constitutional right of free speech.
The National Health Stack: An Expensive, Temporary Placebo
The article was published by Bloomberg Quint on August 6, 2018.
However, the next ten years would see the scheme meet with constant criticism about its poor management and immense expenditure; and after a gruelling battle for survival, including spending £20 billion and having top experts on board, the NPfIT finally met its end in 2011.
Fast forward eight years — the Indian government’s public policy think tank, NITI Aayog, is proposing an eerily similar idea for the much less developed, and much more populated Indian healthcare sector. On July 6, the NITI Aayog released a consultation paper to discuss “a digital infrastructure built with a deep understanding of the incentive structures prevalent in the Indian healthcare ecosystem”, called the National Health Stack. The paper identifies four challenges that previous government-run healthcare programs ran into and that the current system hopes to solve. These include:
- low enrollment of entitled beneficiaries of health insurance,
- low participation by service providers of health insurance,
- poor fraud detection,
- lack of reliable and timely data and analytics.
The current article takes a preliminary look at the goals of the NHS and where it falls behind. Subsequent articles will break down the proposed scheme with regard to safety, privacy and data security concerns, the feasibility of data analytics and fraud detection, and finally, the role of private players within the entire structure.
The primary aim of any digital health infrastructure should be to compliment an existing, efficient healthcare delivery system.
As seen in the U.K., even a very well-functioning healthcare system doesn’t necessarily mean the digitisation efforts will bear fruit.
The NHS is meant to be designed for and beyond the Ayushman Bharat Yojana — the government’s two-pronged healthcare regime that was introduced on Feb. 1. Unfortunately, though, India’s healthcare regime has long been in the need of severe repair, and even if the Ayushman Bharat Yojana works optimally, there are no indications to show that this will miraculously change by their stated target of 2022. Indeed, experts predict it would take at least a ten-year period to successfully implement universal health coverage. A 2013 report by EY-FICCI stated that we must consider a ten-year time frame as well as allocating 3.5-4.7 percent of the GDP to health expenditure to achieve universal health coverage.
However, as per the current statistics, the centre’s allocation for health in the 2017-18 budget is Rs 47,353 crore, which is 1.15 percent of India’s GDP.

Patients wait for treatment in the corridor of the Acharya Tulsi Regional Cancer Treatment & Research Institute in Bikaner, Rajasthan, India. (Photographer: Prashanth Vishwanathan/Bloomberg)
Along with the state costs, India’s current expenditure in the health sector comes to a meagre 1.4 percent of the total GDP, far short of what the target should be. Yet, the government aims to attain universal health coverage by 2022.
In the first of its two-pronged strategy, the Ayushman Bharat Yojana aims to establish 1.5 lakh ‘Health and Wellness Centres’ across the country by 2022, which would provide primary healthcare services free of cost.
However, the total fund allocated for ’setting up’ these centres is only Rs 1,200 crore, which comes down to a meagre Rs 80,000 per centre.
It is unclear whether the government plans to establish new sub-centres, or improve the existing ones. Either way, a pittance of Rs 80,000 is grossly insufficient. As per reports, among the 1,56,231 current health centres, only 17,204 (11 percent) have met Indian Public Health Standards as of March 31, 2017. Shockingly, basic amenities like water and electricity are scarce, if not, absent in a substantial number of these centres.
At least 6,000 centres do not have a female health worker, and at least 1,00,000 centres do not have a male health worker.

A woman holds a child in the post-delivery ward of the district hospital in Jind, Haryana, India. (Photographer: Prashanth Vishwanathan/Bloomberg)
Even taking the generous assumption that the existing 17,204 centres are in top condition, the future of the rest of these health and wellness centres continues to be bleak.
In truth, both limbs of the Ayushman Bharat strategy remain oblivious to the reality of the situation. The goals do not take into account the existing problems within access to healthcare, nor the relevant economic and social indicators that depict a contrasting reality.
Therefore, the fundamental question remains: if there is no established, well-functioning healthcare delivery system to support, what will the NHS help?

NHS: What Purpose Does It Serve?
The ambitious scope of the National Health Stack consultation paper aside, the central problem plaguing the Indian healthcare system, i.e, delivery, and access to healthcare, remains unaddressed. The first two problems that the NHS aims to solve focus solely on increasing health insurance coverage. However, very problematically, the document does not explicitly mention how a digital infrastructure would lead to rising enrollment of both beneficiaries and service providers of insurance.
This goal of increasing enrollment without a functioning healthcare system could result in two highly problematic scenarios.
Either health and wellness centres will effectively act as enrollment agencies rather than providers of healthcare, or the government would fall back on its ‘Aadhar approach’ and employ external enrollment agents.
The former approach runs a very real risk of the health and wellness centres losing focus on their primary purpose even while statistics show them as functioning centres – thus negatively impacting even the working centres. The latter approach is at a higher risk of running into problems akin to the case of Aadhaar enrollment, such as potential data leakages, identity thefts and a market for fake IDs. Even if we somehow overlook this and assume that the NHS would help increase insurance coverage without additional problems, the larger question still stands: should health insurance even be the primary goal of the government, over and above providing access to healthcare? And what effect will this have on the actual delivery of healthcare services to the common citizen?

A lone patient sleeps in the post operation recovery ward of the district hospital in Jind, Haryana, India. (Photographer: Prashanth Vishwanathan/Bloomberg)
Should Insurance Be A Primary Objective Of The Indian Government?
Simply put, the answer is no, because greater insurance coverage need not necessitate better access to healthcare. In recent years, health insurance in India has been rising rapidly due to government-sponsored schemes. In the fiscal year 2016-17, the health insurance market was prized to be worth Rs 30,392 crore. Even with such large investments in insurance premiums, the insurance market accounts for lesser than 5 percent of the total health expenditure.
Furthermore, previous experiences with government-sponsored health insurance schemes have proven that there is little merit to such an expensive task.
For instance, the government’s earlier health insurance scheme, Rashtriya Swasthya Bima Yojana, was predicted to be unable to completely provide ‘accessible, affordable, accountable and good quality health care’ if it focussed only on “increasing financial means and freedom of choice in a top-down manner”.
These traditional insurance-based models are characterised by problems of information asymmetry such as ‘moral hazard’ — patients and healthcare providers have no incentive to control their costs and tend to overuse, resulting in an unsustainable insurance system and cost inflation. Any attempt to regulate providers is met with harsh, cost-cutting steps which end up harming patients.
On another note, some diseases which are responsible for the most number of deaths in the country — including ischaemic heart diseases, lower respiratory tract infections, chronic obstructive pulmonary disease, tuberculosis and diarrhoeal diseases — are usually chronic conditions that need outpatient consultation, resulting in out-of-pocket expenses.

Patients wait at the Head and Neck Cancer Out Patient department of Tata Memorial Hospital in Mumbai, India. (Photographer: Prashanth Vishwanathan/Bloomberg News)
Even though the government has added non-communicable diseases under the ambit of the health and wellness centres, there are still reports stating that for some of the most impoverished, their reality is that 80 percent of the time, they have to cover their expenses from their pocket. This issue in all probability will continue to exist since the status and likelihood for these centres to be successful itself is questionable.
It is clear, that in the current scheme of things, this traditional insurance model of healthcare cannot benefit those it is meant for.
If this is the case, why has the NHS built its main objectives around insurance coverage rather than access to healthcare? It is imperative that we question the legitimacy of these goals, especially if they indicate the government's intentions to push health insurance via the NHS above its responsibility of delivering healthcare. The government's thrust for a digital infrastructure shows tremendous foresight, but at what cost? Even the clear goal of healthcare data portability has very little benefit when one understands that this becomes an important goal only when one has given up on ensuring widespread accessible healthcare. Once the focus shifts from using technology needlessly to developing an efficient and universally accessible healthcare delivery system, the need for data portability dramatically reduces. The temptation of digitisation and insurance coverage cannot and should not blind us from the main goal — access to healthcare. The one lesson that we must learn from the case of the U.K. is that even with a well-functioning healthcare delivery system, a digital infrastructure must be introduced very thoughtfully and carefully. In our eagerness to leapfrog with technology, we must not mistake a placebo for a panacea.
Murali Neelakantan is an expert in healthcare laws. Swaraj Barooah is Policy Director at The Centre for Internet and Society. Swagam Dasgupta and Torsha Sarkar are interns at The Centre for Internet and Society.
Future of Work: Report of the ‘Workshop on the IT/IT-eS Sector and the Future of Work in India’
This report was authored by Torsha Sarkar, Ambika Tandon and Aayush Rath. It was edited by Elonnai Hickok. Akash Sriram, Divya Kushwaha and Torsha Sarkar provided transcription and research assistance. A PDF of the report can be accessed here.
Introduction
The Workshop was attended by a diverse group of stakeholders which included industry representatives, academicians and researchers, and civil society. The discussions went over various components of the transition in the sector to Industry 4.0, including the impact of Industry 4.0-related technological innovations on work broadly in India, and specifically in the IT/IT-eS sector (hereinafter referred to as the “Sector”). The discussion focused on the reciprocal impact on socio-political dimensions, the structure of employment, and forms of work within workspaces.
The Workshop was divided into three sessions. The first session was themed around the adoption and impact of Industry 4.0 technologies vis-a-vis the organisation of work. Within this the key questions were: the nature of the technologies being adopted, the causes that are driving the uptake of these technologies, and the ‘tasks’ constituting jobs in the Sector.
The second session focussed on the role of skilling and re-skilling measures as mitigators to projected displacement of jobs. The issues dealt with included shifts in company, educational, and social competency profiles as a result of Industry 4.0, transformations in the predominant pedagogy of education, vocational, and skill development programmes in India, and their success in creating employable workers and filling skill gaps in the industry.
The third session looked at social welfare considerations and public policy interventions that may be necessitated in the wake of potential technological unemployment owing to Industry 4.0. The session was designed with a specific focus on the axes of gender and class, addressing questions of precarity, wages, and job security in the future of work for marginalized groups in the workforce.
Preliminary Comments
The Workshop opened with a brief introduction on the research the Centre for Internet and Society (CIS) is undertaking on the Future of Work (hereinafter referred to as “FoW”) vis-a-vis Industry 4.0. The conception of Industry 4.0 that CIS is looking at is the technical integration of cyber-physical systems in production and logistics on one hand, and the use of internet of things (IoT) and the connection between everyday objects and services in the industrial processes on the other. The scope of the project, including the impact of automation on the organisation of employment and shifts in the nature and forms of work, including through the gig economy, and microwork, was detailed. The historical lens taken by the project, and the specific focus on questions of inequality across gender, class, language, and skill were highlighted.
It was pointed out that CIS’ research, in this regard, comes from the necessity of localising and re-examining the global narratives around Industry 4.0. While new technologies will be developed and implemented globally, the impact of these technologies in the Indian context would be mediated through local, political and socio-economic structures. For instance, the Third Industrial Revolution, largely associated with the massification of computing, telecommunications and electronics, is still unfolding in India, while attempts are already being made to adapt to Industry 4.0. These issues provided a starting point to the discussion on the impact of Industry 4.0 in India.
Qualifying Technological Change
Contexualising the narrative with historical perspectives
The panel for the first session commenced with a discussion around a historical perspective on job loss being brought about due to mechanisation. The distinction between Industry 3.0 and 4.0, it was suggested, was largely arbitrary, inasmuch as technological innovation has been a continuous process and has been impacting lives and the way work is perceived. It was argued that the only factor differentiating Industry 4.0 from previous industrial revolutions is ‘intelligent’ technology that is automating routine cognitive tasks. The computer, programmatic logic control (PLC) and data (called the ‘new oil’) were also a part of Industry 3.0, but intelligent technologies are able to provide greater analytical power under Industry 4.0.
The discussion also went over the distinction between the terms ‘job’, ‘task’ and ‘work’. It was argued that the term ‘job’ might be treated as a subset of the term ‘work’, with the latter moving beyond livelihood to encompass questions of dignity and a sense of fulfilment in the worker. With relation to this distinction, it was mentioned that the jobs at the risk of automation would be those that fulfill only the basic level in Maslow’s hierarchy - implying largely routine manual tasks. Additionally, it was explained that although these jobs will continue to use labour through Industry 4.0, it is only the nature of technological enablement that would change to automate more dangerous and hazardous tasks.
Technology as a long-term enabler of job creation
It was argued that technology has historically been associated with job creation. Historical instances cited included that of popular anxiety due to anticipated job loss through the uptake of the spinning machine and the steam engine, whereas the actual reduction in the cost of production led to greater job creation, increased mobility and improved quality of life in the long-term. Such instances were used to further argue that technology has historically not resulted in long-term job reductions.
The platform economy was posited as a model for creating jobs, through the efficient matching of supply and demand through digital platforms. It was indicated that rural to urban migration is aided by such platforms, as labourers voluntarily enrol in skilling initiatives given the certainty of employment through platformization. It was further argued that historically, Indian workers have been educated rather than skilled, and that platformization and automation, coupled with the elasticity of human needs, will provide greater incentives for technically skilled workers by creating desirable jobs.
Factors leading to differential adoption of automation
In relation to the adoption of the technologies Industry 4.0, it was argued that the mere existence of a technology does not necessitate its scalablity at an industrial level. Scalability would be possible only when the cost of labour is high relative to the costs entailed in technological adoption. This was supported by data from a McKinsey Report[1] which indicated that countries like the US and Germany would be impacted in the short term by automation, because their cost of labour is higher. Conversely, since the cost of labour in India is relatively cheap, the reality of technological displacement is still far away and the impact would not be immediate.
Similarly, a distinction was also made to account for the differential impact of automation in various sectors. For instance, it was indicated that since the IT/IT-eS sector in India is based on exporting services and outsourcing of businesses. Accordingly, if Germany automates its automobile industry, that would impact India less than if it automates the IT/IT-eS sector, as the latter is more reliant on exporting its services to developed economies. The IT/IT-eS sector was further broken down into sub-sectors with the intention of highlighting the differential impact of automation and FoW in each of these sub-sectors. It was agreed that the BPO sub-sector would be more adversely impacted than core IT services, given its constitution of routine nature of tasks at a higher risk of automation.
Disaggregating India’s Skilling Approach
The discussion around skilling measures was contextualised in the Indian context by alluding to data collected from the National Sample Survey Organisation (NSSO) surveys. The data revealed that around 36% of India’s total population is under the age of seventeen and approximately 13% are between 18 - 24. Additional statistics suggested that only around a quarter of the workforce aged 18-24 years had achieved secondary and higher secondary education and close to 13% of the workforce was illiterate. While these numbers included both male and female workers, it was pointed out that it was an incomplete dataset as it excluded transgender workers. It was suggested it should be this segment of the Indian demographic that is targeted for significant skilling pushes, which could be catalysed through specific vocational training centres. It was also suggested that there was a need for to restructure the role of the National Skill Development Corporation (NSDC) in the Indian skilling framework.
A comprehensive picture was painted by conceptualising the skilling framework in India as 5 distinct pillars. This conceptualisation was used to debunk the narrative around NSDC being the sole entity pushing for skill development in the country. The NSDC’s function in the skilling framework was posited as providing funding to skilling initiatives with programmes lasting for a period of 3 months. These 3- month programmes were critiqued for being insufficient for effective training, especially given the low skill levels of workers going into the programmes. The NSDC’s placement rate of 12% as per their own records was used to support this argument. Further suggestions on making the NSDC more effective were made in a later discussion[2].
Related to this, the second pillar of vocational skilling was said to be the Industrial Training Institute (ITI). The third pillar was said to be the school system which was critiqued for does not offering vocational education at secondary and senior secondary levels. The fourth pillar comprised of the 16 ministries which governed the labour laws in India - none of whose courses were National Skills Qualifications Framework (NSQF) compliant.
The fifth pillar was construed as the industry itself and the enterprise-based training it conducted. However, it was stated that India’s share of registered companies who did enterprise-based training was dismal. In 2009, the share of enterprise-based training was 16% which rose in 2014 to 36%. Further, most of these 36% were registered large firms as opposed to small and medium sized enterprises. Unregistered companies, it was suggested, were simply doing informal apprenticeships.
Joint public and private skilling initiatives
In addition to government sponsored skilling initiatives, attention was directed to skill development partnerships that took the shape of public-private initiatives. As an example, it was said that that a big player in the ride-hailing economy had worked with NSDC and other skilling entities to ensure that soft skills were being imparted to their driver partners before they were on-boarded onto the platform.
It was also brought forth that innovative forms of skilling and training were gaining traction in the education sector as well in the private sector. This was instantiated through instances of uptake of platforms which apply artificial intelligence, and within that machine learning based techniques, to generate and disseminate easier- to- consume video-based learning.
Driving Job Growth: Solving for Structural Eccentricities of the Indian Labour Market
Catalysing manufacturing-led job growth
The discussion began by discussing specific dynamics of the Indian labour markets in the context of the Indian economy. It was pointed out the productivity level of the services sector is not as high as the productivity level of manufacturing, which is problematic for job creation in a developing economy such as India witnessing capital-intensive growth in the manufacturing sector. The underlying argument was that the jobs of the future in the Indian context will have to be created in the manufacturing sector.
Several macroeconomic policy interventions were suggested to reverse the trend of capital-intensive growth in order to make manufacturing the frontier for enhanced job creation. The need for a trade policy in consonance with the industrial policy was stated as imperative. This was substantiated by highlighting the lack of an inverted duty structure governing the automobile sector that has led India to be amongst the biggest manufacturers of automobiles. The inverted duty structure entails finished products having a lower import tariff and a lower customs duty when compared to import of raw materials or intermediates. However, it was highlighted that a dissonant industrial policy failed to acknowledge that at least 50% of india’s manufacturing comes from Micro, Small & Medium Enterprises (MSMEs) and provided no assistance to MSMEs in obtaining credit, market access or technology upgradation. On the other hand, it was asserted that large corporates get 77% of the total bank credit.
Another challenge that was highlighted was with the Government of India’s severely underfunded manufacturing cluster development programs under the aegis of the Ministry of Textiles and the Ministry of MSMEs. For sectors that contribute majorly towards India’s manufacturing output, it was asserted that these programmes were astonishingly bereft of any governing policy and suffer from several foundational issues. Moreover, it was observed that these clusters are located around the country in Tier 2, 3 and 4 cities where the quality of infrastructure is largely lacking. The Atal Mission for Rejuvenation and Urban Transformation (AMRUT) program devised for the development of these cities is also myopic as the the target cities are not the ones where these manufacturing clusters are located. The rationale behind such an approach was that building infrastructure at geographical sites of job creation would lead to an increase in productivity which would in turn attract greater investment. This would have to necessarily be accompanied by hastening the setting up of industrial corridors - the lackadaisical approach to which was stated as a key component of India being outpaced by other developing economies in the South East Asian region.
An additional policy intervention that was suggested was from the lens of setting up of skilling centres by NSDC in proximity to these manufacturing clusters where the job creation is being evidenced as opposed to larger metropolitan cities.
Carving out space for a vocational training paradigm
It was asserted that the focus of skilling needs to be on the manufacturing rather than services sector, given the centrality of manufacturing to a developing economy undergoing an atypical structural transformation[3] - as outlined above. Further compounding the problem of jobless growth, it was stated that 50% of the manufacturing workforce have 8 or less years of education and only 5% of the workforce including those that have technical education are vocationally trained, according to the NSS, 62nd Round on Employment and Unemployment.
A gulf in primary and secondary education vis-a-vis vocational training was pointed as one of the most predominant causes behind the much touted ‘skills gap’ that the Indian workforce is said to be battling with. Using data to further cull out the argument, it was said that in 2007, the net enrollment in India for primary education had already reached 97% and that between 2010 - 2015, the secondary education enrollment rate went from 58% to 85%.[4] It was hypothesised that the latter may have risen to 90% levels since. Furthermore, the higher education enrollment rate also commensurately went up from 11% in 2006 to 26-27% in 2017.[5] It was argued that this is impossible to achieve without gender parity in higher education. This gender parity in education was contrasted with the systematic decline in the women’s labour force participation that India has been witnessing in the last 30 years.
Consequently, the ‘massification’ of higher education in India over the past 10 years was critiqued as ineffectual in comparison to the Chinese model, as the latter focused on engaging students in vocational training, which the Indian education system had failed to do. The role of the gig economy in creating job opportunities despite this gap between educational and vocational training was regarded as important, especially given the lack of growth in the traditional job markets.
Accounting for the Margins
With relation to the profiles of workers within sectors, it was indicated that factors such as gender, class, skill, income, and race must be accounted for to determine the ‘winners’ and ‘losers’ of automation. Several points were discussed with relation to this disaggregation.
Technology as an equaliser? Gender and skill-biased technological change
First, the idea of technology and development as objective and neutral forces was questioned, with the assertion that human decision-makers, who more often than not tend to be male, allow inherent biases to creep into outputs, processes, and objectives of automation. Data from the Belong Survey in IT services[6] indicated that the proportion of women in core engineering was 26% of the workforce, while that in software testing was 33%. Coupled with the knowledge that automation and technology would automate software testing first, it was argued that jobs held by female workers were positioned at a higher immediate risk of automation than male workers.
The ‘Leaky Pipe Problem’ in STEM industries i.e. the observation that female workers tend to be concentrated in entry level jobs, while senior management is largely male dominated was also brought to the fore. This was used to bolster the argument that female workers in the Sector will lose out in the shorter term, when automation adversely impacts the lower level jobs.
A survey conducted by Aspiring Minds[7] which tracked the employability of the engineering graduates was utilised to further flesh out skill biased technological change. As per the survey, 40% of the graduating students are employable in the BPO sector, while only 3% of the students are employable in the sector for software production. With the BPO sector likelier to be impacted more adversely than core IT services, it was emphasised that policy considerations should be very specific in their ambit.
Social security and the platform economy
The discussion around the platform economy commenced with a focus on how it had created economic opportunities in the formal sector by matching demand and supply on one hand, and by reducing inefficiency in the system through technology on the other. It was pointed out that these newer forms of work were creating millions of entrepreneurship opportunities that did not exist previously. These opportunities, it was suggested, were in themselves flexible and contributing the greater push towards enhancing the numbers of those that come within the ambit of India’s formal economy.
This discussion was countered by suggesting that the shift of the workforce from the informal sector to the formal sector, which companies in the gig economy claimed they contributed to, have instead restricted the kind of lives gig workers have been living historically. As an instance, it was pointed out that a farmer who had been working with a completely different set of skills was now being asked to shift to a new set of skills which would be suited for a very specific role and not transposable across occupations. In other words, it would not be meaningful skilling. It was also pointed out that what distinguishes formal work from informal is whether the worker has social security net or not - mere access to banking services or filing of tax returns was not sufficient for characterising a workforce as being formal in nature.
Relatedly, the possibility of social security was discussed for the unorganised sector and microworkers. One of the possibilities discussed was to ensure state subsidised maternity, disability, and death security, and pensions for workers below the poverty line. The fiscal brunt borne by the government for such a scheme was anticipated to not be above 0.4% of the GDP. It was suggested that this would move forward the conversation on minimum wage and fair work, which would be of great importance in broader conversations around working conditions in the platform economy.
The interplay of gender and platformisation
It was highlighted that trends in automation are going to change the occupational structure in the digital economy - the effect of which will especially be felt in cognitive routine jobs given their increased propensity to platformisation. A World Economic Forum report[8] was cited which indicated the disproportional risk of unemployment faced by women given their concentration in cognitive routine jobs was also brought up.
The discussion logically undertook a deeper look at the platformisation of work with a specific focus on freelance microwork and its impact on the female labour force and culled out certain positive mandates arising from such newer forms of work. It was suggested that industries are more likely to employ female workers in microwork due to lower rates of attrition, and flexible labour. It was reiterated that freelancing in India extends beyond data entry and other routine jobs, to include complex work - thereby also catering to skilled workers desirous of flexibility. Platforms designing systems to meet the demand for flexible work were also discussed, such as platforms geared towards female workers undertaking reskilling measures and counselling for females returning from maternity leave or sabbaticals. Additionally, the difficulty of defining freelancing under existing frameworks of employment, compounded by the lack of legal structures for such work, was outlined.
Systemic challenges within the Indian labour law framework
Static design of legal processes
Labour law was, naturally, acknowledged as a key determinant in the conversation around both the uptake and impact of automative technologies encapsulated within Industry 4.0.
The archaic nature of India’s labour law framework was highlighted as a major impediment to ensuring both worker rights as well as the ease of conducting commerce. It was pointed out that organised labour continues to be under the ambit of the Industrial Disputes Act, which was made effective in 1947, has undergone minimal amendments since. This was critiqued on the basis that the framework for the law is embedded in its historical context, and while the industrial landscape in the country has transformed drastically since the implementation of the Industrial Disputes Act, the legal framework has not evolved. Similarly, the Karnataka Shops and Establishments Act, 1961 which regulates the Sector today was enacted much before the Sector even opened up in India in the 1990s.
Additionally, it was pointed out that the consolidation of the fragmented extant framework of labour laws in India was being consolidated into 4 labour codes without any wholesale modernisation push reforming the laws being consolidated. Consequently, it was argued that the government has to drive changes through policies alone as the legal framework remains static. Barriers to implementation of adequate policies were also discussed, such as the political impact of labour policies, lack of state initiative to deal with the impact of the future of work, apart from the historic inability of the law to keep up with the state of labour and economy.
Labour law arbitrage
One of the reasons behind the increasing contractualizing of labour in India was attributed to over-regulation. There was consensus that the labour law regime was not conducive to industry in India leading to greater opportunistic behaviours from industry participants. It was acknowledged that the political clout that a lot of contractors (of labourers) enjoy along with providing primary employers greater flexibility to hire and fire employees at will has led to a widespread utilisation of contract labour entities.
It was further stated that industry behaviour has adopted several other tools of arbitrage to not consider labour law as a key impediment in the ease of scaling business. Empirical evidence of labour law arbitrage was cited to drive home the point - according to national surveys, 80-85% of enterprises employ less than 99 workers as the law mandates stricter compliance requirements for enterprises employing 100 or more workers[9]. This was acknowledged a serious hurdle to scaling businesses.
Problems behind other apparently well-intentioned legislation from a public policy lens having counterproductive consequences was also highlighted. In the space of labour laws, the example of the recently enacted Maternity Benefit (Amendment) Act, 2017 was cited. By enhancing maternity benefits, without accounting for other provisioning such as a paternity benefit inclusion, it was anticipated that companies may entirely shy away from hiring women.
Policy Paralysis
The discussion progressed towards a high-level discussion around the efficacy of law vis-a-vis state policy as a means to create a system of checks and balances in the context of Industry 4.0. It was highlighted that law, by design, would be outpaced by technological change. The common law system of law operating in India is premised on a time-tested emphasis on post-facto regulation. In other words, it is reactionary. While policy making in India suffers from a similar plague of playing catch-up, it is in large part due to a bureaucratic structure premised on generalism - a pressing need for domain expertise in policy making was emphasised upon. Having said that, it was stated that it is the institutional design of policy making institutions that needs rectification. What was acknowledged was the success, albeit scant, that individual states have had in policy making catering to specific yet diverse domains. A greater push towards clear and progressive evidence-based policy pushes was stressed upon with the anticipation that it would lead to self-regulation by the industry itself - be it in terms of the future of employment or of the economic direction that the industry will embark on.
Concluding Remarks
The discussions during the course of the Workshop situated the discourse around Industry 4.0 within the contours of the Indian labour realities and the IT sector within that.
As a useful starting point, various broader perspectives around the impact of technological change on the quantum of jobs were brought forth. While the industry perspective was that of technology as an enabler of job creation in the long-run, it was sufficiently tempered by concerns around those impacted adversely in the short to medium-term time frames. These concerns coalesced towards understanding the potential impact of Industry 4.0 on the nature of work, as well as mitigation tools to ease the impact of technological disruption on labour.
Important facets of technological adoption within the Sector were highlighted, such as potential for scalability as well as the distinct eccentricities of the various sub-sectors the IT sector subsumed. The differential impact within the various sub-sectors was pegged to the differential composition of automatable tasks (routine, rule-based) within each sub-sector. However, questions regarding the exact contours of task composition were left unanswered signalling a potential area for further research. On the other hand, the primary challenge to technological adoption faced from the labour-supply side was skilling, or the lack thereof. This was contextualised in the larger scheme of structural issues plaguing the skilling machinery operating in the country, which lead to inadequate dispensation of technical and vocational education and training (TVET). In terms of additional structural issues that would potentially have an impact on how Industry 4.0 plays out in the Indian context, attention was directed towards overdue reform of the labour law framework which has already struggled with incorporating newer forms of working engagements such as platform and gig work, that are being evidenced as a part of Industry 4.0.
An underlying theme that found mention across sessions was the need to devote attention to prevent further marginalisation as a consequence of technological disruption of the already marginalised. Evidence from government datasets as well as from literature around concepts such as skill biased technological change, the leaky pipe problem, and the U-shaped curve of female labour force participation were cited to explicate these issues. The merits of different policy measures to address these concerns, such as social security, living wages, and maternity benefits were also discussed.
While the Workshop touched upon several facets of the discourse around Industry 4.0 in the Sector, it also sprung up areas that require further inquiry. Questions around where in the value chain use-cases for Industry 4.0 technologies were emerging needed a more comprehensive understanding. Moreover, the impact of Sector Skill Councils (SSCs), a central aspect of the skilling ecosystem in India, wasn’t touched upon. An additional path of inquiry that emerged pertained to evolving constructive reforms to legal and economic policy frameworks as top-down interventions within the Sector that could be anticipated to play a significant role in the uptake and impact of Industry 4.0 technologies.
[1] McKinsey Global Institute, A future that works: Automation, employment, and productivity, https://www.mckinsey.com/~/media/mckinsey/featured%20insights/Digital%20Disruption/Harnessing%20automation%20for%20a%20future%20that%20works/MGI-A-future-that-works-Executive-summary.ashx, (accessed 10 August 2018).
[2] See discussion under ‘Catalysing manufacturing-led job growth‘.
[3] R. Verma, Structural Transformation and Jobless Growth in the Indian Economy, The Oxford Handbook of the Indian Economy, 2012.
[4] S. Mehrotra, ‘The Indian Labour Market: A Fallacy, Two Looming Crises and a Tragedy’, CSE Working Paper, April 2018.
[5] ibid.
[6] Mohita Nagpal, ‘Women in tech: There are 3 times more male engineers to females’, belong.co, http://blog.belong.co/gender-diversity-indian-tech-companies, (accessed 10 August 2018).
[7] Aspiring Minds, National Programming Skills Report - Engineers 2017, https://www.aspiringminds.com/sites/default/files/National%20Programming%20Skills%20Report%20-%20Engineers%202017%20-%20Report%20Brief.pdf, (accessed 11 August 2018).
[8] World Economic Forum, The Future of Jobs Employment, Skills and Workforce Strategy for the Fourth Industrial Revolution: Global Challenge Insight Report, January 2016.
[9] Ministry of Statistics and Programme Implementation, All India Report of Sixth Economic Census, Government of India, 2014.
India's Contribution to Internet Governance Debates
Abstract
India is the leader that championed ‘access to knowledge’ and ‘access to medicine’. However, India holds seemingly conflicting views on the future of the Internet, and how it will be governed. India’s stance is evolving and is distinct from that of authoritarian states who do not care for equal footing and multi-stakeholderism.
Introduction
Despite John Perry Barlow’s defiant and idealistic Declaration of Independence of Cyberspace1 in 1996, debates about governing the Internet have been alive since the late 1990s. The tug-of-war over its governance continues to bubble among states, businesses, techies, civil society and users. These stakeholders have wondered who should govern the Internet or parts of it: Should it be the Internet Corporation for Assigned Names and Numbers (ICANN)? The International Telecommunications Union (ITU)? The offspring of the World Summit on Information Society (WSIS) - the Internet Governance Forum (IGF) or Enhanced Cooperation (EC) under the UN? Underlying this debate has been the role and power of each stakeholder at the decision-making table.States in both the global North and South have taken various positions on this issue.
Whether all stakeholders ought to have an equal say in governing the unique structure of the Internet or do states have sovereign public policy authority? India has, in the past, subscribed to the latter view. For instance, at WSIS in 2003, through Arun Shourie, then India’s Minister for Information Technology, India supported the move ‘requesting the Secretary General to set up a Working Group to think through issues concerning Internet Governance,’ offering him ‘considerable experience in this regard... [and] contribute in whatever way the Secretary General deems appropriate’. The United States (US), United Kingdom (UK) and New Zealand have expressed their support for ‘equal footing multi-stakeholderism’ and Australia subscribes to the status quo.
India’s position has been much followed, discussed and criticised. In this article, we trace and summarise India’s participation in the IGF, UN General Assembly (‘UNGA’), ITU and the NETmundial conference (April 2014) as a representative sample of Internet governance fora. In these fora, India has been represented by one of three arms of its government: the Department of Electronics and Information Technology (DeitY), the Department of Telecommunications (DoT) and the Ministry of External Affairs (MEA). The DeitY was converted to a full-fledged ministry in 2016 known as the Ministry of Electronics and Information Technology (MeitY). DeitY and DoT were part of the Ministry of Communications and Information Technology (MCIT) until 2016 when it was bifurcated into the Ministry of Communications and MeitY.
DeitY used to be and DoT still is, within the Ministry of Communications and Information Technology (MCIT) in India. Though India has been acknowledged globally for championing ‘access to knowledge’ and ‘access to medicine’ at the World Intellectual Property Organization (WIPO) and World Trade Organization (WTO), global civil society and other stakeholders have criticised India’s behaviour in Internet governance for reasons such as lack of continuity and coherence and for holding policy positions overlapping with those of authoritarian states.
We argue that even though confusion about the Indian position arises from a multiplicity of views held within the Indian government, India’s position, in totality, is distinct from those of authoritarian states. Since criticism of the Indian government became more strident in 2011, after India introduced a proposal at the UNGA for a UN Committee on Internet-related Policies (CIRP) comprising states as members, we will begin to trace India's position chronologically from that point onwards.
- Download the paper published in NLUD Student Law Journal here
- For a timeline of the events described in the article click here
- Read the paper published by NLUD Student Law Journal on their website
National Health Stack: Data For Data’s Sake, A Manmade Health Hazard
The op-ed was published in Bloomberg Quint on August 14, 2018.
Apart from facing the severity of their condition, patients afflicted with diseases such as HIV, tuberculosis, and mental illnesses, are often subject to social stigma, sometimes even leading to the denial of medical treatment. Given this grim reality would patients want their full medical history in a database?
The ‘National Health Stack’ as described by the NITI Aayog in its consultation paper, is an ambitious attempt to build a digital infrastructure with a “deep understanding of the incentive structures prevalent in the Indian healthcare ecosystem”. If the government is to create a database of individuals’ health records, then it should appreciate the differential impact that it could have on the patients.
The collection of health data, without sensitisation and accountability, has the potential to deny healthcare to the vulnerable.
We have innumerable instances of denial of services due to Aadhaar and there is a real risk that another database will lead to more denial of access to the most vulnerable.
Earlier, we had outlined some key aspects of the NHS, the ‘world’s largest’ government-funded national healthcare scheme. Here we discuss some of the core technical issues surrounding the question of data collection, updating, quality, and utilisation.
Resting On A Flimsy Foundation: The Unique Health ID
The National Health Stack envisages the creation of a unique ID for registered beneficiaries in the system — a ‘Digital Health ID’. Upon the submission of a ‘national identifier’ and completion of the Know Your Customer process, the patient would be registered in the system, and a unique health ID generated.
This seemingly straightforward process rests on a very flimsy foundation. The base entry in the beneficiary registry would be linked to a ‘strong foundational ID’. Extreme care needs to be taken to ensure that this is not limited to an Aadhaar number. Currently, the unavailability of Aadhaar would not be a ground for denial of treatment to a patient only for their first visit; the patient must provide Aadhaar or an Aadhaar enrolment slip to avail treatment thereafter. This suggests that the national healthcare infrastructure will be geared towards increasing Aadhaar enrollment, with the unstated implication that healthcare is a benefit or subsidy — a largess of government, and not, as the courts have confirmed, a fundamental right.
Not only is this project using government-funded infrastructure to deny its citizens the fundamental right to healthcare, it is using the desperate need of the vulnerable for healthcare to push the ‘Aadhaar’ agenda.
Any pretence that Aadhaar is voluntary is slowly fading with the government mandating it at every step of our lives.

Is The Health ID An Effective And Unique Identifier?
Even if we choose to look past the fact that the validity of Aadhaar is still pending the test of legality before the apex court, a foundational ID would mean that the data contained within that ID is unique, accurate, incorruptible, and cannot be misused. These principles, unfortunately, have been compromised by the UIDAI in the Aadhaar project with its lack of uniqueness of identity (i.e, fake IDs and duplicity), failure to authenticate identity, numerous alleged data leaks (‘alleged’ because UIDAI maintains that there haven’t been any leaks), lack of connectivity to be able to authenticate identity and numerous instances of inaccurate information which cannot be corrected.
Linking something as crucial and basic as healthcare data with such a database is a potential disaster.
There is a real risk that incorrect linking could cause deaths or inappropriate medical care.
The High Risk Of Poor Quality Data
The NITI Aayog paper envisages several expansive databases that are capable of being updated by different entities. It includes enrollment and updating processes but seems to assume that all these extra steps will be taken by all the relevant stakeholders and does not explain the motivation for stakeholders to do so.
In a country where government doctors, hospitals, wellness centres, etc are overburdened and understaffed, this reliance is simply not credible. For instance, all attributes within the registries are to be digitally signed by an authorised updater, there must be an audit trail for all changes made to the registries, and surveyors will be tasked with visiting providers in person to validate the data. Identifying these precautions as measures to assure accurate data is a great step towards building a national health database, but this seems an impossible task.
Who are these actors and what will incentivise them to ensure the accuracy and integrity of data?
In other words, what incentive and accountability structures will ensure that data entry and updating is accurate, and not approached from a more ‘jugaad’ ‘let’s just get this done for the sake of it’ attitude that permeates much of the country. How will patients have access to the database to be able to check its accuracy? Is it possible for a patient (who will presumably be ill) to gain easy access to an updater to change their data? If so, how? It is worth noting that the patient’s ‘right’ to check her data assumes that they have access to a computer that is connected to the internet as well as a good level of digital literacy, which is not the case in India for a significant section of the population. Even data portability loses its potential benefits if the quality of data on these registries is not reliable. In this case, healthcare providers will need to verify their patients’ health history using physical records instead, rendering the stack redundant.
Who will be liable to the patient for misdiagnosis based on the database?

Leaving the question of accountability vague opens updaters to the possibility of facing dangerous and unnecessarily punitive measures in the future. The NITI Aayog paper fails to address this key issue which arose recently. Despite being a notifiable disease, there are reports that numerous doctors from the private sector failed to notify or update TB cases to the Ministry of Health and Family Welfare ostensibly on the grounds that they did not receive consent from their patients to share their information with the government. This was met with a harsh response from the government which stated that clinical establishment that failed to notify tuberculosis patients would face jail time. According to a few doctors, the government’s new move would coerce patients to go to ‘underground clinics’ to receive treatment discreetly and hence, would not solve the issue of TB.
The document also offers no specific recommended procedures regarding how inaccurate entries will be corrected or deleted.
It is then perhaps not a stretch to imagine that these scenarios would affect the quality of the data stored; defeating NITI Aayog’s objective of researchers using the stack for high-quality medical data.
The reason why the quality and integrity of data is at the head of the table is that all the proposed applications of the NHS (analytics, fraud detection etc.) assume a high quality, accurate dataset. At the same time, the enrolment process, updating process and disclosed measures to ensure data quality will effectively lead to poor quality data. If this is the case, then applications derived from the NHS dataset should assume an imperfect data, rather than an accurate dataset, which should make one wonder if no data is better than data that is certainly inaccurate.
Lack Of Data Utilisation Guidelines
Issues with data quality are exacerbated depending on how and where it is used, and who uses it. The paper has identified some users to be health-sector stakeholders such as healthcare providers (hospitals, clinics, labs etc), beneficiaries, doctors, insurers and accredited social health activists but misses laying down utilisation guidelines. The foresight to create a dataset that can be utilised by multiple actors for numerous applications is commendable, but potentially problematic -- especially if guidelines on how this data is to be used by stakeholders (especially the private sector) are ignored.
In order to bridge this knowledge gap, India has the opportunity to learn from the legal precedent set by foreign institutions. As an example, one could examine the Health Information Technology for Economic and Clinical Health Act (HITECH) and the Health Insurance Portability and Accountability Act (HIPAA) in the U.S. which sets out strict guidelines for how businesses are to handle sensitive health data in order to maintain the individual’s privacy and security. It goes one step further to also lay down incentive and accountability structures in order that business associates necessarily report security breaches to their respective covered entities.
If we do not take necessary precautions now, we not only run the risk of poor security and breach of privacy but of inaccurate data that renders the national health data repository a health risk for the whole patient population.
There’s also the lack of clarity on who is meant to benefit from using such a database or whether the benefits are equal to all stakeholders, but more on that in a subsequent piece.

It’s Your Recipe, You Try It First!
If the NITI Aayog and the government are sure that there is a need for a national healthcare database, perhaps they can start using the Central Government Health Scheme (which includes all current and retired government employees and their families) as a pilot scheme for this. Once the software, database and the various apps built on it are found to be good value for money and patients benefit from excellent treatment all over the country, it could be expanded to those who use the Employees’ State Insurance system, and then perhaps to the armed forces. After all, these three groups already have a unique identifier and would benefit from the portability of healthcare records since they are likely to be transferred and posted all over the country. If, and only if, it works for these groups and the claimed benefits are observed, then perhaps it can be expanded to the rest of the country’s healthcare systems.
Murali Neelakantan is an expert in healthcare laws. Swaraj Barooah is Policy Director at The Centre for Internet and Society. Swagam Dasgupta and Torsha Sarkar are interns at The Centre for Internet and Society.
Use of Visuals and Nudges in Privacy Notices
Edited by Elonnai Hickok and Amber Sinha
Former Supreme Court judge, Justice B.N. Srikrishna, who is currently involved in drafting the new data-privacy laws for India, was quoted recently by the Bloomberg[1]. Acknowledging the ineffectiveness of consent forms of tech companies that leads to users’ data being collected and misused, he asked if we should have pictograph warnings for consent much like the warnings that are given on cigarette packets. His concern is that an average Indian does not realise how much data they are generating or how it is being used. He attributed this to the access issues with the consent forms presented by companies which are in the English language. In the Indian context, Justice Srikrishna pointed out, considerations around literacy and languages should be addressed.
The new framework being worked on by Srikrishna and his committee comprising academics and government officials, would make the tech companies more accountable for data collection and use, and allow users to have more control over their own data. But, in addition to this regulatory step towards privacy and data protection, the concern towards communication of companies’ data practices through consent forms or privacy notices is also critical for users. Currently, the cryptic notices are a barrier for users, as are the services that do not provide incremental information about the use of the service - for example, what data is being shared with how many people or what data is being collected at what point, instead relying on blanket consent forms taken at the beginning of a service. Visuals can go a long way in making these notices and services accessible to users.
Although, Justice Srikrishna chose the extreme example of warnings on cigarette packets, visually depicting the health risks of cigarette smoking using repulsive imagery, the underlying intent seems to be of using visuals as a means of giving an immediate and clear warning about how people’s data is being used and by whom. It must be noted that the effectiveness of warnings on cigarette packets is debatable. These warnings are also a way in which manufacturers consider their accountability met, which is a possible danger with privacy notices as well. Most companies consider that their accountability is limited to giving all the information to the users without ensuring that the information is communicated to help the user understand the risks. Hence, one has to be cautious of the role of visuals in notices so that they are used with the primary purpose of meaningful communication and accessibility that can be used to inform further action. The visual summary of the data practice in terms of how it will affect the user will also serve as a warning.
The warning images on cigarette packets are an example of the user-influencing design approach called nudging[2]. While nudging techniques are meant to be aimed at the users’ well being, it brings forward the question of who decides what is beneficial for the users. Moreover, the harm in cigarette smoking is more obvious, and thus the favourable choice for the users is also clearer. But, in the context of data privacy, the harms are less apparent. It is difficult to demonstrate the harms or benefits of data use, particularly when data is re-purposed or used indirectly. There is also no single choice that can be pushed when it comes to the use and collection of data. Different users may have different preferences or degrees to which they would like to allow the use of their data. This raises deeper questions about the extent to which privacy law and regulation should be paternalistic.
Nudges are considered to follow the soft or libertarian paternalism approach, where the user is not forbidden any options but only given a push to alter their behaviour in a predictable way[3]. It is crucial to differentiate between the strong paternalistic approach that doesn’t allow a choice at all, the usability approach, and the soft paternalistic approach of nudging, as mentioned by Alessandro Acquisti in his paper, ‘The Behavioral Economics of Personal Information’[4]. In the usability approach, the design of the system would make it intuitive for users to change settings and secure their data. The soft paternalistic approach of nudging would be a step further and present secure settings as a default. Usability is often prioritised by designers. However, soft paternalism techniques help to enhance choice for users and lead to larger welfare[5].
Nudging in privacy notices can be a privacy-enhancing tool. For example, informing users of how many people would have access to their data would help them make a decision[6]. However, nudges can also be used to influence users towards making choices that compromise their privacy. For example, the visual design of default options on digital platforms currently nudge users to share their data. It is critical to ensure that there is mindful use of nudges, and that it is directed at the well being of the users.
The design of privacy notices should be re-conceptualised to ensure that they inform the users effectively, keeping in mind certain best practices. For instance, a multilayered privacy notice can be used, which includes a very short notice designed for use on portable digital devices where there is limited space, condensed notice that contains all the key factors in an easy to understand way, and a complete notice with all the legal requirements[7]. Along with the layering of information, the timing of notices should also be designed to be at setup, just in time of the user’s action, or at periodic intervals. In terms of visuals, infographics can be used to depict data flows in a system. Another best practice is to integrate privacy notices with the rest of the system. Designers are needed to be involved early in the process so that the design decisions are not purely visual but also consider information architecture, content design, and research.
Practice based frameworks should be developed for communication designers in order to have a standardised vocabulary around creating privacy notices. Additionally, multiple user groups and their varied privacy preferences must be taken into account. Finally, an ethical framework must be put into place for design practitioners in order to ensure that the users’ well being is prioritised, and notices are designed to facilitate informed consent. Further recommendations and concerns regarding the design of privacy notices, and the use of visuals can be read here.
Justice Srikrishna’s statement is an important step towards creating effective privacy notices with visuals. The conversation on the need to design privacy notices can lead to clearer and more comprehensible notices. Combined with the enforcement of fair collection and use of data by companies, well designed notices will allow users more control and a real choice to opt-in or out of a service and make informed choices as they engage with a service. Justice Srikrishna’s analogy seems to recommend using visuals to describe what type of data is being collected and for what purposes at the time of taking consent. Though cigarette warnings may not be the most appropriate analogy, this is a good start, and it is important to explore how visuals and design can be used throughout a service - from beginning to end - to convey and promote awareness and informed choices by users. It is also important to extend this conversation outside of privacy into the realm of security and understand how visuals and design can inform users’ awareness and personal choices around security when using a service.
[1] https://www.bloomberg.com/news/articles/2018-06-10/tech-giants-nervous-as-judge-drafts-first-data-rules-in-india
[2] http://www.ijdesign.org/index.php/IJDesign/article/viewFile/1512/584
[3] https://www.andrew.cmu.edu/user/pgl/psosm2013.pdf
[4] https://www.heinz.cmu.edu/~acquisti/papers/acquisti-privacy-nudging.pdf
[5] https://www.heinz.cmu.edu/~acquisti/papers/acquisti-privacy-nudging.pdf
[6] https://cis-india.org/internet-governance/files/rethinking-privacy-principles
[7] https://www.informationpolicycentre.com/uploads/5/7/1/0/57104281/ten_steps_to_develop_a_multilayered_privacy_notice__white_paper_march_2007_.pdf
ICANN response to DIDP #31 on diversity
The file can be found here
In our 31st DIDP request, we had asked ICANN to disclose information pertaining to the diversity of employees based on their race and citizenship. ICANN states that they are an equal opportunities employer and to ascertain the extent of people from different backgrounds in their ranks, we were hoping to be given the information.
However the response provided to us did not shed any light on this because of two reasons; firstly, ICANN has this information solely for two countries namely USA and Singapore as legislation in these countries compels employers to record this information. In the US, Title VII of the Civil Rights Act of 1964 requires that any organization with 100 or more employees have to file an Employer Information Report wherein the employment data is categorized by race/ethnicity/, gender and job category. Whereas in Singapore, information on race is gathered from the employee to assess which Self-Help group fund an employee should contribute to under Singaporean law.
Secondly, for the two countries, they refused to divulge information on the basis of their conditions of nondisclosure. The conditions pertinent here were:
- Information provided by or to a government or international organization, or any form of recitation of such information, in the expectation that the information will be kept confidential and/or would or likely would materially prejudice ICANN's relationship with that party.
- Personnel, medical, contractual, remuneration, and similar records relating to an individual's personal information, when the disclosure of such information would or likely would constitute an invasion of personal privacy, as well as proceedings of internal appeal mechanisms and investigations.
- Drafts of all correspondence, reports, documents, agreements, contracts, emails, or any other forms of communication
We had only enquired about the percentage of representation of employees at each level by their race or citizenship but this was deemed dangerous to disclose by ICANN. They did not volunteer anymore information such as an anonymized data set and hence we will now file a DIDP to ask them for the same.
Given the global and multi-stakeholder nature of the processes at ICANN, it is also of importance that their workforce represents true diversity as well. Their bylaws mandate diversity amongst its Board of Directors and some of its constituent bodies but there is no concrete proof of this being imbibed within their recruitment ICANN also did not think it was necessary to disclose our requested information in the benefit of public interest because it does not outweigh the harm that could be caused by the requested disclosure.
DNA ‘Evidence’: Only Opinion, Not Science, And Definitely Not Proof Of Crime!
The article was published in Bloomberg Quint on August 20, 2018.
Though taking some steps in the right direction such as formalising the process for lab accreditation, the Bill ignores many potential cases of ‘harm’ that may arise out of the collection, databasing, and using DNA evidence for criminal and civil purposes.
DNA evidence is widely touted as the most accurate forensic tool, but what is not widely publicised is it is not infallible. From crime scene to database, it is extremely vulnerable to a number of different unknown variables and outcomes. These variables are only increasing as the technology becomes more precise – profiles can be developed from only a few cells and technology now exists that generates a profile in 90 minutes. Primary and secondary transfer, contamination, incomplete samples, too many mixed samples, and inaccurate or outdated methods of analysis and statistical methodologies that may be used, are all serious reasons as to why DNA evidence may paint an innocent person guilty.
Importantly, DNA itself is not static and predicting how it may have changed over time is virtually impossible.
Innocent, But Charged
In April 2018, WIRED carried a story of Lukis Anderson who was charged with the first-degree murder of Raveesh Kumra, a Silicon Valley investor after investigators found Anderson’s DNA on Kumra’s nails. Long story short – Anderson earlier that day had been intoxicated in public and had been attended by paramedics. The same paramedics handled Kumra’s body and inadvertently transferred Anderson’s DNA to Kumra’s body. The story quotes some sobering facts that research has found about DNA:
- Direct contact is not necessary for DNA to be transferred. In an experiment with a group of individuals sharing a bottle of juice, 50 percent had another’s DNA on their hand and ⅓rd of the glasses contained DNA from individuals that did not have direct contact with them.
- An average person sheds 50 million skin cells a day.
- Standing still our DNA can travel over a yard away and will be easily carried over miles on others clothing or hair, for example not very differently from pollen.
- In an experiment that tested public items, it was found that items can contain DNA from a half-dozen people.
- A friendly or inadvertent contact can transfer DNA to private regions or clothing.
- Different people shed detritus at different levels that contain DNA.
- One in five has some other person’s DNA under the fingernails on a continuous basis.

In another case, the police in Idaho, USA, used a public DNA database to run a familial DNA search – a technique used to identify suspects whose DNA is not recorded in a law enforcement database, but whose close relatives have had their genetic profiles cataloged, just as India's DNA Bill seeks to do. The partial match that resulted implicated Michael Usry, the son of the man whose DNA was in the public database. It took 33 days for Michael to be cleared of the crime. That an innocent man only spent 33 days under suspicion could be considered a positive outcome when compared to the case of Josiah Sutton who spent four years convicted of rape in prison due to misinterpretation of DNA samples by the Houston Police Department Crime Laboratory, which is among the largest public forensic centers in Texas. The Atlantic called this out as “The False Promise of DNA Testing – the forensic technique is becoming ever more common and ever less reliable”.
Presently, there is little confidence that such safeguards exist – prosecutors do not share any exculpatory evidence with the accused and India does not even follow the ‘fruit of a poisonous tree’ doctrine with respect to the admissibility of evidence and India has yet to develop a robust jurisprudence for evaluating scientific evidence.
The 2015 Law Commission Report cites four cases that speak to the role and reliance on expert opinion as evidence. Though these cases point to the importance of expert opinion they differ on the weight that should be given to the same. International best practice requires the submission of corroborating evidence, training law enforcement, and court officers, and ensuring that prosecution and defence have equal access to forensic evidence.
Consider India with a population of 1.3 billion people – 70 percent mostly residing in rural areas and less educated and a heavy migrant population in urban centres, an overwhelmed police force in nascent stages of forensic training, and an overburdened judiciary and no concrete laws to govern issues of the admissibility of forensic techniques.
In such circumstances, the question is not only how many criminals can be convicted but also how many innocents could be convicted.

A pair of standard issue handcuffs sits on a table. (Photographer: Jerome Favre/Bloomberg)
The DNA Bill seeks to establish DNA databanks at the regional and national level but how this will be operationalised is not quite clear. The Bill enables the DNA Regulatory Board to accredit DNA labs. Will databases be built from scratch? Will they begin by pulling in existing databases?
The question is not if the DNA samples match but how they came to match. The greater power that comes from the use of DNA databases requires greater responsibility in ensuring adequate information, process, training, and laws are in place for everyone – those who give DNA, collect DNA, store DNA, process DNA, present DNA, and eventually decide on the use of the DNA. As India matures in its use of DNA evidence for forensic purposes it is important that it keeps at the forefront what is necessary to ensure and protect the rights of the individual.
Elonnai Hickok Chief Operating Officer at The Centre for Internet and Society. Murali Neelakantan is an expert in healthcare laws, and the author of ‘DNA Testing as Evidence - A Judge’s Nightmare’ in the Journal of Law and Medicine.
An Analysis of the CLOUD Act and Implications for India
Introduction
Networked technologies have changed the nature of crime and will continue to do so. Access to data generated by digital technologies and on digital platforms is important in solving online and offline crimes. Yet, a significant amount of such data is stored predominantly under the control of companies in the United States. Thus, for Indian law enforcement to access metadata (location data or subscriber information), they can send a request directly to the company. However for access to content data, law enforcement must follow the MLAT process as a result of requirements under the Electronic Communications Privacy Act (ECPA). ECPA allows service providers to share metadata on request of foreign governments, but requires a judicially issued warrant based on a finding of ‘probable cause’ for a service provider to share content data.
The challenges associated with accessing data across borders has been an area of concern for India for many years. From data localization requirements, legal decryption mandates, proposed back doors- law enforcement and the government have consistently been trying to find efficient ways to access data across borders.
Towards finding solutions to the challenges in the MLAT process, Peter Swire and Deven Desai in the article “A Qualified SPOC Approach for India and Mutual Legal Assistance” have noted the importance of finding a solution to the hurdles in the India - US MLAT and have suggested that reforms for the MLAT process in India should not start with law enforcement, and have instead proposed the establishment of a Single Point of Contact designated to handle and process government to government requests with requests emerging from that office receiving special legal treatment.
Frustrations with cross border sharing of data are not unique to India and the framework has been recognized by many stakeholders for being outdated, slow, and inefficient - giving rise to calls from governments, law enforcement, and companies for solutions. As a note, some research has also highlighted that the identified issues with the MLAT system are broad and more evidence is needed to support each concern and inform policy response.
Towards this, the US and EU have undertaken clear policy steps to address the tensions in the MLAT system by enabling direct access by governments to content data. On April 17 2018, the European Union published the E-Evidence Directive and a Regulation that allows for a law enforcement agency to obtain electronic evidence from service providers within 10 days of receiving a request or 6 hours for emergency requests and request the preservation or production of data. Production orders for content and transactional records can be issued only for certain serious crimes and must be issued by a judge. No judicial authorisation is required for production orders for subscriber information and access data, and it can be sought to investigate any criminal offense, not just serious offenses. Preservation orders can be issued without judicial authorisation for all four types of data and for the investigation of any crime. Further, requests originating from the European Union must be handled by a designated legal representative. Preservation orders can be issued for all four types of data. Further, requests originating from the European Union must be handled by a designated legal representative.
On the US side, in 2016, the Department of Justice (DoJ) put out draft legislation that would create a framework allowing the US to enter into executive agreements with countries that have been evaluated as meeting criteria defined in the law. Our response to the DoJ draft Bill can be found here. In February 2018, the Microsoft Ireland Case was presented before the U.S Supreme Court. The question central to the case was whether or not a US warrant issued against a company incorporated in the US was valid if the data was stored in servers outside of the US. On March 23, 2018, the United States government enacted the “Clarifying Lawful Overseas Use of Data Act” also known as the CLOUD Act. The passing of the Act solves the dilemma found in the Microsoft Ireland case. The CLOUD Act amends Title 18 of the United States Code and allows U.S. law enforcement agencies to access data stored abroad by increasing the reach of the U.S. Stored Communication Act, enabling access without requiring the specific cooperation of foreign governments. Under this law, U.S. law enforcement agencies can seek or issue orders that compel companies to provide data regardless of where the data is located as long as the data is under their “possession, custody or control”. It further allows US communication service providers to intercept or provide the content of communications in response to orders from foreign governments if the foreign government has entered into an executive agreement with the US upon approval by the Attorney General and concurrence with the Secretary of State. The Act also absolves companies from criminal and civil liability when disclosing information in good faith pursuant to an executive agreement between the US and a foreign country. Such access would be reciprocal, with the US government having similar access rights to data stored in the foreign country.
Though the E-Evidence Directive is a significant development, in this article - we focus on the CLOUD Act and its implications for cross border sharing of data between India and the US.
To read more download the PDF
Consumer Care Society: Silver Jubilee Year Celebrations
CONSUMER CARE SOCIETY (CCS) is an active volunteer based not-for-profit organization involved in Consumer activities. Established as a registered society in the year 1994, CCS has for the past 3 decades functioned as the voice of consumer in many forums. Today CCS is widely recognized as an premier consumer voluntary organization (CVO) in Bangalore and Karnataka. CCS is registered with many goverenmental agencies and regulators like TRAI,BIS, Petroleum and Natural Gas Regulatory Board, DOT, ICMR at the Central Government levels and with almost all service providers at the State Level like BWSSB, BESCOM, BDA, BBMP.
Shreenivas.S. Galgali, ITS, Adviser, TRAI Regional Office, Bangalore and Aradhana Biradar, User Education and Research Specialist, Google were the other speakers at the event held at CCS.
The Srikrishna Committee Data Protection Bill and Artificial Intelligence in India
Privacy Considerations in AI
Other related privacy concerns in the context of AI center around re-identification and de-anonymisation, discrimination, unfairness, inaccuracies, bias, opacity, profiling, and misuse of data and imbedded power dynamics.[1]
The need for large amounts of data to improve accuracy, the ability to process vast amounts of granular data, and the present relationship between explainability and result of AI systems[2] have raised many concerns on both sides of the fence. On one hand, there is concern that heavy handed or inappropriate regulation will result in stifling innovation. If developers can only use data for pre-defined purpose - the prospects of AI are limited. On the other hand, individuals are concerned that privacy will be significantly undermined in light of AI systems that collect and process data in realtime and at a personal level not previously possible. Chatbots, house assistants, wearable devices, robot caregivers, facial recognition technology etc. have the ability to collect data from a person at an intimate level. At the sametime, some have argued that AI can work towards protecting privacy by limiting the access that humans working at respective companies have to personal data.[3]
India is embracing AI. Two national roadmaps for AI were released in 2018 respectively by the Ministry of Commerce and Industry and Niti Aayog. Both roadmaps emphasized the importance of addressing privacy concerns in the context of AI and ensuring that a robust privacy legislation is enacted. In August 2018, the Srikrishna Committee released a draft Personal Data Protection Bill 2018 and the associated report that outlines and justifies a framework for privacy in India. As the development and use of AI in India continues to grow, it is important that India simultaneously moves forward with a privacy framework that addresses the privacy dimensions of AI.
In this article we attempt to analyse if and how the Srikrishna committee draft Bill and report has addressed AI, contrast this with developments in the EU and the passing of the GDPR, and identify solutions that are being explored towards finding a way to develop AI while upholding and safeguarding privacy.
The GDPR and Artificial Intelligence
The General Data Protection Regulation became enforceable in May 2018 and establishes a framework for the processing of personal data for individuals within the European Union. The GDPR has been described by IAAP as taking a ‘risk based’ approach to data protection that pushes data controllers to engage in risk analysis and adopt ‘risk measured responses’.[4] Though the GDPR does not explicitly address artificial intelligence, it does have a number of provisions that address automated decision making and profiling and a number of provisions that will impact companies using artificial intelligence in their business activities. These have been outlined below:
- Data rights: The GDPR enables individuals with a number of data rights: the right to be informed, right of access, right to rectification, right to erasure, right to restrict processing, right to data portability, right to object, and rights related to automated decision making including profiling. The last right - rights related to automated decision making - seeks to address concerns arising out of automated decision making by giving the individual the right to request to not be subject to a decision based solely on automated decision making including profiling if the decision would produce legal effects or similarly significantly affects them. There are three exceptions to this right - if the automated decision making is: a. necessary for the performance of a contract, b. authorised by the Union or Member State c. is based on explicit consent.[5]
- Transparency: Under Article 14, data controllers must enable the right to opt out of automated decision making by notifying individuals of the existence of automated decision making including profiling and providing meaningful information about the logic involved as well as the potential consequences of such processing.[6] Importantly, this requirement has the potential of ensuring that companies do not operate complete ‘black box’ algorithms within their business processes.
- Fairness: The principle of fairness found under Article 5(1) will also apply to the processing of personal data by AI. The principle requires that personal data must be processed in a way to meet the three conditions of lawfully, fairly, and in a transparent manner in relation to the data subject. Recital 71 further clarifies that this will include implementing appropriate mathematical and statistical measures for profiling, ensuring that inaccuracies are corrected, and ensuring that processing that does not result in negative discriminatory results.[7]
- Purpose Limitation: The principle of purpose limitation (Article 5(1)(b) requires that personal data must be collected for specified, explicit, and legitimate purposes and not be further processed in a manner incompatible with those purposes. Processing for archiving purposes in the public interest, scientific or historical research purposes or statistical purposes are not considered to be incompatible with the initial purposes. It has been noted that it is unclear if research carried out through artificial intelligence would fall under this exception as the GDPR does not define ‘scientific purposes’.[8]
- Privacy by Design and Default: Article 25 requires all data controllers to implement technical and organizational measures to meet the requirements of the regulation. This could include techniques like pseudonymisation. Data controllers also are required to implement appropriate technical and organizational measures for ensuring that by default only personal data which are necessary for a specific purpose are processed.[9]
- Data Protection Impact Assessments: Article 35 requires data controllers to undertake impact assessments if they are undertaking processing that is likely to result in a high risk to individuals. This includes if the data controller undertakes: systematic and extensive profiling, processes special categories of criminal offence data on a large scale, systematically monitor publicly accessible places on a large scale. In implementation, some jurisdictions like the UK require impact assessments on additional conditions including if the data controller: uses new technologies, uses profiling or special category data to decide on access to services, profile individuals on a large scale, process biometric data, process genetic data, match data or combine datasets from different sources, collect personal data from a source other than the individual without providing them with a privacy notice, track individuals’ location or behaviour, profile children or target marketing or online services at them, process data that might endanger the individual’s physical health or safety in the event of a security breach.[10]
- Security: Article 30 requires data controllers to ensure a level of security appropriate to the risk including employing methods like encryption and pseudonymization.
Srikrishna Committee Bill and AI
The Draft Data Protection Bill and associated report by the Srikrishna Committee was published in August 2018 and recommends a privacy framework for India. The Bill contains a number of provisions that will directly impact data fiduciaries using AI and that try and account for the unintended consequences of emerging technologies like AI. These include:
- Definition of Harm: The Bill defines harm as including bodily or mental injury, loss, distortion or theft of identity, financial loss or loss of property, loss of reputation or humiliation, loss of employment, any discriminatory treatment, any subjection to blackmail or extortion, any denial or withdrawal of a service, benefit or good resulting from an evaluative decision about the data principal, any restriction placed or suffered directly or indirectly on speech, movement or any other action arising out of a fear of being observed or surveilled, any observation or surveillance that is not reasonably expected by the data principal. The Bill also allows for categories of significant harm to be further defined by the data protection authority.
Many of the above are harms that have been associated with artificial intelligence - specifically loss employment, discriminatory treatment, and denial of service. Enabling the data protection authority to further define categories of significant harm, could allow for unexpected harms arising from the use of AI to come under the ambit of the Bill.
- Data Rights: Like the GDPR, the Bill creates a set of data rights for the individual including the right to confirmation and access, correction, data portability, and right to be forgotten. At the sametime the Bill is intentionally silent on the rights and obligations that have been incorporated into the GDPR that address automated decision making including: The right to object to processing,[11] the right to opt out of automated decision making[12], and the obligation on the data controller to inform the individual about the use of automated decision making and basic information regarding the logic and impact of same.[13] As justification, in their report the Committee noted the following: The right to restrict processing may be unnecessary in India as it provides only interim remedies around issues such as inaccuracy of data and the same can be achieved by a data principal approaching the DPA or courts for a stay on processing as well as simply withdraw consent. The objective of protecting against discrimination, bias, and opaque decisions that the right to object to automated processing and receive information about the processing of data in the Indian context seeks to fulfill would be better achieved through an accountability framework requiring specific data fiduciaries that will be making evaluative decisions through automated means to set up processes that ‘weed out’ discrimination. At the same time, if discrimination has taken place, individuals can seek remedy through the courts.
By taking this approach, the Bill creates a framework to address harms arising out of AI, but does not empower the individual to decide how their data is processed and remains silent on the issue of ‘black box’ algorithms.
- Data Quality: Requires data fiduciaries to ensure that personal data that is processed is complete, accurate, not misleading and updated with respect to the purposes for which it is processed. When taking steps to comply with this - data fiduciaries must take into consideration if the personal data is likely to be used to make a decision about the data principal, if it is likely to be disclosed to other individuals, if the personal data is kept in a form that distinguishes personal data based on facts from personal data based on opinions or personal assessments.[14]
This principle, while not mandating that data fiduciaries take into account considerations such as biases in datasets, could potentially be be interpreted by the data protection authority to include in its scope, means towards ensuring that data does not contain or result in bias.
- Principle of Privacy by Design: Requires significant data fiduciaries to have in place a number policies and measures around several aspects of privacy. These include - (a) measures to ensure managerial, organizational, business practices and technical systems are designed in a manner to anticipate, identify, and avoid harm to the data principal (b) the obligations mentioned in Chapter II are embedded in organisational and business practices (c) technology used in the processing of personal data is in accordance with commercially accepted or certified standards (d) legitimate interests of business including any innovation is achieved without compromising privacy interests (e) privacy is protected throughout processing from the point of collection to deletion of personal data (f) processing of personal data is carried out in a transparent manner (g) the interest of the data principal is accounted for at every stage of processing of personal data.
A number of these (a, d, e, and g) require that the interest of the data principal is accounted for throughout the processing of personal data, This will be significant for systems driven by artificial intelligence as a number of the harms that have arisen from the use of AI include discrimination, denial of service, or loss of employment - have been brought under the definition of harm within the Bill. Placing the interest of the data principal first is also important in protecting against unintended consequences or harms that may arise from AI.[15] If enacted, it will be important to see what policies and measures emerge in the context of AI to comply with this principle. It will also be important to see what commercially accepted or certified standard companies rely on to comply with (c.)
- Data Protection Impact Assessment: Requires data fiduciaries to undertake a data protection impact assessment when implementing new technologies or large scale profiling or use of sensitive personal data. Such assessments need to include a detailed description of the proposed processing operation, the purpose of the processing and the nature of personal data being processed, an assessment of the potential harm that may be caused to the data principals whose personal data is proposed to be processed, and measures for managing, minimising, mitigating or removing such risk of harm. If the Authority finds that the processing is likely to cause harm to the data principles, it may direct the data fiduciary to undertake processing in certain circumstances or entirely. This requirement applies to all significant data fiduciaires and all other data fiduciaries as required by the DPA.[16]
This principle will apply to companies implementing AI systems. For AI systems, it will be important to see how much information the DPA will require under the requirement of data fiduciaries providing detailed descriptions of the proposed processing operation and purpose of processing.
- Classification of data fiduciaries as significant data fiduciaries: The Authority has the ability to notify certain categories of data fiduciaries as significant data fiduciaries based on 1. The volume of personal data processed, 2. The sensitivity of personal data processed, turnover of the data fiduciary, risk of harm resulting from any processing being undertaken by the fiduciary, use of new technologies for processing, and other factor relevant for causing harm to any data principal. If a data fiduciary falls under the ambit of any of these conditions they are required to register with the Authority. All significant data fiduciaries must undertake data protection impact assessments, maintain records as per the bill, under go data audits, and have in place a data protection officer.
As per this provision - companies deploying artificial intelligence would come under the definition of a significant data fiduciary and be subject to the principles of privacy by design etc. articulated in the chapter. The exception to this will be if the data fiduciary comes under the definition of ‘small entity’ found in section 48.[17]
- Restrictions on cross border transfer of personal data: Requires that all data fiduciaries must store a copy of personal data on a server or data centre located in India and notified categories of critical personal data must be processed in servers located in India.
It is interesting to note that in the context of cross border sharing of data, the Bill is creating a new category of data that can be further defined beyond personal and sensitive personal data. For companies implementing artificial intelligence, this provision may prove cumbersome to comply with as many utilize cloud storage and facilities located outside of India for the processing of larger amounts of data.[18]
- Powers and functions of the Authority: The Bill lays down a number of functions of the Authority one being to monitor technological developments and commercial practices that may affect protection of personal data.
By assumption, this will include monitoring of technological developments in the field of Artificial Intelligence.[19]
- Fair and reasonable processing: Requires that any person processing personal data owes a duty to the data principal to process such personal data in a fair and reasonable manner that respects the privacy of the data principal. In the Srikrishna Committee report, the committee explains that the principle of the fair and reasonable is meant to address 1. Power asymmetries between data subjects and data fiduciaries - recognizing that data fiduciaires have a responsibility to act in the best interest of the data principal 2. Situations where processing may be legal but not necessary fair or in the best interest of the data principal 3. Developing trust between the data principal and the data fiduciary.[20]
This is in contrast to the GDPR which requires processing to simultaneously meet the three conditions of fairness, lawfulness, and transparency.
- Purpose Limitation: Personal data can only be processed for the purposes specified or any other purpose that the data principal would reasonably expect.
As a note, the Srikrishna Committee Bill does not include ‘scientific purposes’ as an exception to the principle of purpose limitation as found in the GDPR,[21] and instead creates an exception for research, archiving, or statistical purposes.[22] The DPA has the responsibility of developing codes defining research purposes under the act.[23]
- Security Safeguards: Every data fiduciary must implement appropriate security safeguards including the use of methods such as de-identification and encryption, steps to protect the integrity of personal data, and steps necessary to prevent misuse, unauthorised access to, modification, and disclosure or destruction of personal data.[24]
Unlike the GDPR which explicitly refers to the technique of pseudonymization, the Srikrishna uses Bill uses term de-identification. The Srikrishna Report clarifies that the this includes techniques like pseudonymization and masking and further clarifies that because of the risk of re-identification, de-identified personal data should still receive the same level of protection as personal data. The Bill further gives the DPA the authority to define appropriate levels of anonymization. [25]
Technical perspectives of Privacy and AI
There is an emerging body of work that is looking at solutions to the dilemma of maintaining privacy while employing artificial intelligence and finding ways in which artificial intelligence can support and strengthen privacy. For example, there are AI driven platforms that leverage the technology to help a business to meet regulatory compliance with data protection laws[26], as well as research into AI privacy enhancing technologies.[27] Standards setting bodies like IEEE have undertaken work on the ethical considerations in the collection and use of personal data when designing, developing, and/or deploying AI through the standard ‘Ethically Aligned Design’.[28] . In the article Artificial Intelligence and Privacy by Datatilsynet - the Norwegian Data Protection Authority[29] break such methods into three categories:
- Techniques for reducing the need for large amounts of training data: Such techniques can include
- Generative adversarial networks (GANs): GANs are used to create synthetic data and can address the need for large volumes of labelled data without relying on real data containing personal data. GANs could potentially be useful from a research and development perspective in sectors like healthcare where most data would quality as sensitive personal data.
- Federated Learning: Federated learning allows for models to be trained and improved on data from a large pool of users without directly using user data. This is achieved by running a centralized model on a client unit and subsequently improved on local data. Changes from the improvements are shared back with the centralized server. An average of the changes from multiple individual client units becomes the basis for improving the centralized model.
- Matrix Capsules: Proposed by Google researcher Geoff Hinton, Matrix Capsules improve the accuracy of existing neural networks while requiring less data.[30]
- Techniques that uphold data protection without reducing the basic data set
- Differential Privacy: Differential privacy intentionally adds ‘noise’ to data when accessed. This allows for personal data to be accessed with revealing identifying information.
- Homomorphic Encryption: Homomorphic encryption allows for the processing of data while it is still encrypted. This addresses the need to access and use large amounts of personal data for multiple purposes
- Transfer Learning: Instead of building a new model, transfer learning relies builds upon existing models that are applied to new related purposes or tasks. This has the potential to reduce the amount of training data needed.
- RAIRD: Developed by Statistics Norway and the Norwegian Centre for Research Data, RAIRD is a national research infrastructure that allows for access to large amounts of statistical data for research while managing statistical confidentiality. This is achieved by allowing researchers access to metadata. The metadata is used to build analyses which are then run against detailed data without giving access to actual data.[31]
- Techniques to move beyond opaque algorithms
- Explainable AI (XAI): DARPA in collaboration with Oregon State University is researching how to create explainable models and explanation interface while ensuring a high level of learning performance in order to enable individuals to interact with, trust, and manage artificial intelligence.[32] DARPA identifies a number of entities working on different models and interfaces for analytics and autonomy AI.[33]
- Local Interpretable Model Agnostic Explanations: Developed to enable trust between AI models and humans by generating explainers to highlight key aspects that were important to the model and its decision - thus providing insight into the rationale behind a model.[34]
Public Sector use of AI and Privacy
The role of AI in public sector decision making has been gradually growing globally across sectors such as law enforcement, education, transportation, judicial decision making and healthcare. In India too, use of automated processing in electronic governance under the Digital India mission, domestic law enforcement agencies monitoring social media content and educational schemes is being discussed and gradually implemented. Much like the potential applications of AI across sub-sectors, the nature of regulatory issues are also diverse.
Aside from the accountability framework discussed in the Srikrishna Committee report, the Puttaswamy judgment also provides a basis for governance of AI with respect to its concerns for privacy, in limited contexts. The sources of right to privacy as articulated in the Puttaswamy judgments included the terms ‘personal liberty’ under Article 21 of the Constitution. In order to fully appreciate how constitutional principles could apply to automated processing in India, we need to look closely at the origins of privacy under liberty. In the famous case of AK Gopalan there is a protracted discussion on the contents of the rights under Article 21. Amongst the majority opinions itself, the opinion was divided. While Sastri J. and Mukherjea J. took the restrictive view that limiting the protections to bodily restraint and detention, Kania J. and Das J. take a broader view for it to include the right to sleep, play etc. Through RC Cooper[35] and Maneka[36], the Supreme Court took steps to reverse the majority opinion in Gopalan and it was established that that the freedoms and rights in Part III could be addressed by more than one provision. The expansion of ‘personal liberty’ has began in Kharak Singh where the unjustified interference with a person’s right to live in his house, was held to be violative of Article 21. The reasoning in Kharak Singh draws heavily from Munn v. Illinois[37] which held life to be “more than mere animal existence.” Curiously, after taking this position Kharak Singh fails to recognise a fundamental right to privacy (analogous to the Fourth Amendment protection in US) under Article 21. The position taken in Kharak Singh was to extrapolate the same method of wide interpretation of ‘personal liberty’ as was accorded to ‘life’. Maneka which evolved the test for enumerated rights within Part III says that the claimed right must be an integral part of or of the the same nature as the named right. It says that the claimed must be ‘in reality and substance nothing but an instance of the exercise of the named fundamental right’. The clear reading of privacy into ‘personal liberty’ in this judgment is effectively a correction of the inherent inconsistencies in the positions taken by the majority in Kharak Singh.
The other significant change in constitutional interpretation that occurred in Maneka was with respect to the phrase ‘procedure established by law’ in Article 21. In Gopalan, the majority held that the phrase ‘procedure established by law’ does not mean procedural due process or natural justice. What this meant was that, once a ‘procedure’ was ‘established by law’, Article 21 could not be said to have been infringed. This position was entirely reversed in Maneka. The ratio in Maneka said that ‘procedure established by law’ must be fair, just and reasonable, and cannot be arbitrary and fanciful. Therefore, any infringement of the right to privacy must be through a law which follows the principles of natural justice, and is not arbitrary or unfair. It follows that any instances of automated processing for public functioning by state actors or others, must meet this standard of ‘fair, just and reasonable’.
While there is a lot of focus internationally on what ethical AI must be, it is important that when we consider use of AI by the state, we pay heed to the existing constitutional principles which determine how AI must be evaluated against these standards. These principles however extend only to limited circumstances for protections under Article 21 are not horizontal in nature but only applicable against the state. Whether a party is the state or not is a question that has been considered several times by the Supreme Court and must be determined by functional tests. In our submission of the Justice Srikrishna Committee, we clearly recommended that where automated decision making is used for discharging of public functions, the data protection law must state that such actions are subject the the constitutional standards and are ‘just, fair and reasonable’ and satisfy the tests for both procedural and substantive due process. To a limited extent, the committee seems to have picked up the standards of ‘fair’ and ‘reasonable’ and made it applicable to all forms of processing, whether public or private. It is as yet unclear whether fairness and reasonableness as inserted in the bill would draw from the constitutional standard under Article 21. The report makes a reference to the twin principles of acting in a manner that upholds the best interest of the privacy of the individual, and processing within the reasonable expectations of the individual, which do not seem to cover the fullest essence of the legal standard under Article 21.
Conclusion
The Srikrishna Committee Bill attempts to create an accountability framework for the use of emerging technologies including AI that is focused on placing the responsibility on companies to prevent harm. Though not as robust as found in the GDPR, the protections have been enabled through requirements such as fair and reasonable processing, ensuring data quality, and implementing principles of privacy of design. At the sametime, the Srikrishna Bill does not include provisions that can begin to address the consumer facing ‘black box’ of AI by ensuring that individuals have information about the potential impact of decisions taken by automated means. In contrast, the GDPR has already taken important steps to tackle this by requiring companies to explain the logic and potential impact of decisions taken by automated means.
Most importantly, the Bill gives the Data Protection Authority the necessary tools to hold companies accountable for the use of AI through the requirements of data protection audits. If enacted, it will have to be seen how these audits and the principle of privacy by design are implemented and enforced in the context of companies using AI. Though the Bill creates a Data Protection Authority consisting of members that have significant experience in data protection, information technology, data management, data science, cyber and internet laws, and related subjects, these requirements can be further strengthened by having someone from a background of ethics and human rights.
One of the responsibilities of the DPA under the Srikrishna Bill will be to monitor technological developments and commercial practices that may affect protection of personal data and promote measures and undertake research for innovation in the field of protection of personal data. If enacted, we hope that AI and solutions towards enhancing privacy in the context of AI like described above will be one of these focus areas of the DPA. It will also be important to see how the DPA develops impact assessments related to AI and what tools associated with the principle of Privacy by Design emerge to address AI.
[1] https://privacyinternational.org/topics/artificial-intelligence
[2] https://www.wired.com/story/our-machines-now-have-knowledge-well-never-understand/
[3] https://iapp.org/news/a/ai-offers-opportunity-to-increase-privacy-for-users/
[4] https://iapp.org/media/pdf/resource_center/GDPR_Study_Maldoff.pdf
[5] https://gdpr-info.eu/art-22-gdpr/
[6] https://gdpr-info.eu/art-14-gdpr/
[7] https://www.datatilsynet.no/globalassets/global/english/ai-and-privacy.pdf
[8] https://www.datatilsynet.no/globalassets/global/english/ai-and-privacy.pdf
[9] https://gdpr-info.eu/art-25-gdpr/
[10] https://ico.org.uk/for-organisations/guide-to-the-general-data-protection-regulation-gdpr/accountability-and-governance/data-protection-impact-assessments/
[11] https://gdpr-info.eu/art-21-gdpr/
[12] https://gdpr-info.eu/art-22-gdpr/
[13] https://gdpr-info.eu/art-14-gdpr/
[14]Draft Data Protection Bill 2018 - Chapter II section 9
[15] Draft Data Protection Bill 2018 - Chapter VII section 29
[16] Draft Data Protection Bill 2018 - Chapter VII section 33
[17] Draft Data Protection Bill 2018 - Chapter VII section 38
[18] Draft Data Protection Bill 2018 - Chapter VIII section 40
[19] Draft Data Protection Bill 2018 - Chapter X section 60
[20] Draft Data Protection Bill 2018 - Chapter II section 4
[21] Draft Data Protection Bill 2018 - Chapter II section 5
[22] Draft Data Protection Bill 2018 - Chapter IX Section 45
[23] Draft Data Protection Bill 2018 - Chapter XIV section 97
[24] Draft Data Protection Bill 2018 - Chapter VII section 31
[25] Srikrishna Committee Report on Data Protection pg. 36 and 37. Available at: http://www.prsindia.org/uploads/media/Data%20Protection/Committee%20Report%20on%20Draft%20Personal%20Data%20Protection%20Bill,%202018.pdf
[26] https://www.ciosummits.com/Online_Assets_DocAuthority_Whitepaper_-_Guide_to_Intelligent_GDPR_Compliance.pdf
[27] https://jolt.law.harvard.edu/assets/articlePDFs/v31/31HarvJLTech217.pdf
[28] https://standards.ieee.org/content/dam/ieee-standards/standards/web/documents/other/ead_personal_data_v2.pdf
[29] https://www.datatilsynet.no/globalassets/global/english/ai-and-privacy.pdf
[30] https://www.artificial-intelligence.blog/news/capsule-networks
[31] http://raird.no/about/factsheet.html
[32] https://www.darpa.mil/attachments/XAIProgramUpdate.pdf
[33] https://www.darpa.mil/attachments/XAIProgramUpdate.pdf
[34] https://www.oreilly.com/learning/introduction-to-local-interpretable-model-agnostic-explanations-lime
[35] R C Cooper v. Union of India, 1970 SCR (3) 530.
[36] Maneka Gandhi v. Union of India, 1978 SCR (2) 621.
[37] 94 US 113 (1877).
AI in India: A Policy Agenda
Click to download the file
Background
Over the last few months, the Centre for Internet and Society has been engaged in the mapping of use and impact of artificial intelligence in health, banking, manufacturing, and governance sectors in India through the development of a case study compendium.[1] Alongside this research, we are examining the impact of Industry 4.0 on jobs and employment and questions related to the future of work in India. We have also been a part of several global conversations on artificial intelligence and autonomous systems. The Centre for Internet and Society is part of the Partnership on Artificial Intelligence, a consortium which has representation from some of most important companies and civil society organisations involved in developments and research on artificial intelligence. We have contributed to the The IEEE Global Initiative on Ethics of Autonomous and Intelligent Systems, and are also a part of a Big Data for Development Global Network, where we are undertaking research towards evolving ethical principles for use of computational techniques. The following are a set of recommendations we have arrived out of our research into artificial intelligence, particularly the sectoral case studies focussed on the development and use of artificial intelligence in India.
National AI Strategies: A Brief Global Overview
Artificial Intelligence is emerging as a central policy issue in several countries. In October 2016, the Obama White House released a report titled, “Preparing for the Future of Artificial Intelligence”[2] delving into a range of issues including application for public goods, regulation, economic impact, global security and fairness issues. The White House also released a companion document called the “National Artificial Intelligence Research and Development Strategic Plan”[3] which laid out a strategic plan for Federally-funded research and development in AI. These were the first of a series of policy documents released by the US towards the role of AI. The United Kingdom announced its 2020 national development strategy and issued a government report to accelerate the application of AI by government agencies while in 2018 the Department for Business, Energy, and Industrial Strategy released the Policy Paper - AI Sector Deal.[4] The Japanese government released it paper on Artificial Intelligence Technology Strategy in 2017.[5] The European Union launched "SPARC," the world’s largest civilian robotics R&D program, back in 2014.[6]
Over the last year and a half, Canada,[7] China,[8] the UAE,[9] Singapore,[10] South Korea[11], and France[12] have announced national AI strategy documents while 24 member States in the EU have committed to develop national AI policies that reflect a “European” approach to AI [13]. Other countries such as Mexico and Malaysia are in the process of evolving their national AI strategies. What this suggests is that AI is quickly emerging as central to national plans around the development of science and technology as well as economic and national security and development. There is also a focus on investments enabling AI innovation in critical national domains as a means of addressing key challenges facing nations. India has followed this trend and in 2018 the government published two AI roadmaps - the Report of Task Force on Artificial Intelligence by the AI Task Force constituted by the Ministry of Commerce and Industry[14] and the National Strategy for Artificial Intelligence by Niti Aayog.[15] Some of the key themes running across the National AI strategies globally are spelt out below.
Economic Impact of AI
A common thread that runs across the different national approaches to AI is the belief in the significant economic impact of AI, that it will likely increase productivity and create wealth. The British government estimated that AI could add $814 billion to the UK economy by 2035. The UAE report states that by 2031, AI will help boost the country’s GDP by 35 per cent, reduce government costs by 50 per cent. Similarly, China estimates that the core AI market will be worth 150 billion RMB ($25bn) by 2020, 400 billion RMB ($65bn) and one trillion RMB ($160bn) by 2030. The impact of adoption of AI and automation of labour and employment is also a key theme touched upon across the strategies. For instance, the White House Report of October 2016 states the US workforce is unprepared – and that a serious education programme, through online courses and in-house schemes, will be required.[16]
State Funding
Another key trend exhibited in all national strategies towards AI has been a commitment by the respective governments towards supporting research and development in AI. The French government has stated that it intends to invest €1.5 billion ($1.85 billion) in AI research in the period through to 2022. The British government’s recommendations, in late 2017, were followed swiftly by a promise in the autumn budget of new funds, including at least £75 million for AI. Similarly, the the Canadian government put together a $125-million ‘pan-Canadian AI strategy’ last year.
AI for Public Good
The use of AI for Public Good is a significant focus of most AI policies. The biggest justification for AI innovation as a legitimate objective of public policy is its promised impact towards improvement of people’s lives by helping to solve some of the world’s greatest challenges and inefficiencies, and emerge as a transformative technology, much like mobile computing. These public good uses of AI are emerging across sectors such as transportation, migration, law enforcement and justice system, education, and agriculture..
National Institutions leading AI research
Another important trend which was key to the implementation of national AI strategies is the creation or development of well-funded centres of excellence which would serve as drivers of research and development and leverage synergies with the private sector. The French Institute for Research in Computer Science and Automation (INRIA) plans to create a national AI research program with five industrial partners. In UK, The Alan Turing Institute is likely to emerge as the national institute for data science, and an AI Council would be set up to manage inter-sector initiatives and training. In Canada, Canadian Institute for Advanced Research (CIFAR) has been tasked with implementing their AI strategy. Countries like Japan has a less centralised structure with the creation of strategic council for AI technology’ to promote research and development in the field, and manage a number of key academic institutions, including NEDO and its national ICT (NICT) and science and tech (JST) agencies. These institutions are key to successful implementation of national agendas and policies around AI.
AI, Ethics and Regulation
Across the AI strategies — ethical dimensions and regulation of AI were highlighted as concerns that needed to be addressed. Algorithmic transparency and explainability, clarity on liability, accountability and oversight, bias and discrimination, and privacy are ethical and regulatory questions that have been raised. Employment and the future of work is another area of focus that has been identified by countries. For example, the US 2016 Report reflected on if existing regulation is adequate to address risk or if adaption is needed by examining the use of AI in automated vehicles. In the policy paper - AI Sector Deal - the UK proposes four grand challenges: AI and Data Economy, Future Mobility, Clean Growth, and Ageing Society. The Pan Canadian Artificial Intelligence Strategy focuses on developing global thought leadership on the economic, ethical, policy, and legal implications of advances in artificial intelligence.[17]
The above are important factors and trends to take into account and to different extents have been reflected in the two national roadmaps for AI. Without adequate institutional planning, there is a risk of national strategies being too monolithic in nature. Without sufficient supporting mechanisms in the form of national institutions which would drive the AI research and innovation, capacity building and re-skilling of workforce to adapt to changing technological trends, building regulatory capacity to address new and emerging issues which may disrupt traditional forms of regulation and finally, creation of an environment of monetary support both from the public and private sector it becomes difficult to implement a national strategy and actualize the potentials of AI . As stated above, there is also a need for identification of key national policy problems which can be addressed by the use of AI, and the creation of a framework with institutional actors to articulate the appropriate plan of action to address the problems using AI. There are several ongoing global initiatives which are in the process of trying to articulate key principles for ethical AI. These discussions also feature in some of the national strategy documents.
Key considerations for AI policymaking in India
As mentioned above, India has published two national AI strategies. We have responded to both of these here[18] and here.[19] Beyond these two roadmaps, this policy brief reflects on a number of factors that need to come together for India to leverage and adopt AI across sectors, communities, and technologies successfully.
Resources, Infrastructure, Markets, and Funding
Ensure adequate government funding and investment in R&D
As mentioned above, a survey of all major national strategies on AI reveals a significant financial commitment from governments towards research and development surrounding AI. Most strategy documents speak of the need to safeguard national ambitions in the race for AI development. In order to do so it is imperative to have a national strategy for AI research and development, identification of nodal agencies to enable the process, and creation of institutional capacity to carry out cutting edge research.
Most jurisdictions such as Japan, UK and China have discussed collaborations between the industry and government to ensure greater investment into AI research and development. The European Union has spoken using the existing public-private partnerships, particularly in robotics and big data to boost investment by over one and half times.[20] To some extent, this step has been initiated by the Niti Aayog strategy paper. The paper lists out enabling factors for the widespread adoption of AI and maps out specific government agencies and ministries that could promote such growth. In February 2018, the Ministry of Electronics and IT also set up four committees to prepare a roadmap for a national AI programme. The four committees are presently studying AI in context of citizen centric services; data platforms; skilling, reskilling and R&D; and legal, regulatory and cybersecurity perspectives.[21]
Democratize AI technologies and data
Clean, accurate, and appropriately curated data is essential for training algorithms. Importantly, large quantities of data alone does not translate into better results. Accuracy and curation of data should be prerequisites to quantity of data. Frameworks to generate and access larger quantity of data should not hinge on models of centralized data stores. The government and the private sector are generally gatekeepers to vast amounts of data and technologies. Ryan Calo has called this an issue of data parity,[22] where only a few well established leaders in the field have the ability to acquire data and build datasets. Gaining access to data comes with its own questions of ownership, privacy, security, accuracy, and completeness. There are a number of different approaches and techniques that can be adopted to enable access to data.
Open Government Data
Robust open data sets is one way in which access can be enabled. Open data is particularly important for small start-ups as they build prototypes. Even though India is a data dense country and has in place a National Data and Accessibility Policy India does not yet have robust and comprehensive open data sets across sectors and fields. Our research found that this is standing as an obstacle to innovation in the Indian context as startups often turn to open datasets in the US and Europe for developing prototypes. Yet, this is problematic because the demography represented in the data set is significantly different resulting in the development of solutions that are trained to a specific demographic, and thus need to be re-trained on Indian data. Although AI is technology agnostic, in the cases of different use cases of data analysis, demographically different training data is not ideal. This is particularly true for certain categories such as health, employment, and financial data.
The government can play a key role in providing access to datasets that will help the functioning and performance of AI technologies. The Indian government has already made a move towards accessible datasets through the Open Government Data Platform which provides access to a range of data collected by various ministries. Telangana has developed its own Open Data Policy which has stood out for its transparency and the quality of data collected and helps build AI based solutions.
In order to encourage and facilitate innovation, the central and state governments need to actively pursue and implement the National Data and Accessibility Policy.
Access to Private Sector Data
The private sector is the gatekeeper to large amounts of data. There is a need to explore different models of enabling access to private sector data while ensuring and protecting users rights and company IP. This data is often considered as a company asset and not shared with other stakeholders. Yet, this data is essential in enabling innovation in AI.
Amanda Levendowski states that ML practitioners have essentially three options in securing sufficient data— build the databases themselves, buy the data, or use data in the public domain. The first two alternatives are largely available to big firms or institutions. Smaller firms often end resorting to the third option but it carries greater risks of bias.
A solution could be federated access, with companies allowing access to researchers and developers to encrypted data without sharing the actual data. Another solution that has been proposed is ‘watermarking’ data sets.
Data sandboxes have been promoted as tools for enabling innovation while protecting privacy, security etc. Data sandboxes allow companies access to large anonymized data sets under controlled circumstances. A regulatory sandbox is a controlled environment with relaxed regulations that allow the product to be tested thoroughly before it is launched to the public. By providing certification and safe spaces for testing, the government will encourage innovation in this sphere. This system has already been adopted in Japan where there are AI specific regulatory sandboxes to drive society 5.0.160 data sandboxes are tools that can be considered within specific sectors to enable innovation. A sector wide data sandbox was also contemplated by TRAI.[23] A sector specific governance structure can establish a system of ethical reviews of underlying data used to feed the AI technology along with data collected in order to ensure that this data is complete, accurate and has integrity. A similar system has been developed by Statistics Norway and the Norwegian Centre for Research Data.[24]
AI Marketplaces
The National Roadmap for Artificial Intelligence by NITI Aayog proposes the creation of a National AI marketplace that is comprised of a data marketplace, data annotation marketplace, and deployable model marketplace/solutions marketplace.[25] In particular, it is envisioned that the data marketplace would be based on blockchain technology and have the features of: traceability, access controls, compliance with local and international regulations, and robust price discovery mechanism for data. Other questions that will need to be answered center around pricing and ensuring equal access. It will also be interesting how the government incentivises the provision of data by private sector companies. Most data marketplaces that are emerging are initiated by the private sector.[26] A government initiated marketplace has the potential to bring parity to some of the questions raised above, but it should be strictly limited to private sector data in order to not replace open government data.
Open Source Technology
A number of companies are now offering open source AI technologies. For example, TensorFlow, Keras, Scikit-learn, Microsoft Cognitive Toolkit, Theano, Caffe, Torch, and Accord.NET.[27] The government should incentivise and promote open source AI technologies towards harnessing and accelerating research in AI.
Re-thinking Intellectual Property Regimes
Going forward it will be important for the government to develop an intellectual property framework that encourages innovation. AI systems are trained by reading, viewing, and listening to copies of human-created works. These resources such as books, articles, photographs, films, videos, and audio recordings are all key subjects of copyright protection. Copyright law grants exclusive rights to copyright owners, including the right to reproduce their works in copies, and one who violates one of those exclusive rights “is an infringer of copyright.[28]
The enterprise of AI is, to this extent, designed to conflict with tenets of copyright law, and after the attempted ‘democratization’ of copyrighted content by the advent of the Internet, AI poses the latest challenge to copyright law. At the centre of this challenge is the fact that it remains an open question whether a copy made to train AI is a “copy” under copyright law, and consequently whether such a copy is an infringement.[29] The fractured jurisprudence on copyright law is likely to pose interesting legal questions with newer use cases of AI. For instance, Google has developed a technique called federated learning, popularly referred to as on-device ML, in which training data is localised to the originating mobile device rather than copying data to a centralized server.[30] The key copyright questions here is whether decentralized training data stored in random access memory (RAM) would be considered as “copies”.[31] There are also suggestions that copies made for the purpose of training of machine learning systems may be so trivial or de minimis that they may not qualify as infringement.[32] For any industry to flourish, there needs to be legal and regulatory clarity and it is imperative that these copyright questions emerging out of use of AI be addressed soon.
As noted in our response to the Niti Aayog national AI strategy “The report also blames the current Indian Intellectual Property regime for being “unattractive” and averse to incentivising research and adoption of AI. Section 3(k) of Patents Act exempts algorithms from being patented, and the Computer Related Inventions (CRI) Guidelines have faced much controversy over the patentability of mere software without a novel hardware component. The paper provides no concrete answers to the question of whether it should be permissible to patent algorithms, and if yes, to to what extent. Furthermore, there needs to be a standard either in the CRI Guidelines or the Patent Act, that distinguishes between AI algorithms and non-AI algorithms. Additionally, given that there is no historical precedence on the requirement of patent rights to incentivise creation of AI, innovative investment protection mechanisms that have lesser negative externalities, such as compensatory liability regimes would be more desirable. The report further failed to look at the issue holistically and recognize that facilitating rampant patenting can form a barrier to smaller companies from using or developing AI. This is important to be cognizant of given the central role of startups to the AI ecosystem in India and because it can work against the larger goal of inclusion articulated by the report.”[33]
National infrastructure to support domestic development
Building a robust national Artificial Intelligence solution requires establishing adequate indigenous infrastructural capacity for data storage and processing. While this should not necessarily extend to mandating data localisation as the draft privacy bill has done, capacity should be developed to store data sets generated by indigenous nodal points.
AI Data Storage
Capacity needs to increase as the volume of data that needs to be processed in India increases. This includes ensuring effective storage capacity, IOPS (Input/Output per second) and ability to process massive amounts of data.
AI Networking Infrastructure
Organizations will need to upgrade their networks in a bid to upgrade and optimize efficiencies of scale. Scalability must be undertaken on a high priority which will require a high-bandwidth, low latency and creative architecture, which requires appropriate last mile data curation enforcement.
Conceptualization and Implementation
Awareness, Education, and Reskilling
Encouraging AI research
This can be achieved by collaborations between the government and large companies to promote accessibility and encourage innovation through greater R&D spending. The Government of Karnataka, for instance, is collaborating with NASSCOM to set up a Centre of Excellence for Data Science and Artificial Intelligence (CoE-DS&AI) on a public-private partnership model to “accelerate the ecosystem in Karnataka by providing the impetus for the development of data science and artificial intelligence across the country.” Similar centres could be incubated in hospitals and medical colleges in India. Principles of public funded research such as FOSS, open standards, and open data should be core to government initiatives to encourage research. The Niti Aaayog report proposes a two tier integrated approach towards accelerating research, but is currently silent on these principles.[34]
Therefore,as suggested by the NITI AAYOG Report, the government needs to set up ‘centres of excellence’. Building upon the stakeholders identified in the NITI AAYOG Report, the centers of excellence should involve a wide range of experts including lawyers, political philosophers, software developers, sociologists and gender studies from diverse organizations including government, civil society,the private sector and research institutions to ensure the fair and efficient roll out of the technology.[35] An example is the Leverhulme Centre for the Future of Intelligence set up by the Leverhulme Foundation at the University of Cambridge[36] and the AI Now Institute at New York University (NYU)[37] These research centres bring together a wide range of experts from all over the globe.[38]
Skill sets to successfully adopt AI
Educational institutions should provide opportunities for students to skill themselves to adapt to adoption of AI, and also push for academic programmes around AI. It is also important to introduce computing technologies such as AI in medical schools in order to equip doctors to adopt the technical skill sets and ethics required to use integrate AI in their practices. Similarly, IT institutes could include courses on ethics, privacy, accountability etc. to equip engineers and developers with an understanding of the questions surrounding the technology and services they are developing.
Societal Awareness Building
Much of the discussion around skilling for AI is in the context of the workplace, but there is a need for awareness to be developed across society for a broader adaptation to AI. The Niti Aayog report takes the first steps towards this - noting the importance of highlighting the benefits of AI to the public. The conversation needs to go beyond this towards enabling individuals to recognize and adapt to changes that might be brought about - directly and indirectly - by AI - inside and outside of the workplace. This could include catalyzing a shift in mindset to life long learning and discussion around potential implications of human-machine interactions.
Early Childhood Awareness and Education
It is important that awareness around AI begins in early childhood. This is in part because children already interact with AI and increasingly will do so and thus awareness is needed in how AI works and can be safely and ethically used. It is also important to start building the skills that will be necessary in an AI driven society from a young age.
Focus on marginalised groups
Awareness, skills, and education should be targeted at national minorities including rural communities, the disabled, and women. Further, there should be a concerted focus on communities that are under-represented in the tech sector-such as women and sexual minorities-to ensure that the algorithms themselves and the community working on AI driven solutions are holistic and cohesive. For example, Iridescent focuses on girls, children, and families to enable them to adapt to changes like artificial intelligence through promoting curiosity, creativity, and perseverance to become lifelong learners.[39] This will be important towards ensuring that AI does not deepen societal and global inequalities including digital divides. Widespread use of AI will undoubtedly require re-skilling various stakeholders in order to make them aware of the prospects of AI.[40] Artificial Intelligence itself can be used as a resource in the re-skilling process itself-as it would be used in the education sector to gauge people’s comfort with the technology and plug necessary gaps.
Improved access to and awareness of Internet of Things
The development of smart content or Intelligent Tutoring Systems in the education can only be done on a large scale if both the teacher and the student has access to and feel comfortable with using basic IoT devices . A U.K. government report has suggested that any skilled workforce using AI should be a mix of those with a basic understanding responsible for implementation at the grassroots level , more informed users and specialists with advanced development and implementation skills.[41]The same logic applies to the agriculture sector, where the government is looking to develop smart weather-pattern tracking applications. A potential short-term solution may lie in ensuring that key actors have access to an IoT device so that he/she may access digital and then impart the benefits of access to proximate individuals. In the education sector, this would involve ensuring that all teachers have access to and are competent in using an IoT device. In the agricultural sector, this may involve equipping each village with a set of IoT devices so that the information can be shared among concerned individuals. Such an approach recognizes that AI is not the only technology catalyzing change - for example industry 4.0 is understood as comprising of a suite of technologies including but not limited to AI.
Public Discourse
As solutions bring together and process vast amounts of granular data, this data can be from a variety of public and private sources - from third party sources or generated by the AI and its interaction with its environment. This means that very granular and non traditional data points are now going into decision making processes. Public discussion is needed to understand social and cultural norms and standards and how these might translate into acceptable use norms for data in various sectors.
Coordination and collaboration across stakeholders
Development of Contextually Nuanced and Appropriate AI Solutions
Towards ensuring effectiveness and accuracy it is important that solutions used in India are developed to account for cultural nuances and diversity. From our research this could be done in a number of ways ranging from: training AI solutions used in health on data from Indian patients to account for differences in demographics[42], focussing on natural language voice recognition to account for the diversity in languages and digital skills in the Indian context,[43] and developing and applying AI to reflect societal norms and understandings.[44]
Continuing, deepening, and expanding partnerships for innovation
Continued innovation while holistically accounting for the challenges that AI poses will be key for actors in the different sectors to remain competitive. As noted across case study reports partnerships is key in facilitating this innovation and filling capacity gaps. These partnerships can be across sectors, institutions, domains, geographies, and stakeholder groups. For example: finance/ telecom, public/private, national/international, ethics/software development/law, and academia/civil society/industry/government. We would emphasize collaboration between actors across different domains and stakeholder groups as developing holistics AI solutions demands multiple understandings and perspectives.
Coordinated Implementation
Key sectors in India need to begin to take steps to consider sector wide coordination in implementing AI. Potential stress and system wide vulnerabilities would need to be considered when undertaking this. Sectoral regulators such as RBI, TRAI, and the Medical Council of India are ideally placed to lead this coordination.
Develop contextual standard benchmarks to assess quality of algorithms
In part because of the nacency of the development and implementation of AI, towards enabling effective assessments of algorithms to understand impact and informing selection by institutions adopting solutions, standard benchmarks can help in assessing quality and appropriateness of algorithms. It may be most effective to define such benchmarks at a sectoral level (finance etc.) or by technology and solution (facial recognition etc.). Ideally, these efforts would be led by the government in collaboration with multiple stakeholders.
Developing a framework for working with the private sector for use-cases by the government
There are various potential use cases the government could adopt in order to use AI as a tool for augmenting public service delivery in India by the government. However, given lack of capacity -both human resource and technological-means that entering into partnerships with the private sector may enable more fruitful harnessing of AI- as has been seen with existing MOUs in the agricultural[45] and healthcare sectors.[46] However, the partnership must be used as a means to build capacity within the various nodes in the set-up rather than relying only on the private sector partner to continue delivering sustainable solutions.
Particularly, in the case of use of AI for governance, there is a need to evolve a clear parameter to do impact assessment prior to the deployment of the technology that clearly tries to map estimated impact of the technology of clearly defined objectives, which must also include the due process, procedural fairness and human rights considerations . As per Article 12 of the Indian Constitution, whenever the government is exercising a public function, it is bound by the entire gamut of fundamental rights articulated in Part III of the Constitution. This is a crucial consideration the government will have to bear in mind whenever it uses AI-regardless of the sector. In all cases of public service delivery, primary accountability for the use of AI should lie with the government itself, which means that a cohesive and uniform framework which regulates these partnerships must be conceptualised. This framework should incorporate : (a) Uniformity in the wording and content of contracts that the government signs, (b) Imposition of obligations of transparency and accountability on the developer to ensure that the solutions developed are in conjunction with constitutional standards and (c) Continuous evaluation of private sector developers by the government and experts to ensure that they are complying with their obligations.
Defining Safety Critical AI
The implications of AI differs according to use. Some countries, such as the EU, are beginning to define sectors where AI should play the role of augmenting jobs as opposed to functioning autonomously. The Global Partnership on AI is has termed sectors where AI tools supplement or replace human decision making in areas such as health and transportation as ‘safety critical AI’ and is researching best practices for application of AI in these areas. India will need to think through if there is a threshold that needs to be set and more stringent regulation applied. In addition to uses in health and transportation, defense and law enforcement would be another sector where certain use would require more stringent regulation.
Appropriate certification mechanisms
Appropriate certificate mechanisms will be important in ensuring the quality of AI solutions. A significant barrier to the adoption of AI in some sectors in India is acceptability of results, which include direct results arrived at using AI technologies as well as opinions provided by practitioners that are influenced/aided by AI technologies. For instance, start-ups in the healthcare sectors often find that they are asked to show proof of a clinical trial when presenting their products to doctors and hospitals, yet clinical trials are expensive, time consuming and inappropriate forms of certification for medical devices and digital health platforms. Startups also face difficulty in conducting clinical trials as there is lack of a clear regulation to adhere to. They believe that while clinical trials are a necessity with respect to drugs, the process often results in obsolescence of the technology by the time it is approved in the context of AI. Yet, medical practitioners are less trusting towards startups who do not have approval from a national or international authority. A possible and partial solution suggested by these startups is to enable doctors to partner with them to conduct clinical trials together. However, such partnerships cannot be at the expense of rigour, and adequate protections need to be built in the enabling regulation.
Serving as a voice for emerging economies in the global debate on AI
While India should utilise Artificial Intelligence in the economy as a means of occupying a driving role in the global debate around AI, it must be cautious before allowing the use of Indian territory and infrastructure as a test bed for other emerging economies without considering the ramifications that the utilisation of AI may have for Indian citizens. The NITI AAYOG Report envisions India as leverage AI as a ‘garage’ for emerging economies.[47] While there are certain positive connotations of this suggestion in so far as this propels India to occupy a leadership position-both technically and normatively in determining future use cases for AI in India,, in order to ensure that Indian citizens are not used as test subjects in this process, guiding principles could be developed such as requiring that projects have clear benefits for India.
Frameworks for Regulation
National legislation
Data Protection Law
India is a data-dense country, and the lack of a robust privacy regime, allows the public and private sector easier access to large amounts of data than might be found in other contexts with stringent privacy laws. India also lacks a formal regulatory regime around anonymization. In our research we found that this gap does not always translate into a gap in practice, as some start up companies have adopted self-regulatory practices towards protecting privacy such as of anonymising data they receive before using it further, but it does result in unclear and unharmonized practice..
In order to ensure rights and address emerging challenges to the same posed by artificial intelligence, India needs to enact a comprehensive privacy legislation applicable to the private and public sector to regulate the use of data, including use in artificial intelligence. A privacy legislation will also have to address more complicated questions such as the use of publicly available data for training algorithms, how traditional data categories (PI vs. SPDI - meta data vs. content data etc.) need to be revisited in light of AI, and how can a privacy legislation be applied to autonomous decision making. Similarly, surveillance laws may need to be revisited in light of AI driven technologies such as facial recognition, UAS, and self driving cars as they provide new means of surveillance to the state and have potential implications for other rights such as the right to freedom of expression and the right to assembly. Sectoral protections can compliment and build upon the baseline protections articulated in a national privacy legislation.[48] In August 2018 the Srikrishna Committee released a draft data protection bill for India. We have reflected on how the Bill addresses AI. Though the Bill brings under its scope companies deploying emerging technologies and subjects them to the principles of privacy by design and data impact assessments, the Bill is silent on key rights and responsibilities, namely the responsibility of the data controller to explain the logic and impact of automated decision making including profiling to data subjects and the right to opt out of automated decision making in defined circumstances.[49] Further, the development of technological solutions to address the dilemma between AI and the need for access to larger quantities of data for multiple purposes and privacy should be emphasized.
Discrimination Law
A growing area of research globally is the social consequences of AI with a particular focus on its tendency to replicate or amplify existing and structural inequalities. Problems such as data invisibility of certain excluded groups,[50] the myth of data objectivity and neutrality,[51] and data monopolization[52] contribute to the disparate impacts of big data and AI. So far much of the research on this subject has not moved beyond the exploratory phase as is reflected in the reports released by the White House[53] and Federal Trade Commission[54] in the United States. The biggest challenge in addressing discriminatory and disparate impacts of AI is ascertaining “where value-added personalization and segmentation ends and where harmful discrimination begins.”[55]
Some prominent cases where AI can have discriminatory impact are denial of loans based on attributes such as neighbourhood of residence as a proxies which can be used to circumvent anti-discrimination laws which prevent adverse determination on the grounds of race, religion, caste or gender, or adverse findings by predictive policing against persons who are unfavorably represented in the structurally biased datasets used by the law enforcement agencies. There is a dire need for disparate impact regulation in sectors which see the emerging use of AI.
Similar to disparate impact regulation, developments in AI, and its utilisation, especially in credit rating, or risk assessment processes could create complex problems that cannot be solved only by the principle based regulation. Instead, regulation intended specifically to avoid outcomes that the regulators feel are completely against the consumer, could be an additional tool that increases the fairness, and effectiveness of the system.
Competition Law
The conversation of use of competition or antitrust laws to govern AI is still at an early stage. However, the emergence of numerous data driven mergers or acquisitions such as Yahoo-Verizon, Microsoft-LinkedIn and Facebook-WhatsApp have made it difficult to ignore the potential role of competition law in the governance of data collection and processing practices. It is important to note that the impact of Big Data goes far beyond digital markets and the mergers of companies such as Bayer, Climate Corp and Monsanto shows that data driven business models can also lead to the convergence of companies from completely different sectors as well. So far, courts in Europe have looked at questions such as the impact of combination of databases on competition[56] and have held that in the context of merger control, data can be a relevant question if an undertaking achieves a dominant position through a merger, making it capable of gaining further market power through increased amounts of customer data. The evaluation of the market advantages of specific datasets has already been done in the past, and factors which have been deemed to be relevant have included whether the dataset could be replicated under reasonable conditions by competitors and whether the use of the dataset was likely to result in a significant competitive advantage.[57] However, there are limited circumstances in which big data meets the four traditional criteria for being a barrier to entry or a source of sustainable competitive advantage — inimitability, rarity, value, and non-substitutability.[58]
Any use of competition law to curb data-exclusionary or data-exploitative practices will first have to meet the threshold of establishing capacity for a firm to derive market power from its ability to sustain datasets unavailable to its competitors. In this context the peculiar ways in which network effects, multi-homing practices and how dynamic the digital markets are, are all relevant factors which could have both positive and negative impacts on competition. There is a need for greater discussion on data as a sources of market power in both digital and non-digital markets, and how this legal position can used to curb data monopolies, especially in light of government backed monopolies for identity verification and payments in India.
Consumer Protection Law
The Consumer Protection Bill, 2015, tabled in the Parliament towards the end of the monsoon session has introduced an expansive definition of the term “unfair trade practices.” The definition as per the Bill includes the disclosure “to any other person any personal information given in confidence by the consumer.” This clause excludes from the scope of unfair trade practices, disclosures under provisions of any law in force or in public interest. This provision could have significant impact on the personal data protection law in India. Alongside, there is also a need to ensure that principles such as safeguarding consumers personal information in order to ensure that the same is not used to their detriment are included within the definition of unfair trade practices. This would provide consumers an efficient and relatively speedy forum to contest adverse impacts on them of data driven decision-making.
Sectoral Regulation
Our research into sectoral case studies revealed that there are a number of existing sectoral laws and policies that are applicable to aspects of AI. For example, in the health sector there is the Medical Council Professional Conduct, Etiquette, and Ethics Regulations 2002, the Electronic Health Records Standards 2016, the draft Medical Devices Rules 2017, the draft Digital Information Security in Healthcare Act. In the finance sector there is the Credit Information Companies (Regulation) Act 2005 and 2006, the Securities and Exchange Board of India (Investment Advisers) Regulations, 2013, the Payment and Settlement Systems Act, 2007, the Banking Regulations Act 1949, SEBI guidelines on robo advisors etc. Before new regulations, guidelines etc are developed - a comprehensive exercise needs to be undertaken at a sectoral level to understand if 1. sectoral policy adequately addresses the changes being brought about by AI 2. If it does not - is an amendment possible and if not - what form of policy would fill the gap.
Principled approach
Transparency
Audits
Internal and external audits can be mechanisms towards creating transparency about the processes and results of AI solutions as they are implemented in a specific context. Audits can take place while a solution is still in ‘pilot’ mode and on a regular basis during implementation. For example, in the Payment Card Industry (PCI) tool, transparency is achieved through frequent audits, the results of which are simultaneously and instantly transmitted to the regulator and the developer. Ideally parts of the results of the audit are also made available to the public, even if the entire results are not shared.
Tiered Levels of Transparency
There are different levels and forms of transparency as well as different ways of achieving the same. The type and form of transparency can be tiered and dependent on factors such as criticality of function, potential direct and indirect harm, sensitivity of data involved, actor using the solution . The audience can also be tiered and could range from an individual user to senior level positions, to oversight bodies.
Human Facing Transparency
It will be important for India to define standards around human-machine interaction including the level of transparency that will be required. Will chatbots need to disclose that they are chatbots? Will a notice need to be posted that facial recognition technology is used in a CCTV camera? Will a company need to disclose in terms of service and privacy policies that data is processed via an AI driven solution? Will there be a distinction if the AI takes the decision autonomously vs. if the AI played an augmenting role? Presently, the Niti Aayog paper has been silent on this question.
Explainability
An explanation is not equivalent to complete transparency. The obligation of providing an explanation does not mean that the developer should necessarily know the flow of bits through the AI system. Instead, the legal requirement of providing an explanation requires an ability to explain how certain parameters may be utilised to arrive at an outcome in a certain situation.
Doshi-Velez and Kortz have highlighted two technical ideas that may enhance a developer's ability to explain the functioning of AI systems:[59]
1) Differentiation and processing: AI systems are designed to have the inputs differentiated and processed through various forms of computation-in a reproducible and robust manner. Therefore, developers should be able to explain a particular decision by examining the inputs in an attempt to determine which of them have the greatest impact on the outcome.
2) Counterfactual faithfulness: The second property of counterfactual faithfulness enables the developer to consider which factors caused a difference in the outcomes. Both these solutions can be deployed without necessarily knowing the contents of black boxes. As per Pasquale, ‘Explainability matters because the process of reason-giving is intrinsic to juridical determinations – not simply one modular characteristic jettisoned as anachronistic once automated prediction is sufficiently advanced.”[60]
Rules based system applied contextually
Oswald et al have suggested two proposals that might mitigate algorithmic opacity.by designing a broad rules-based system, whose implementation need to be applied in a context-specific manner which thoroughly evaluates the key enablers and challengers in each specific use case.[61]
- Experimental proportionality was designed to enable the courts to make proportionality determinations of an algorithm at the experimental stage even before the impacts are fully realised in a manner that would enable them to ensure that appropriate metrics for performance evaluation and cohesive principles of design have been adopted. In such cases they recommend that the courts give the benefit of the doubt to the public sector body subject to another hearing within a stipulated period of time once data on the impacts of the algorithm become more readily available.
- ‘ALGO-CARE' calls for the design of a rules-based system which ensures that the algorithms[62] are:
(1) Advisory: Algorithms must retain an advisory capacity that augments existing human capability rather than replacing human discretion outright;
(2) Lawful: Algorithm's proposed function, application, individual effect and use of datasets should be considered in symbiosis with necessity, proportionality and data minimisation principles;
(3) Granularity: Issues such as data analysis issues such as meaning of data, challenges stemming from disparate tracts of data, omitted data and inferences should be key points in the implementation process;
(4) Ownership: Due regard should be given to intellectual property ownership but in the case of algorithms used for governance, it may be better to have open source algorithms at the default. Regardless of the sector,the developer must ensure that the algorithm works in a manner that enables a third party to investigate the workings of the algorithm in an adversarial judicial context.
(5)Challengeable:The results of algorithmic analysis should be applied with regard to professional codes and regulations and be challengeable. In a report evaluating the NITI AAYOG Discussion Paper, CIS has argued that AI that is used for governance , must be made auditable in the public domain,if not under Free and Open Source Software (FOSS)-particularly in the case of AI that has implications for fundamental rights.[63]
(6) Accuracy: The design of the algorithm should check for accuracy;
(7) Responsible: Should consider a wider set of ethical and moral principles and the foundations of human rights as a guarantor of human dignity at all levels and
(8) Explainable: Machine Learning should be interpretable and accountable.
A rules based system like ALGO-CARE can enable predictability in use frameworks for AI. Predictability compliments and strengthens transparency.
Accountability
Conduct Impact Assessment
There is a need to evolve Algorithmic Impact Assessment frameworks for the different sectors in India, which should address issues of bias, unfairness and other harmful impacts of use of automated decision making. AI is a nascent field and the impact of the technology on the economy, society, etc. is still yet to be fully understood. Impact assessment standards will be important in identifying and addressing potential or existing harms and could potentially be more important in sectors or uses where there is direct human interaction with AI or power dimensions - such as in healthcare or use by the government. A 2018 Report by the AI Now Institute lists methods that should be adopted by the government for conducting his holistic assessment[64]: These should include: (1) Self-assessment by the government department in charge of implementing the technology, (2)Development of meaningful inter-disciplinary external researcher review mechanisms, (3) Notice to the public regarding self-assessment and external review, (4)Soliciting of public comments for clarification or concerns, (5) Special regard to vulnerable communities who may not be able to exercise their voice in public proceedings. An adequate review mechanism which holistically evaluates the impact of AI would ideally include all five of these components in conjunction with each other.
Regulation of Algorithms
Experts have voiced concerns about AI mimicking human prejudices due to the biases present in the Machine Learning algorithms. Scientists have revealed through their research that machine learning algorithms can imbibe gender and racial prejudices which are ingrained in language patterns or data collection processes. Since AI and machine algorithms are data driven, they arrive at results and solutions based on available
and historical data. When this data itself is biased, the solutions presented by the AI will also be biased. While this is inherently discriminatory, scientists have provided solutions to rectify these biases which can occur at various stages by introducing a counter bias at another stage. It has also been suggested that data samples should be shaped in such a manner so as to minimise the chances of algorithmic bias. Ideally regulation of algorithms could be tailored - explainability, traceability, scrutability. We recommend that the national strategy on AI policy must take these factors into account and combination of a central agency driving the agenda, and sectoral actors framing regulations around specific uses of AI that are problematic and implementation is required.
As the government begins to adopt AI into governance - the extent to which and the circumstances autonomous decision making capabilities can be delegated to AI need to be questioned. Questions on whether AI should be autonomous, should always have a human in the loop, and should have a ‘kill-switch’ when used in such contexts also need to be answered. A framework or high level principles can help to guide these determinations. For example:
- Modeling Human Behaviour: An AI solution trying to model human behaviour, as in the case of judicial decision-making or predictive policing may need to be more regulated, adhere to stricter standards, and need more oversight than an algorithm that is trying to predict ‘natural’ phenomenon such as traffic congestion or weather patterns.
- Human Impact: An AI solution which could cause greater harm if applied erroneously-such as a robot soldier that mistakenly targets a civilian requires a different level and framework of regulation than an AI solution designed to create a learning path for a student in the education sector and errs in making an appropriate assessment..
- Primary User: AI solutions whose primary users are state agents attempting to discharge duties in the public interest such as policemen, should be approached with more caution than those used by individuals such as farmers getting weather alerts
Fairness
It is possible to incorporate broad definitions of fairness into a wide range of data analysis and classification systems.[65] While there can be no bright-line rules that will necessarily enable the operator or designer of a Machine Learning System to arrive at an ex ante determination of fairness, from a public policy perspective, there must be a set of rules or best practices that explain how notions of fairness should be utilised in the real world applications of AI-driven solutions.[66] While broad parameters should be encoded by the developer to ensure compliance with constitutional standards, it is also crucial that the functioning of the algorithm allows for an ex-post determination of fairness by an independent oversight body if the impact of the AI driven solution is challenged.
Further, while there is no precedent on this anywhere in the world, India could consider establishing a Committee entrusted with the specific task of continuously evaluating the operation of AI-driven algorithms. Questions that the government would need to answer with regard to this body include:
- What should the composition of the body be?
- What should be the procedural mechanisms that govern the operation of the body?
- When should the review committee step in? This is crucial because excessive review may re-entrench the bureaucracy that the AI driven solution was looking to eliminate.
- What information will be necessary for the review committee to carry out its determination? Will there be conflicts with IP, and if so how will these be resolved?
- To what degree will the findings of the committee be made public?
- What powers will the committee have? Beyond making determinations, how will these be enforced?
Market incentives
Standards as a means to address data issues
With digitisation of legacy records and the ability to capture more granular data digitally, one of the biggest challenges facing Big Data is a lack of standardised data and interoperability frameworks. This is particularly true in the healthcare and medicine sector where medical records do not follow a clear standard, which poses a challenge to their datafication and analysis. The presence of developed standards in data management and exchange, interoperable Distributed Application Platform and Services, Semantic related standards for markup, structure, query, semantics, Information access and exchange have been spoken of as essential to address the issues of lack of standards in Big Data.[67]
Towards enabling usability of data, it is important that clear data standards are established. This has been recognized by Niti Aayog in its National Strategy for AI. On one hand, there can operational issues with allowing each organisation to choose their own specific standards to operate under, while on the other hand, non-uniform digitisation of data will also cause several practical problems, most primarily to do with interoperability of the individual services, as well as their usability. For instance, in the healthcare sector, though India has adopted an EHR policy, implementation of this policy is not yet harmonized - leading to different interpretations of ‘digitizing records (i.e taking snapshots of doctor notes), retention methods and periods, and comprehensive implementation across all hospital data. Similarly, while independent banks and other financial organisations are already following, or in the process of developing internal practices,there exist no uniform standards for digitisation of financial data. As AI development, and application becomes more mainstream in the financial sector, the lack of a fixed standard could create significant problems.
Better Design Principles in Data Collection
An enduring criticism of the existing notice and consent framework has been that long, verbose and unintelligible privacy notices are not efficient in informing individuals and helping them make rational choices. While this problem predates Big Data, it has only become more pronounced in recent times, given the ubiquity of data collection and implicit ways in which data is being collected and harvested. Further, constrained interfaces on mobile devices, wearables, and smart home devices connected in an Internet of Things amplify the usability issues of the privacy notices. Some of the issues with privacy notices include Notice complexity, lack of real choices, notices decoupled from the system collecting data etc. An industry standard for a design approach to privacy notices which includes looking at factors such as the timing of the notice, the channels used for communicating the notices, the modality (written, audio, machine readable, visual) of the notice and whether the notice only provides information or also include choices within its framework, would be of great help. Further, use of privacy by design principles can be done not just at the level of privacy notices but at each step of the information flow, and the architecture of the system can be geared towards more privacy enhanced choices.
[1] https://cis-india.org/internet-governance/blog/artificial-intelligence-in-india-a-compendium
[2] https://obamawhitehouse.archives.gov/sites/default/files/whitehouse_files/microsites/ostp/NSTC/preparing_for_the_future_of_ai.pdf
[3] https://www.nitrd.gov/PUBS/national_ai_rd_strategic_plan.pdf
[4] https://www.gov.uk/government/publications/artificial-intelligence-sector-deal/ai-sector-deal
[5] http://www.nedo.go.jp/content/100865202.pdf
[6] https://www.eu-robotics.net/sparc/10-success-stories/european-robotics-creating-new-markets.html?changelang=2
[7] https://www.cifar.ca/ai/pan-canadian-artificial-intelligence-strategy
[8] https://www.newamerica.org/cybersecurity-initiative/blog/chinas-plan-lead-ai-purpose-prospects-and-problems/
[10] https://www.aisingapore.org/
[11] https://news.joins.com/article/22625271
[12] https://www.aiforhumanity.fr/pdfs/MissionVillani_Report_ENG-VF.pdf
[13] https://ec.europa.eu/digital-single-market/en/news/communication-artificial-intelligence-europe https://www.euractiv.com/section/digital/news/twenty-four-eu-countries-sign-artificial-intelligence-pact-in-bid-to-compete-with-us-china/
[14] https://www.aitf.org.in/
[15] http://www.niti.gov.in/writereaddata/files/document_publication/NationalStrategy-for-AI-Discussion-Paper.pdf
[16] https://obamawhitehouse.archives.gov/sites/default/files/whitehouse_files/microsites/ostp/NSTC/preparing_for_the_future_of_ai.pdf
[17] https://www.cifar.ca/ai/pan-canadian-artificial-intelligence-strategy
[18] https://cis-india.org/internet-governance/blog/the-ai-task-force-report-the-first-steps-towards-indias-ai-framework
[19] https://cis-india.org/internet-governance/blog/niti-aayog-discussion-paper-an-aspirational-step-towards-india2019s-ai-policy
[20] https://ec.europa.eu/digital-single-market/en/news/communication-artificial-intelligence-europe
[21] http://pib.nic.in/newsite/PrintRelease.aspx?relid=181007
[22] Ryan Calo, 2017 Artificial Intelligence Policy: A Primer and Roadmap. U.C. Davis L. Review,
Vol. 51, pp. 398 - 435.
[23] https://trai.gov.in/sites/default/files/CIS_07_11_2017.pdf
[24] https://www.datatilsynet.no/globalassets/global/english/ai-and-privacy.pdf
[25] http://www.niti.gov.in/writereaddata/files/document_publication/NationalStrategy-for-AI-Discussion-Paper.pdf
[26] https://martechtoday.com/bottos-launches-a-marketplace-for-data-to-train-ai-models-214265
[27] https://opensource.com/article/18/5/top-8-open-source-ai-technologies-machine-learning
[28] Amanda Levendowski, How Copyright Law Can Fix Artificial Intelligence’s
Implicit Bias Problem, 93 WASH. L. REV. (forthcoming 2018) (manuscript at 23, 27-32),
https://papers.ssrn.com/sol3/papers.cfm?abstract_id=3024938.
[29] Id.
[30] H. Brendan McMahan, et al., Communication-Efficient Learning of Deep Networks
from Decentralized Data, arXiv:1602.05629 (Feb. 17, 2016), https://arxiv.org/abs/1602.05629.
[31] Id.
[32] Pierre N. Leval, Nimmer Lecture: Fair Use Rescued, 44 UCLA L. REV. 1449, 1457 (1997).
[33] https://cis-india.org/internet-governance/blog/niti-aayog-discussion-paper-an-aspirational-step-towards-india2019s-ai-policy
[34] https://cis-india.org/internet-governance/blog/niti-aayog-discussion-paper-an-aspirational-step-towards-india2019s-ai-policy
[35] Discussion Paper on National Strategy for Artificial Intelligence | NITI Aayog | National Institution for Transforming India. (n.d.) p. 54. Retrieved from http://niti.gov.in/content/national-strategy-ai-discussion-paper.
[36] Leverhulme Centre for the Future of Intelligence, http://lcfi.ac.uk/.
[37] AI Now, https://ainowinstitute.org/.
[38] https://cis-india.org/internet-governance/ai-and-governance-case-study-pdf
[39] http://iridescentlearning.org/
[40] https://cis-india.org/internet-governance/ai-and-governance-case-study-pdf
[41] Points, L., & Potton, E. (2017). Artificial intelligence and automation in the UK.
[42] Paul, Y., Hickok, E., Sinha, A. and Tiwari, U., Artificial Intelligence in the Healthcare Industry in India, Centre for Internet and Society. Available at https://cis-india.org/internet-governance/files/ai-and-healtchare-report.
[43] Goudarzi, S., Hickok, E., and Sinha, A., AI in the Banking and Finance Industry in India, Centre for Internet and Society. Available at https://cis-india.org/internet-governance/blog/ai-in-banking-and-finance.
[44] Paul, Y., Hickok, E., Sinha, A. and Tiwari, U., Artificial Intelligence in the Healthcare Industry in India, Centre for Internet and Society. Available at https://cis-india.org/internet-governance/files/ai-and-healtchare-report.
[45] https://news.microsoft.com/en-in/government-karnataka-inks-mou-microsoft-use-ai-digital-agriculture/
[46] https://news.microsoft.com/en-in/government-telangana-adopts-microsoft-cloud-becomes-first-state-use-artificial-intelligence-eye-care-screening-children/
[47] NITI Aayog. (2018). Discussion Paper on National Strategy for Artificial Intelligence. Retrieved from http://niti.gov.in/content/national-strategy-ai-discussion-paper. 18
[48] https://edps.europa.eu/sites/edp/files/publication/16-10-19_marrakesh_ai_paper_en.pdf
[49] https://cis-india.org/internet-governance/blog/the-srikrishna-committee-data-protection-bill-and-artificial-intelligence-in-india
[50] J. Schradie, The Digital Production Gap: The Digital Divide and Web 2.0 Collide. Elsevier Poetics, 39 (1).
[51] D Lazer, et al., The Parable of Google Flu: Traps in Big Data Analysis. Science. 343 (1).
[52] Danah Boyd and Kate Crawford, Critical Questions for Big Data. Information, Communication & Society. 15 (5).
[53] John Podesta, (2014) Big Data: Seizing Opportunities, Preserving Values, available at
http://www.whitehouse.gov/sites/default/files/docs/big_data_privacy_report_may_1_2014.pdf
[54] E. Ramirez, (2014) FTC to Examine Effects of Big Data on Low Income and Underserved Consumers at September Workshop, available at http://www.ftc.gov/news-events/press-releases/2014/04/ftc-examine-effects-big-data-lowincome-underserved-consumers
[55] M. Schrage, Big Data’s Dangerous New Era of Discrimination, available at http://blogs.hbr.org/2014/01/bigdatas-dangerous-new-era-of-discrimination/.
[56] Google/DoubleClick Merger case
[57] French Competition Authority, Opinion n°10-A-13 of 1406.2010,
http://www.autoritedelaconcurrence.fr/pdf/avis/10a13.pdf. That opinion of the Authority aimed at
giving general guidance on that subject. It did not focus on any particular market or industry
although it described a possible application of its analysis to the telecom industry.
[58] http://www.analysisgroup.com/is-big-data-a-true-source-of-market-power/#sthash.5ZHmrD1m.dpuf
[59] Doshi-Velez, F., Kortz, M., Budish, R., Bavitz, C., Gershman, S., O'Brien, D., ... & Wood, A. (2017). Accountability of AI under the law: The role of explanation. arXiv preprint arXiv:1711.01134.
[60] Frank A. Pasquale ‘Toward a Fourth Law of Robotics: Preserving Attribution, Responsibility, and Explainability in an Algorithmic Society’ (July 14, 2017). Ohio State Law Journal, Vol. 78, 2017; U of Maryland Legal Studies Research Paper No. 2017-21, 7.
[61] Oswald, M., Grace, J., Urwin, S., & Barnes, G. C. (2018). Algorithmic risk assessment policing models: lessons from the Durham HART model and ‘Experimental’ proportionality. Information & Communications Technology Law, 27(2), 223-250.
[62] Ibid.
[63] Abraham S., Hickok E., Sinha A., Barooah S., Mohandas S., Bidare P. M., Dasgupta S., Ramachandran V., and Kumar S., NITI Aayog Discussion Paper: An aspirational step towards India’s AI policy. Retrieved from https://cis-india.org/internet-governance/files/niti-aayog-discussion-paper.
[64] Reisman D., Schultz J., Crawford K., Whittaker M., (2018, April) Algorithmic Impact Assessments: A Practical Framework For Public Agency Accountability. Retrieved from https://ainowinstitute.org/aiareport2018.pdf.
[65] Sample I., (2017, November 5) Computer says no: why making AIs fair, accountable and transparent is crucial. Retrieved from https://www.theguardian.com/science/2017/nov/05/computer-says-no-why-making-ais-fair-accountable-and-transparent-is-crucial.
[66] Kroll, J. A., Barocas, S., Felten, E. W., Reidenberg, J. R., Robinson, D. G., & Yu, H. (2016). Accountable algorithms. U. Pa. L. Rev., 165, 633.
India’s post-truth society
The op-ed was published in Hindu Businessline on September 7, 2018.
After a set of rumours spread over WhatsApp triggered a series of lynchings across the country, the government recently took the interesting step of placing the responsibility for this violence on WhatsApp. This is especially noteworthy because the party in power, as well as many other political parties, have taken to campaigning over social media, including using WhatsApp groups in a major way to spread their agenda and propaganda.
After all, a simple tweet or message could be shared thousands of times and make its way across the country several times, before the next day’s newspaper is out. Nonetheless, while the use of social media has led to a lot of misinformation and deliberately polarising ‘news’, it has also helped contribute to remarkable acts of altruism and community, as seen during the recent Kerala floods.
While the government has taken a seemingly techno-determinist view by placing responsibility on WhatsApp, the duality of very visible uses of social media has led to others viewing WhatsApp and other internet platforms more as a tool, at the mercy of the user. However, as historian Melvin Kranzberg noted, “technology is neither good nor bad; nor is it neutral”. And while the role of political and private parties in spreading polarising views should be rigorously investigated, it is also true that these internet platforms are creating new and sometimes damaging structural changes to how our society functions. A few prominent issues are listed below:
Fragmentation of public sphere
Jurgen Habermas, noted sociologist, conceptualised the Public Sphere as being “a network for communicating information and points of view, where the streams of communication are, in the process, filtered and synthesised in such a way that they coalesce into bundles of topically specified public opinions”.
To a large extent, the traditional gatekeepers of information flow, such as radio, TV and mainstream newspapers, performed functions enabling a public sphere. For example, if a truth-claim about an issue of national relevance was to be made, it would need to get an editor’s approval.
In case there was a counter claim, that too would have to pass an editorial check. Today however, nearly anybody can become a publisher of information online, and if it catches the right ‘influencer’s attention, it could spread far wider and far quicker than it would’ve in traditional media. While this does have the huge positive of giving space to more diverse viewpoints, it also comes with two significant downsides.
First, that it gives a sense of ‘personal space’ to public speech. An ordinary person would think a few times, do some research, and perhaps practice a speech before giving it before 10,000 people. An ordinary person would also think for perhaps five seconds before putting out a tweet on the very same topic, despite now having a potentially global audience.
Second, by having messages sent directly to your hand-held device, rather than open for anyone to fact-check and counter, there is less transparency and accountability for those who send polarising material and misinformation. How can a mistaken and polarising view be countered, if one doesn’t even know it is being made? And if it can’t be countered, how can its spread by contained?
The attention market
Not only is that earlier conception of public sphere being fragmented, these new networked public spheres are also owned by giant corporations. This means that these public spheres where critical discourse is being shaped and spread, are actually governed by advertisement-financed global conglomerates. In a world of information overflow, and privately owned, ad-financed public spheres, the new unit of currency is attention.
It is in the direct interest of the Facebooks and Googles of the world, to capture user attention as long as possible, regardless of what type of activity that encourages. It goes without saying that neither the ‘mundane and ordinary’, nor the ‘nuanced and detailed’ capture people’s attention nearly as well as the sensational and exciting.
Nearly as addicting, studies show, are the headlines and viewpoints which confirm people’s biases. Fed by algorithms that understand the human desire to ‘fit in’, people are lowered into echo chambers where like-minded people find each other and continually validate each other. When people with extremist views are guided to each other by these algorithms, they not only gather validation, but also now use these platforms to confidently air their views — thus normalising what was earlier considered extreme. Needless to say, internet platforms are becoming richer in the process.
Censorship by obfuscation
Censorship in the attention economy, no longer requires blocking of views or interrupting the transmission of information. Rather, it is sufficient to drown out relevant information in an ocean of other information. Fact checking news sites face this problem. Regardless of how often they fact-check speeches by politicians, only a minuscule percentage of the original audience comes to know about, much less care about the corrections.
Additionally, repeated attacks (when baseless) on credibility of news sources causes confusion about which sources are trustworthy. In her extremely insightful book “Twitter and Tear Gas”, Prof Zeynep Tufekci rightly points out that rather than traditional censorship, powerful entities today, (often States) focus on overwhelming people with information, producing distractions, and deliberately causing confusion, fear and doubt. Facts, often don’t matter since the goal is not to be right, but to cause enough confusion and doubt to displace narratives that are problematic to these powers.
Viewpoints from members of groups that have been historically oppressed, are especially harangued. And those who are oppressed tend to have less time, energy and emotional resources to continuously deal with online harassment, especially when their identities are known and this harassment can very easily spill over to the physical world.
Conclusion
Habermas saw the ideal public sphere as one that is free of lies, distortions, manipulations and misinformation. Needless to say, this is a far cry from our reality today, with all of the above available in unhealthy doses. It will take tremendous effort to fix these issues, and it is certainly no longer sufficient for internet platforms to claim they are neutral messengers. Further, whether the systemic changes are understood or not, if they are not addressed, they will continue to create and expand fissures in society, giving the state valid cause for intervening through backdoors, surveillance, and censorship, all actions that states have historically been happy to do!
Artificial Intelligence in the Governance Sector in India
Ecosystem Mapping:Shweta Mohandas and Anamika Kundu
Edited by: Amber Sinha, Pranav MB and Vishnu Ramachandran
Much of the technological capacity and funding for AI in governance in India is coming from the private sector - a trend we expect will continue as the government engages in an increasing number of partnerships with both start-ups and large corporations alike. While there is considerable enthusiasm and desire by the government to develop AI-driven solutions in governance, including the release of two reports identifying the broad contours of India’s AI strategy, this enthusiasm is yet to be underscored by adequate financial, infrastructural, and technological capacity. This gap provides India with a unique opportunity to understand some the of the ethical, legal and technological hurdles faced by the West both during and after the implementation of similar technology and avoid these challenges when devising its own AI strategy and regulatory policy.
The case study identified five sub-sectors including law enforcement, education, defense, discharge of governmental functions and also considered the implications of AI in judicial decision-making processes that have been used in the United States. After mapping the uses of AI in various sub-sectors, this report identifies several challenges to the deployment of this technology. This includes factors such as infrastructural and technological capacity, particularly among key actors at the grassroots level, lack of trust in AI driven solutions and adequate funding. We also identified several ethical and legal concerns that policy-makers must grapple with. These include over-dependence on AI systems, privacy and security, assignment of liability, bias and discrimination both in process and outcome, transparency and due process. Subsequently, this report can be considered as a roadmap for the future of AI in India by tracking corresponding and emerging developments in other parts of the world. In the final section of the report, we propose several recommendations for policy-makers and developers that might address some of the challenges and ethical concerns identified. Some of these include benchmarks for the use of AI in the public sector, development of standards of explanation, a standard framework for engagement with the private sector, leveraging AI as a field to further India’s international strategy, developing adequate standards of data curation, ensuring that the benefits of the technology reaches the lowest common denominator, adopting interdisciplinary approaches to the study of Artificial Intelligence and developing fairness,transparency and due process through the contextual application of a rules-based system.
It is crucial that policy-makers do not adopt a ‘one-size-fits-all’ approach to AI regulation but consider all options within a regulatory spectrum that considers the specific impacts of the deployment of this technology for each sub-sector within governance - with the distinction of public sector use. Given that the governance sector has potential implications for the fundamental rights of all citizens, it is also imperative that the government does not shy away from its obligation to ensure the fair and ethical deployment of this technology while also ensuring the existence of robust redress mechanisms. To do so, it must chart out a standard rules-based system that creates guidelines and standards for private sector development of AI solutions for the public sector. As with other emerging technology, the success of Artificial intelligence depends on whether it is deployed with the intention of placing greater regulatory scrutiny on the daily lives of individuals or for harnessing individual potential that augment rather than counter the core tenets of constitutionalism and human dignity.
Read the full report here
Cross-Border Data Sharing and India: A study in Processes, Content and Capacity
The crux of the issue lies in the age old international law tenet of territorial sovereignty.Investigating crimes is a sovereign act and it cannot be exercised in the territory of another country without that country’s consent or through a permissive principle of extra-territorial jurisdiction. Certain countries have explicit statutory provisions which disallow companies incorporated in their territory from disclosing data to foreign jurisdictions. The United States of America, which houses most of the leading technological firms like Google, Apple, Microsoft, Facebook, and Whatsapp, has this requirement.
This necessitates a consent based international model for cross border data sharing as a completely ad-hoc system of requests for each investigation would be ineffective. Towards this, Mutual Legal Assistance Treaties (MLATs) are the most widely used method for cross border data sharing, with letters rogatory, emergency requests and informal requests being other methods available to most investigators. While recent gambits towards ring-fencing the data within Indian shores might alter the contours of the debate, a sustainable long-term strategy requires a coherent negotiation strategy that enables co-operation with a range of international partners.
This negotiation strategy needs to be underscored by domestic safeguards that ensure human rights guarantees in compliance with international standards, robust identification and augmentation of capacity and clear articulation of how India’s strategy lines up with the existing tenets of International law. This report studies the workings of the Mutual Legal Assistance Treaty (MLAT) between the USA and India and identifies hurdles in its existing form, culls out suggestions for improvement and explores how recent legislative developments, such as the CLOUD Act might alter the landscape.
The path forward lies in undertaking process based reforms within India with an eye on leveraging these developments to articulate a strategically beneficial when negotiating with external partners.As the nature of policing changes to a model that increasingly relies on electronic evidence, India needs to ensure that it’s technical strides made in accessing this evidence is not held back by the lack of an enabling policy environment. While the data localisation provisions introduced in the draft Personal Data Protection Bill may alter the landscape once it becomes law, this paper retains its relevance in terms of guiding the processes, content and capacity to adequately manoeuvre the present conflict of laws situation and accessing data not belonging to Indians that may be needed for criminal investigations.As a disclaimer,the report and graphics contained within it have been drafted using publicly available information and may not reflect real world practices.
Click here to download the report With research assistance from Sarath Mathew and Navya Alam and visualisation by Saumyaa Naidu
A trust deficit between advertisers and publishers is leading to fake news
The article was published in Hindustan Times on September 24, 2018.
Traditionally, we have depended on the private censorship that intermediaries conduct on their platforms. They enforce, with some degree of success, their own community guidelines and terms of services (TOS). Traditionally, these guidelines and TOS have been drafted keeping in mind US laws since historically most intermediaries, including non-profits like Wikimedia Foundation were founded in the US.
Across the world, this private censorship regime was accepted by governments when they enacted intermediary liability laws (in India we have Section 79A of the IT Act). These laws gave intermediaries immunity from liability emerging from third party content about which they have no “actual knowledge” unless they were informed using takedown notices. Intermediaries set up offices in countries like India, complied with some lawful interception requests, and also conducted geo-blocking to comply with local speech regulation.
For years, the Indian government has been frustrated since policy reforms that it has pursued with the US have yielded little fruit. American policy makers keep citing shortcomings in the Indian justice systems to avoid expediting the MLAT (Mutual Legal Assistance Treaties) process and the signing of an executive agreement under the US Clout Act. This agreement would compel intermediaries to comply with lawful interception and data requests from Indian law enforcement agencies no matter where the data was located.
The data localisation requirement in the draft national data protection law is a result of that frustration. As with the US, a quickly enacted data localisation policy is absolutely non-negotiable when it comes to Indian military, intelligence, law enforcement and e-governance data. For India, it also makes sense in the cases of health and financial data with exceptions under certain circumstances. However, it does not make sense for social media platforms since they, by definition, host international networks of people. Recently an inter ministerial committee recommended that “criminal proceedings against Indian heads of social media giants” also be considered. However, raiding Google’s local servers when a lawful interception request is turned down or arresting Facebook executives will result in retaliatory trade actions from the US.
While the consequences of online recruitment, disinformation in elections and fake news to undermine public order are indeed serious, are there alternatives to such extreme measures for Indian policy makers? Updating intermediary liability law is one place to begin. These social media companies increasingly exercise editorial control, albeit indirectly, via algorithms to claim that they have no “actual knowledge”.
But they are no longer mere conduits or dumb pipes as they are now publishers who collect payments to promote content. Germany passed a law called NetzDG in 2017 which requires expedited compliance with government takedown orders. Unfortunately, this law does not have sufficient safeguards to prevent overzealous private censorship. India should not repeat this mistake, especially given what the Supreme Court said in the Shreya Singhal judgment.
Transparency regulations are imperative. And they are needed urgently for election and political advertising. What do the ads look like? Who paid for them? Who was the target? How many people saw these advertisements? How many times? Transparency around viral content is also required. Anyone should be able to see all public content that has been shared with more than a certain percentage of the population over a historical timeline for any geographic area. This will prevent algorithmic filter bubbles and echo chambers, and also help public and civil society monitor unconstitutional and hate speech that violates terms of service of these platforms. So far the intermediaries have benefitted from surveillance — watching from above. It is time to subject them to sousveillance — watched by the citizens from below.
Data portability mandates and interoperability mandates will allow competition to enter these monopoly markets. Artificial intelligence regulations for algorithms that significantly impact the global networked public sphere could require – one, a right to an explanation and two, a right to influence automated decision making that influences the consumers experience on the platform.
The real solution lies elsewhere. Google and Facebook are primarily advertising networks. They have successfully managed to destroy the business model for real news and replace it with a business model for fake news by taking away most of the advertising revenues from traditional and new news media companies. They were able to do this because there was a trust deficit between advertisers and publishers. Perhaps this trust deficit could be solved by a commons-based solutions based on free software, open standards and collective action by all Indian new media companies.
Why Data Localisation Might Lead To Unchecked Surveillance
The article was published in Bloomberg Quint on October 15, 2018 and also mirrored in the Quint.
In April 2018, the Reserve Bank of India put out a circular requiring that all “data relating to payment systems operated by them are stored in a system only in India” within six months. Lesser requirements have been imposed on all Indian companies’ accounting data since 2014 (the back-up of the books of account and other books that are stored electronically must be stored in India, the broadcasting sector under the Foreign Direct Investment policy, must locally store subscriber information, and the telecom sector under the Unified Access licence, may not transfer their subscriber data outside India).
The draft e-commerce policy has a wide-ranging requirement of exclusive local storage for “community data collected by Internet of Things devices in public space” and “data generated by users in India from various sources including e-commerce platforms, social media, search engines, etc.”, as does the draft e-pharmacy regulations, which stipulate that “the data generated” by e-pharmacy portals be stored only locally.
While companies such as Airtel, Reliance, PhonePe (majority-owned by Walmart) and Alibaba, have spoken up in support the government’s data localisation efforts, others like Facebook, Amazon, Microsoft, and Mastercard have led the way in opposing it.
Just this week, two U.S. Senators wrote to the Prime Minister’s office arguing that the RBI’s data localisation regulations along with the proposals in the draft e-commerce and cloud computing policies are “key trade barriers”. In her dissenting note to the Srikrishna Committee's report, Rama Vedashree of the Data Security Council of India notes that, “mandating localisation may potentially become a trade barrier and the key markets for the industry could mandate similar barriers on data flow to India, which could disrupt the IT-BPM (information technology-business process management) industry.”
Justification For Data Localisation
What are the reasons for these moves towards data localisation?
Given the opacity of policymaking in India, many of the policies and regulations provide no justification at all. Even the ones that do, don’t provide cogent reasoning.
The RBI says it needs “unfettered supervisory access” and hence needs data to be stored in India. However, it fails to state why such unfettered access is not possible for data stored outside of India.
As long as an entity can be compelled by Indian laws to engage in local data storage, that same entity can also be compelled by that same law to provide access to their non-local data, which would be just as effective.
What if they don’t provide such access? Would they be blacklisted from operating in India, just as they would if they didn’t engage in local data storage? Is there any investigatory benefit to storing data in India? As any data forensic expert would note, chain of custody and data integrity are what are most important components of data handling in fraud investigation, and not physical access to hard drives. It would be difficult for the government to say that it will block all Google services if the company doesn’t provide all the data that Indian law enforcement agencies request from it. However, it would be facile for the RBI to bar Google Pay from operating in India if Google doesn’t provide it “unfettered supervisory access” to data.
The most exhaustive justification of data localisation in any official Indian policy document is that contained in the Srikrishna Committee’s report on data protection. The report argues that there are several benefits to data localisation:
- Effective enforcement,
- Avoiding reliance on undersea cables,
- Avoiding foreign surveillance on data stored outside India,
- Building an “Artificial Intelligence ecosystem”
Of these, the last three reasons are risible.
Not A Barrier To Surveillance
Requiring mirroring of personal data on Indian servers will not magically give rise to experts skilled in statistics, machine learning, or artificial intelligence, nor will it somehow lead to the development of the infrastructure needed for AI.
The United States and China are both global leaders in AI, yet no one would argue that China’s data localisation policies have helped it or that America’s lack of data localisation polices have hampered it.
On the question of foreign surveillance, data mirroring will not have any impact, since the Srikrishna Committee’s recommendation would not prevent companies from storing most personal data outside of India.
Even for “sensitive personal data” and for “critical personal data”, which may be required to be stored in India alone, such measures are unlikely to prevent agencies like the U.S. National Security Agency or the United Kingdom’s Government Communications Headquarters from being able to indulge in extraterritorial surveillance.
In 2013, slides from an NSA presentation that were leaked by Edward Snowden showed that the NSA’s “BOUNDLESSINFORMANT” programme collected 12.6 billion instances of telephony and Internet metadata (for instance, which websites you visited and who all you called) from India in just one month, making India one of the top 5 targets.
This shows that technically, surveillance in India is not a challenge for the NSA.
So, forcing data mirroring enhances Indian domestic intelligence agencies’ abilities to engage in surveillance, without doing much to diminish the abilities of skilled foreign intelligence agencies.
As I have noted in the past, the technological solution to reducing mass surveillance is to use decentralised and federated services with built-in encryption, using open standards and open source software.
Reducing reliance on undersea cables is, just like reducing foreign surveillance on Indians’ data, a laudable goal. However, a mandate of mirroring personal data in India, which is what the draft Data Protection Bill proposes for all non-sensitive personal data, will not help. Data will stay within India if the processing happens within India. However, if the processing happens outside of India, as is often the case, then undersea cables will still need to be relied upon.
The better way to keep data within India is to incentivise the creation of data centres and working towards reducing the cost of internet interconnection by encouraging more peering among Internet connectivity providers.
While data mirroring will not help in improving the enforcement of any data protection or privacy law, it will aid Indian law enforcement agencies in gaining easier access to personal data.
The MLAT Route
Currently, many forms of law enforcement agency requests for data have to go through onerous channels called ‘mutual legal assistance treaties’. These MLAT requests take time and are ill-suited to the needs of modern criminal investigations. However, the U.S., recognising this, passed a law called the CLOUD Act in March 2018. While the CLOUD Act compels companies like Google and Amazon, which have data stored in Indian data centres, to provide that data upon receiving legal requests from U.S. law enforcement agencies, it also enables easier access to foreign law enforcement agencies to data stored in the U.S. as long as they fulfill certain procedural and rule-of-law checks.
While the Srikrishna Committee does acknowledge the CLOUD Act in a footnote, it doesn’t analyse its impact, doesn’t provide suggestions on how India can do this, and only outlines the negative consequences of MLATs.
Further, it is inconceivable that the millions of foreign services that Indians access and provide their personal data to will suddenly find a data centre in India and will start keeping such personal data in India. Instead, a much likelier outcome, one which the Srikrishna Committee doesn’t even examine, is that many smaller web services may find such requirements too onerous and opt to block users from India, similar to the way that Indiatimes and the Los Angeles Times opted to block all readers from the European Union due to the coming into force of the new data protection law.
The government could be spending its political will on finding solutions to the law enforcement agency data access question, and negotiating solutions at the international level, especially with the U.S. government. However it is not doing so.
Given this, the recent spate of data localisation policies and regulation can only be seen as part of an attempt to increase the scope and ease of the Indian government’s surveillance activities, while India’s privacy laws still remain very weak and offer inadequate legal protection against privacy-violating surveillance. Because of this, we should be wary of such requirements, as well as of the companies that are vocal in embracing data localisation.
377 Bites the Dust: Unpacking the long and winding road to the judicial decriminalization of homosexuality in India
The article was published in Socio-Legal Review, a magazine published by National Law School of India University on October 11, 2018.
Introduction
After a prolonged illness due to AIDS-related complications, the gregarious Queen front-man Farrokh Bulsara (known to the world as Freddie Mercury) breathed his last in his home in Kensington, London in 1991. Despite being the symbol of gay masculinity for over a decade, Mercury never explicitly confirmed his sexual orientation-for reasons that remain unknown but could stem from prevailing social stigma. Occluded from public discourse and shrouded in irrational fears, the legitimate problems of the LGBT+ community, including the serial killer of HIV/AIDS was still relegated to avoidable debauchery as opposed to genuine illness. Concerted activism throughout the 90’s-depicted on the big screen through masterpieces such as Philadelphia, alerted the Western public of this debacle, which lead to a hard-fought array of rights and a reduction of social ostracization at the turn of the century for the LGBT+ community across western countries. This includes over two dozen countries that have allowed same-sex marriages and a host of others that recognize civil union between same-sex partners in some form.[1]
On 6th September, 2018, Section 377 of the Indian Penal Code – a colonial era law that criminalized “carnal intercourse against the order of nature” bit the dust in New Delhi, at the hands of five judges of the Supreme Court of India (Navtej Johar v Union of India).[2] Large parts of the country celebrated the restoration of the ideals of the Indian Constitution. It was freedom, not just for a community long suppressed, but for the ethos of our foundation that for a century suffered this incessant incongruity. The celebrations were tempered, perhaps by a recognition of how long this fight had taken, the unnecessary hurdles – both judicial and otherwise – that were erected along the way, and a realization of the continued suffering this community might have to tolerate till they truly earn the acceptance they deserve. While the judgment will serve as a document that signifies the sanctity of our constitutional ethos, in the grander scheme of things it is still but a small step, with the potential to catalyze a giant leap forward. For our common future, it is imperative that the LGBT+ community does not undertake this leap alone but is accompanied by the rest of the nation- a nation that recognizes the travails of this long march to freedom.
Long March to Freedom
Modelled on the 1533 Buggery Act in the UK, Section 377 was introduced into the Indian Penal Code by Thomas Macaulay, a representative of the British Raj. While our colonial masters progressed in 1967, the hangover enmeshed in our penal laws lingered on. Public discourse on this legal incongruity emerged initially with the publication of a report titled Less than Gay: A Citizens Report on the Status of Homosexuality in India, spearheaded by activist Siddhartha Gautam, on behalf of the AIDS Bhedbav Virodhi Andolan (ABVA) that sought to fight to decriminalise homosexuality and thereby move towards removing its associated stigma.[3] The ABVA went on to file a petition for this decriminalisation in 1994. The judicial skirmish continued in 2001 with the Naz Foundation, a Delhi-based NGO that works on HIV/AIDS and sexual health, filing a petition by way of Public Interest Litigation asking for a reading down of the Section. The Delhi High Court initially dismissed this petition – stating that the foundation had no locus standi.[4] Naz Foundation appealed against this before the Supreme Court, which overturned the dismissal on technical grounds and ordered the High Court to decide the case on merits.
The two-judge bench of the Delhi High Court held that Section 377 violated privacy, autonomy and liberty, ideals which were grafted into the ecosystem of fundamental rights guaranteed by Part-III of the Indian Constitution.[5] It stated that the Constitution was built around the core tenet of inclusiveness, which was denigrated by the sustained suppression of the LGBT+ community. It was an impressive judgment, not only because of the bold and progressive claim it made in a bid to reverse a century and a half of oppression, but also because of the quality of the judgment itself. It tied in principles of international law, along with both Indian and Foreign judgments in addition to citing literature on sexuality as a form of identity. For a brief while, faith in the ‘system’ seemed justified.
Hope, however, is a fickle friend. Four years from the day, an astrologer by the name of Suresh Kumar Koushal challenged the Delhi High Court’s verdict.[6] Some of the reasons behind this challenge would defy any standard sense of rationality. These included national security concerns – as soldiers who stay away from their families[7] may enter into consensual relationships with each other – leading to distractions that might end up in military defeats. Confoundingly, the Supreme Court’s verdict lent judicial legitimacy to Koushal’s thought process, as they overturned the Naz Foundation judgment and affirmed the constitutional validity of Section 377 on some truly bizarre grounds.[8] Indian constitutional tradition permits discrimination by the state only if classification is based on an intelligible differential between the group being discriminated against from the rest of the populace; having a rational nexus with a constitutionally valid objective. To satisfy this threshold, the Supreme Court stated, without any evidence, that there are two classes of people-those who engage in sexual intercourse in the ‘ordinary course’ and those who do not- thereby satisfying the intelligible differential threshold.[9] As pointed out by constitutional law scholar Gautam Bhatia, this differential makes little sense – an extrapolation of this idea could indicate that intercourse with a blue-eyed person was potentially not ‘ordinary’, since the probability of this occurring is rare.[10] The second justification was based on numbers. The Court argued that statistics pointed to the fact that only 200 people had been arrested under this law, which suggested that it was largely dormant and hence, discrimination doesn’t get established per se.[11] In other words, a plain reading of the judgement might lead one to conclude that the random arrests of a small number of citizens would be constitutionally protected, so long it does not overshoot an arbitrarily determined de minimis threshold! The judgment seemed to drag Indian society ceaselessly into the past. This backward shift internally was accompanied by international posturing by India that opposed the recent wave of UN resolutions which sought to advocate LGBT+ rights.[12]
Thankfully, there remained a way to correct such Supreme Court induced travesties, through what is known as a curative petition, a concept introduced by the Court itself through one of its earlier judgements.[13] Needless to mention, such a petition was duly filed before the Court.[14] While this curative petition was under consideration, last August, a 9-judge bench of the Court spun some magic through a landmark judgment in Just. (Retd.) K S Puttuswamy v Union of India[15] which stated that the ‘right to privacy’ was a recognised fundamental right as per the Indian Constitution. The judgment in Koushal was singled out and criticised by Justice Chandrachud who asserted the fact that an entire community could not be deprived of the dignity of privacy in their sexual relations.
Strategically, this was a master-class. While the right to privacy cannot alone serve as the justification for allowing individuals to choose their sexual orientation, in several common law nations including the UK[16] and the USA[17], privacy has served as the initial spark for legitimizing same-sex relations. A year before the privacy judgment was delivered, a group of individuals had filed a separate petition arguing that Section 377 violated their constitutional rights. The nature of this petition was intrinsically different[18] from the Naz Foundation’s, since the Foundation had filed a ‘public interest litigation’ in a representative capacity whereas this petition affected individuals in their personal capacity, implying that the nature of the claim in each case was different.
The cold case file of this petition that crystallised into the iconic judgment delivered last week, was brought to the fore and listed for hearing in January 2018.[19] Justice Chandrachud’s judgement in Puttaswamy, that tore apart the Koushal verdict, had no small role to play in the unfolding of this saga.[20]
And so the hearings began. The government chose to not oppose the petition and allowed the court to decide the fate of Article 377.[21] This was another convenient manoeuvre by the legislature, effectively shifting the ball into the judiciary’s court, shielding itself from potential pushbacks from its conservative voter-base. However, as public support for decriminalisation started pouring in from various quarters, leaders of religious groups were quick to make their opposition known, leaving the five judges on the bench to decide the fate of a community long suppressed through the clutches of an illegitimate law.
“I am what I am”: The judgement, redemption and beyond
“The mis-application of this provision denied them the Fundamental Right to equality guaranteed by Article 14. It infringed the Fundamental Right to non-discrimination under Article 15, and the Fundamental Right to live a life of dignity and privacy guaranteed by Article 21. The LGBT persons deserve to live a life unshackled from the shadow of being ‘unapprehended felons.”[22]
Justice Indu Malhotra summed up her short judgement with this momentous pronouncement, adding that ‘history owes an apology’[23] to the members of the LGBT+ community, for the injustices faced during these centuries of hatred and apathy. It seems fair to suggest that this idea of ‘righting the wrongs of the past’ became the underlying theme of the Supreme Court’s landmark verdict on the constitutionality of Section 377. Five judges, through four concurring but separate opinions, extracted the essence of the claim against this law – protecting the virtue of personal liberty and dignity. In doing so, it exculpated itself from the travesty of Suresh Kaushal, emancipating the ‘miniscule minority’ from their bondage before the law and took yet another step towards restoring faith in the ‘system’ of which the judiciary is currently positioning itself as the sole conscientious wing. Perhaps the only set of people shamed through this verdict were our parliamentarians, who on two separate occasions in the recent past had thwarted any chance of change when they opposed, insulted and ridiculed Dr. Shashi Tharoor while he attempted to introduce a Bill decriminalizing homosexuality on the floor of the House.[24]
Earlier in the day, the Chief Justice, authoring the lead opinion for himself and Justice Khanwilkar, began with the ominous pronouncement that ‘denying self-expression (to the individual) was an invitation to death’,[25] emphasizing through his long judgement the importance of promoting individuality in all its varied facets- in matters of choice, privacy, speech and expression.[26] Arguing strongly in support of the ‘progressive realization of rights’,[27] which he identified as the soul of constitutional morality, the Chief Justice outlawed the ‘artificial distinction’ drawn between heterosexual and homosexual through the application of the ‘equality’ doctrine embedded in Articles 14 and 15.[28] Noting that the recent criminal law amendment recognizes the absence of consent as the basis for sexual offences, he pointed out the lack of a similar consent-based framework in the context of non peno-vaginal sex, effectively de-criminalizing ‘voluntary sexual acts by consenting adults’ as envisaged within the impugned law.[29] The Chief Justice went on to elaborate that the right to equality, liberty and privacy are inherent in all individuals, and no discrimination on grounds of sex would survive the scrutiny of the law.[30]
Justice Nariman in his separate opinion charted out the legislative history behind the adoption of the Indian Penal Code. In his inimitable manner, he travelled effortlessly across time and space to source historical material and legislations, judicial decisions and literary critique from various jurisdictions to bolster the claim that the discrimination faced by homosexuals had no basis in law or fact.[31] For instance, referring to the Wolfenden Committee Report in the UK regarding decriminalisation of homosexuality which urged legislators to distinguish between ‘sin and crime’, the judge went on to lament the lives lost to mere social perception, including that of Oscar Wilde and Alan Turing.[32] Repelling the popular myth of homosexuality being a ‘disease’, he quoted from the Mental Healthcare Act, 2017, the US Supreme Court’s seminal judgment in Lawrence v Texas[33] and several other studies on the intersection of homosexuality and public health, dismissing this contention entirely. Justice Nariman, invoking the doctrine of ‘manifest arbitrariness’[34] to dispel the notion that the law treating homosexuals was ‘different’. Since it was based on sexual identity and orientation, such a law was a gross abuse of the equal protection of the Constitution.
Justice Chandrachud, having already built a formidable reputation as the foremost liberal voice on the bench, launched a scathing, almost visceral attack against the idea of ‘unnatural sexual offence’ insofar as it applied to homosexuality.[35] Mirroring the concern first espoused by Justice Nariman about the chilling effect of majoritarianism, he wondered aloud what societal harm did a provision like Section 377 seek to prevent. In fact, his separate opinion is categorical in its negation of the ‘intelligible differentia’ between ‘natural’ and ‘non-natural’ sex, sardonically stating the perpetuation of heteronormativity cannot be the object of a law.[36]
As an interesting aside, his judgement in Puttaswamy famously introduced a section called ‘discordant notes’[37] which led an introspective Court to disown and overturn disturbing precedent from the past, most notably the Court’s opinion in the ADM Jabalpur,[38] decided that the right to seek redressal for violation of Fundamental Rights remained suspended as a consequence of the National Emergency.
In a similar act of constitutional manipulation, he delved into a critique of the Apex Court’s judgement in the Nergesh Meerza[39] case. This was a decision which upheld the discriminatory practice of treating men and women as different classes of employees by Air India, denying the women employees certain benefits ordinarily available to men. The Court in Nergesh Meerza read the non-discrimination guarantee in Article 15 narrowly to understand that discrimination based on ‘sex alone’ would be struck down. He held that since the sexes had differences in the mode of recruitment, promotion and conditions of service, it did not tantamount to ‘merely sex based’ categorization and was an acceptable form of classification. In his missionary zeal to exorcise the Court of past blemishes, Dr. Chandrachud observed that interpreting constitutional provisions through such narrow tests as ‘sex alone’ would lead to denuding the freedoms guaranteed within the text. Though not the operative part of the judgement, one hopes his exposition of the facets of the equality doctrine and fallacies in reasoning in Nargesh Meerza will pave the way for just jurisprudence to emerge in sex discrimination cases in the future.[40]
Reverting to the original issue, the judge addresses several key concerns voiced by the LGBT+ community through their years of struggle. He spoke of bridging the public-private divide by ensuring the protection of sexual minorities in the public sphere as well, wherein they are most vulnerable. Alluding to his opinion in Puttaswamy, he declares that all people have an inalienable right to privacy, which is a fundamental aspect of their liberty and the ‘soulmate of dignity’- ascribing the right to dignified life as a constitutional guarantee for one and all. Denouncing the facial neutrality[41] of Section 377, insofar as it targets certain ‘acts and not classes of people’, his broad and liberal reading of non-discrimination goes beyond the semantics of neutrality and braves the original challenge- fashioning a justice system with real equality at its core.
Shall History Absolve Us?
Where to from here then? Can the 500 pages of this iconic judgment magically change the social norms that define the existence of LGBT+ communities in modern Indian society? If the reception of this judgement by the conservative factions within society is anything to go by, the answer is clear enough. Yet, the role of this judgment – in an ecosystem of other enablers – might just be a crucial first step. As noted by Harvard Law School professor Lawrence Lessig, law can create, displace or change the collective expectations of society by channelling societal behaviour in a manner that conforms with its contents.[42] An assessment of the impact of Brown v Board of Education on African-Americans offers an interesting theoretical analogy.[43]
The unanimous decision of the US Supreme Court in Brown marked a watershed moment in American history that struck down the ‘separate but equal’ doctrine which served as the basis for segregation between communities of colour and the dominant White majority in American public schools. While this ruling initially faced massive resistance, it laid the edifice for progressive legislation such as the Civil Rights Act and the Voting Act a decade later.[44] While its true impact on evolving acceptable standards of social behaviour remains disputed with valid arguments on all sides, Brown kick-started a counter-culture that sought to wipe out the toxic norms that the Jim Crow-era had birthed in the 1950s. Along with subsequent decisions by the US Supreme Court, it acted as the catalyst that morphed the boundaries between ‘us’ and ‘them’. Republican Senator Barry Goldwater attempted to stifle this counterculture in 1964 by undertaking a sustained campaign that opposed the dictum in Brown not in opposition to African-Americans but instead in opposition to an overly intrusive federal government that was taking away from the cultural traditions and values, particularly of the South.[45] In the past few years, cultural apathy seems to have taken a more sinister turn as recent incidents of police violence and the rebirth of white supremacist movements indicate.
Lessons from a different context in an alternate society can never be transposed in another without substantial alterations. Discrimination is intersectional and a celebration of identity is a recognition of intersectionality. Therefore, the path ahead for the LGBT+ community lies in crafting a strategy that works for them – a strategy that can draw from lessons learned in other contexts. Last week’s judgment could morph into a point of reference for a counter-cultural movement that works to remove the stains of oppression. The key challenge is carrying this message to swathes of the populace who, goaded by leading public figures, continue to treat homosexuality as an unnatural phenomenon[46].
Being a majority Hindu nation, one possible medium of communication could be reference to ancient Hindu scriptures that do not ostracize individuals based on their sexual orientation but treat them as fellow sojourners on their path to Nirvana, the idea of spiritual emancipation, a central tenet of Hindu belief.[47] Strategically, using this framework as a dangling carrot for religious conservatives may be a potential conversation starter but comes riddled with potholes, as the same scriptures could be interpreted to justify subjugation of women, for example. A more holistic approach might be reading these scriptures into the overarching foundation stone of society -The Indian Constitution, which is not a rigid, static document – stuck in the time of its inception – but is a dynamic one that responds to and triggers the Indian social and political journey. The burden of a constitution, as reiterated by Chief Justice Misra and Dr. Chandrachud is to ‘draw a curtain’ on the past of social injustice and prejudice and embrace constitutional morality, a cornerstone of which is the principle of inclusiveness. Inclusiveness driven by rhetoric in political speeches and storylines on the big screen. Inclusiveness that fosters symbiosis between the teachings of religious scriptures and that of Constitutional Law Professors – an inclusiveness that begets the idea of India, which is a fair deal for all Indians.
…And Justice for all?
In the aftermath of this decision come further legal challenges. Legally, while the ‘right to love’ has been vindicated, the right to formalise this union through societal recognition remains to be established. This judgement paves the way for the acceptance of homosexual relationships, but not necessarily the right to marry for a homosexual couple. There are passages within Justice Chandrachud’s visionary analysis which directly address this concern, and advocate for the ‘full protection’ of the law being extended to the LGBT+ populace. It will certainly be instructive for future courts, and one tends to remain hopeful that the long march to freedom for the LGBT+ community and its supporters will not come to a screeching halt through judicial intervention or State action. If anything, the wings of government should bolster these efforts, in view of this verdict.
That said, social acceptance seldom waits on the sanction of the law.
The outpouring of public support which was witnessed through public demonstrations, social media advocacy and concerted efforts from so many quarters to bring down this draconian law needs to continue and consolidate. There are evils yet, and the path to genuine inclusiveness in this country (as in most others) is littered with thorns. And even greater resistance is likely to emerge when tackling some of these issues, which tend to hit closer home than others.
While this judgement entered into detailed discussions on the issue of consent, it remained disquietingly silent on a most contentious subject, perhaps because it was perceived to be beyond the terms of reference. The exception of marital rape carved out in the Indian Penal Code, which keeps married relationships outside the purview of rape laws, remains as a curse – a reminder that gender equality in this nation will only come at tremendous human cost. The institution of family, that sacrosanct space which even the most liberal courtrooms in India have sought to protect, stands threatened. Malignant patriarchy will raise its head and claim its pound of flesh before the dust settles, and in the interest of freedom, it shall be up to the Apex Court to ensure that it settles on the right side of history. Else, all our progress, howsoever incremental, may be undone by this one stain on our collective conscience.
*Agnidipto Tarafder is an Assistant Professor of Law at the National University of Juridical Sciences, Kolkata, where he teaches courses in Constitutional Law, Labour Law and Privacy.
*Arindrajit Basu recently finished his LLM (Public International Law) at the University of Cambridge and is a Policy Officer at the Centre for Internet & Society, Bangalore
_________________________________________________________________________________________
[1] Gay Marriage Around the World, Pew Research Centre (Aug 8, 2017) available at http://www.pewforum.org/2017/08/08/gay-marriage-around-the-world-2013/.
[2] W. P. (Crl.) No. 76 of 2016 (Supreme Court of India).
[3] Aids Bhedbav Virodhi Andolan, Less than Gay: A Citizen’s Report on the Status of Homosexuality in India (Nov-Dec, 1991) available at https://s3.amazonaws.com/s3.documentcloud.org/documents/1585664/less-than-gay-a-citizens-report-on-the-status-of.pdf.
[4] P.P Singh, 377 battle at journey’s end (September 6, 2018) available at https://indianexpress.com/article/explained/section-377-verdict-supreme-court-decriminalisation-gay-sex-lgbtq-5342008/.
[5] (2009) 160 DLT 277; W.P. (C) No.7455/2001 of 2009 (Delhi HC).
[6] Sangeeta Barooah Pisharoty, It is like reversing the motion of the earth, The Hindu (December 20, 2013) available at https://www.thehindu.com/features/metroplus/society/it-is-like-reversing-the-motion-of-the-earth/article5483306.ece.
[7] Id.
[8] (2014) 1 SCC 1 (Supreme Court of India).
[9] Ibid, at para 42.
[10] Gautam Bhatia, The unbearable wrongness of Koushal v Naz Foundation, Ind Con Law Phil (December 11, 2013)
[11] supra note 8, at para 43.
[12] Manjunath, India’s UN Vote: A Reflection of Our Deep Seated Anti-Gay Sentiments, Amnesty International (Apr 20, 2015) available at https://amnesty.org.in/indias-un-vote-reflection-societys-deep-seated-anti-gay-prejudice/.
[13] The concept of curative petitions was laid down in Rupa Ashok Hurra v. Ashok Hurra, (2002) 4 SCC 388 (Supreme Court of India).
[14] Ajay Kumar, All you need to know about the SC’s decision to reopen the Section 377 debate, FIRSTPOST (February 3, 2016) available at https://www.firstpost.com/india/all-you-need-to-know-about-the-scs-decision-to-reopen-the-section-377-debate-2610680.html.
[15] 2017 (10) SCC 1(Supreme Court of India).
[16] The Wolfenden Report, Brit. J; Vener. Dis. (1957) 33, 205 available at https://sti.bmj.com/content/sextrans/33/4/205.full.pdf.
[17] Griswold v Connecticut, 381 US 479.
[18] Gautam Bhatia, Indian Supreme Court reserves judgment on the de-criminalisation of Homosexuality, OHRH Blog (August 15, 2018) available at http://ohrh.law.ox.ac.uk/the-indian-supreme-court-reserves-judgment-on-the-de-criminalisation-of-homosexuality/.
[19] Krishnadas Rajagopal, Supreme Court refers plea to decriminalize homosexuality under Section 377 to larger bench, The Hindu (January 8, 2018) available at https://www.thehindu.com/news/national/supreme-court-refers-377-plea-to-larger-bench/article22396250.ece.
[20] Puttuswamy, paras 124-28.
[21] Aditi Singh, Government leaves decision on Section 377 to the wisdom of Supreme Court, LIVEMINT (July 11, 2018) available at https://www.livemint.com/Politics/fMReaXRcldOWyY20ELJ0GK/Centre-leaves-it-to-Supreme-Court-to-decide-on-Section-377.html.
[22] supra note 2, at para 20.
[23] Ibid.
[24] Express News Service, Lok Sabha votes against Shashi Tharoor’s bill to decriminalize homosexuality again, Indian Express (March 12, 2016) available at https://indianexpress.com/article/india/india-news-india/decriminalising-homosexuality-lok-sabha-votes-against-shashi-tharoors-bill-again/.
[25] Navtej Johar v. Union of India, W. P. (Crl.) No. 76 of 2016 (Supreme Court of India) at para 1.
[26] Ibid, at para 2.
[27] Ibid, at para 82.
[28]Ibid, at para 224.
[29] Ibid, at para 253.
[30] Ibid.
[31] Separate Opinion, RF Nariman, paras 1-20.
[32] Ibid, at paras 28-9.
[33] Ibid. Lawrence v Texas, 539 US 558 (2003), discussed in paras 108-09.
[34] Ibid, at para 82.
[35] Separate Opinion, DY Chandrachud, at para 28.
[36] Ibid, at para 56-7, 61.
[37] Supra note 20, at para 118-9.
[38] ADM Jabalpur v Shiv Kant Shukla (1976) 2 SCC 521. (Supreme Court of India)
[39] Air India v Nergesh Meerza (1981) 4 SCC 335. (Supreme Court of India)
[40] Supra note 25, at paras 36-41.
[41] Ibid, at paras 42-43, 56.
[42] Lawrence Lessig, The Regulation of Social Meaning, 62 University of Chicago Law Review 943 ,947 (1995)
[43] Brown v. Board of Education of Topeka, 347 U.S. 483.
[44] David Smith, Little Rock Nine: The day young students shattered racial segregation, The Guardian (September 24, 2017) available at https://www.theguardian.com/world/2017/sep/24/little-rock-arkansas-school-segregation-racism.
[45]Michael Combs and Gwendolyn Combs, Revisiting Brown v. Board of Education: A Cultural, Historical-Legal, and Political Perspective (2005).
[46] Poulomi Saha, RSS on 377: Gay sex not a crime but is unnatural, India Today (September 6, 2018) available at https://www.indiatoday.in/india/story/rss-on-section-377-verdict-gay-sex-not-a-crime-but-is-unnatural-1333414-2018-09-06.
[47] S Venkataraman and H Varuganti, A Hindu approach to LGBT Rights, Swarajya (July 4, 2015) available at https://swarajyamag.com/culture/a-hindu-approach-to-lgbt-rights.
Discrimination in the Age of Artificial Intelligence
This was originally published by Oxford Human Rights Hub on October 23, 2018

Image Credit: Sarla Catt via Flickr, used under a Creative Commons license available at https://creativecommons.org/licenses/by/2.0/
In the international human rights law context, AI solutions pose a threat to norms which prohibit discrimination. International Human Rights Law recognizes that discrimination may take place in two possible ways, directly or indirectly. Direct discrimination occurs when an individual is treated less favourably than someone else similarly situated on one of the grounds prohibited in international law, which, as per the Human Rights Committee, includes race, colour, sex, language, religion, political or other opinion, national or social origin, property, birth or other status. Indirect discrimination occurs when a policy, rule or requirement is ‘outwardly neutral’ but has a disproportionate impact on certain groups that are meant to be protected by one of the prohibited grounds of discrimination. A clear example of indirect discrimination recognized by the European Court of Human Rights arose in the case of DH&Ors v Czech Republic. The ECtHR struck down an apparently neutral set of statutory rules, which implemented a set of tests designed to evaluate the intellectual capability of children but which resulted in an excessively high proportion of minority Roma children scoring poorly and consequently being sent to special schools, possibly because the tests were blind to cultural and linguistic differences. This case acts as a useful analogy for the potential disparate impacts of AI and should serve as useful precedent for future litigation against AI-driven solutions.
Indirect discrimination by AI may occur at two stages. First is the usage of incomplete or inaccurate training data that results in the algorithm processing data that may not accurately reflect reality. Cathy O’Neil explains this using a simple example. There are two types of crimes-those that are ‘reported’ and others that are only ‘found’ if a policeman is patrolling the area. The first category includes serious crimes such as murder or rape while the second includes petty crimes such as vandalism or possession of illicit drugs in small quantities. Increased police surveillance in areas in US cities where Black or Hispanic people reside lead to more crimes being ‘found’ there. Thus, data is likely to suggest that these communities commit a higher proportion of crimes than they actually do – indirect discrimination that has been empirically been shown through research published by Pro Publica.
Discrimination may also occur at the stage of data processing, which is done through a metaphorical ‘black-box’ that accepts inputs and generates outputs without revealing to the human developer how the data was processed. This conundrum is compounded by the fact that the algorithms are often utilised to solve an amorphous problem-which attempts to break down a complex question into a simple answer. An example is the development of ‘risk profiles’ of individuals for the determination of insurance premiums. Data might show that an accident is more likely to take place in inner cities due to more densely packed populations in these areas. Racial and ethnic minorities tend to reside more in these areas, which means that algorithms could learn that minorities are more likely to get into accidents, thereby generating an outcome (‘risk profile’) that indirectly discriminates on grounds of race or ethnicity.
It would be wrong to ignore discrimination, both direct and indirect, that occurs as a result of human prejudice. The key difference between that and discrimination by AI lies in the ability of other individuals to compel the decision-maker to explain the factors that lead to the outcome in question and testing its validity against principles of human rights. The increasing amounts of discretion and, consequently, power being delegated to autonomous systems mean that principles of accountability which audit and check indirect discrimination need to be built into the design of these systems. In the absence of these principles, we risk surrendering core tenets of human rights law to the whims of an algorithmically crafted reality.
Conceptualizing an International Security Regime for Cyberspace
Policy-makers often use past analogous situations to reshape questions and resolve dilemmas in current issues. However, without sufficient analysis of the present situation and the historical precedent being considered, the effectiveness of the analogy is limited.This applies across contexts, including cyber space. For example, there exists a body of literature, including The Tallinn Manual, which applies key aspects (structure, process, and techniques) of various international legal regimes regulating the global commons (air, sea, space and the environment) towards developing global norms for the governance of cyberspace.
Given the recent deadlock at the Group of Governmental Experts (GGE), owing to a clear ideological split among participating states, it is clear that consensus on the applicability of traditional international law norms drawn from other regimes, will not emerge if talks continue without a major overhaul of the present format of negotiations. The Achilles Heel of the GGE thus far has been a deracinated approach to the norms formulation process. There has been excessive focus on the content and the language of the applicable norm rather than the procedure underscoring its evolution, limited state and non state participation, and a lack of consideration for social, cultural, economic and strategic contexts through which norms emerge at the global level. Even if the GGE process became more inclusive and included all United Nations members, strategies preceding the negotiation process must be designed in a manner to facilitate consensus.
There exists to date, no scholarship that traces the negotiation processes that lead to the forging of successful analogous universal regimes or an investigation into the nature of normative contestation that enabled the evolution of the core norms that shaped these regimes. To develop an effective global regime governing cyberspace, we must consider if and how existing international law or norms for other global commons might also apply to ‘cyberspace’, but also transcend this frame into more nuanced thinking around techniques and frameworks that have been successful in consensus building. This paper focuses on the latter and embarks on an assessment of how regimes universally maximized functional utility through global interactions and shaped legal and normative frameworks that resulted, for some time, at least, in broad consensus.
Lessons from US response to cyber attacks
The article was published in Hindu Businessline on October 30, 2018. The article was edited by Elonnai Hickok.
In September, amidst the brewing of a new found cross-continental romance between Kim Jong-Un and Donald Trump, the US Department of Justice filed a criminal complaint indicting North Korean hacker Park Jin Hyok for playing a role in at least three massive cyber operations against the US. This included the Sony data breach of 2014; the Bangladesh bank heist of 2016 and the WannaCry ransomware attack in 2017. This indictment was followed by one on October 4, of seven officers in the GRU, Russia’s military agency, for “persistent and sophisticated computer intrusions.” Evidence adduced in support included forensic cyber evidence like similarities in lines of code or analysis of malware and other factual details regarding the relationship between the employers of the indicted individuals and the state in question.
While it is unlikely that prosecutions will ensue, indicting individuals responsible for cyber attacks offers an attractive option for states looking to develop a credible cyber deterrence strategy.
Attributing cyber attacks
Technical uncertainty in attributing attacks to a specific actor has long fettered states from adopting defensive or offensive measures in response to an attack and garnering support from multilateral fora. Cyber attacks are multi-stage, multi-step and multi-jurisdictional, which complicates the attribution process and removes the attacker from the infected networks.
Experts at the RAND Corporation have argued that technical challenges to attribution should not detract from international efforts to adopt a robust, integrated and multi-disciplinary approach to attribution, which should be seen as a political process operating in symbiosis with technical efforts. A victim state must communicate its findings and supporting evidence to the attacking state in a bid to apply political pressure.
Clear publication of the attribution process becomes crucial as it furthers public credibility in investigating authorities; enables information exchange among security researchers and fosters deterrence by the adversary and potential adversaries.
Although public attributions need not take the form of a formal indictment and are often conducted through statements by foreign ministries, a criminal indictment is more legitimate as it needs to comply with the rigorous legal and evidentiary standards required by the country’s legal system. Further, an indictment allows for the attack to be conceptualised as a violation of the rule of law in addition to being a geopolitical threat vector.
Lessons for India
India is yet to publicly attribute a cyber attack to any state or non-state actor. This is surprising given that an overwhelming percentage of attacks on Indian websites are perpetrated by foreign states or non-state actors, with 35 per cent of attacks emanating from China, as per a report by the Indian Computer Emergency Response Team (CERT-IN), the national nodal agency under the Ministry of Electronics and Information Technology (MEITY) which deals with cyber threats.
Along with other bodies, such as the National Critical Information Protection Centre (NCIIPC) which is the nodal central agency for the protection of critical information infrastructure, CERT-IN forms part of an ecosystem of nodal agencies designed to guarantee national cyber security.
There are three key lessons that policy makers involved in this ecosystem can take away from the WannaCry attribution process and the Park indictment. First, there is a need for multi-stakeholder collaboration through sharing of research, joint investigations and combined vulnerability identification among the various actors employed by the government, law enforcement authorities and private cyber security firms.
The affidavit suggested that the FBI had used information from various law enforcement personnel, computer scientists at the FBI; Mandiant — a cyber security firm retained by the US Attorney’s Office and publicly available materials produced by cyber security companies. Second, the standards of attribution need to demonstrate compliance both with the evidentiary requirements of Indian criminal law and the requirements in the International Law on State Responsibility. The latter requires an attribution to demonstrate that a state had ‘effective control’ over the non-state actor.
Finally, the attribution must be communicated to the adversary in a manner that does not risk military escalation. Despite the delicate timing of the indictment, Park’s prosecution by the FBI did not dampen the temporary thaw in relations between US and North Korea.
While building capacity to improve resilience, detect attacks and improve attribution capabilities should be a priority, we need to remember that regardless of the breakthrough in both human and infrastructural capacities, attributing cyber attacks will never be an exercise in certainty.
India will need to marry its improved capacity with strategic geopolitical posturing. Lengthy indictments may not deter all potential adversaries but may be a tool in fostering a culture of accountability in cyberspace.
Clarification on the Information Security Practices of Aadhaar Report
The report concerned can be accessed here, and the first clarificatory statement (dated May 16, 2017) can be accessed here.
This clarificatory statement is being issued in response to reports that misrepresent our research. In light of repeated questions we have received, which seem to emanate from a misunderstanding of our report, we would like to make the following clarifications.
- Our research involved documentation and taking illustrative screenshots (included in our report) of public webpages on the four government websites listed in our report. These screenshots were taken to demonstrate that the vulnerability existed.
- The figure of 130-135 million Aadhaar Numbers quoted in our Report are, as clearly stated, derived directly by adding the aggregate numbers (of beneficiaries/individuals whose data were listed in the three government websites concerned) and published by the portals themselves in the MIS reports publicly available on the portals. The numbers are as follows:
- 10,97,60,343 from NREGA,
- 63,95,317 from NSAP, and
- 2,05,60,896 from Chandranna Bima (screenshots included in the report).
- 10,97,60,343 from NREGA,
We sincerely hope that this clarification helps with a clearer comprehension of the argument and implications of the said report. We urge those who are using our report in their research to reach out to us to prevent the future misinterpretation of the report.
— Amber Sinha and Srinivas Kodali
DIDP #32 On ICANN's Fellowship Program
These fellows are assigned a mentor and receive training on ICANN's various areas of engagement. They are also given travel assistance to attend the meeting. While the process and selection criteria is detailed on their website, CIS had some questions as to the execution of these.
Our DIDP questioned the following aspects:
- Has any individual received the ICANN Fellowship more than the stated maximum limit of 3 times?
- If so, whose decision and what was the justification given for awarding it the 4th time and any other times after that?
- What countries did any such individuals belong to?
- How many times has the limit of 3 been breached while giving fellowships?
- What recording mechanisms are being used to ensure that awarding of these fellowships is kept track of, stored and updated? Are these public or privately made available anywhere?
Budapest Convention and the Information Technology Act
Introduction
It was drafted by the Council of Europe along with Canada, Japan, South Africa and the United States of America.[1] The importance of the Convention is also indicated by the fact that adherence to it (whether by outright adoption or by otherwise making domestic laws in compliance with it) is one of the conditions mentioned in the Clarifying Lawful Overseas Use of Data Act passed in the USA (CLOUD Act) whereby a process has been established to enable security agencies of in India and the United States to directly access data stored in each other’s territories. Our analysis of the CLOUD Act vis-à-vis India can be found here. It is in continuation of that analysis that we have undertaken here a detailed comparison of the Information Technology Act, 2000 (“IT Act”) and how it stacks up against the provisions of Chapter I and Chapter II of the Convention.[2]
Before we get into a comparison of the Convention with the IT Act, we must point out the distinction between the two legal instruments, for the benefit of readers from a non legal background. An international instrument such as the Convention on Cybercrime (generally speaking) is essentially a promise made by the States which are a party to that instrument, that they will change or modify their local laws to get them in line with the requirements or principles laid out in said instrument. In case the signatory State does not make such amendments to its local laws, (usually) the citizens of that State cannot enforce any rights that they may have been granted under such an international instrument. The situation is the same with the Convention on Cybercrime, unless the signatory State amends its local laws to bring them in line with the provisions of the Convention, there cannot be any enforcement of the provisions of the Convention within that State.[3] This however is not the case for India and the IT Act since India is not a signatory to the Convention on Cybercrime and therefore is not obligated to amend its local laws to bring them in line with the Convention.
Although India and the Council of Europe cooperated to amend the IT Act through major amendments brought about vide the Information Technology (Amendment) Act, 2008, India still has not become a signatory to the Convention on Cybercrime. The reasons for this appear to be unclear and it has been suggested that these reasons may range from the fact that India was not involved in the original drafting, to issues of sovereignty regarding the provisions for international cooperation and extradition.[4]
|
Convention on Cybercrime |
Information Technology Act, 2000 |
|
Article 2 – Illegal access Each Party shall adopt such legislative and other measures as may be necessary to establish as criminal offences under its domestic law, when committed intentionally, the access to the whole or any part of a computer system without right. A Party may require that the offence be committed by infringing security measures, with the intent of obtaining computer data or other dishonest intent, or in relation to a computer system that is connected to another computer system. |
Section 43 If any person without permission of the owner or any other person who is incharge of a computer, computer system or computer network - (a) accesses or secures access to such computer, computer system or computer network or computer resource
Section 66 If any person, dishonestly, or fraudulently, does any act referred to in section 43, he shall be punishable with imprisonment for a term which may extend to two three years or with fine which may extend to five lakh rupees or with both. |
The Convention gives States the right to further qualify the offence of “illegal access” or “hacking” by adding elements such as infringing security measures, special intent to obtain computer data, other dishonest intent that justifies criminal culpability, or the requirement that the offence is committed in relation to a computer system that is connected remotely to another computer system.[5] However, Indian law deals with the distinction by making the act of unathorised access without dishonest or fraudulent intent a civil offence, where the offender is liable to pay compensation. If the same act is done with dishonest and fraudulent intent, it is treated as a criminal offence punishable with fine and imprisonment which may extend to 3 years.
It must be noted that this provision was included in the Act only through the Amendment of 2008 and was not present in the Information Technology Act, 2000 in its original iteration.
|
Convention on Cybercrime |
Information Technology Act, 2000 |
|
Article 3 – Illegal Interception Each Party shall adopt such legislative and other measures as may be necessary to establish as criminal offences under its domestic law, when committed intentionally, the interception without right, made by technical means, of non-public transmissions of computer data to, from or within a computer system, including electromagnetic emissions from a computer system carrying such computer data. A Party may require that the offence be committed with dishonest intent, or in relation to a computer system that is connected to another computer system.
|
NA |
Although the Information Technology Act, 2000 does not specifically criminalise the interception of communications by a private person. It is possible that under the provisions of Rule 43(a) the act of accessing a “computer network” could be interpreted as including unauthorised interception within its ambit.
The other way in which illegal interception may be considered to be illegal is through a combined reading of Sections 69 (Interception) and 45 (Residuary Penalty) with Rule 3 of the Information Technology (Procedure and Safeguards for Interception, Monitoring and Decryption of Information) Rules, 2009 which prohibits interception, monitoring and decryption of information under section 69(2) of the IT Act except in a manner as provided by the Rules. However, it must be noted that section 69(2) only talks about interception by the government and Rule 3 only provides for procedural safeguards for such an interception. It could therefore be argued that the prohibition under Rule 3 is only applicable to the government and not to private individuals since section 62, the provision under which Rule 3 has been issued, itself is not applicable to private individuals.
|
Convention on Cybercrime |
Information Technology Act, 2000
|
|
Article 4 – Data interference 1 Each Party shall adopt such legislative and other measures as may be necessary to establish as criminal offences under its domestic law, when committed intentionally, the damaging, deletion, deterioration, alteration or suppression of computer data without right. 2 A Party may reserve the right to require that the conduct described in paragraph 1 result in serious harm. |
Section 43 If any person without permission of the owner or any other person who is incharge of a computer, computer system or computer network - (d) damages or causes to be damaged any computer, computer system or computer network, data, computer data base or any other programmes residing in such computer, computer system or computer network; (i) destroys, deletes or alters any information residing in a computer resource or diminishes its value or utility or affects it injuriously by any means; (j) Steals, conceals, destroys or alters or causes any person to steal, conceal, destroy or alter any computer source code used for a computer resource with an intention to cause damage, he shall be liable to pay damages by way of compensation not exceeding one crore rupees to the person so affected. (change vide ITAA 2008) Section 66 If any person, dishonestly, or fraudulently, does any act referred to in section 43, he shall be punishable with imprisonment for a term which may extend to two three years or with fine which may extend to five lakh rupees or with both. |
Damage, deletion, diminishing in value and alteration of data is considered a crime as per Section 66 read with section 43 of the IT Act if done with fraudulent or dishonest intention. While the Convention only requires such acts to be crimes if committed intentionally, however the Information Technology Act requires that such intention be either dishonest or fraudulent only then such an act will be a criminal offence, otherwise it will only incur civil consequences requiring the perpetrator to pay damages by way of compensation.
It must be noted that the optional requirement of such an act causing serious harm has not been adopted by Indian law, i.e. the act of such damage, deletion, etc. by itself is enough to constitute the offence, and there is no requirement of such an act causing serious harm.
As per the Explanatory Report to the Convention on Cybercrime, “Suppressing of computer data means any action that prevents or terminates the availability of the data to the person who has access to the computer or the data carrier on which it was stored.” Strictly speaking the act of suppression of data in another system is not covered by the language of section 43, but looking at the tenor of the section it is likely that if a court is faced with a situation of intentional/malicious denial of access to data, the court could expand the scope of the term “damage” as contained in sub-section (d) to include such malicious acts.
|
Convention on Cybercrime |
Information Technology Act, 2000
|
|
Article 5 – System interference Each Party shall adopt such legislative and other measures as may be necessary to establish as criminal offences under its domestic law, when committed intentionally, the serious hindering without right of the functioning of a computer system by inputting, transmitting, damaging, deleting, deteriorating, altering or suppressing computer data. |
Section 43 If any person without permission of the owner or any other person who is incharge of a computer, computer system or computer network - (e) disrupts or causes disruption of any computer, computer system or computer network; Explanation - for the purposes of this section - (i) "Computer Contaminant" means any set of computer instructions that are designed - (a) to modify, destroy, record, transmit data or programme residing within a computer, computer system or computer network; or (b) by any means to usurp the normal operation of the computer, computer system, or computer network; (iii) "Computer Virus" means any computer instruction, information, data or programme that destroys, damages, degrades or adversely affects the performance of a computer resource or attaches itself to another computer resource and operates when a programme, data or instruction is executed or some other event takes place in that computer resource;
Section 66 If any person, dishonestly, or fraudulently, does any act referred to in section 43, he shall be punishable with imprisonment for a term which may extend to two three years or with fine which may extend to five lakh rupees or with both. |
The offence of causing hindrance to the functioning of a computer system with fraudulent or dishonest intention is an offence under the IT Act. While the Convention only requires such acts to be crimes if committed intentionally, however the IT Act requires that such intention be either dishonest or fraudulent only then such an act will be a criminal offence, otherwise it will only incur civil consequences requiring the perpetrator to pay damages by way of compensation.
The IT Act does not require such disruption to be caused in any particular manner as is required under the Convention, although the acts of introducing computer viruses as well as damaging or deleting data themselves have been classified as offences under the IT Act.
|
Convention on Cybercrime |
Information Technology Act, 2000
|
|
Article 6 – Misuse of devices 1 Each Party shall adopt such legislative and other measures as may be necessary to establish as criminal offences under its domestic law, when committed intentionally and without right: a the production, sale, procurement for use, import, distribution or otherwise making available of: i a device, including a computer program, designed or adapted primarily for the purpose of committing any of the offences established in accordance with Articles 2 through 5; ii a computer password, access code, or similar data by which the whole or any part of a computer system is capable of being accessed, with intent that it be used for the purpose of committing any of the offences established in Articles 2 through 5; and b the possession of an item referred to in paragraphs a.i or ii above, with intent that it be used for the purpose of committing any of the offences established in Articles 2 through 5. A Party may require by law that a number of such items be possessed before criminal liability attaches. 2 This article shall not be interpreted as imposing criminal liability where the production, sale, procurement for use, import, distribution or otherwise making available or possession referred to in paragraph 1 of this article is not for the purpose of committing an offence established in accordance with Articles 2 through 5 of this Convention, such as for the authorised testing or protection of a computer system. 3 Each Party may reserve the right not to apply paragraph 1 of this article, provided that the reservation does not concern the sale, distribution or otherwise making available of the items referred to in paragraph 1 a.ii of this article. |
NA |
This provision establishes as a separate and independent criminal offence the intentional commission of specific illegal acts regarding certain devices or access data to be misused for the purpose of committing offences against the confidentiality, the integrity and availability of computer systems or data. While the IT Act does not by itself makes the production, sale, procurement for use, import, distribution of devices designed to be adopted for such purposes, sub-section (g) of section 43 along with section 120A of the Indian Penal Code, 1860 which deals with “conspiracy” could perhaps be used to bring such acts within the scope of the penal statutes.
|
Convention on Cybercrime |
Information Technology Act, 2000
|
|
Article 7 – Computer related forgery Each Party shall adopt such legislative and other measures as may be necessary to establish as criminal offences under its domestic law, when committed intentionally and without right, the input, alteration, deletion, or suppression of computer data, resulting in inauthentic data with the intent that it be considered or acted upon for legal purposes as if it were authentic, regardless whether or not the data is directly readable and intelligible. A Party may require an intent to defraud, or similar dishonest intent, before criminal liability attaches. |
NA |
The acts of deletion, alteration and suppression of data by itself is a crime as discussed above, there is no specific offence for doing such acts for the purpose of forgery. However this does not mean that the crime of online forgery is not punishable in India at all, such crimes would be dealt with under the relevant provisions of the Indian Penal Code, 1860 (Chapter 18) read with section 4 of the IT Act.
|
Convention on Cybercrime |
Information Technology Act, 2000
|
|
Article 8 – Computer-related fraud Each Party shall adopt such legislative and other measures as may be necessary to establish as criminal offences under its domestic law, when committed intentionally and without right, the causing of a loss of property to another person by: a any input, alteration, deletion or suppression of computer data, b any interference with the functioning of a computer system, with fraudulent or dishonest intent of procuring, without right, an economic benefit for oneself or for another person. |
NA |
Just as in the case of forgery, there is no specific provision in the IT Act whereby online fraud would be considered as a crime, however specific acts such as charging services availed of by one person to another (section 43(h), identity theft (section 66C), cheating by impersonation (section 66D) have been listed as criminal offences. Further, as with forgery, fraudulent acts to procure economic benefits would also get covered by the provisions of the Indian Penal Code that deal with cheating.
|
Convention on Cybercrime |
Information Technology Act, 2000
|
|
Article 9 – Offences related to child pornography 1 Each Party shall adopt such legislative and other measures as may be necessary to establish as criminal offences under its domestic law, when committed intentionally and without right, the following conduct: a producing child pornography for the purpose of its distribution through a computer system; b offering or making available child pornography through a computer system; c distributing or transmitting child pornography through a computer system; d procuring child pornography through a computer system for oneself or for another person; e possessing child pornography in a computer system or on a computer-data storage medium. 2 For the purpose of paragraph 1 above, the term "child pornography" shall include pornographic material that visually depicts: a a minor engaged in sexually explicit conduct; b a person appearing to be a minor engaged in sexually explicit conduct; c realistic images representing a minor engaged in sexually explicit conduct. 3 For the purpose of paragraph 2 above, the term "minor" shall include all persons under 18 years of age. A Party may, however, require a lower age-limit, which shall be not less than 16 years. 4 Each Party may reserve the right not to apply, in whole or in part, paragraphs 1, subparagraphs d and e, and 2, sub-paragraphs b and c. |
67 B Punishment for publishing or transmitting of material depicting children in sexually explicit act, etc. in electronic form. Whoever,- (a) publishes or transmits or causes to be published or transmitted material in any electronic form which depicts children engaged in sexually explicit act or conduct or (b) creates text or digital images, collects, seeks, browses, downloads, advertises, promotes, exchanges or distributes material in any electronic form depicting children in obscene or indecent or sexually explicit manner or (c) cultivates, entices or induces children to online relationship with one or more children for and on sexually explicit act or in a manner that may offend a reasonable adult on the computer resource or (d) facilitates abusing children online or (e) records in any electronic form own abuse or that of others pertaining to sexually explicit act with children, shall be punished on first conviction with imprisonment of either description for a term which may extend to five years and with a fine which may extend to ten lakh rupees and in the event of second or subsequent conviction with imprisonment of either description for a term which may extend to seven years and also with fine which may extend to ten lakh rupees: Provided that the provisions of section 67, section 67A and this section does not extend to any book, pamphlet, paper, writing, drawing, painting, representation or figure in electronic form- (i) The publication of which is proved to be justified as being for the public good on the ground that such book, pamphlet, paper writing, drawing, painting, representation or figure is in the interest of science, literature, art or learning or other objects of general concern; or (ii) which is kept or used for bonafide heritage or religious purposes Explanation: For the purposes of this section, "children" means a person who has not completed the age of 18 years. |
The publishing, transmission, creation, collection, seeking, browsing, etc. of child pornography is an offence under Indian law punishable with imprisonment for upto 5 years for a first offence and upto 7 years for a subsequent offence, along with fine.
It is important to note that bona fide depictions for the public good, such as for publication in pamphlets, reading or educational material are specifically excluded from the rigours of the section, Similarly material kept for heritage or religious purposes is also exempted under this section. Such exceptions are in line with the intent of the Convention, since the Explanatory statement itself states that “The term "pornographic material" in paragraph 2 is governed by national standards pertaining to the classification of materials as obscene, inconsistent with public morals or similarly corrupt. Therefore, material having an artistic, medical, scientific or similar merit may be considered not to be pornographic.
|
Convention on Cybercrime |
Information Technology Act, 2000
|
|
Article 10 – Offences related to infringements of copyright and related rights 1 Each Party shall adopt such legislative and other measures as may be necessary to establish as criminal offences under its domestic law the infringement of copyright, as defined under the law of that Party, pursuant to the obligations it has undertaken under the Paris Act of 24 July 1971 revising the Bern Convention for the Protection of Literary and Artistic Works, the Agreement on Trade-Related Aspects of Intellectual Property Rights and the WIPO Copyright Treaty, with the exception of any moral rights conferred by such conventions, where such acts are committed wilfully, on a commercial scale and by means of a computer system. 2 Each Party shall adopt such legislative and other measures as may be necessary to establish as criminal offences under its domestic law the infringement of related rights, as define under the law of that Party, pursuant to the obligations it has undertaken under the International Convention for the Protection of Performers, Producers of Phonograms and Broadcasting Organisations (Rome Convention), the Agreement on Trade-Related Aspects of Intellectual Property Rights and the WIPO Performances and Phonograms Treaty, with the exception of any moral rights conferred by such conventions, where such acts are committed wilfully, on a commercial scale and by means of a computer system. 3 A Party may reserve the right not to impose criminal liability under paragraphs 1 and 2 of this article in limited circumstances, provided that other effective remedies are available and that such reservation does not derogate from the Party’s international obligations set forth in the international instruments referred to in paragraphs 1 and 2 of this article. |
81 Act to have Overriding effect The provisions of this Act shall have effect notwithstanding anything inconsistent therewith contained in any other law for the time being in force. Provided that nothing contained in this Act shall restrict any person from exercising any right conferred under the Copyright Act, 1957 or the Patents Act, 1970 |
The use of the term "pursuant to the obligations it has undertaken" in both paragraphs makes it clear that a Contracting Party to the Convention is not bound to apply agreements cited (TRIPS, WIPO, etc.) to which it is not a Party; moreover, if a Party has made a reservation or declaration permitted under one of the agreements, that reservation may limit the extent of its obligation under the present Convention.
The IT Act does not try to intervene in the existing copyright regime of India and creates a special exemption for the Copyright Act and the Patents Act in the clause which provides this Act overriding effect. India’s obligations under the various treaties and conventions on intellectual property rights are enshrined in these legislations.[6]
|
Convention on Cybercrime |
Information Technology Act, 2000
|
|
Article 11 – Attempt and aiding or abetting 1 Each Party shall adopt such legislative and other measures as may be necessary to establish as criminal offences under its domestic law, when committed intentionally, aiding or abetting the commission of any of the offences established in accordance with Articles 2 through 10 of the present Convention with intent that such offence be committed. 2 Each Party shall adopt such legislative and other measures as may be necessary to establish as criminal offences under its domestic law, when committed intentionally, an attempt to commit any of the offences established in accordance with Articles 3 through 5, 7, 8, and 9.1.a and c of this Convention. 3 Each Party may reserve the right not to apply, in whole or in part, paragraph 2 of this article. |
84 B Punishment for abetment of offences Whoever abets any offence shall, if the act abetted is committed in consequence of the abetment, and no express provision is made by this Act for the punishment of such abetment, be punished with the punishment provided for the offence under this Act. Explanation: An Act or offence is said to be committed in consequence of abetment, when it is committed in consequence of the instigation, or in pursuance of the conspiracy, or with the aid which constitutes the abetment.
84 C Punishment for attempt to commit offences Whoever attempts to commit an offence punishable by this Act or causes such an offence to be committed, and in such an attempt does any act towards the commission of the offence, shall, where no express provision is made for the punishment of such attempt, be punished with imprisonment of any description provided for the offence, for a term which may extend to one-half of the longest term of imprisonment provided for that offence, or with such fine as is provided for the offence or with both. |
As can be seen, both attempts as well as abetment of criminal offences under the IT Act have also been criminalised.
|
Convention on Cybercrime |
Information Technology Act, 2000
|
|
Article 12 – Corporate liability 1 Each Party shall adopt such legislative and other measures as may be necessary to ensure that legal persons can be held liable for a criminal offence established in accordance with this Convention, committed for their benefit by any natural person, acting either individually or as part of an organ of the legal person, who has a leading position within it, based on: a a power of representation of the legal person; b an authority to take decisions on behalf of the legal person; c an authority to exercise control within the legal person. 2 In addition to the cases already provided for in paragraph 1 of this article, each Party shall take the measures necessary to ensure that a legal person can be held liable where the lack of supervision or control by a natural person referred to in paragraph 1 has made possible the commission of a criminal offence established in accordance with this Convention for the benefit of that legal person by a natural person acting under its authority. 3 Subject to the legal principles of the Party, the liability of a legal person may be criminal, civil or administrative. 4 Such liability shall be without prejudice to the criminal liability of the natural persons who have committed the offence. |
85 Offences by Companies. (1) Where a person committing a contravention of any of the provisions of this Act or of any rule, direction or order made there under is a Company, every person who, at the time the contravention was committed, was in charge of, and was responsible to, the company for the conduct of business of the company as well as the company, shall be guilty of the contravention and shall be liable to be proceeded against and punished accordingly: Provided that nothing contained in this sub-section shall render any such person liable to punishment if he proves that the contravention took place without his knowledge or that he exercised all due diligence to prevent such contravention. (2) Notwithstanding anything contained in sub-section (1), where a contravention of any of the provisions of this Act or of any rule, direction or order made there under has been committed by a company and it is proved that the contravention has taken place with the consent or connivance of, or is attributable to any neglect on the part of, any director, manager, secretary or other officer of the company, such director, manager, secretary or other officer shall also be deemed to be guilty of the contravention and shall be liable to be proceeded against and punished accordingly. Explanation- For the purposes of this section (i) "Company" means any Body Corporate and includes a Firm or other Association of individuals; and (ii) "Director", in relation to a firm, means a partner in the firm. |
The liability of a company or other body corporate has been laid out in the IT Act in a manner similar to the Budapest Convention. While, the test to determine the relationship between the legal entity and the natural person who has committed the act on behalf of the legal entity is a little more detailed[7] in the Convention, the substance of the test is laid out in the IT Act as “a person who is in charge of, and was responsible to, the company”.
|
Convention on Cybercrime |
Information Technology Act, 2000
|
|
Article 14 1 Each Party shall adopt such legislative and other measures as may be necessary to establish the powers and procedures provided for in this section for the purpose of specific criminal investigations or proceedings. 2 Except as specifically provided otherwise in Article 21, each Party shall apply the powers and procedures referred to in paragraph 1 of this article to: a the criminal offences established in accordance with Articles 2 through 11 of this Convention; b other criminal offences committed by means of a computer system; and c the collection of evidence in electronic form of a criminal offence. 3 a Each Party may reserve the right to apply the measures referred to in Article 20 only to offences or categories of offences specified in the reservation, provided that the range of such offences or categories of offences is not more restricted than the range of offences to which it applies the measures referred to in Article 21. Each Party shall consider restricting such a reservation to enable the broadest application of the measure referred to in Article 20. b Where a Party, due to limitations in its legislation in force at the time of the adoption of the present Convention, is not able to apply the measures referred to in Articles 20 and 21 to communications being transmitted within a computer system of a service provider, which system: i is being operated for the benefit of a closed group of users, and ii does not employ public communications networks and is not connected with another computer system, whether public or private, that Party may reserve the right not to apply these measures to such communications. Each Party shall consider restricting such a reservation to enable the broadest application of the measures referred to in Articles 20 and 21. |
NA |
This is a provision of a general nature that need not have any equivalence in domestic law. The provision clarifies that all the powers and procedures provided for in this section (Articles 14 to 21) are for the purpose of “specific criminal investigations or proceedings”.
|
Convention on Cybercrime |
Information Technology Act, 2000
|
|
Article 15 – Conditions and safeguards 1 Each Party shall ensure that the establishment, implementation and application of the powers and procedures provided for in this Section are subject to conditions and safeguards provided for under its domestic law, which shall provide for the adequate protection of human rights and liberties, including rights arising pursuant to obligations it has undertaken under the 1950 Council of Europe Convention for the Protection of Human Rights and Fundamental Freedoms, the 1966 United Nations International Covenant on Civil and Political Rights, and other applicable international human rights instruments, and which shall incorporate the principle of proportionality. 2 Such conditions and safeguards shall, as appropriate in view of the nature of the procedure or power concerned, inter alia, include judicial or other independent supervision, grounds justifying application, and limitation of the scope and the duration of such power or procedure. 3 To the extent that it is consistent with the public interest, in particular the sound administration of justice, each Party shall consider the impact of the powers and procedures in this section upon the rights, responsibilities and legitimate interests of third parties. |
NA |
This again is a provision of a general nature which need not have a corresponding clause in the domestic law. India is a signatory to a number of international human rights conventions and treaties, it has acceded to the International Covenant on Civil and Political Rights (ICCPR), 1966, International Covenant on Economic, Social and Cultural Rights (ICESCR), 1966, ratified the International Convention on the Elimination of All Forms of Racial Discrimination (ICERD), 1965, with certain reservations, signed the Convention on the Elimination of All Forms of Discrimination against Women (CEDAW), 1979 with certain reservations, Convention on the Rights of the Child (CRC), 1989 and signed the Convention against Torture and Other Cruel, Inhuman or Degrading Treatment or Punishment (CAT), 1984. Further the right to life guaranteed under Article 21 of the Constitution takes within its fold a number of human rights such as the right to privacy. Freedom of expression, right to fair trial, freedom of assembly, right against arbitrary arrest and detention are all fundamental rights guaranteed under the Constitution of India, 1950.[8]
In addition, India has enacted the Protection of Human Rights Act, 1993 for the constitution of a National Human Rights Commission, State Human Rights Commission in States and Human Rights Courts for better protection of “human rights” and for matters connected therewith or incidental thereto. Thus, there does exist a statutory mechanism for the enforcement of human rights[9] under Indian law. It must be noted that the definition of human rights also incorporates rights embodied in International Covenants and are enforceable by Courts in India.
|
Convention on Cybercrime |
Information Technology Act, 2000
|
|
Article 16 – Expedited preservation of stored computer data 1 Each Party shall adopt such legislative and other measures as may be necessary to enable its competent authorities to order or similarly obtain the expeditious preservation of specified computer data, including traffic data, that has been stored by means of a computer system, in particular where there are grounds to believe that the computer data is particularly vulnerable to loss or modification. 2 Where a Party gives effect to paragraph 1 above by means of an order to a person to preserve specified stored computer data in the person’s possession or control, the Party shall adopt such legislative and other measures as may be necessary to oblige that person to preserve and maintain the integrity of that computer data for a period of time as long as necessary, up to a maximum of ninety days, to enable the competent authorities to seek its disclosure. A Party may provide for such an order to be subsequently renewed. 3 Each Party shall adopt such legislative and other measures as may be necessary to oblige the custodian or other person who is to preserve the computer data to keep confidential the undertaking of such procedures for the period of time provided for by its domestic law. 4 The powers and procedures referred to in this article shall be subject to Articles 14 and 15. Article 17 – Expedited preservation and partial disclosure of traffic data 1 Each Party shall adopt, in respect of traffic data that is to be preserved under Article 16, such legislative and other measures as may be necessary to: a ensure that such expeditious preservation of traffic data is available regardless of whether one or more service providers were involved in the transmission of that communication; and b ensure the expeditious disclosure to the Party’s competent authority, or a person designated by that authority, of a sufficient amount of traffic data to enable the Party to identify the service providers and the path through which the communication was transmitted. 2 The powers and procedures referred to in this article shall be subject to Articles 14 and 15. |
29 Access to computers and data. (1) Without prejudice to the provisions of sub-section (1) of section 69, the Controller or any person authorized by him shall, if he has reasonable cause to suspect that any contravention of the provisions of this chapter made there under has been committed, have access to any computer system, any apparatus, data or any other material connected with such system, for the purpose of searching or causing a search to be made for obtaining any information or data contained in or available to such computer system. (Amended vide ITAA 2008)
(2) For the purposes of sub-section (1), the Controller or any person authorized by him may, by order, direct any person in charge of, or otherwise concerned with the operation of the computer system, data apparatus or material, to provide him with such reasonable technical and other assistant as he may consider necessary.
67 C Preservation and Retention of information by intermediaries (1) Intermediary shall preserve and retain such information as may be specified for such duration and in such manner and format as the Central Government may prescribe.
Rule 3(7) of the Information Technology (Intermediary Guidelines) Rules, 2011 3(7) - When required by lawful order, the intermediary shall provide information or any such assistance to Government Agencies who are lawfully authorised for investigative, protective, cyber security activity. The information or any such assistance shall be provided for the purpose of verification of identity, or for prevention, detection, investigation, prosecution, cyber security incidents and punishment of offences under any law for the time being in force, on a request in writing staling clearly the purpose of seeking such information or any such assistance.
|
It must be noted that Article 16 and Article 17 refer only to data preservation and not data retention. “Data preservation” means to keep data, which already exists in a stored form, protected from anything that would cause its current quality or condition to change or deteriorate. Data retention means to keep data, which is currently being generated, in one’s possession into the future.[10] In short, the article provides only for preservation of existing stored data, pending subsequent disclosure of the data, in relation to specific criminal investigations or proceedings.
The Convention uses the term "order or similarly obtain", which is intended to allow the use of other legal methods of achieving preservation than merely by means of a judicial or administrative order or directive (e.g. from police or prosecutor). In some States, preservation orders do not exist in the procedural law, and data can only be preserved and obtained through search and seizure or production order. Flexibility was therefore intended by the use of the phrase "or otherwise obtain" to permit the implementation of this article by the use of these means.
While Indian law does not have a specific provision for issuing an order for preservation of data, the provisions of section 29 as well as sections 99 to 101 of the Code of Criminal Procedure, 1973 may be utilized to achieve the result intended by Articles 16 and 17. Although section 67C of the IT Act uses the term “preserve and retain such information”, this provision is intended primarily for the purpose of data retention and not data preservation.
Another provision which may conceivably be used for issuing preservation orders is Rule 3(7) of the Information Technology (Intermediary Guidelines) Rules, 2011 which requires intermediaries to provide “any such assistance” to Government Agencies who are lawfully authorised for investigative, protective, cyber security activity. However, in the absence of a power of preservation in the main statute (IT Act) it remains to be seen whether such an order would be enforced if challenged in a court of law.
|
Convention on Cybercrime |
Information Technology Act, 2000
|
|
Article 18 – Production order 1 Each Party shall adopt such legislative and other measures as may be necessary to empower its competent authorities to order: a. a person in its territory to submit specified computer data in that person’s possession or control, which is stored in a computer system or a computer-data storage medium; and b. a service provider offering its services in the territory of the Party to submit subscriber information relating to such services in that service provider’s possession or control. 2 The powers and procedures referred to in this article shall be subject to Articles 14 and 15. 3 For the purpose of this article, the term “subscriber information” means any information contained in the form of computer data or any other form that is held by a service provider, relating to subscribers of its services other than traffic or content data and by which can be established: a the type of communication service used, the technical provisions taken thereto and the period of service; b the subscriber’s identity, postal or geographic address, telephone and other access number, billing and payment information, available on the basis of the service agreement or arrangement; c any other information on the site of the installation of communication equipment, available on the basis of the service agreement or arrangement.
|
Section 28(2) (2) The Controller or any officer authorized by him in this behalf shall exercise the like powers which are conferred on Income-tax authorities under Chapter XIII of the Income-Tax Act, 1961 and shall exercise such powers, subject to such limitations laid down under that Act. Section 58(2) (2) The Cyber Appellate Tribunal shall have, for the purposes of discharging their functions under this Act, the same powers as are vested in a civil court under the Code of Civil Procedure, 1908, while trying a suit, in respect of the following matters, namely - (b) requiring the discovery and production of documents or other electronic records;
|
While the Cyber Appellate Tribunal and the Controller of Certifying Authorities both have the power to call for information under the IT Act, these powers can be exercised only for limited purposes since the jurisdiction of both authorities is limited to the procedural provisions of the IT Act and they do not have the jurisdiction to investigate penal provisions. In practice, the penal provisions of the IT Act are investigated by the regular law enforcement apparatus of India, which use statutory provisions for production orders applicable in the offline world to computer systems as well. It is a very common practice amongst law enforcement authorities to issue orders under the Code of Criminal Procedure, 1973 (section 91) or the relevant provisions of the Income Tax Act, 1961 to compel production of information contained in a computer system. The power to order production of a “document or other thing” under section 91 of the Criminal Procedure Code is wide enough to cover all types of information which may be residing in a computer system and can even include the entire computer system itself.
|
Convention on Cybercrime |
Information Technology Act, 2000
|
|
Article 19 – Search and seizure of stored computer data 1 Each Party shall adopt such legislative and other measures as may be necessary to empower its competent authorities to search or similarly access: a a computer system or part of it and computer data stored therein; and b a computer-data storage medium in which computer data may be stored in its territory. 2 Each Party shall adopt such legislative and other measures as may be necessary to ensure that where its authorities search or similarly access a specific computer system or part of it, pursuant to paragraph 1.a, and have grounds to believe that the data sought is stored in another computer system or part of it in its territory, and such data is lawfully accessible from or available to the initial system, the authorities shall be able to expeditiously extend the search or similar accessing to the other system. 3 Each Party shall adopt such legislative and other measures as may be necessary to empower its competent authorities to seize or similarly secure computer data accessed according to paragraphs 1 or 2. These measures shall include the power to: a seize or similarly secure a computer system or part of it or a computer-data storage medium; b make and retain a copy of those computer data; c maintain the integrity of the relevant stored computer data; d render inaccessible or remove those computer data in the accessed computer system. 4 Each Party shall adopt such legislative and other measures as may be necessary to empower its competent authorities to order any person who has knowledge about the functioning of the computer system or measures applied to protect the computer data therein to provide, as is reasonable, the necessary information, to enable the undertaking of the measures referred to in paragraphs 1 and 2. 5 The powers and procedures referred to in this article shall be subject to Articles 14 and15. |
76 Confiscation Any computer, computer system, floppies, compact disks, tape drives or any other accessories related thereto, in respect of which any provision of this Act, rules, orders or regulations made thereunder has been or is being contravened, shall be liable to confiscation: Provided that where it is established to the satisfaction of the court adjudicating the confiscation that the person in whose possession, power or control of any such computer, computer system, floppies, compact disks, tape drives or any other accessories relating thereto is found is not responsible for the contravention of the provisions of this Act, rules, orders or regulations made there under, the court may, instead of making an order for confiscation of such computer, computer system, floppies, compact disks, tape drives or any other accessories related thereto, make such other order authorized by this Act against the person contravening of the provisions of this Act, rules, orders or regulations made there under as it may think fit.
|
While Article 19 provides for the power to search and seize computer systems for the investigation into criminal offences of any type of kind, section 76 of the IT Act is limited only to contraventions of the provisions of the Act, rules, orders or regulations made thereunder. However, this does not mean that Indian law enforcement authorities do not have the power to search and seize a computer system for crimes other than those contained in the IT Act; just as in the case of Article 18, the authorities in India are free to use the provisions contained in the Criminal Procedure Code and other sectoral legislations which allow for seizure of property to seize computer systems when investigating criminal offences.
|
Convention on Cybercrime |
Information Technology Act, 2000
|
|
Article 20 – Real-time collection of traffic data 1 Each Party shall adopt such legislative and other measures as may be necessary to empower its competent authorities to: a collect or record through the application of technical means on the territory of that Party, and b compel a service provider, within its existing technical capability: i to collect or record through the application of technical means on the territory of that Party; or ii to co-operate and assist the competent authorities in the collection or recording of,
traffic data, in real-time, associated with specified communications in its territory transmitted by means of a computer system. 2 Where a Party, due to the established principles of its domestic legal system, cannot adopt the measures referred to in paragraph 1.a, it may instead adopt legislative and other measures as may be necessary to ensure the real-time collection or recording of traffic data associated with specified communications transmitted in its territory, through the application of technical means on that territory. 3 Each Party shall adopt such legislative and other measures as may be necessary to oblige a service provider to keep confidential the fact of the execution of any power provided for in this article and any information relating to it. 4 The powers and procedures referred to in this article shall be subject to Articles 14 and 15. |
69B Power to authorize to monitor and collect traffic data or information through any computer resource for Cyber Security (1) The Central Government may, to enhance Cyber Security and for identification, analysis and prevention of any intrusion or spread of computer contaminant in the country, by notification in the official Gazette, authorize any agency of the Government to monitor and collect traffic data or information generated, transmitted, received or stored in any computer resource. (2) The Intermediary or any person in-charge of the Computer resource shall when called upon by the agency which has been authorized under sub-section (1), provide technical assistance and extend all facilities to such agency to enable online access or to secure and provide online access to the computer resource generating , transmitting, receiving or storing such traffic data or information. (3) The procedure and safeguards for monitoring and collecting traffic data or information, shall be such as may be prescribed. (4) Any intermediary who intentionally or knowingly contravenes the provisions of sub-section (2) shall be punished with an imprisonment for a term which may extend to three years and shall also be liable to fine. Explanation: For the purposes of this section, (i) "Computer Contaminant" shall have the meaning assigned to it in section 43. (ii) "traffic data" means any data identifying or purporting to identify any person, computer system or computer network or location to or from which the communication is or may be transmitted and includes communications origin, destination, route, time, date, size, duration or type of underlying service or any other information.
|
Section 69B in the IT Act enables the government to authorise the monitoring and collection of traffic data through any computer system. Under the Convention, orders for collection and recording of traffic data can be given for the purposes mentioned in Articles 14 and 15. On the other hand, as per the Information Technology (Procedure and safeguard for Monitoring and Collecting Traffic Data or Information) Rules, 2009, an order for monitoring may be issued for any of the following purposes relating to cyber security:
(a) forecasting of imminent cyber incidents;
(b) monitoring network application with traffic data or information on computer resource;
(c) identification and determination of viruses or computer contaminant;
(d) tracking cyber security breaches or cyber security incidents;
(e) tracking computer resource breaching cyber security or spreading virus or computer contaminants;
(f) identifying or tracking of any person who has breached, or is suspected of having breached or being likely to breach cyber security;
(g) undertaking forensic of the concerned computer resource as a part of investigation or internal audit of information security practices in the computer resources;
(h) accessing a stored information for enforcement of any provisions of the laws relating to cyber security for the time being in force;
(i) any other matter relating to cyber security.
As can be seen from the above, the reasons for which an order for monitoring traffic data can be issued are extremely wide, this is in stark contrast to the reasons for which an order for interception of content data may be issued under section 69. The Rules also provide that the intermediary shall not disclose the existence of a monitoring order to any third party and shall take all steps necessary to ensure extreme secrecy in the matter of monitoring of traffic data.
|
Convention on Cybercrime |
Information Technology Act, 2000
|
|
Article 21 – Interception of content data 1 Each Party shall adopt such legislative and other measures as may be necessary, in relation to a range of serious offences to be determined by domestic law, to empower its competent authorities to: a collect or record through the application of technical means on the territory of that Party, and b compel a service provider, within its existing technical capability: i to collect or record through the application of technical means on the territory of that Party, or ii to co-operate and assist the competent authorities in the collection or recording of, content data, in real-time, of specified communications in its territory transmitted by means of a computer system. 2 Where a Party, due to the established principles of its domestic legal system, cannot adopt the measures referred to in paragraph 1.a, it may instead adopt legislative and other measures as may be necessary to ensure the real-time collection or recording of content data on specified communications in its territory through the application of technical means on that territory. 3 Each Party shall adopt such legislative and other measures as may be necessary to oblige a service provider to keep confidential the fact of the execution of any power provided for in this article and any information relating to it. 4 The powers and procedures referred to in this article shall be subject to Articles 14 and 15. |
69 Powers to issue directions for interception or monitoring or decryption of any information through any computer resource (1) Where the central Government or a State Government or any of its officer specially authorized by the Central Government or the State Government, as the case may be, in this behalf may, if is satisfied that it is necessary or expedient to do in the interest of the sovereignty or integrity of India, defense of India, security of the State, friendly relations with foreign States or public order or for preventing incitement to the commission of any cognizable offence relating to above or for investigation of any offence, it may, subject to the provisions of sub-section (2), for reasons to be recorded in writing, by order, direct any agency of the appropriate Government to intercept, monitor or decrypt or cause to be intercepted or monitored or decrypted any information transmitted received or stored through any computer resource. (2) The Procedure and safeguards subject to which such interception or monitoring or decryption may be carried out, shall be such as may be prescribed (3) The subscriber or intermediary or any person in charge of the computer resource shall, when called upon by any agency which has been directed under sub section (1), extend all facilities and technical assistance to - (a) provide access to or secure access to the computer resource containing such information; generating, transmitting, receiving or storing such information; or (b) intercept or monitor or decrypt the information, as the case may be; or (c) provide information stored in computer resource. (4) The subscriber or intermediary or any person who fails to assist the agency referred to in sub-section (3) shall be punished with an imprisonment for a term which may extend to seven years and shall also be liable to fine. |
There has been a lot of academic research and debate around the exercise of powers under section 69 of the IT Act, but the current piece is not the place for a standalone critique of section 69.[11] The analysis here is limited to a comparison of the provisions of Article 20 vis-à-vis section 69 of the IT Act.
In that background, it needs to be pointed out that two important issues mentioned in Article 20 of the Convention are not specifically mentioned in section 69B, viz. (i) that the order should be only for specific computer data, and (ii) that the intermediary should keep such an order confidential; these requirements are covered by Rules 9 and 20 of the Information Technology (Procedure and Safeguards for Interception, Monitoring and Decryption of Information) Rules, 2009, respectively.
|
Convention on Cybercrime |
Information Technology Act, 2000
|
|
Article 22 – Jurisdiction 1 Each Party shall adopt such legislative and other measures as may be necessary to establish jurisdiction over any offence established in accordance with Articles 2 through 11 of this Convention, when the offence is committed: a in its territory; or b on board a ship flying the flag of that Party; or c on board an aircraft registered under the laws of that Party; or d by one of its nationals, if the offence is punishable under criminal law where it was committed or if the offence is committed outside the territorial jurisdiction of any State. 2 Each Party may reserve the right not to apply or to apply only in specific cases or conditions the jurisdiction rules laid down in paragraphs 1.b through 1.d of this article or any part thereof. 3 Each Party shall adopt such measures as may be necessary to establish jurisdiction over the offences referred to in Article 24, paragraph 1, of this Convention, in cases where an alleged offender is present in its territory and it does not extradite him or her to another Party, solely on the basis of his or her nationality, after a request for extradition. 4 This Convention does not exclude any criminal jurisdiction exercised by a Party in accordance with its domestic law. 5 When more than one Party claims jurisdiction over an alleged offence established in accordance with this Convention, the Parties involved shall, where appropriate, consult with a view to determining the most appropriate jurisdiction for prosecution. |
1. Short Title, Extent, Commencement and Application (2) It shall extend to the whole of India and, save as otherwise provided in this Act, it applies also to any offence or contravention hereunder committed outside India by any person. 75 Act to apply for offence or contraventions committed outside India (1) Subject to the provisions of sub-section (2), the provisions of this Act shall apply also to any offence or contravention committed outside India by any person irrespective of his nationality. (2) For the purposes of sub-section (1), this Act shall apply to an offence or contravention committed outside India by any person if the act or conduct constituting the offence or contravention involves a computer, computer system or computer network located in India. |
The Convention provides for extra territorial jurisdiction only for crimes committed outside the State by nationals of that State. However, the IT Act applies even to offences under the Act committed by foreign nationals outside India, as long as the act involves a computer system or computer network located in India.
Unlike para 3 of Article 22 of the Convention, the IT Act does not touch upon the issue of extradition. Cases involving extradition would therefore be dealt with by the general law of the land in respect of extradition requests contained in the Extradition Act, 1962. The Convention requires that in cases where the state refuses to extradite an alleged offender, it should establish jurisdiction over the offences referred to in Article 21(1) so that it can proceed against that offender itself. In this regard, it must be pointed out that Section 34A of the Extradition Act, 1962 provides that “Where the Central Government is of the opinion that a fugitive criminal cannot be surrendered or returned pursuant to a request for extradition from a foreign State, it may, as it thinks fit, take steps to prosecute such fugitive criminal in India.” Thus the Extradition Act gives the Indian government the power to prosecute an individual in the event that such individual cannot be extradited.
International Cooperation
Chapter III of the Convention deals specifically with international cooperation between the signatory parties. Such co-operation is to be carried out both "in accordance with the provisions of this Chapter" and "through application of relevant international agreements on international cooperation in criminal matters, arrangements agreed to on the basis of uniform or reciprocal legislation, and domestic laws." The latter clause establishes the general principle that the provisions of Chapter III do not supersede the provisions of international agreements on mutual legal assistance and extradition or the relevant provisions of domestic law pertaining to international co-operation.[12] Although the Convention grants primacy to mutual treaties and agreements between member States, in certain specific circumstances it also provides for an alternative if such treaties do not exist between the member states (Article 27 and 28). The Convention also provides for international cooperation on certain issues which may not have been specifically provided for in mutual assistance treaties entered into between the parties and need to be spelt out due to the unique challenges posed by cyber crimes, such as expedited preservation of stored computer data (Article 29) and expedited disclosure of preserved traffic data (Article 30). Contentious issues such as access to stored computer data, real time collection of traffic data and interception of content data have been specifically left by the Convention to be dealt with as per existing international instruments or arrangements between the parties.
Conclusion
The broad language and wide terminology used IT Act seems to cover a number of the cyber crimes mentioned in the Budapest Convention, even though India has not signed and ratified the same. Penal provisions such as illegal access (Article 2), data interference (Article 4), system interference (Article 5), offence related to child pornography (Article 9), attempt and aiding or abetting (Article 11), corporate liability (Article 12) are substantially covered and reflected in the IT Act in a manner very similar to the requirements of the Convention. Similarly procedural provisions such as search and seizure of stored computer data (Article 19), real-time collection of traffic data (Article 20), interception of content data (Article 21) and Jurisdiction (Article 22) are also substantially reflected in the IT Act.
However certain penal provisions mentioned in the Convention such as computer related forgery (Article 7), computer related fraud (Article 8) are not provided for specifically in the IT Act but such offences are covered when provisions of the Indian Penal Code, 1860 are read in conjugation with provisions of the IT Act. Similarly procedural provisions such as expedited preservation of stored computer data (Article 16) and production order (Article 18) are not specifically provided for in the IT Act but are covered under Indian law through the provisions of the Code of Criminal Procedure, 1973.
Apart from the above two categories there are certain provisions such as misuse of devices (Article 6) and Illegal interception (Article 3) which may not be specifically covered at all under Indian law, but may conceivably be said to be covered through an expansive reading of provisions of the Indian Penal Code and the IT Act. It may therefore be said that even though India has not signed or ratified the Budapest Convention, the legal regime in India is substantially in compliance with the provisions and requirements contained therein.
Thus, the Convention on Cybercrime is perhaps the most important international multi state instruments that may be used to combat cybercrime, not merely because the provisions thereunder may be used as a model to bolster national/local laws by any State, be it a signatory or not (as in the case of India) but also because of the mechanism it lays down for international cooperation in the field of cyber terrorism. In an increasingly interconnected world where more and more information of individuals is finding its way to the cloud or other networked infrastructure the international community is making great efforts to generate norms for increased international cooperation to combat cybercrime and cyber terrorism. While the Convention is one such multilateral effort, States are also proposing to use bilateral treaties to enable them to better fight cybercrime, the United States CLOUD Act, being one such effort. In the backdrop of these novel efforts the role to be played by older instruments such as the Convention on Cybercrime as well as by important States such as India is extremely crucial.
[1] Explanatory Report to the Convention on Cybercrime, Para 304, https://rm.coe.int/16800cce5b.
[2] The analysis here has been limited to only Chapter I and Chapter II of the Convention, as it is only adherence to these two chapters that is required under the CLOUD Act.
[3] The only possible enforcement that may be done with regard to the Convention on Cybercrime is that the Council of Europe may put pressure on the signatory State to amend its local laws (if it is refusing to do so) otherwise it would be in violation of its obligations as a member of the European Union.
[4] Alexander Seger, “India and the Budapest Convention: Why Not?”, https://www.orfonline.org/expert-speak/india-and-the-budapest-convention-why-not/
[5] Explanatory Report to the Convention on Cybercrime, Para 50, https://rm.coe.int/16800cce5b.
[6] India is a party to the Berne Convention on Literary and Artistic Works, the Agreement on Trade Related Intellectual Property Rights and the Rome Convention. India has also recently (July 4, 2018) announced that it will accede to the WIPO Copyright Treaty as well as the WIPO Performances and Phonographs Treaty.
[7] The test under the Convention is that the relevant person would be the one who has a leading position within the company, based on:
- a power of representation of the legal person;
- an authority to take decisions on behalf of the legal person;
- an authority to exercise control within the legal person.
[8]Vipul Kharbanda and Elonnai Hickock, “MLATs and the proposed Amendments to the US Electronic Communications Privacy Act”, https://cis-india.org/internet-governance/blog/mlats-and-the-proposed-amendments-to-the-us-electronic-communications-privacy-act
[9] The term “human rights” has been defined in the Act as “rights relating to life, liberty, equality and dignity of the individual guaranteed by the Constitution or embodied in the International Covenants and enforceable by courts in India”.
[10] Explanatory Report to the Convention on Cybercrime, Para 151, https://rm.coe.int/16800cce5b. .
[11] A similar power of interception is available under section 5 of the Telegraph Act, 1885, but that extends only to interception of telegraphic communication and does not extend to communications exchanged through computer networks.
[12] Explanatory Report to the Convention on Cybercrime, Para 244, https://rm.coe.int/16800cce5b.
ICANN Workstream 2 Recommendations on Accountability
At the ICANN meeting in March of 2017 in Finland, the second Work Stream (WS2) was launched. The Cross Community Working Group submitted their final report at the end of June 2018 and the purpose of this blog is to look at the main recommendations given and the steps ahead to its implementation.
The new Workstream was structured into the following 8 independent sub groups as per the topics laid down in the WS1 final report, each headed by a Rapporteur:
1. Diversity
2. Guidelines for Standards of Conduct Presumed to be in Good Faith Associated with Exercising Removal of Individual ICANN Board Directors. (Guidelines for Good Faith)
3. Human Rights Framework of Interpretation (HR-FOI)
4. Jurisdiction
5. Office of the Ombuds
6. Supporting Organization/ Advisory Committee Accountability
7. Staff Accountability
8. ICANN Transparency
1. DIVERSITY Recommendations
The sub-group on Diversity suggested ways by which ICANN can define, measure, report, support and promote diversity. They proposed 7 key factors to guide all diversity considerations: Language, Gender, Age, Physical Disability, Diverse skills, Geographical representation and stakeholder group. Each charting organization within ICANN is asked to undertake an exercise whereby they publish their diversity obligations on their website, for each level of employment including leadership either under their own charter or ICANN Bylaws. This should be followed by a diversity assessment of their existing structures and consequently used to formulate their diversity objectives/criteria and steps on how to achieve the same along with the timeline to do so. These diversity assessments should be conducted annually and at the very least, every 3 years. ICANN staff has been tasked with developing a mechanism for dealing with complaints arising out of diversity and related issues. Eventually, it is envisioned that ICANN will create a Diversity section on their website where an Annual Diversity Report will be published. All information regarding Diversity should also be published in their Annual Report.
The recommendations leave much upto the organization without establishing specific recruitment policies for equal opportunities. In their 7 parameters, race was left out as a criteria for diversity. The criteria of ‘diverse skills’ is also ambiguous; and within stakeholder group, it would have been more useful to highlight the priority for diversity of opinions within the same stakeholder group. So for example, to have two civil society organizations (CSOs) advocating for contrasting stances as opposed to having many CSO’s supporting one stance. However, these steps should be a good starting point to improve the diversity of an organization which in our earlier research we have found to be neither global nor multistakeholder. In fact, our recent diversity analysis has shown concerns such as the vast number of the end users participating and as an extension, influencing ICANN work are male. The mailing list where the majority of discussions take place are dominated by individuals from industry bodies. This coupled with the relative minority presence of the other stakeholders, especially geographically (14.7% participation from Asian countries), creates an environment where concerns emanating from other sections of the society could be overshadowed. Moreover, when we have questioned ICANN’s existing diversity of employees based on their race and citizenship, they did not give us the figures citing either lack of information or confidentiality.
2. HUMAN RIGHTS FRAMEWORK OF INTERPRETATION (HR-FOI)
A Framework of Interpretation was developed by the WS2 for ICANN Bylaws relating to Human Rights which clarified that Human Rights are not a Commitment for the organization but is a Core Value. The former being an obligation while the latter are “not necessarily intended to apply consistently and comprehensively to ICANN’s activities”.
To summarize the FOI, if the applicable law i.e. the law practiced in the jurisdiction where ICANN is operating, does not mandate certain human rights then they do not raise issues under the core value. As such, there can be no enforcement of human rights obligations by ICANN or any other party against any other party. Thus, contingent on the seat of the operations the law can vary though by in large ICANN recognizes and can be guided by significant internationally respected human rights such as those enumerated in the Universal Declaration of Human Rights. The United Nations Guiding Principles for Business and Human Rights was recognized as useful in the process of applying the core value in operations since it discusses corporate responsibility to respect human rights. Building on this, Human Right Impact Assessments (HRIA) with respect to ICANN policy development processes are currently being formulated by the Cross Community Working Group on Human Rights. Complementing this, ICANN is also undertaking an internal HRIA of the organization’s operations. It is important to remember that the international human rights instruments that are relevant here are those required by the applicable law.
Apart from its legal responsibility to uphold the HR laws of an area, the framework is worded negatively in that it says ICANN should in general avoid violating human rights. It is also said that they should take into account HR when making policies but these fall short from saying that HR considerations should be given prominent weightage and since there are many core values, at any point one of the others can be used to sidestep human rights. One core value in particular says that ICANN should duly consider the public policy advice of governments and other authorities when arriving at a decision. Thus, if governments want to promote a decision to further national interests at the expense of citizen’s human rights then that would be very much possible within this FOI.
3. JURISDICTION
A highly contentious issue in WS2 was that of Jurisdiction, and the recommendations formed to tackle it were quite disappointing. Despite initial discussion by the group on ICANN’s location, they did not address the elephant in the room in their report. Even after the transition, ICANN’s new by-laws state that it is subject to California Law since it was incorporated there. This is partly the fault of the first Workstream because when enumerating the issues for WS2 with respect to jurisdiction, they left it ambiguous by stating: :
“At this point in the CCWG Accountability’s work, the main issues that need within Work Stream 2 relate to the influence that ICANN ́s existing jurisdiction may have on the actual operation of policies and accountability mechanisms. This refers primarily to the process for the settlement of disputes within ICANN, involving the choice of jurisdiction and of the applicable laws, but not necessarily the location where ICANN is incorporated.”
Jurisdiction can often play a significant role in the laws that ICANN will have to abide by in terms of financial reporting, consumer protection, competition and labour laws, legal challenges to ICANN’s actions and finally, in resolving contractual disputes. In its present state, the operations of ICANN could, if such a situation arises, see interference from US authorities by way of legislature, tribunals, enforcement agencies and regulatory bodies.
CIS has, in the past, discussed the concept of “jurisdictional resilience”, which calls for:
- Legal immunity for core technical operators of Internet functions (as opposed to policymaking venues) from legal sanctions or orders from the state in which they are legally situated.
- Division of core Internet operators among multiple jurisdictions
- Jurisdictional division of policymaking functions from technical implementation functions
Proposing to change ICANN’s seat of headquarters or at the very least, suggest ways for ICANN to gain partial immunity for its policy development processes under the US law would have gone a long way in making ICANN truly a global body. It would have also ensured that as an organization, ICANN would have been equally accountable to all its stakeholders as opposed to now, where by virtue of its incorporation, it has higher legal and possible political, obligations to the United States. This was (initially?) expressed by Brazil who dissented from the majority conclusions of the sub-group and drafted their own minority report, which was supported by countries like Russia. They were unhappy that all countries are still not at an equal footing in the participation of management of Internet resources, which goes against the fundamentals of the multi-stakeholder system approach.
Recommendations:
The recommendations passed were in two categories:
- Office of Foreign Asset Control (OFAC)
OFAC is an office of the US Treasury administering and enforcing economic and trade sanctions based on the American foreign policy and national security objectives. It is pertinent because, for ICANN to enter into a Registration Accreditation Agreement (RAA) with an applicant from a sanctioned country, it will need an OFAC license. What happens right now is that ICANN is under no obligation to request for this license and in either case, OFAC can refuse to provide it. The sub group recommended that the terms of the RAA be modified so that ICANN is required to apply for and put their best efforts in securing the license if the applicant is qualified to be a registrar and not individually subject to sanctions. While the licensing process is underway they should also be helpful and transparent, and maintain on-going communication with the applicant. The same recommendation was made for applicants to the new gTLD program, from sanctioned countries. Other general licenses are needed from OFAC for certain ICANN transactions and hence it was proposed that ICANN pursue the same.
2. Choice of law and Choice of Venue Provisions in ICANN Agreements
In ICANN’S Registry Agreements (RA) and Registration Accreditation Agreement (RAA) the absence of a choice of law provision means that the governing law of these contracts is undetermined until later decided by a judge or arbitrator or an agreement between the parties. It was collectively seen that increased freedom of choice for the parties in the agreement could help in customizing the agreements and make it easier for registries and such to contractually engage with ICANN. Out of various options, the group decided that a Menu approach would be best whereby a host of options(decided by ICANN) can be provided and the party in case choose the most appropriate from them such as the jurisdiction of their incorporation.In RAs, the choice of venue was pre determined as Los Angeles, California but the group recommended that instead of imposing this choice on the party it would be better to offer a list of possible venues for arbitration. The registry can then choose amongst these options when entering into the contract. There were other issues discussed which did not reach fruition due to lack of unanimity such as discussions on immunity of ICANN from US jurisdiction.
4. OFFICE OF THE OMBUDS
Subsequent to the external evaluation of the ICANN Office of the Ombuds (IOO), there were a couple of recommendations to strengthen the office. They were divided into procedural aspects that the office should carry out to improve their complaint mechanism such as differentiating between categories of complaints and explaining how each type would be handled with. The issues that would not invoke actions from the IOO should also be established clearly and if and where these could be transferred to any other channel. The response from all the relevant parties of ICANN to a formal request or report from the IOO should take place within 90 days, and 120 at the maximum if an explanation for the same can be provided. An internal timeline will be defined by the office for handling of complaints and document a report on these every quarter or annually. A recommendation for the IOO to be formally trained in mediation and have such experience within its ranks was further given. Reiterating the importance of diversity, even this sub group emphasized on the IOO bearing a diverse group in terms of gender and other parameters. This ensures that a complainant has a choice in who to approach in the office making them more comfortable. To enhance the independence of the Ombuds, their employment contract should have a 5 year fixed term which only allows for one extension of maximum 3 years. An Ombuds Advisory Panel is to be constituted by ICANN comprising five members to act as advisers, supporters and counsel for the IOO with at least 2 members having Ombudsman experience and the remaining possessing extensive ICANN experience. They would be responsible for selecting the new Ombuds and conducting the IOO’s evaluation every 5 years amongst others. Lastly, the IOO should proactively document their work by publishing reports on activity, collecting and publicizing statistics, user satisfaction information a well any improvements to the process.
These proposals still do not address the opacity of how the Office of the Ombuds resolve these cases since it does not call for; a) a compilation of all the cases that have been decided by the office in the history of the organization b) the details of the parties that are involved if the parties have allowed that to be revealed and if not at the very least, the non sensitive data such as their nationality and stakeholder affiliation and c) a description of the proceedings of the case and who won in each of them. When CIS asked for the above in 2015, the information was denied on ground of confidentiality. Yet, it is vital to know these details since the Ombuds hear complaints against the Board, Staff and other constituent bodies and by not reporting on this, ICANN is rendering the process much less accountable and transparent. This conflict resolution process and its efficacy is even more essential in a multi-stakeholder environment so as to give parties the faith to engage in the process, knowing that the redressal mechanisms are strong. It is also problematic that sexual harassments complaints are dealt by the Ombuds and that ICANN does not have a specific Anti-Sexual Harassment Committee. The committee should be neutral and approachable and while it is useful for the Office of the Ombuds to be trained in sexual harassment cases, it is by no means a comprehensive and ideal approach to deal with complaints of this nature. Despite ICANN facing a sexual harassment claim in 2016, the recommendations do not specifically address the approach the Ombuds should take in tackling sexual harassment.
5. SUPPORTING ORGANIZATION/ ADVISORY COMMITTEE ACCOUNTABILITY
The sub group presented the outcomes under the main heads of Accountability, Transparency, Participation, Outreach and Updates to policies and procedures. They suggested these as good practices that can be followed by the organizations and did not recommend that implementation of the same be required. The accountability aspect had suggestions of better documentation of procedures and decision-making. Proposals of listing members of such organizations publicly, making their meetings open to public observation including minutes and transcripts along with disclosing their correspondence with ICANN were aimed at making these entities more transparent. In the same vein, rules of membership and eligibility criteria, the process of application and a process of appeal should be well defined. Newsletters should be published by the SO/AC to help non-members understand the benefit and the process of becoming a member. Policies were asked to be reviewed at regular intervals and these internal reviews should not extend beyond a year.
6. STAFF ACCOUNTABILITY
Improving the ICANN staff’s Accountability was the job of a different group who assessed it at the service delivery, departmental or organizational level not at an individual or personnel level. They did this by analysing the roles and responsibilities of the Board, staff and community members and the nexus between them. Their observations culminated in the understanding that ICANN needs to take steps such as make visible their performance management system and process, their vision for the departmental goals and how they tie in to the organization’s strategic goals and objectives. They note that several new mechanisms have already been established yet have not been used enough to ascertain their efficacy and thus, propose a regular information acquisition mechanism. Most importantly, they have asked ICANN to standardize and publish guidelines for suitable timeframes for acknowledging and responding to requests from the community.
7. ICANN TRANSPARENCY
The last group of the WS2 was one specifically looking at the transparency of the organization.
a. The Documentary Information Disclosure Policy (DIDP)
Currently the DIDP process only applies to ICANN’s “operational activities”, it was recommended to delete this caveat to cover a wider breadth of the organization’s activities. As CIS has experienced, request for information is often met with an answer that such information is not documented and to remedy the same, a documentation policy was proposed where if significant elements of a decision making process are taking place orally then the participants will be required to document the substance of the conversation. Many a times DIDP requests are refused because one aspect of the information sought is subject to confidentiality. hus one of the changes is to introduce a severability clause so that in such cases, information can still be disclosed with the sensitive aspect redacted or severed. In scenarios of redaction, the rationale should be provided citing one of the given DIDP exceptions along with the process for appeal. ICANN’s contracts should be under the purview of the DIDP except when subject to a non-disclosure agreement and further, the burden is on the other party to convince ICANN that it has a legitimate commercial reason for requested the NDA. No longer would any information pertaining to the security and stability of the Internet be outside the ambit of the DIDP but only if it is harmful to the security and stability. Finally, ICANN should review the DIDP every five years to see how it can be improved.
b. Documenting and Reporting on ICANN’s Interactions with the Government
In a prominent step towards being more transparent with their expenditure and lobbying, the group recommended that ICANN begins disclosing publicly on at least an annual basis, sums of $20,000 per year devoted to “political activities” both in the US and abroad. All expenditures should be done on an itemized basis by ICANN for both outside contractors and internal personnel along with the identities of the persons engaging in such activities and the type of engagement used for such activities amongst others.
cc. Transparency of Board Deliberations
The bylaws were recommended to be revised so that material may be removed from the minutes of the Board if subject to a DIDP exception. The exception for deliberative processes should not apply to any factual information, technical report or reports on the performance or effectiveness of a particular body or strategy. When any information is removed from the minutes of the Board meeting, they should be disclosed after a particular period of time as and when the window of harm has passed.
d. ICANN’s Anonymous Hotline (Whistle-blower Protection)
To begin with, ICANN was recommended to devise a way such that when anyone searches their website for the term “whistle-blower”, it should redirect to their Hotline policy since people are unlikely to be aware that in ICANN parlance it is referred to as the Hotline policy. Instead of only “serious crimes” that are currently reported, all issues and concerns that violate local laws should be. Complaints should not be classified as ‘urgent’ and ‘non-urgent’ but all reports should be a priority and receive a formal acknowledgment within 48 hours at the maximum. ICANN should make it clear that any retaliation against the reporter will be taken and investigated as seriously as the original alleged wrongdoing. Employees should be provided with data about the use of the Hotline, including the types of incidents reported. Few member of this group came out with a Minority Statement expressing their disapproval with one particular aspect of the recommendations that they felt was not developed enough, the one pertaining to ICANN’s attorney-client privilege. The recommendation did not delve into specifics but merely stated that ICANN should expand transparency in their legal processes including clarifying how attorney-client privilege is invoked. The dissidents thought ICANN should go farther and enumerate principles where the privilege would be waived in the interests of transparency and account for voluntary disclosure as well.
The transparency recommendations did not focus on the financial reporting aspects of ICANN which we have found ambiguities with before. Some examples are; the Registries and Registrars are the main sources of revenue though there is ambiguity as to the classifications provided by ICANN such as the difference between RYG and RYN. The mode of contribution of sponsors isn’t clear either so we do not know if this was done through travel, money, media partnerships etc. Several entities have been listed from different places in different years, sometimes depending on the role they have played such as whether they are a sponsor or registry. Moreover, the Regional Internet Registries are clubbed under one heading and as a consequence it is not possible to determine individual RIR contribution like how much did APNIC pay for the Asia and Pacific region. Thus, there is a lot more scope for ICANN to be transparent which goes beyond the proposals in the report.
It is worth noting that whereas the mandate of the WS1 included the implementation of the recommendations, this is not the case for WS2 and thus, by creating a report itself the mission of the group is concluded. This difference can be attributed to the fact that during the first WS, there was a need to see it through since the IANA transition would not happen otherwise. The change in circumstances and the corresponding lack of urgency render the process less powerful, the second time round. The final recommendations are now being discussed in the relevant charting organizations within ICANN such as the Government Advisory Council (GAC) and subsequent to their approval,, it will be sent to the Board who will decide to adopt them or not. If adopted, ICANN and its sub organizations will have to see how they can implement these recommendations. The co-chairs of the group will be the point of reference for the chartering organizations and an implementation oversight team has been formed, consisting of the Rapporteurs of the sub teams and the co-chairs. A Feasibility Assessment Report will be made public in due time which will describe the resources that would take to implement the recommendations. Since it would be a huge undertaking for ICANN to implement the above, the compliance process is expected to take a few years. .
The link to report can be found here.
Regulating the Internet: The Government of India & Standards Development at the IETF
This brief was authored by Aayush Rathi, Gurshabad Grover and Sunil Abraham. Click here to download the policy brief.
Executive Summary
The institution of open standards has been described as a formidable regulatory regime governing the Internet. As the Internet has moved to facilitate commerce and communication, governments and corporations find greater incentives to participate and influence the decisions of independent standards development organisations.
While most such bodies have attempted to systematise fair and transparent processes, this brief highlights how they may still be susceptible to compromise. Documented instances of large private companies like Microsoft, and governmental instrumentalities like the US National Security Agency (NSA) exerting disproportionate influence over certain technical standards further the case for increased Indian participation.
The debate around Transport Layer Security (TLS) 1.3 at the Internet Engineering Task Force (IETF) forms an important case for studying how a standards body responded to political developments, and how the Government of India participated in the ensuing discussions. Lasting four years, the debate ended in favour of greater communications security. One of the security improvements in TLS 1.3 over its predecessor is that is makes less information available to networking middleboxes. Considering that Indian intelligence agencies and government departments have expressed fears of foreign-manufactured networking equipment being used by foreign intelligence to eavesdrop on Indian networks, the development is potentially favourable for the security of Indian communication in general, and the security of military and intelligence systems in particular. India has historically procured most networking equipment from foreign manufacturers. While there have been calls for indigenised production of such equipment, achieving these objectives will necessarily be a gradual process. Participating in technical standards can, then, be an effective interim method for intelligence agencies, defence wings and law enforcement for establishing trust in critical networking infrastructure sourced from foreign enterprises.
Outlining some of the existing measures the Indian government has put in place to build capacity for and participate in standard setting, this brief highlights that while these are useful starting points, they need to be harmonised and strengthened to be more fruitful. Given the regulatory and domestic policy implications that technical standards can have, there is a need for Indian governmental agencies to focus adequate resources geared towards achieving favourable outcomes at standards development fora.
Click here to download the policy brief.
Note: The recommendations in the brief were updated on 17 December 2018 to reflect the relevance of technical standard-setting in the recent discussions around Indian intelligence concerns about foreign-manufactured networking equipment.
Cyberspace and External Affairs:A Memorandum for India Summary
It limits itself to advocating certain procedural steps that the Ministry of External Affairs should take towards propelling India forward as a leading voice in the global cyber norms space and explains why occupying this leadership position should be a vital foreign policy priority. It does not delve into content-based recommendations at this stage. Further, this memorandum is not meant to serve as exhaustive academic research on the subject but builds on previous research by the Centre for Internet & Society in this area to highlight key policy windows that can be driven by India.
This memorandum provides a background to global norms formation focussing on key global developments over the past month; traces the opportunities s for India to play a lead role in the global norms formulation debate and then charts out process related recommendations on next steps towards India taking this forward.
Click here to read more
A Critical Look at the Visual Representation of Cybersecurity
- Edited by Karan Saini / Illustrations by - Paul Anthony George, and Roshan Shakeel
- Download the file here
The existing imagery comprises of largely stereotypical images of silhouettes of men in hoodies, binary codes, locks, shields; all in dark tones of blue and green. The workshop aimed at identifying the concerns with these existing images and ideating on creating visuals that capture the nuanced concepts within cybersecurity as well as to contextualise them for the Global South. It began with a discussion on the various concepts within cybersecurity including disinformation, surveillance in the name of security, security researchers, regulation of big technology companies, gender and cybersecurity, etc. This was followed by a mapping of different visual elements in the existing cybersecurity imagery to infer the biases in them. Further, an ideation session was conducted to create alternate visualisations that counter these biases. A detailed report of the workshop can be read here.
The participants began by discussing the concerning impacts of present visualisations – there is a lack of representation and context of the global south. Misrepresentation of cybersecurity leads people to be susceptible to disinformation, treats cybercrime as an abstract concept that does not have a direct impact, and oversimplifies the problem and its solutions. The ecosystem in which this imagery exists also presented a larger issue. A majority of the images are created as clickbait alongside media articles. Media houses thus benefit from the oversimplification and mystification of cybersecurity in such images.
Through the mapping of existing images present online, several concerns were identified. The vague elements and unclear representation add to the mystification of cybersecurity as a concept. In present depictions, the use of technological devices and objects, leads to the lack of a human element, distancing the threat from any real impact to people using these devices. The metaphor of a physical threat is often used to depict cybersecurity using elements such as a lock and key. Recurring use of these elements gives a false idea of what is being secured or breached and how. Representations rely on tropes regarding the identity of hackers, and fail to capture the vulnerability of the system. The imagery gives the impression that systems which are breached are immensely secure to begin with and are compromised only as a result of sophisticated attacks carried out by malicious actors. The identity of hackers is commonly associated with cyber attacks and breaches, and the existing imagery reinforces this. Visuals showing a masked man or a silhouette of a man in dark background are the usual markers of a malicious hacker in conventional cybersecurity imagery. While there is a lack of representation of women in stock cybersecurity images, another trope found was that of a cheerful woman coder. There were also images of faceless women with laptops[1]. The reductive nature of these images point to deeper concerns around gender representation in cybersecurity.
The participants examined what the implications of such visual representation would be, and why there is a need to change the imagery. How can visual depictions be more representative? Can they avoid subscribing to a homogenised idea of an Indian context – specific without being reductive? Can better depiction broaden understanding of cybercrime and emphasize the proximity of those threats? With technology, concepts are often understood through metaphors – how data is explained impacts how people perceive it. Visual imagery can play a critical role in demystifying concepts when done well; illustrations can change the discourse. They must begin to incorporate intersecting aspects of gender, privacy, susceptibility of vulnerable populations, generational and cultural gaps, as well as manifestations of the described crimes to make technological laypersons more aware of the threat.
Potential new imagery would need to address aspects such as disinformation, the importance of privacy and who has a right to it, change representation of hackers, depict the cybersecurity community, explain specific concepts to both – the general user and to the people part of cybersecurity efforts in the country, the implications of cybercrime on vulnerable populations, and more in an attempt to deconstruct and disseminate what cybersecurity looks like today.
The ideation session involved rethinking specific concepts such as disinformation, and ethical hacking to create alternate imagery. For instance, disinformation was visually imagined as a distortion of an already distorted message being perceived by the viewer. In order to bring attention to the impact of devices, a phone was thought of as a central object to which different concepts of cybersecurity can be connected.

‘Fake News Cascade’ by Paul Anthony George

‘Fake News’ by Paul Anthony George


‘Disinformation/ Fake News’ by Roshan Shakeel; The sketch is about questioning the validity of what we see online, and that every message we see is constructed in some form or the other by someone else.

‘Disinformation/ Fake News’ by Roshan Shakeel; The sketch visualizes how the source of information ('the original') gets distorted after a certain point.
For ethical hacking, a visualisation depicting a day in the life of an ethical hacker was thought of to normalize hacking and to focus on their contribution in security research.

‘A Day in the Life of an Indian Hacker’ by Paul Anthony George

'Surveillance in the Name of Security' by Roshan Shakeel
Resources on ethical hacking (HackerOne)[2] and hacker culture (2600.com)[3] were also consulted as part of the exercise to gather references on the work done by hackers. This allowed a deeper understanding of how the hacker community depicts itself. Check Point Research[4] and Kerala Police Cyberdome[5] were also examined for further insight into cybersecurity. With regard to gender representation, sources that use visual techniques to communicate concerns and advocacy campaigns were also referred to. The Gendering Surveillance[6] initiative by the Internet Democracy project[7], which looks at how surveillance harms and restricts women, also offered insights on the use of illustrations supporting the case studies. Another reference was the "Visualising Women's Rights in the Arab World"[8] project by the Tactical Technology Collective[9]. The project aims to “strengthen the use of visual techniques by women's rights advocates in the Arab world, and to build a network of women with these skills”.[10]
More visual explainers and animations[11] from the Tactical Technology Collective were noted for their broader engagement with digital security and privacy. A video by the Internet Democracy Project that explains the Internet through rangoli[12], was observed specifically for setting the concept in Indian context through the use of aesthetics.
The workshop concluded with a discussion of potential visual iterations – imagery of cybersecurity that is not technology-oriented but focussed on the behavioural implications of access to such technology, illustrated public service announcements enhancing the profile of cybersecurity researchers or the everyday hacker. The impact of the discussion itself can indicate the relevance of such an effort. Artists and designers can be encouraged to create a body of imagery that shifts discourse and perception, to begin visualising for advocacy, demystify and stop the abstraction of cybercrime that can lead to a false sense of security, incorporate unique aspects of the debate within the Indian context, and generate new dialogue and understanding of cybersecurity. A potential step forward from this workshop would be to engage with the design community at large along with the domain experts to create more effective imagery for cybersecurity.
[1] https://www.hackerone.com/
[2] https://2600.com/
[3] https://research.checkpoint.com/about-us/
[4] http://www.cyberdome.kerala.gov.in/
[5] https://genderingsurveillance.internetdemocracy.in/
[6] https://internetdemocracy.in/
[7] https://visualrights.tacticaltech.org/index.html
[8] https://tacticaltech.org/
[9] https://visualrights.tacticaltech.org/content/about-website.html
[10] https://tacticaltech.org/projects/survival-in-the-digital-age-ono-robot-2012/
[11] https://internetdemocracy.in/2018/08/dots-and-connections/
[12] https://www.independent.co.uk/life-style/gadgets-and-tech/features/women-in-tech-its-time-to-drop-the-old-stereotypes-7608794.html
Event Report on Intermediary Liability and Gender Based Violence
With inputs and edited by Ambika Tandon. Click here to download the PDF
Introduction
Background
The topic of discussion was intermediary liability and Gender Based Violence (GBV), the debate on GBV globally and in India evolving to include myriad forms of violence in online spaces in the past few years. This ranges from violence native to the digital, such as identity theft, and extensions of traditional forms of violence, such as online harassment, cyberbullying, and cyberstalking[1]. Given the extent of personal data available online, cyber attacks have led to a variety of financial and personal harms.[2] Studies have explored the extent of psychological and even physical harm to victims, which has been found to have similar effects to violence in the physical world[3]. Despite this, technologically-facilitated violence is often ignored or trivialised. When present, redressal mechanisms are often inadequate, further exacerbating the effects of violence on victims.
TheRoundtable explored ways of how intermediaries can help tackle gender based violence and discussed attempts at making the Internet a safer place for women which can ultimately help make it a gender equal environment. It also analyzed the key concerns of privacy and security leading the conversation to how we can demand more from platforms for our protection and how best to regulate them.
The roundtable had four female and one male participants from various civil society organisations working on rights in the digital space.
Roundtable Discussion
Online Abuse
The discussion commenced with the acknowledgement of it being well documented that women and sexual minorities face a disproportionate level of violence in the digital space, as an extension/reproduction of physical space. GBV exists on a continuum from the physical, verbal, and technologically enabled, either partially or fully, with overflowing boundaries and deep interconnections between different kinds of violence. Some forms of traditional violence such as harassment, stalking, bullying, sex trafficking, extend themselves into the digital realm while other forms are uniquely tech enabled like doxxing and morphing of imagery. Due to this considerations of anonymity, privacy, and consent, need to be re-thought in the context of tech enabled GBV. These come into play in a situation where the technological realm has largely been corporatised and functions under the imperative of treating the user and their data as the final product.
It was noted early on that GBV online can be a misnomer because it can be across a number of spaces and, the participants concentrated on laying down the specific contours of tech mediated or tech enabled violence. One of the discussants stated that the term GBV is a not a useful one since it does not encompass everything that is talked about when referring to online abuse. The phenomenon that gets the most traction is trolling on social media or abuse on social media. This is partly because it is the most visible people who are affected by it, and also since often, it is the most difficult to treat under law. In a 2012 study by the Internet Democracy Project focusing on online verbal abuse in social media, every woman they interviewed started by asserting that she is not a victim. The challenge with using the GBV framework is that it positions the woman as a victim. Other incidents on social media such as verbal abuse where there are rape threats or death threats, especially when there is an indication that the perpetrator is aware of the physical location of the victim, need to be treated differently from say online trolling.
Further, certain forms of violence, such as occurrences of ‘revenge porn’ or the non-consensual sharing of intimate images, including rape videos are easier to fit within the description of GBV. It is important to make these distinctions because the remedies then should be commensurate with perceived harm. It is not appropriate to club all of these together since the criminal threshold for each act is different. Whereas being called a “slut” or a “bitch” would not be enough for someone to be arrested, if a woman is called that repetitively by a large number of people the commensurate harm could be quite significant. Thus, using GBV as a broad term for all forms of violence ends up invisiblising certain forms of violence and prevents a more nuanced treatment of the discussion.
In response to this, a participant highlighted the normalisation of gendered hate speech, to the extent of lack of recognition as a form of hate speech. This lacunae in our law stems from the fact that we inherited our hate speech laws from a colonial era where it was based on the grounds of incitement of violence, more so physical violence. As a result, we do not take the International Covenant on Civil and Political Rights (ICCPR) standard of incitement to discrimination. If the law was based on an incitement to discriminate point of view then acts of trolling could come under hate speech. Even in the United Kingdom where there is higher sentencing for gender based crime as compared to other markers of identity such as race, gender does not fall under the parameters of hate speech. This can also be attributed to the threshold at which criminalization kicks in for such acts.
A significant aspect of online verbal abuse pointed out by a participant was that it does not affect all women equally. In a study, the Twitter accounts of 12 publicly visible women across the political spectrum were looked at for 2 weeks in early December, 2017. They were filtered against keywords and analyzed for abusive content. One Muslim woman in the study had extremely high levels of abuse, being consistently addressed as “Jihad man, Jihad didi or Jihad biwi”. According to the participant, she is also the least likely to get justice through the criminal system for such vitriol and as such, this disparity in the likelihood of facing online abuse and accessing official redressal mechanisms should be recognized. Another discussant reaffirmed the importance of making a distinction between online abuse against someone as opposed to gender based violence online where the threat itself is gendered.
In a small ethnographic study with the Bangalore police undertaken by one of the participants, the police were asked for their opinion on the following situation: A women voluntarily providers photos of herself in a relationship and once the relationship is over, the man distributes it. Is there a cause for redressal?
Policemen responded that since she gave it voluntarily in the first instance, the burden of the consequences is now on her. So even in a feminist framework of consent and agency where we have laws for actions of voyeurism and publishing photos of private parts, it is not being recognized by institutional response mechanisms.
Intermediary Liability
Private communications based intermediaries can be understood to be of two types: those that enable the carriage/transmission of communications and provide access to the internet, and those that host third party content. The latter have emerged as platforms that are central to the exercising of voice, the exchange of information and knowledge, and even the mobilisation of social movements. The norms and regulations around what constitutes gender based violence in this realm is then shaped not only by state regulations, but content moderation standards of these intermediaries. Further, the kinds of preventive tools and tools providing redressal are controlled by these platforms. More than before, we are looking deeper into the role of these companies that function as intermediaries and control access to third party content without performing editorial functions.
In the Intermediary Liability framework in the United States formulated in the 1990s, the intermediaries that were envisioned were not the intermediaries we have now. With time, the intermediary today is able to access and possess your data while urging a certain kind of behaviour from you. There is then an intermediary design duty which is not currently accounted for by the law. Moreover, the law practices a one size fits all regime whereas what could be more suitable is having approached tailored as per the offence. So for child pornography, a ‘removal when uploaded’ action using artificial intelligence or machine learning is appropriate but a notice and takedown approach is better for other kinds of content takedown.
Globally, another facet is that of safe harbour provisions for platforms. When intermediaries such as Google and Facebook were established, they were thought of as neutral pipes since they were not creating the content but only facilitating access. However, as they have scaled and as their role in ecosystem has increased, they are now one of the intervention points for governments as gatekeepers of free speech. One needs to be careful in asking for an expansion of the role and responsibilities of platforms because then complementary to that we will also have to see that the frameworks regulating them need to be revisited. Additionally, would a similar standard be applicable to larger and smaller intermediaries, or do we need layers of distinction between their responsibilities? Internet platforms such as the GAFA (Google, Apple, Facebook and Amazon) yield exceptional power to dictate what discourse takes place and this translates into the the online and offline divide disappearing. Do we then hold these four intermediaries to a separate and higher standard? If not, then all small players will be held to stringent rules disadvantaging their functioning and ultimately, stifling innovation. Thus, regulation is definitely needed but instead of a uniform one, one that’s layered and tailor-made to different situations and platform visibility levels could be more useful.
Some participants shared the opinion that because these intermediaries are based in foreign countries and have primary legal obligations there, the insulation plays out in the citizen’s benefit. It lends itself a layer of freedom of speech and expression that is not present in the substantive law, rule of law framework or the institutional culture in India.
Child pornography is an area where platforms are taking a lot of responsibility. Google has spoken about how they have been using machine learning algorithms to block 40% of such content and Microsoft is also working on a similar process. If we argue for more intervention from platforms, we simultaneously also need to look at their machine learning algorithms. Concerns of how these algorithms are being deployed and further, being incorporated into the framework of controlling child pornography are relevant since there is not much accountability and transparency regarding the same.
Another fraction that has emerged from recent events is the divide between traditional form of media and new media. Taking the example of rape victims and sexual harassment claims, there are strict rules regarding the kinds of details that can be disclosed and the manner in which this is to be done. In the Kathua rape case, for instance, the Delhi High Court sent a notice to Twitter and Facebook for revealing details because there are norms around this even though they have not been applicable to platforms. Hence, there are certain regulations that apply to old media that have now escaped in the frameworks applicable to the new media and at some level that gap needs to be bridged.
Role of Law
One of the participants brought up the question; what is the proper role of the law and does it come first or last? In case of the latter, the burden then falls upon the kind of standard setting that we do as a society. The role of platforms as an entity in mediating the online environment was discussed, given the concerns that have been highlighted about this environment, especially for women. The third thing to be considered is whether we run the risk of enforcing patriarchal behaviour by doubling down on the either of the two aforementioned factors. If legal standards are made too harsh they may end up reinforcing a power structure that is essentially dominated by upper caste men who comprise a majority of staff within law enforcement and the judiciary. Even though the subordinate judiciary do have mahila courts now, the application of the law seems to reify the position of the woman as the victim. This also brings up the question of who can become a victim within such frameworks, where selective bias such as elements of chastity come to play as court functions are undertaken.
An assessment of the way criminal law in India is used to stifle free speech was carried out in 2013 and repeated in 2018, illustrating how censorship law is used to stifle voices of minorities and people critical of the political establishment. Even though it is perhaps time to revisit the earlier conceptualizations of intermediaries as neutral pipes, it is concerning to look at the the court cases regarding safe harbour in India. Many of them are carried out with the ostensible objective of protecting women's rights. In Kamlesh Vaswani V Union of India, the petition claims that porn is a threat to Indian women and culture, ignoring the reality that many women watch porn as well. Pornhub releases figures on viewership every year, and of the entirety of Indian subscribers one third are women. This is not taken into account in such petitions. In Prajwala V Union of India, an NGO sent the Supreme Court a letter raising concerns about videos of sexual violence being distributed on the internet. The letter sought to bring attention to the existence of such videos, as well as their rampant circulation on online platforms. At some point in the proceedings, the Court wanted the intermediaries to use keywords to take down content and keeping aside poor implementation, the rationale behind such a move is problematic in itself. For instance, if you choose sex as one of those words then all sexual education will disappear from the Internet. There are many problems with court encouraged filtering systems like one where a system automatically tells you when a rape video goes up. The question arises of how will you distinguish between a video that was consensually made depicting sexual activities and a rape video. The narrow minded responses to the Sabu Mathew and Prajwala cases originate in the conservative culture regarding sexual activity prevalent in India.
In a research project undertaken by one of the participants in the course of their work, they made a suggestion to include gender, sexuality and disability as grounds for hate speech while working with women’s rights activists and civil society organisations. This suggestion was not well received as they vehemently opposed more regulation. In their opinion, the laws that India has in place are not being upheld and creating new laws will not change if the implementation of legislation is flawed. For instance, even though the Supreme Court stuck down S.66A, Internet Freedom Foundation has earlier provided instances of its continued usage by police officers to file complaints.[4] Hate speech laws can be used to both ends, even though unlike in the US they do not determine whose speech they want to protect. Consequently, in the US a white supremacist gets as much protection as a Black Lives Matter activist but in India, that is not the case. The latest Law Commission Report on hate speech in India tries to make progress by incorporating the ICCPR view of incitement to discriminate and include dignity in the harms. It specifically speaks about hate speech against women saying that it does not always end up in violence but does result in a harm to dignity and standing in society. Often, protectionist forms of speech such as hate speech often end up hurting the people it aims to protect by reinforcing stereotypes.
Point of View undertook a study where they looked at the use of S.67 in the Information Technology (IT) Act which criminalizes obscene speech when you use a medium covered by the IT, in which they found that the section was used to criminalize political speech. In many censorship cases, the people who those provisions benefit are the ones in power.[5] For instance in S.67, obscenity provisions do not protect women's rights, they protect morality of society. Even though these are done in the name of protecting women, when a woman herself decides that she wants to publish a revealing picture of herself online, it is disallowed by the law. That kind of control of sexuality is part of a larger patriarchal framework which does not support women's rights or recognise her sexuality. However, under Indian law, there are quite a few robust provisions for image based abuse, and there is some recognition of women in particular being vulnerable to it. S.66A of the IT Act specifically recognizes that it is a criminal activity to share images of someone’s private parts without their consent. This then also encompasses instances of ‘revenge porn’. That provision has been in place in India since 2008, in contrast to the US where half the states still do not have such a provision. Certain kinds of vulnerability have adequate recognition in the law, thus one should be wary of calls of censorship and lowering the standards for criminalizing speech.
Non-legal interventions
This section centres around the discussions of redressal mechanisms that can be used to address some of the forms of violence which do not emanate from the law. All of the participants emphasized the importance of creating safe spaces through non-legal interventions. It was debated whether there is a need to always approach the law or if it is possible to categorize forms of online violence according to the gravity of the violation committed. These can be in the form of community solutions where law is treated as the last resort. For instance, there was support for using community tools such as ‘feminist trollback’ where humor can be used to troll the trolls. Trolls feed on the fear of being trolled, so the harm can be mitigated by using community initiatives wherein the target can respond to the trolls with the help of other people in the community. It was reiterated that non technical and legal interventions are needed not only from the perspective of power relations within these spaces but also access to the spaces in the first place. Accordingly, the government should work on initiatives that get more women online and focus on policies that makes smartphones and data services more accessible. This would also be a good method to increase the safety of women and benefit from the strength in numbers.
In cases of the non-consensual sharing of intimate images, law can be the primary forum but in cases of trolling and other social media abuse, the question was raised - should we enhance the role of the intermediary platforms? Being the first point of intervention, their responsibility should be more than it currently is. However this would require them to act in the nature of police or judiciary and necessitate an examination of their algorithms. A large proportion of the designers of such algorithms are white males, which increases the possibility of their biases against women of colour for instance, to feed into the algorithms and reinforce a power structure that lacks accountability.
Participants questioned the lack of privacy in design with the example in mind being of how registrars do not make domain owner details private by default. Users have to pay an additional fee for not exposing their details to public and the notion of having to pay for privacy is unsettling. There is no information being provided during the purchasing of the domain name about the privacy feature as well. It was acknowledged that for audit and law enforcement purposes it is imperative to have the information of the owner of a domain name and their details since in cases of websites selling fake medicines, arms or hosting child pornography. Thus, it boils down to the kind of information necessary for law enforcement. Global domain name rules also impact privacy on the national level. The process of ascertaining the suitability and necessity of different kinds of information excludes ordinary citizens since all the consultations take place between the regulatory authority and the state. This makes it difficult for citizens to participate and contribute to this space without government approval.
Issues were flagged against community standards in that the violence that occurs to women is also because the harms are not equal for all. Further, some users are targeted specifically because of the community they come from or the views they have. Often also because, they represent a ‘type’ of a woman that does not adhere to the ‘ideal’ of a woman held by the perpetrator. Unfortunately community standards do not recognise differential harms towards certain communities in India or globally. Twitter, for example, regularly engages in shadow banning and targets people who do not conform to the moral views prevalent in that society where the platform is engaging in censorship. We know these instances occur only when our community members notice and notify us of the same. There is a certain amount of labor that the community has already put in flagging instances of these violations to the intermediary which also needs recognition. In this situation, Twitter is disproportionately handling how it engages with the two entities in question. Community standards could thus become a double edged sword without adding additional protections for certain disadvantaged communities.
Conclusion
Currently, intermediaries are considered neutral pipes through which content flows and hence have no liability as long as they do not perform editorial functions. This has also been useful in ensuring that the freedom of speech is not harmed. However, given their potential ability to remedy this problem, as well as the fact that intermediaries sometimes benefit financially from such activities, it is important to look at the intermediaries’ responsibility in addressing these instances of violence. Governments across the world have taken different approaches to this question[6]. Models, such as in the US, where intermediaries have been solely responsible to institute redressal mechanisms have proven to be ineffectual. On the other hand, in Thailand, where intermediaries are held primarily liable for content, the monitoring of content has led to several free speech harms.
People are increasingly looking at other forms of social intervention to combat online abuse since technological and legal ones do not completely address and resolve the myriad issues emanating from this umbrella term. There is also a need to make the law gender sensitive as well as improving the execution of laws at ground level, possibly through sensitisation of law enforcement authorities. Gender based violence as a catchall phrase does not do justice to the full spectrum of experiences that victims face, especially women and sexual minorities. Often these do not attract criminal punishment given the restricted framework of the current law and need to be seen through the prism of hate speech to strengthen these provisions.
Some actions within GBV receive more attention than others and as a consequence, these are the ones platforms and governments are most concerned with regulating. Considerations of free speech and censorship and the role of intermediaries in being the flag bearers of either has translated into growing calls for greater responsibility to be taken by these players. The roundtable raised some key concerns regarding revisiting intermediary liability within the context of the scale of the platforms, their content moderation policies and machine learning algorithms.
[1] See Khalil Goga, “How to tackle gender-based violence online”, World Economic Forum, 18 February 2015, <https://www.weforum.org/agenda/2015/02/how-to-tackle-gender-based-violence-online/>. See also Shiromi Pinto, “What is online violence and abuse against women?”, 20 November 2017, Amnest International, <https://www.amnesty.org/en/latest/campaigns/2017/11/what-is-online-violence-and-abuse-against-women/>.
[2] Nidhi Tandon, et. al., “Cyber Violence Against Women and Girls: A worldwide wake up call”, UN Broadband Commission for Digital Development Working Group on Broadband and Gender, <http://www.unesco.org/new/fileadmin/MULTIMEDIA/HQ/CI/CI/images/wsis/GenderReport2015FINAL.pdf>
[3] See Azmina Dhrodia, “Unsocial Media: The Real Toll of Online Abuse against Women”, Amnesty Global Insights Blog, <https://medium.com/amnesty-insights/unsocial-media-the-real-toll-of-online-abuse-against-women-37134ddab3f4>
[4] See Abhinav Sekhri and Apar Gupta, “Section 66A and other legal zombies”, Internet Freedom Foundation Blog, <https://internetfreedom.in/66a-zombie/?
[5] See Bishakha Datta “Guavas and Genitals”, Point of View <https://itforchange.net/e-vaw/wp-content/uploads/2018/01/Smita_Vanniyar.pdf>
[6] ‘Examining Technology-Mediated Violence Against Women Through a Feminist Framework: Towards appropriate legal-institutional responses in India’, Gurumurthy et al., January 2018.
Feminist Methodology in Technology Research: A Literature Review
Abstract
Feminist research methodology is a vast body of knowledge, spanning across multiple disciplines including sociology, media studies, and critical legal studies. This literature review aims to understand key aspects of feminist methodology across these disciplines, with a particular focus on research on technology and its interaction with society. Stemming from the argument that the ontological notion of objectivity effaces power relations in the process of knowledge production, feminist research is critical of the subjects, producers, and nature of knowledge. Section I of the literature review explores this argument along with a range of theoretical concepts, such as standpoint theory and historical materialism, as well as principles of feminist research derived from these, such as intersectionality and reflexivity.
Given its critique of the "god's eye view" (Madhok and Evans, 2014) of objectivist research, feminist scholars have largely developed qualitative methods that are more conducive to acknowledgement of power hierarchies. Additionally, some scholars have recognised the political value in quantification of inequalities such as the wage gap, and have developed intersectional quantitative methods that aim at narrowing down measurable inequalities. Both sets of methods are explored in Section II of the literature review, interspersed with examples from research focused on technology.
Introduction
According to authoritative accounts on the subject, while research focused on gender or women predates its arrival, the field of ‘feminist methodology’ explores questions of epistemology and ontology of research and knowledge. Initiated in scholarship arising out of the second wave of North American feminism, it theoretically anchors itself in the post-modernist and post-structuralist traditions. It additionally critiques positivism for being a project furthering patriarchal oppression. North American feminist scholars critique traditional methods within the social sciences from an epistemological perspective, for producing acontextual and ahistorical knowledge, replicating the tendency of positivist science to enumerate and measure subjective social phenomena. This, according to them, leads to the invisiblising of the web of power relations within which the ‘known’ and ‘knower’ in knowledge production are placed. This is then used to devise methods and underlying principles and ethics for conducting more egalitarian research, aimed at achieving goals of social justice.
The second wave feminist movement was itself critiqued by Black and other feminists from the global South for being exclusionary of non-white and heterosexual identities. Given its origins in the global North, scholars from the South have interrogated the meaning of feminism and feminist research in their context. Some African scholars even detail difficulty in disclosing a project as feminist publicly due to popular resistance to the term feminism, which stems from it being rejected by certain social groups as an alien social movement that’s antithetical to their “African cultural values." Their own critique of “White feminism” comes from its essentialization of womanhood and the resultant negation of the (neo)colonial and racialised histories of African women. This has led scholars from the global South to critically interrogate feminism and feminist methods. They acknowledge the multiplicity of feminisms, and initiate creative inquiries into different forms of feminist methodology. Feminist researchers that work in contexts of political violence, instability, repression, scarcity of resources, poor infrastructure, and/or lack of social security, have pointed out that traditional research methods assume conditions that are largely absent in their realities, leading them to experiment with feminist research.
Feminist research across these variety of contexts raises ontological and epistemological concerns about traditional research methods and underlying assumptions about what can be known, who can know, and the nature of knowledge itself. It argues that knowledge production has historically led to the creation of epistemic hierarchies, wherein certain actors are designated as ‘knowers’ and others as the ‘known’. Such hierarchies wreak epistemic violence upon marginalised subjects by denying them the agency to produce knowledge, and delegitimize forms of knowledge that aren’t normative. Acknowledging the role of power in knowledge production has the radical implication that the subjectivities of the researchers and the researched inherently find their way into research and more broadly, knowledge production. This challenges the objectivity and “god’s eye view” of traditional humanistic knowledge and its processes of production. Feminist research eschews scientifically orthodox notions of how “valid knowledge will look”, and creates novel resources for understanding epistemic marginalization of various kinds. It then provides a myriad of tools to disrupt structural hierarchies through and within knowledge production and dissemination.
Feminist research, given its evolution from living movements and theoretical debates, remains a contested domain. It has reformulated a range of qualitative and quantitative research methods, and also surfaced its own, such as experimental and action-based. What these have in common are theoretical dispositions to identify, critique, and ultimately dismantle power relations within and through research projects. It is thus “critical, political, and praxis oriented. Several disciplines with the social sciences, such as feminist technology studies, cyberfeminism, and cultural anthropology, have built feminist approaches to the study of technology and technologically mediated social relations. However, this continues to remain a minor strand of research on technology.
This literature review aims to address that gap through scoping of such methods and their application in technological research. Feminist methodology provides a critical lens that allows us to explore questions and areas in technology-based research that are inaccessible by traditional methods. This paper draws on examples from technology-focused research, covering key interdisciplinary feminist methods across fields such as gender studies, sociology, development, and ICT for development. In doing so, it actively constructs a history of feminist methodology through authoritative sources of knowledge.
Read the full paper here
European E-Evidence Proposal and Indian Law
The main feature of the E-evidence Proposal is twofold: (i) establishment of a legal regime whereunder competent authorities can issue European Production Orders (EPOs) and European Preservation Orders (EPROs) to entities in any other EU member country (together the “Data Orders”); and (ii) an obligation on service providers offering services in any of the EU member countries to designate legal representatives who will be responsible for receiving the Data Orders, irrespective of whether such entity has an actual physical establishment in any EU member country.
In this article we will briefly discuss the framework that has been proposed under the two instruments and then discuss how service providers based in India whose services are also available in Europe would be affected by these proposals. The authors would like to make it clear that this article is not intended to be an analysis of the E-evidence Proposal and therefore shall not attempt to bring out the shortcomings of the proposed European regime, except insofar as such shortcomings may affect the service providers located in India being discussed in the second part of the article.
Part I - E-evidence Directive and Regulation
The E-evidence Proposal introduces the concept of binding EPOs and EPROs. Both Data Orders need to be issued or validated by a judicial authority in the issuing EU member country. A Data Order can be issued to seek preservation or production of data that is stored by a service provider located in another jurisdiction and that is necessary as evidence in criminal investigations or a criminal proceeding. Such Data Orders may only be issued if a similar measure is available for the same criminal offence in a comparable domestic situation in the issuing country. Both Data Orders can be served on entities offering services such as electronic communication services, social networks, online marketplaces, other hosting service providers and providers of internet infrastructure such as IP address and domain name registries. Thus companies such as Big Rock (domain name registry), Ferns n Petals (online marketplace providing services in Europe), Hike (social networking and chatting), etc. or any website which has a subscription based model and allows access to subscribers in Europe would potentially be covered by the E-evidence Proposal. The EPRO, similarly to the EPO, is addressed to the legal representative outside of the issuing country’s jurisdiction to preserve the data in view of a subsequent request to produce such data, which request may be issued through MLA channels in case of third countries or via a European Investigation Order (EIO) between EU member countries. Unlike surveillance measures or data retention obligations set out by law, which are not provided for by this proposal, the EPRO is an order issued or validated by a judicial authority in a concrete criminal proceeding after an individual evaluation of the proportionality and necessity in every single case.[1] Like the EPO, it refers to the specific known or unknown perpetrators of a criminal offence that has already taken place. The EPRO only allows preserving data that is already stored at the time of receipt of the order, not the access to data at a future point in time after the receipt of the EPRO.
While EPOs to produce subscriber data[2] and access data[3] can be issued for any criminal offence an EPO for content data[4] and transactional data[5] may only be issued by a judge, a court or an investigating judge competent in the case. In case the EPO is issued by any other authority (which is competent to issue such an order in the issuing country), such an EPO has to be validated by a judge, a court or an investigating judge. In case of an EPO for subscriber data and access data, the EPO may also be validated by a prosecutor in the issuing country.
To reduce obstacles to the enforcement of the EPOs, the Directive makes it mandatory for service providers to designate a legal representative in the European Union to receive, comply with and enforce Data Orders. The obligation of designating a legal representative for all service providers that are operating in the European Union would ensure that there is always a clear addressee of orders aiming at gathering evidence in criminal proceedings. This would in turn make it easier for service providers to comply with those orders, as the legal representative would be responsible for receiving, complying with and enforcing those orders on behalf of the service provider.
Grounds on which EPOs can be issued
The grounds on which Data Orders may be issued are contained in Articles 5 and 6 of the Regulation which makes it very clear that a Data Order may only be issued in a case if it is necessary and proportionate for the purposes of a criminal proceeding. The Regulation further specifies that an EPO may only be issued by a member country if a similar domestic order could be issued by the issuing state in a comparable situation. By using this device of linking the grounds to domestic law, the Regulation tries to skirt around the thorny issue of when and on what basis an EPO may be issued. The Regulation also assigns greater weight (in terms of privacy) to transactional and content data as opposed to subscriber and access data and subjects the production and preservation of the former to stricter requirements. Therefore while Data Orders for access and subscriber data may be issued for any criminal offence, orders for transactional and content data can only be issued in case of criminal offences providing for a maximum punishment of atleast 3 years and above. In addition to that EPOs for producing transactional or content data can also be issued for offences specifically listed in Article 5(4) of the Regulation. These offences have been specifically provided for since evidence for such cases would typically be available mostly only in electronic form. This is the justification for the application of the Regulation also in cases where the maximum custodial sentence is less than three years, otherwise it would become extremely difficult to secure convictions in those offences.[6]
The Regulation also requires the issuing authority to take into account potential immunities and privileges under the law of the member country in which the service provider is being served the EPO, as well as any impact the EPO may have on fundamental interests of that member country such as national security and defence. The aim of this provision is to ensure that such immunities and privileges which protect the data sought are respected, in particular where they provide for a higher protection than the law of the issuing member country. In such situations the issuing authority “has to seek clarification before issuing the European Production Order, including by consulting the competent authorities of the Member State concerned, either directly or via Eurojust or the European Judicial Network.”
Grounds to Challenge EPOs
Service Providers have been given the option to object to Data Orders on certain limited grounds specified in the Regulation such as, if it was not issued by a proper issuing authority, if the provider cannot comply because of a de facto impossibility or force majeure, if the data requested is not stored with the service provider or pertains to a person who is not the customer of the service provider.[7] In all such cases the service provider has to inform the issuing authority of the reasons for the inability to provide the information in the specified form. Further, in the event that the service provider refuses to provide the information on the grounds that it is apparent that the EPO “manifestly violates” the Charter of Fundamental Rights of the European Union or is “manifestly abusive”, the service provider shall send the information in specified Form to the competent authority in the member state in which the Order has been received. The competent authority shall then seek clarification from the issuing authority through Eurojust or via the European Judicial Network.[8]
If the issuing authority is not satisfied by the reasons given and the service provider still refuses to provide the information requested, the issuing authority may transfer the EPO Certificate along with the reasons given by the service provider for non compliance, to the enforcing authority in the addressee country. The enforcing authority shall then proceed to enforce the Order, unless it considers that the data concerned is protected by an immunity or privilege under its national law or its disclosure may impact its fundamental interests such as national security and defence; or the data cannot be provided due to one of the following reasons:
(a) the European Production Order has not been issued or validated by an issuing authority as provided for in Article 4;
(b) the European Production Order has not been issued for an offence provided for by Article 5(4);
(c) the addressee could not comply with the EPOC because of de facto impossibility or force majeure, or because the EPOC contains manifest errors;
(d) the European Production Order does not concern data stored by or on behalf of the service provider at the time of receipt of EPOC;
(e) the service is not covered by this Regulation;
(f) based on the sole information contained in the EPOC, it is apparent that it manifestly violates the Charter or that it is manifestly abusive.
In addition to the above mechanism the service provider may refuse to comply with an EPO on the ground that disclosure would force it to violate a third-country law that either protects “the fundamental rights of the individuals concerned” or “the fundamental interests of the third country related to national security or defence.” Where a provider raises such a challenge, issuing authorities can request a review of the order by a court in the member country. If the court concludes that a conflict as claimed by the service provider exists, the court shall notify authorities in the third-party country and if that third-party country objects to execution of the EPO, the court must set it aside.[9]
A service provider may also refuse to comply with an order because it would force the service provider to violate a third-country law that protects interests other than fundamental rights or national security and defense. In such cases, the Regulation provides that the same procedure be followed as in case of law protecting fundamental rights or national security and defense, except that in this case the court, rather than notifying the foreign authorities, shall itself conduct a detailed analysis of the facts and circumstances to decide whether to enforce the order.[10]
Service Provider “Offering Services in the Union”
As is clear from the discussion above, the proposed regime puts an obligation on service providers offering services in the Union to designate a legal representative in the European Union, whether the service provider is physically located in the European Union or not. This appears to be a fairly onerous obligation for small technology companies which may involve a significant cost to appoint and maintain a legal representative in the European Union, especially if the service provider is not located in the EU. Therefore the question arises as to which service providers would be covered by this obligation and the answer to that question lies in the definitions of the terms “service provider” and “offering services in the Union”.
The term service provider has been defined in Article 2(2) of the Directive as follows:
“‘service provider’ means any natural or legal person that provides one or more of the following categories of services:
(a) electronic communications service as defined in Article 2(4) of [Directive establishing the European Electronic Communications Code];[11]
(b) information society services as defined in point (b) of Article 1(1) of Directive (EU) 2015/1535 of the European Parliament and of the Council[12] for which the storage of data is a defining component of the service provided to the user, including social networks, online marketplaces facilitating transactions between their users, and other hosting service providers;
(c) internet domain name and IP numbering services such as IP address providers, domain name registries, domain name registrars and related privacy and proxy services;”
Thus broadly speaking the service providers covered by the Regulation would include providers of electronic communication services, social networks, online marketplaces, other hosting service providers and providers of internet infrastructure such as IP address and domain name registries, or on their legal representatives where they exist. An important qualification that has been added in the definition is that it covers only those services where “storage of data is a defining component of the service”. Therefore, services for which the storage of data is not a defining component are not covered by the proposal. The Regulation also recognizes that most services delivered by providers involve some kind of storage of data, especially where they are delivered online at a distance; and therefore it specifically provides that services for which the storage of data is not a main characteristic and is thus only of an ancillary nature would not be covered, including legal, architectural, engineering and accounting services provided online at a distance.[13]
This does not mean that all such service providers offering the type of services in which data storage is the main characteristic, in the EU, would be covered by the Directive. The term “offering services in the Union” has been defined in Article 2(3) of the Directive as follows:
“‘offering services in the Union’ means:
(a) enabling legal or natural persons in one or more Member State(s) to use the services listed under (3) above; and
(b) having a substantial connection to the Member State(s) referred to in point (a);”
Clause (b) of the definition is the main qualifying factor which would ensure that only those entities whose offering of services has a “substantial connection” which the member countries of the EU would be covered by the Directive. The Regulation recognizes that mere accessibility of the service (which could also be achieved through mere accessibility of the service provider’s or an intermediary’s website in the EU) should not be a sufficient condition for the application of such an onerous condition and therefore the concept of a “substantial connection” was inserted to ascertain a sufficient relationship between the provider and the territory where it is offering its services. In the absence of a permanent establishment in an EU member country, such a “substantial connection” may be said to exist if there are a significant number of users in one or more EU member countries, or the “targeting of activities” towards one or more EU member countries. The “targeting of activities” may be determined based on various circumstances, such as the use of a language or a currency generally used in an EU member country, the availability of an app in the relevant national app store, providing local advertising or advertising in the language used in an EU member country, making use of any information originating from persons in EU member countries in the course of its activities, or from the handling of customer relations such as by providing customer service in the language generally used in EU member countries. A substantial connection can also be assumed where a service provider directs its activities towards one or more EU member countries as set out in Article 17(1)(c) of Regulation 1215/2012 on jurisdiction and the recognition and enforcement of judgments in civil and commercial matters.[14]
Part II - EU Directive and Service Providers located in India
In this part of the article we will discuss how companies based in India and running websites providing any “service” such as social networking, subscription based video streaming, etc. such as Hike or AltBalaji, Hotstar, etc. and how such companies would be affected by the E-evidence Proposal. At first glance a website providing a video streaming service may not appear to be covered by the E-evidence Proposal since one would assume that there may not be any storage of data. But if it is a service which allows users to open personal accounts (with personal and possibly financial details such as in the case of TVF, AltBalaji or Hotstar) and uses their online behaviour to push relevant material and advertisements to their accounts, whether that would make the storage of data a defining component of the website’s services as contemplated under the proposal is a question that may not be easy to answer.
Even if it is assumed that the services of an Indian company can be classified as information society services for which the storage of data is a defining component, that by itself would not be sufficient to make the E-evidence Proposal applicable to it. The services of an Indian company would still need to have a “substantial connection” with an EU member country. As discussed above, this substantial connection may be said to exist based on the existence of (i) a significant number of users in one or more EU member countries, or (ii) the “targeting of activities” towards one or more EU member countries. The determination of whether a service provider is targeting its services towards an EU member country is to be made based on a number of factors listed above and is a subjective determination with certain guiding factors.
There does not seem to be clarity however on what would constitute a significant number of users and whether this determination is to be based upon the total number of users in an EU member country as a proportion of the population of the country or is it to be considered as a proportion of the total number of customers the service provider has worldwide. To explain this further let us assume that an Indian company such as Hotstar has a total user base of 100 million customers.[15] If there is a situation where 10 million of these 100 million subscribers are located in countries other than India, out of which there are about 40 thousand customers in France and another 40 thousand in Malta; then it would lead to some interesting analysis. Now 40 thousand customers in a customer base of 100 million is 0.04% of the total customer base of the service provider which generally speaking would not constitute a “significant number”. However if we reckon the 40 thousand customers from the point of view of the total population of the country of Malta, which is approximately 4.75 Lakh,[16] it would mean approx. 8.4% of the total population of Malta. It is unlikely that any service affecting almost a tenth of the population of the entire country can be labeled as not having a significant number of users in Malta. If the same math is done on the population of a country such as France, which has a population of approx. 67.3 million,[17] then the figure would be 0.05% of the total population; would that constitute a significant number as per the E-evidence Proposal.
The issues discussed above are very important for any service provider, specially a small or medium sized company since the determination of whether the E-evidence Proposal applies to them or not, apart from any potential legal implications, imposes a direct economic cost for designating a legal representative in an EU member country. Keeping in mind this economic burden and how it might affect the budget of smaller companies, the Explanatory Memorandum to the Regulation clarifies that this legal representative could be a third party, which could be shared between several service providers, and further the legal representative may accumulate different functions (e.g. the General Data Protection Regulation or e-Privacy representatives in addition to the legal representative provided for by the E-evidence Directive).[18]
In case all the above issues are determined to be in favour of the E-evidence Directive being applicable to an Indian company and the company designates a legal representative in an EU member country, then it remains to be seen how Indian laws relating to data protection would interact with the obligations of the Indian company under the E-evidence Directive. As per Rule 6 of the Information Technology (Reasonable Security Practices and Procedures and Sensitive Personal Data or Information) Rules, 2011 (“SPDI Rules”) service providers are not allowed to disclose sensitive personal data or information except with the prior permission of the except disclosure to mandated government agencies. The Rule provides that “the information shall be shared, without obtaining prior consent from provider of information, with Government agencies mandated under the law to obtain information including sensitive personal data or information for the purpose of verification of identity, or for prevention, detection, investigation including cyber incidents, prosecution, and punishment of offences….”. Although the term “government agency mandated under law” has not been defined in the SPDI Rules, the term “law” has been defined in the Information Technology Act, 2000 (“IT Act”) as under:
“’law’ includes any Act of Parliament or of a State Legislature, Ordinances promulgated by the President or a Governor, as the case may be. Regulations made by the President under article 240, Bills enacted as President's Act under sub-clause (a) of clause (1) of article 357 of the Constitution and includes rules, regulations, byelaws and orders issued or made thereunder;”[19]
Since the SPDI Rules are issued under the IT Act, therefore the term “law” referred as used in the would have to be read as defined in the IT Act (unless court holds to the contrary). This would mean that Rule 6 of the SPDI Rules only recognises government agencies mandated under Indian law and therefore information cannot be disclosed to agencies not recognised by Indian law. In such a scenario an Indian company may not have any option except to raise an objection and challenge an EPO issued to it on the grounds provided in Article 16 of the Regulation, which process itself could mean a significant expenditure on the part of such a company.
Conclusion
The framework sought to be established by the European Union through the E-evidence Proposal seeks to establish a regime different from those favoured by countries such as the United States which favours Mutual Agreements with (presumably) key nations or the push for data localisation being favoured by countries such as India, to streamline the process of access to digital data. Since the regime put forth by the EU is still only at the proposal stage, there may yet be changes which could clarify the regime significantly. However, as things stand Indian companies may be affected by the E-evidence Proposal in the following ways:
- Companies offering services outside India may inadvertently trigger obligations under the E-evidence Proposal if their services have a substantial connection with any of the member states of the European Union;
- Indian companies offering services overseas will have to make an internal determination as to whether the E-evidence Proposal applies to them or not;
- In case of Indian companies which come under the E-evidence Proposal, they would be obligated to designate a legal representative in an EU member state for receiving and executing Data Orders as per the E-evidence Proposal.
- If a legal representative is designated by the Indian company they may have to incur significant costs on maintaining a legal representative especially in a situation where they have to object to the implementation of an EPO. The company would also have to coordinate with the legal representative to adequately put forth their (Indian law related) concerns before the competent authority so that they are not forced to fall foul of their legal obligations in either jurisdiction. It is also unclear the extent to which appointed legal representatives from Indian companies could challenge or push back against requests received.
Disclaimer: The author of this Article is an Indian trained lawyer and not an expert on European law. The author would like to apologise for any incorrect analysis of European law that may have crept into this article despite best efforts.
[1] Explanatory Memorandum to the Proposal for Regulation of the European Parliament and of the Council on European Production and Preservation Orders for Electronic Evidence in Criminal Matters, Pg. 4, available at https://eur-lex.europa.eu/legal-content/EN/TXT/PDF/?uri=CELEX:52018PC0225&from=EN.
[2] Subscriber data means data which is used to identify the user and has been defined in Article 2 (7) as follows:
“‘subscriber data’ means any data pertaining to:
(a) the identity of a subscriber or customer such as the provided name, date of birth, postal or geographic address, billing and payment data, telephone, or email;
(b) the type of service and its duration including technical data and data identifying related technical measures or interfaces used by or provided to the subscriber or customer, and data related to the validation of the use of service, excluding passwords or other authentication means used in lieu of a password that are provided by a user, or created at the request of a user;”
[3] The term access data has been defined in Article 2(8) as follows:
“‘access data’ means data related to the commencement and termination of a user access session to a service, which is strictly necessary for the sole purpose of identifying the user of the service, such as the date and time of use, or the log-in to and log-off from the service, together with the IP address allocated by the internet access service provider to the user of a service, data identifying the interface used and the user ID. This includes electronic communications metadata as defined in point (g) of Article 4(3) of Regulation concerning the respect for private life and the protection of personal data in electronic communications;”
[4] The term content data has been defined in Article 2 (10) as follows:
“‘content data’ means any stored data in a digital format such as text, voice, videos, images, and sound other than subscriber, access or transactional data;”
[5] The term transactional data has been defined in Article 2(9) as follows:
“‘transactional data’ means data related to the provision of a service offered by a service provider that serves to provide context or additional information about such service and is generated or processed by an information system of the service provider, such as the source and destination of a message or another type of interaction, data on the location of the device, date, time, duration, size, route, format, the protocol used and the type of compression, unless such data constitues access data. This includes electronic communications metadata as defined in point (g) of Article 4(3) of [Regulation concerning the respect for private life and the protection of personal data in electronic communications];”
[6] Explanatory Memorandum to the Proposal for Regulation of the European Parliament and of the Council on European Production and Preservation Orders for Electronic Evidence in Criminal Matters, Pg. 17, available at https://eur-lex.europa.eu/legal-content/EN/TXT/PDF/?uri=CELEX:52018PC0225&from=EN.
[7] Articles 9(4) and 10(5) of the Regulation.
[8] Article 10(5) of the Regulation.
[9] Article 15 of the Regulation.
[10] Article 16 of the Regulation. Also see https://www.insideprivacy.com/uncategorized/eu-releases-e-evidence-proposal-for-cross-border-data-access/.
[11] Article 2(4) of the Directive establishing European Electronic Communications Code provides as under:
‘electronic communications service’ means a service normally provided for remuneration via electronic communications networks, which encompasses 'internet access service' as defined in Article 2(2) of Regulation (EU) 2015/2120; and/or 'interpersonal communications service'; and/or services consisting wholly or mainly in the conveyance of signals such as transmission services used for the provision of machine-to-machine services and for broadcasting, but excludes services providing, or exercising editorial control over, content transmitted using electronic communications networks and services;”
[12] Information Society Services have been defined in the Directive specified as “any Information Society service, that is to say, any service normally provided for remuneration, at a distance, by electronic means and at the individual request of a recipient of services.”
[13] Proposal for a Directive of the European Parliament and of the Council Laying Down Harmonised Rules on the Appointment of Legal Representatives for the Purpose of Gathering Evidence in Criminal Proceedings, Pg 8, available at https://eur-lex.europa.eu/legal-content/EN/TXT/PDF/?uri=CELEX:52018PC0226&from=EN.
[14] Proposal for a Directive of the European Parliament and of the Council Laying Down Harmonised Rules on the Appointment of Legal Representatives for the Purpose of Gathering Evidence in Criminal Proceedings, Pg 9, available at https://eur-lex.europa.eu/legal-content/EN/TXT/PDF/?uri=CELEX:52018PC0226&from=EN.
[15] Hotstar already has an active customer base of 75 million, as of December, 2017; https://telecom.economictimes.indiatimes.com/news/netflix-restricted-to-premium-subscribers-hotstar-leads-indian-ott-content-market/62351500
[16] https://en.wikipedia.org/wiki/Malta
[17] https://en.wikipedia.org/wiki/France
[18] Proposal for a Directive of the European Parliament and of the Council Laying Down Harmonised Rules on the Appointment of Legal Representatives for the Purpose of Gathering Evidence in Criminal Proceedings, Pg 5, available at https://eur-lex.europa.eu/legal-content/EN/TXT/PDF/?uri=CELEX:52018PC0226&from=EN.
[19] Section 2(y) of the Information Technology Act, 2000.
Mapping cybersecurity in India: An infographic

Infographic designed by Saumyaa Naidu
Private-public partnership for cyber security
For security The private sector has a long history of fostering global pacts iStockphoto - Getty Images/iStockphoto
The article by Arindrajit Basu was published in Hindu Businessline on December 24, 2018.
On November 11, 2018, as 70 world leaders gathered in Paris to commemorate the countless lives lost in World War I, French President Emmanuel Macron inaugurated the Paris Peace Forum with a fiery speech denouncing nationalism and urging global leaders to pursue peace and stability through multilateral initiatives.
In many ways, it echoed US President Woodrow Wilson’s monumental speech delivered at the US Senate a century ago in which he outlined 14 points on the principles for peace post World War I. As history unkindly reminds us through the catastrophic realities of World War II, Wilson’s principles went on to be sacrificed at the altar of national self-interest and inadequate multilateral enforcement.
President Macron’s first initiative for global peace — the Paris Call for Trust and Security in Cyber Space was unveiled on November 12 — at the UNESCO Internet Governance Forum — also taking place in Paris. The call was endorsed by over 50 states, 200 private sector entities, including Indian business guilds such as FICCI and the Mobile Association of India and over 100 organisations from civil society and academia from all over the globe. The text essentially comprises a set of high-level principles that seeks to prevent the weaponisation of cyberspace and promote existing institutional mechanisms to “limit hacking and destabilising activities” in cyberspace.
Need for private participation
Given the increasing exploitation of the internet for reaping offensive dividends by state and non-state actors alike and the prevailing roadblocks in the multilateral cyber norms formulation process, Macron’s efforts are perhaps of Wilsonian proportions.
A key difference, however, was that Macron’s efforts were devised hand-in-glove with Microsoft — one of the most powerful and influential private sector actors of our time. Microsoft’s involvement is unsurprising given that private entities have become a critical component of the global cybersecurity landscape and governments need to start thinking about how to optimise their participation in this process.
Indeed, one of the defining features of cyberspace is its incompatibility with state-centric ‘command and control’ formulae that lead to the ordering of other global security regimes — such as nuclear non-proliferation. The decentralised nature of cyberspace means that private sector actors play a vital role in implementing the rules designed to secure cyberspace.
Simultaneously, private actors such as Microsoft have recognised the utility of clearly defined ‘rules of the road’ which ensure certainty and stability in cyberspace and ensure its trustworthiness among global customers.
Normative deadlock
There have been multiple gambits to develop universal norms of responsible state behaviour to foster cyber stability. The United Nations-Group of Governmental Experts (UN-GGE) has been constituted five times now and will meet again in January 2019.
While the third and fourth GGEs in 2013 and 2015 respectively made some progress towards agreeing on some baseline principles, the fifth GGE broke down due to opposition from states including Russia, China and Cuba on the application of specific principles of international law to cyberspace.
This was an extension of a long-running ‘Cold War’ like divide among states at the United Nations. The US along with its NATO allies believe in creating voluntary non-binding norms for cybersecurity through the application of international law in its entirety while Russia, China and its allies in the Shanghai Co-operation Organization (SCO) reject the premise that international law applies in its entirety and call for the negotiation of an independent treaty for cyberspace that lays down binding obligations on states.
Critical role
The private sector has begun to play a critical role in breaking this deadlock. Recent history is testament to catalytic roles played by non-state actors in cementing global co-operative regimes.
For example, Dupont — the world’s leading ChloroFluoroCarbon (CFC) producer — played a leading role in the 1970s and 1980s towards the development of The Montreal Protocol on Substances that Deplete the Ozone Layer and gained positive recognition for its efforts.
Another example is the International Committee of the Red Cross (ICRC) — a non-governmental organisation that played a crucial role in the development of the Geneva Conventions and its Additional Protocols, which regulate the conduct of atrocities in warfare by preparing initial drafts of the treaties and circulating them to key government players.
Similarly, in cyberspace, Microsoft’s Digital Geneva Convention which devised a set of rules to protect civilian use of the internet was put forward by Chief Legal Officer, Brad Smith two months before the fifth GGE met in 2017.
Despite the breakdown at the UN-GGE, Microsoft pushed on with the Tech Accords — a public commitment made by (as of today) 69 companies “agreeing to defend all customers everywhere from malicious attacks by cyber-criminal enterprises and nation-states.”
Much like the ICRC, Microsoft leads commendable diplomatic efforts with the Paris Call as they reached out to states, civil society actors and corporations for their endorsement.
Looking Forward
Private sector-led normative efforts towards securing cyberspace are redundant in the absence of three key recommendations. First, is the implementation of best practices at the organisational level through the implementation of robust cyber defense mechanisms, the detection and mitigation of vulnerabilities and breach notifications — both to consumer and the government.
Second, is the development of mechanisms that enables direct co-operation between governments and private actors at the domestic level. In India, a Joint Working Group between the Data Security Council of India (DSCI) and the National Security Council Secretariat (NSCS) was set up in 2012 to explore a Private Public Partnership on cyber-security in India , which has great potential but is yet to report any tangible outcomes.
The third and final point is the recognition that their efforts need to result in a plurality of states coming to the negotiating table. The absence of the US, China and Russia in the Paris Call are eerily reminiscent of the lack of US participation in Woodrow Wilson’s League of Nations, which was one of the reasons for its ultimate failure.
Microsoft needs to keep on calling with Paris but Beijing, Washington and Alibaba need to pick up.
Is the new ‘interception’ order old wine in a new bottle?
An opinion piece co-authored by Elonnai Hickok, Vipul Kharbanda, Shweta Mohandas and Pranav M. Bidare was published in Newslaundry.com on December 27, 2018.
On December 20, 2018, through an order issued by the Ministry of Home Affairs (MHA), 10 security agencies—including the Intelligence Bureau, the Central Bureau of Investigation, the Enforcement Directorate and the National Investigation Agency—were listed as the intelligence agencies in India with the power to intercept, monitor and decrypt "any information" generated, transmitted, received, or stored in any computer under Rule 4 of the Information Technology (Procedure and Safeguards for Interception, Monitoring and Decryption of Information) Rules, 2009, framed under section 69(1) of the IT Act.
On December 21, the Press Information Bureau published a press release providing clarifications to the previous day’s order. It said the notification served to merely reaffirm the existing powers delegated to the 10 agencies and that no new powers were conferred on them. Additionally, the release also stated that “adequate safeguards” in the IT Act and in the Telegraph Act to regulate these agencies’ powers.
Presumably, these safeguards refer to the Review Committee constituted to review orders of interception and the prior approval needed by the Competent Authority—in this case, the secretary in the Ministry of Home Affairs in the case of the Central government and the secretary in charge of the Home Department in the case of the State government.
As noted in the press release, the government has always had the power to authorise intelligence agencies to submit requests to carry out the interception, decryption, and monitoring of communications, under Rule 4 of the Information Technology (Procedure and Safeguards for Interception, Monitoring and Decryption of Information) Rules, 2009, framed under section 69(1) of the IT Act.
When considering the implications of this notification, it is important to look at it in the larger framework of India’s surveillance regime, which is made up of a set of provisions found across multiple laws and operating licenses with differing standards and surveillance capabilities.
- Section 5(2) of the Indian Telegraph Act, 1885 allows the government (or an empowered authority) to intercept or detain transmitted information on the grounds of a public emergency, or in the interest of public safety if satisfied that it is necessary or expedient so to do in the interests of the sovereignty and integrity of India, the security of the State, friendly relations with foreign states or public order or for preventing incitement to the commission of an offence. This is supplemented by Rule 419A of the Indian Telegraph Rules, 1951, which gives further directions for the interception of these messages.
- Condition 42 of the Unified Licence for Access Services, mandates that every telecom service provider must facilitate the application of the Indian Telegraph Act. Condition 42.2 specifically mandates that the license holders must comply with Section 5 of the same Act.
- Section 69(1) of the Information Technology Act and associated Rules allows for the interception, monitoring, and decryption of information stored or transmitted through any computer resource if it is found to be necessary or expedient to do in the interest of the sovereignty or integrity of India, defense of India, security of the State, friendly relations with foreign States or public order or for preventing incitement to the commission of any cognizable offence relating to above or for investigation of any offence.
- Section 69B of the Information Technology Act and associated Rules empowers the Centre to authorise any agency of the government to monitor and collect traffic data “to enhance cyber security, and for identification, analysis, and prevention of intrusion, or spread of computer contaminant in the country”.
- Section 92 of the CrPc allows for a Magistrate or Court to order access to call record details.
Notably, a key difference between the IT Act and the Telegraph Act in the context of interception is that the Telegraph Act permits interception for preventing incitement to the commission of an offence on the condition of public emergency or in the interest of public safety while the IT Act permits interception, monitoring, and decryption of any cognizable offence relating to above or for investigation of any offence. Technically, this difference in surveillance capabilities and grounds for interception could mean that different intelligence agencies would be authorized to carry out respective surveillance capabilities under each statute. Though the Telegraph Act and the associated Rule 419A do not contain an equivalent to Rule 4—nine Central Government agencies and one State Government agency have previously been authorized under the Act. The Central Government agencies authorised under the Telegraph Act are the same as the ones mentioned in the December 20 notification with the following differences:
- Under the Telegraph Act, the Research and Analysis Wing (RAW) has the authority to intercept. However, the 2018 notification more specifically empowers the Cabinet Secretariat of RAW to issue requests for interception under the IT Act.
- Under the Telegraph Act, the Director General of Police, of concerned state/Commissioner of Police, Delhi for Delhi Metro City Service Area, has the authority to intercept. However, the 2018 notification specifically authorises the Commissioner of Police, New Delhi with the power to issue requests for interception.
That said, the IT (Procedure and safeguard for Monitoring and Collecting Traffic Data or Information) Rules, 2009 under 69B of the IT Act contain a provision similar to Rule 4 of the IT (Procedure and Safeguards for Interception, Monitoring and Decryption of Information) Rules, 2009 - allowing the government to authorize agencies that can monitor and collect traffic data. In 2016, the Central Government authorised the Indian Computer Emergency Response Team to monitor and collect traffic data, or information generated, transmitted, received, or stored in any computer resource. This was an exercise of the power conferred upon the Central Government by Section 69B(1) of the IT Act. However, this notification does not reference Rule 4 of the IT Rules, thus it is unclear if a similar notification has been issued under Rule 4.
While it is accurate that the order does not confer new powers, areas of concern that existed with India’s surveillance regime continue to remain including the question of whether 69(1) and 69B and associated Rules are constitutionally valid, the lack of transparency by the government and the prohibition of transparency by service providers, heavy handed penalties on service providers for non-compliance, and a lack of legal backing and oversight mechanisms for intelligence agencies. Some of these could be addressed if the draft Data Protection Bill 2018 is enacted and the Puttaswamy Judgement fully implemented.
Conclusion
The MHA’s order and the press release thereafter have served to publicise and provide needed clarity with respect to the powers vested in which intelligence agencies in India under section 69(1) of the IT Act. This was previously unclear and could have posed a challenge to ensuring oversight and accountability of actions taken by intelligence agencies issuing requests under section 69(1) .
The publishing of the list has subsequently served to raise questions and create a debate about key issues concerning privacy, surveillance and state overreach. On December 24, the order was challenged by advocate ML Sharma on the grounds of it being illegal, unconstitutional and contrary to public interest. Sharma in his contention also stated the need for the order to be tested on the basis of the right to privacy established by the Supreme Court in Puttaswamy which laid out the test of necessity, legality, and proportionality. According to this test, any law that encroaches upon the privacy of the individual will have to be justified in the context of the right to life under Article 21.
But there are also other questions that exist. India has multiple laws enabling its surveillance regime and though this notification clarifies which intelligence agencies can intercept under the IT Act, it is still seemingly unclear which intelligence agencies can monitor and collect traffic data under the 69B Rules. It is also unclear what this order means for past interceptions that have taken place by agencies on this list or agencies outside of this list under section 69(1) and associated Rules of the IT Act. Will these past interceptions possess the same evidentiary value as interceptions made by the authorised agencies in the order?
Economics of Cybersecurity: Literature Review Compendium
Authored by Natallia Khaniejo and edited by Amber Sinha
Politics and economics are increasingly being amalgamated with Cybernetic frameworks and consequently Critical infrastructure has become intrinsically dependent on Information and Communication Technology (ICTs). The rapid evolution of technological platforms has been accompanied by a concomitant rise in the vulnerabilities that accompany them. Recurrent issues include concerns like network externalities, misaligned incentives and information asymmetries. Malignant actors use these vulnerabilities to breach secure systems, access and sell data, and essentially destabilize cyber and network infrastructures. Additionally, given the relative nascence of the realm, establishing regulatory policies without limiting innovation in the space becomes an additional challenge as well. The lack of uniform understanding regarding the definition and scope of what can be defined as Cybersecurity also serves as a barrier preventing the implementation of clear guidelines. Furthermore, the contrast between what is convenient and what is ‘sanitary’ in terms of best practices for cyber infrastructures is also a constant tussle with recommendations often being neglected in favor of efficiency. In order to demystify the security space itself and ascertain methods of effective policy implementation, it is essential to take stock of current initiatives being proposed for the development and implementation of cybersecurity best practices, and examine their adequacy in a rapidly evolving technological environment. This literature review attempts to document the various approaches that are being adopted by different stakeholders towards incentivizing cybersecurity and the economic challenges of implementing the same.
Click on the below links to read the entire story:
Registering for Aadhaar in 2019
The article was published in Business Standard on January 2, 2019.
Last November, a global committee of lawmakers from nine countries the UK, Canada, Ireland, Brazil, Argentina, Singapore, Belgium, France and Latvia summoned Mark Zuckerberg to what they called an “international grand committee” in London. Mr. Zuckerberg was too spooked to show up, but Ashkan Soltani, former CTO of the FTC was among those who testified against Facebook. He said “in the US, a lot of the reticence to pass strong policy has been about killing the golden goose” referring to the innovative technology sector. Mr. Soltani went on to argue that “smart legislation will incentivise innovation”. This could be done either intentionally or unintentionally by governments. For example, a poorly thought through blocking of pornography can result in innovative censorship circumvention technologies. On other occasions, this can happen intentionally. I hope to use my inaugural column in these pages to provide an Indian example of such intentional regulatory innovation.
Eight years ago, almost to this date, my colleague Elonnai Hickok wrote an open letter to the Parliamentary Finance Committee on what was then called the UID or Unique Identity. She compared Aadhaar to the digital identity project started by the National Democratic Alliance (NDA) government in 2001. Like the Vajpayee administration which was working in response to the Kargil War, she advocated a decentralised authentication architecture using smart cards based on public key cryptography. Last year, even before the five-judge constitutional bench struck down Section 57 of the Aadhaar Act, the UIDAI preemptively responded to this regulatory development by launching offline Aadhaar cards. This was to be expected especially since from the A.P. Shah Committee report, the Puttaswamy Judgment, the B.N. Srikrishna Committee consultation paper, report and bill, the principle of “privacy by design” was emerging as a key Indian regulatory principle in the domain of data protection.
The introduction of the offline Aadhaar mechanism eliminates the need for biometrics during authentication. I have previously provided 11 reasons why biometrics is inappropriate technology for e-governance applications by democratic governments, and this comes as a massive relief for both human rights activists and security researchers. Second, it decentralises authentication, meaning that there is a no longer a central database that holds a 360-degree view of all incidents of identification and authentication. Third, it dramatically reduces the attack surface for Aadhaar numbers, since only the last four digits remain unmasked on the card. Each data controller using Aadhaar will have to generate his/her own series of unique identifiers to distinguish between residents. If those databases leak or get breached, it won’t tarnish the credibility of Aadhaar or the UIDAI to the same degree. Fourth, it increases the probability of attribution in case a data breach were to occur; if the breached or leaked data contains identifiers issued by a particular data controller, it would become easier to hold them accountable and liable for the associated harms. Fifth, unlike the previous iteration of the Aadhaar “card”, on which the QR code was easy to forge and alter, this mechanism provides for integrity and tamper detection because the demographic information contained within the QR code is digitally signed by the UIDAI. Finally, it retains the earlier benefit of being very cheap to issue, unlike smart cards.
Thanks to the UIDAI, the private sector is also being forced to implement privacy by design. Previously, since everyone was responsible for protecting Aadhaar numbers, nobody was. Data controllers would gladly share the Aadhaar number with their contractors, that is, data processors, since nobody could be held responsible. Now, since their own unique identifiers could be used to trace liability back to them, data controllers will start using tokenisation when they outsource any work that involves processing of the collected data. Skin in the game immediately breeds more responsible behaviour in the ecosystem.
The fintech sector has been rightfully complaining about regulatory and technological uncertainty from last year’s developments. This should be addressed by developing open standards and free software to allow for rapid yet secure implementation of these changes. The QR code standard itself should be an open standard developed by the UIDAI using some of the best practices common to international standard setting organisations like the World Wide Web Consortium, Internet Engineers Task Force and the Institute of Electrical and Electronics Engineers. While the UIDAI might still choose to take the final decision when it comes to various technological choices, it should allow stakeholders to make contributions through comments, mailing lists, wikis and face-to-face meetings. Once a standard has been approved, a reference implementation must be developed by the UIDAI under liberal licences, like the BSD licence that allows for both free software and proprietary software derivative works. For example, a software that can read the QR code as well as send and receive the OTP to authenticate the resident. This would ensure that smaller fintech companies with limited resources can develop secure systems.
Since Justice Dhananjaya Y. Chandrachud’s excellent dissent had no other takers on the bench, holdouts like me must finally register for an Aadhaar number since we cannot delay filing taxes any further. While I would still have preferred a physical digital artefact like a smart card (built on an open standard), I must say it is a lot less scary registering for Aadhaar in 2019 than it was in 2010, given how the authentication modalities have since evolved.
Response to TRAI Consultation Paper on Regulatory Framework for Over-The-Top (OTT) Communication Services
Click here to view the submission (PDF).
This submission presents a response by Gurshabad Grover, Nikhil Srinath and Aayush Rathi (with inputs from Anubha Sinha and Sai Shakti) to the Telecom Regulatory Authority of India’s “Consultation Paper on Regulatory Framework for Over-The-Top (OTT) Communication Services (hereinafter “TRAI Consultation Paper”) released on November 12, 2018 for comments. CIS appreciates the continual efforts of Telecom Regulatory Authority of India (TRAI) to have consultations on the regulatory framework that should be applicable to OTT services and Telecom Service Providers (TSPs). CIS is grateful for the opportunity to put forth its views and comments.
Addendum: Please note that this document differs in certain sections from the submission emailed to TRAI: this document was updated on January 9, 2019 with design and editorial changes to enhance readability. The responses to Q5 and Q9 have been updated. This updated document was also sent to TRAI.
How to make EVMs hack-proof, and elections more trustworthy
The article was published in Times of India on December 9, 2018.
Electronic voting machines (EVM) have been in use for general elections in India since 1999 having been first introduced in 1982 for a by-election in Kerala. The EVMs we use are indigenous, having been designed jointly by two public-sector organisations: the Electronics Corporation of India Ltd. and Bharat Electronics Ltd. In 1999, the Karnataka High Court upheld their use, as did the Madras High Court in 2001.
Since then a number of other challenges have been levelled at EVMs, but the only one that was successful was the petition filed by Subramanian Swamy before the Supreme Court in 2013. But before we get to Swamy's case and its importance, we should understand what EVMs are and how they are used.
The EVM used in India are standardised and extremely simple machines. From a security standpoint this makes them far better than the myriad different, and some notoriously insecure machines used in elections in the USA. Are they 'hack-proof' and 'infallible' as has been claimed by the ECI? Not at all.
Similarly simple voting machines in the Netherlands and Germany were found to have vulnerabilities, leading both those countries to go back to paper ballots.
Because the ECI doesn't provide security researchers free and unfettered access to the EVMs, there had been no independent scrutiny until 2010. That year, an anonymous source provided a Hyderabad-based technologist an original EVM. That technologist, Hari Prasad, and his team worked with some of the world's foremost voting security experts from the Netherlands and the US, and demonstrated several actual live hacks of the EVM itself and several theoretical hacks of the election process, and recommended going back to paper ballots. Further, EVMs have often malfunctioned, as news reports tell us. Instead of working on fixing these flaws, the ECI arrested Prasad (for being in possession of a stolen EVM) and denied Princeton Prof Alex Halderman entry into India when he flew to Delhi to publicly discuss their research. Even in 2017, when the ECI challenged political parties to âhackâ EVMs, it did not provide unfettered access to the machines.
While paper ballots may work well in countries like Germany, they hadn't in India, where in some parts ballot-stuffing and booth-capturing were rampant. The solution as recognised by international experts, and as the ECI eventually realised, was to have the best of both worlds and to add a printer to the EVMs.
These would print out a small slip of paper containing the serial number and name of the candidate, and the symbol of the political party, so that the sighted voter could verify that her vote has been cast correctly. This paper would then be deposited in a sealed box, which would provide a paper trail that could be used to audit the correctness of the EVM. They called this VVPAT: voter-verifiable paper audit trail. Swamy, in his PIL, asked for VVPAT to be introduced. The Supreme Court noted that the ECI had already done trials with VVPAT, and made them mandatory.
However, VVPATs are of no use unless they are actually counted to ensure that the EVM tally and the paper tally do match. The most advanced and efficient way of doing this has been proposed by Lindeman & Stark, through a methodology called (RLAs), in which you keep auditing until either you've done a full hand count or you have strong evidence that continuing is pointless. The ECI could request the Indian Statistical Institute for its recommendations in implementing RLAs. Also, it must be remembered, current VVPAT technology are inaccessible for persons with visual impairments.
While in some cases, the ECI has conducted audits of the printed paper slips, in 2017 it officially noted that only the High Court can order an audit and that the ECI doesn't have the power to do so under election law. Rule 93 of the Conduct of Election Rules needs to be amended to make audits mandatory.
The ECI should also create separate security procedures for handling of VVPATs and EVMs, since there are now reports of EVMs being replaced 'after' voting has ended. Having separate handling of EVMs and VVPATs would ensure that two different safe-houses would need to be broken into to change the results of the vote. Implementing these two changes, changing election law to make risk-limiting audits mandatory, and improving physical security practices would make Indian elections much more trustworthy than they are now, while far more needs to be done to make them inclusive and accessible to all.
The DNA Bill has a sequence of problems that need to be resolved
The opinion piece was published by Newslaundry on January 14, 2019.
On January 9, Science and Technology Minister Harsh Vardhan introduced the DNA Technology (Use and Application) Regulation Bill, 2018, amidst opposition and questions about the Bill’s potential threat to privacy and the lack of security measures. The Bill aims to provide for the regulation of the use and application of DNA technology for certain criminal and civil purposes, such as identifying offenders, suspects, victims, undertrials, missing persons and unknown deceased persons. The Schedule of the Bill also lists civil matters where DNA profiling can be used. These include parental disputes, issues relating to immigration and emigration, and establishment of individual identity. The Bill does not cover the commercial or private use of DNA samples, such as private companies providing DNA testing services for conducting genetic tests or for verifying paternity.
The Bill has seen several iterations and revisions from when it was first introduced in 2007. However, after repeated expert consultations, the Bill even at its current stage is far from a comprehensive legislation. Experts have articulated concerns that the version of the Bill that was presented post the Puttaswamy judgement still fails to make provisions that fully uphold the privacy and dignity of the individual. The hurry to pass the Bill by pushing for it by extending the winter session and before the Personal Data Protection Bill is brought before Parliament is also worrying. The Bill was passed in the Lok Sabha with only one amendment: which changed the year of the Bill from 2018 to 2019.
Need for a better-drafted legislation
Although the Schedule of the Bill includes certain civil matters under its purview, some important provisions are silent on the procedure that is to be followed for these civil matters. For example, the Bill necessitates the consent of the individual for DNA profiling in criminal investigation and for identifying missing persons. However, the Bill is silent on the requirement for consent in all civil matters that have been brought under the scope of the Bill.
The omission of civil matters in the provisions of the Bill that are crucial for privacy is just one of the ways the Bill fails to ensure privacy safeguards. The civil matters listed in the Bill are highly sensitive (such as paternity/maternity, use of assisted reproductive technology, organ transplants, etc.) and can have a far-reaching impact on a number of sections of society. For example, the civil matters listed in the Bill affect women not just in the case of paternity disputes but in a number of matters concerning women including the Domestic Violence Act and the Prenatal Diagnostic Techniques Act. Other matters such as pedigree, immigration and emigration can disproportionately impact vulnerable groups and communities, raising raises concerns of discrimination and abuse.
Privacy and security concerns
Although the Bill makes provisions for written consent for the collection of bodily substances and intimate bodily substances, the Bill allows non-consensual collection for offences punishable by death or imprisonment for a term exceeding seven years. Another issue with respect to collection with consent is the absence of safeguards to ensure that consent is given freely, especially when under police custody. This issue was also highlighted by MP NK Premachandran when he emphasised that the Bill be sent to a Parliamentary Standing Committee.
Apart from the collection, the Bill fails to ensure the privacy and security of the samples. One such example of this failure is Section 35(b), which allows access to the information contained in the DNA Data Banks for the purpose of training. The use of these highly sensitive data—that carry the risk of contamination—for training poses risks to the privacy of the people who have deposited their DNA both with and without consent.
An earlier version of the Bill included a provision for the creation of a population statistics databank. Though this has been removed now, there is no guarantee that this provision will not make its way through regulation. This is a cause for concern as the Bill also covers certain civil cases including those relating to immigration and emigration.
Conclusion
In July 2018, the Justice Sri Krishna Committee released the draft Personal Data Protection Bill. The Bill was open for public consultation and is now likely to be introduced in Parliament in June. The PDP Bill, while defining “sensitive personal data”, provides an exhaustive list of data that can be considered sensitive, including biometric data, genetic data and health data. Under the Bill, sensitive personal data has heightened parameters for collection and processing, including clear, informed, and specific consent. Ideally, the DNA Bill should be passed after ensuring that it is in line with the PDP Bill.
The DNA Bill, once it becomes a law, will allow for law enforcement authorities to collect sensitive DNA data and database the same for forensic purposes without a number of key safeguards in place with respect to security and the rights of individuals. In 2016 alone, 29,75,711 crimes under various provisions the Indian Penal Code were reported. One can only guess the sheer number of DNA profiles and related information that will be collected from both criminal and specified civil cases. The Bill needs to be revised to reduce all ambiguity with respect to the civil cases, and also to ensure that it is in line with the data protection regime in India. A comprehensive privacy legislation should be enacted prior to the passing of this Bill.
There are still studies and cases that show that DNA testing can be fallible. The Indian government needs to ensure that there is proper sensitisation and training on the collection, storage and use of DNA profiles as well as the recognition and awareness of the fact that the DNA tests are not infallible amongst key stakeholders, including law enforcement and the judiciary.
India should reconsider its proposed regulation of online content
The article was published in the Hindustan Times on January 24, 2019. The author would like to thank Akriti Bopanna and Aayush Rathi for their feedback.
Flowing from the Information Technology (IT) Act, India’s current intermediary liability regime roughly adheres to the “safe harbour” principle, i.e. intermediaries (online platforms and service providers) are not liable for the content they host or transmit if they act as mere conduits in the network, don’t abet illegal activity, and comply with requests from authorised government bodies and the judiciary. This paradigm allows intermediaries that primarily transmit user-generated content to provide their services without constant paranoia, and can be partly credited for the proliferation of online content. The law and IT minister shared the intent to change the rules this July when discussing concerns of online platforms being used “to spread incorrect facts projected as news and designed to instigate people to commit crime”.
On December 24, the government published and invited comments to the draft intermediary liability rules. The draft rules significantly expand “due diligence” intermediaries must observe to qualify as safe harbours: they mandate enabling “tracing” of the originator of information, taking down content in response to government and court orders within 24 hours, and responding to information requests and assisting investigations within 72 hours. Most problematically, the draft rules go much further than the stated intentions: draft Rule 3(9) mandates intermediaries to deploy automated tools for “proactively identifying and removing [...] unlawful information or content”.
The first glaring problem is that “unlawful information or content” is not defined. A conservative reading of the draft rules will presume that the phrase means restrictions on free speech permissible under Article 19(2) of the Constitution, including that relate to national integrity, “defamation” and “incitement to an offence”.
Ambiguity aside, is mandating intermediaries to monitor for “unlawful content” a valid requirement under “due diligence”? To qualify as a safe harbour, if an intermediary must monitor for all unlawful content, then is it substantively different from an intermediary that has active control over its content and not a safe harbour? Clearly, the requirement of monitoring for all “unlawful content” is so onerous that it is contrary to the philosophy of safe harbours envisioned by the law.
By mandating automated detection and removal of unlawful content, the proposed rules shift the burden of appraising legality of content from the state to private entities. The rule may run afoul of the Supreme Court’s reasoning in Shreya Singhal v Union of India wherein it read down a similar provision because, among other reasons, it required an intermediary to “apply [...] its own mind to whether information should or should not be blocked”. “Actual knowledge” of illegal content, since then, has held to accrue to the intermediary only when it receives a court or government order.
Given the inconsistencies with legal precedence, the rules may not stand judicial scrutiny if notified in their current form.
The lack of technical considerations in the proposal is also apparent since implementing the proposal is infeasible for certain intermediaries. End-to-end encrypted messaging services cannot “identify” unlawful content since they cannot decrypt it. Internet service providers also qualify as safe harbours: how will they identify unlawful content when it passes encrypted through their network? Presumably, the government’s intention is not to disallow end-to-end encryption so that intermediaries can monitor content.
Intermediaries that can implement the rules, like social media platforms, will leave the task to algorithms that perform even specific tasks poorly. Just recently, Tumblr flagged its own examples of permitted nudity as pornography, and Youtube slapped a video of randomly-generated white noise with five copyright-infringement notices. Identifying more contextual expression, such as defamation or incitement to offences, is a much more complex problem. In the lack of accurate judgement, platforms will be happy to avoid liability by taking content down without verifying whether it violated law. Rule 3(9) also makes no distinction between large and small intermediaries, and has no requirement for an appeal system available to users whose content is taken down. Thus, the proposed rules set up an incentive structure entirely deleterious to the exercise of the right to freedom of expression. Given the wide amplitude and ambiguity of India’s restrictions on free speech, online platforms will end up removing swathes of content to avoid liability if the draft rules are notified.
The use of draconian laws to quell dissent plays a recurring role in the history of the Indian state. The draft rules follow India’s proclivity to join the ignominious company of authoritarian nations when it comes to disrespecting protections for freedom of expression. To add insult to injury, the draft rules are abstruse, ignore legal precedence, and betray a poor technological understanding. The government should reconsider the proposed regulation and the stance which inspired it, both of which are unsuited for a democratic republic.
Response to GCSC on Request for Consultation: Norm Package Singapore
The Global Commission on the Stability of Cyberspace, a multi-stakeholder initiative comprised of eminent individuals across the globe that seeks to promote awareness and understanding among the various cyberspace communities working on issues related to international cyber security. CIS is honoured to have contributed research to this initiative previously and commends the GCSC for the work done so far.
The GCSC announced the release of its new Norm Package on Thursday November 8, 2018 that featured six norms that sought to promote the stability of cyberspace.This was done with the hope that they may be adopted by public and private actors in a bid to improve the international security architecture of cyberspace
The norms introduced by the GCSC focus on the following areas:
- Norm to Avoid Tampering
- Norm Against Commandeering of ICT Devices into Botnets
- Norm for States to Create a Vulnerability Equities Process
- Norm to Reduce and Mitigate Significant Vulnerabilities
- Norm on Basic Cyber Hygiene as Foundational Defense
- Norm Against Offensive Cyber Operations by Non-State Actors
The GCSC opened a public comment procedure to solicit comments and obtain additional feedback. CIS responded to the public call-offering comments on all six norms and proposing two further norms. We sincerely hope that the Commission may find the feedback useful in their upcoming deliberations.
A Gendered Future of Work
Abstract
Studies around the future of work have predicted technological disruption across industries, leading to a shift in the nature and organisation of work, as well as the substitution of certain kinds of jobs and growth of others. This paper seeks to contextualise this disruption for women workers in India. The paper argues that two aspects of the structuring of the labour market will be pertinent in shaping the future of work: the gendered nature of skilling and skill classification, and occupational segregation along the lines of gender and caste. We will take the case study of the electronics manufacturing sector to flesh out these arguments further. Finally, we bring in a discussion on the platform economy, a key area of discussion under the future of work. We characterise it as both generating employment opportunities, particularly for women, due to the flexible nature of work, and retrenching traditional inequalities built into non-standard employment.
Introduction
The question on the future of work across the global North - and parts of the global South - has recently been raised with regards to technological disruption, as a result of digitisation, and more recently, automation (Leurent et al., 2018). While the former has been successively replacing routine cognitive tasks, the latter, defined as the deployment of cyber-physical systems, will enable the replacement of manual tasks previously being performed using human labour (Leurent et al., 2018). In combination, these are expected to have a twofold effect on: the “structure of employment”, which includes occupational roles and nature of tasks, and “forms of work”, including interpersonal relationships and organization of work (Piasna and Drahokoupil, 2017). Building from historical evidence, the diffusion of digitising or automative technologies can be anticipated to take place differently across economic contexts, with different factors causing varied kinds of technological upgradation across the global North and South. Moreover, occupational analysis projects occupations in the latter to be at a significantly higher risk of being disrupted than the former (WTO, 2017).
However, these concerns are somewhat offset by the barriers to technological adoption that exist in lower income countries such as lower wages, and a relatively higher share of non-routine manual jobs (WTO, 2017). 1 With the global North typically being early and quicker adopters of automation technologies, the differential technology levels in countries have been in fact been utilised to understand global inequality (Foster and Rosenzweig, 2010). Consequently, the labour-cost advantage that economies in the global South enjoy may be eroded, leading to what may be understood as re-shoring/back shoring - a reversal of offshoring (ILO, 2017). This may especially be the case in sectors where there has been a failure to capitalise on the labour-cost advantage by evolving supplier networks to complement assembly activities (such as in manufacturing) (Milington, 2017), or production of high-value services (such as in the services sector).
Extensive work over the past three decades has been conducted on the effects of liberalisation and globalisation on employment for women in the global South. This has explored conditional empowerment and exploitation as women are increasingly employed in factories and offices, with different ways of reproducing and challenging patriarchal relations. However, the effects of reshoring and technological disruption have yet to be explored to any degree of granularity for this population, which arguably will be one of the first to face its effects. This can be seen as a consequence of industries that rely on low cost labour being impacted first by re-shoring, such as textile and apparel and electronics manufacturing (Kucera and Tejani, 2014).
Download the full paper here.
CIS Submission to UN High Level Panel on Digital Cooperation
The high-level panel on
Digital Cooperation was convened by the UN Secretary-General to advance
proposals to strengthen cooperation in the digital space among
Governments, the private sector, civil society, international
organizations, academia, the technical community and other relevant
stakeholders. The Panel issued a call for input that called for
responses to various questions. CIS responded to the call for inputs.
The response can be accessed here.
Response to the Draft of The Information Technology [Intermediary Guidelines (Amendment) Rules] 2018
This document presents the Centre for Internet & Society (CIS) response to the Ministry of Electronics and Information Technology’s invitation to comment and suggest changes to the draft of The Information Technology [Intermediary Guidelines (Amendment) Rules] 2018 (hereinafter referred to as the “draft rules”) published on December 24, 2018. CIS is grateful for the opportunity to put forth its views and comments. This response was sent on the January 31, 2019.
In this response, we aim to examine whether the draft rules meet tests of constitutionality and whether they are consistent with the parent Act. We also examine potential harms that may arise from the Rules as they are currently framed and make recommendations to the draft rules that we hope will help the Government meet its objectives while remaining situated within the constitutional ambit.
The response can be accessed here.
The Future of Work in the Automotive Sector in India
Introduction
The adoption of information and communication based technology (ICTs) for industrial use is not a new phenomenon. However, the advent of Industry 4.0 hasbeen described as a paradigm shift in production, involving widespread automation and irreversible shifts in the structure of jobs. Industry 4.0 is widely understood as the technical integration of cyber-physical systems into production and logistics, and the use of Internet of Things (IoTs) in processes and systems. This may pose major challenges for industries, workers, and policymakers as they grapple with shifts in the structure of employment and content of jobs, bring about significant changes in business models, downstream services and the organisation of work.
The adoption of information and communication based technology (ICTs) for industrial use is not a new phenomenon. However, the advent of Industry 4.0 hasbeen described as a paradigm shift in production, involving widespread automation and irreversible shifts in the structure of jobs. Industry 4.0 is widelyunderstood as the technical integration of cyber-physical systems into production and logistics, and the use of Internet of Things (IoTs) in processes and systems.This may pose major challenges for industries, workers, and policymakers as they grapple with shifts in the structure of employment and content of jobs, bringabout significant changes in business models, downstream services and the organisation of work.
Industry 4.0 is characterised by four elements. First, the use of intelligent machines could have significant impact on production through the introduction of automated processes in ‘smart factories.’ Second, real-time production would begin optimising utilisation capacity, with shorter lead times and avoidance of standstills. Third, the self-organisation of machines can lead to decentralisation of production. Finally, Industry 4.0 is commonly characterised by the individualisation of production, responding to customer requests. The advancement of digital technology and consequent increase in automation has raised concerns about unemployment and changes in the structure of work. Globally, automation in manufacturing and services has been posited as replacing jobs with routine task content, while generating jobs with non-routine cognitive and manual tasks.
Some scholars have argued that unemployment will increase globally as technology eliminates tens of million of jobs in the manufacturing sector. It could then result in the lowering of wages and employment opportunities for low skilled workers, and increased investment in capital-intensive technologies for employer.
However, this theory of technologically driven job loss and increasing inequality has been contested on numerous occasions, with the assertion that technology will be an enabler, will change task content rather than displace workers, and will also create new jobs . It has further been argued that other factors such as increasing globalisation, weakening trade unions and platforms for collective bargaining, and disaggregation of the supply chain through outsourcing has led to declined wages, income inequality, inadequate health and safety conditions, and displacement of workers.
In India, there is little evidence of unemployment caused by adoption of technology due to Industry 4.0, but there is a strong consensus that technology affects labour by changing the job mix and skill demand. It should be noted that technological adoption under Industry 4.0 in advanced industrial economies has been driven by cost-benefit analysis due to accessible technology, and a highly skilled labour force. However, these key factors are serious impediments in the Indian context, which brings the large scale adoption of cyber-physical systems into question.
The diffusion of low cost manual labour across a large majority of roles in manufacturing raises concerns about the cost-benefit analysis of investing capital inexpensive automative technology, while also accounting for the resultant displacement of labour. Further, the skill gap across the labour force implies that the adoption of cyber-physical systems would require significant up-skilling or re-skilling to meet the potential shortage in highly skilled professionals.
This is an in-depth case study on the future of work in the automotive sector in India. We chose to focus on the future of work in the automotive sector in India for two reasons: first, the Indian automotive sector is one of largest contributors to the GDP at 7.2 percent, and second, it is one of the largest employment generators among non-agricultural industries. The first section details the structure of the automotive industry in India, including the range of stakeholders, and the national policy framework, through an analysis of academic literature, government reports, and legal documents.
The second section explores different aspects of the future of work in the automotive sector, through a combination of in-depth semi-structured interviews and enterprise-based surveys in the North Indian belt of Gurgaon-Manesar-Dharuhera-Bawal. Challenges posed by shifts in the industrial relations framework, with increasing casualization and emergence of a typical forms of work, will also be explored, with specific reference to crises in collective bargaining and social security. We will then move onto looking at the state of female participation in the workforce in the automotive industry. The report concludes with policy recommendations addressing some of the challenges outlined above.
Read the full report here.
CIS Comment on ICANN's Draft FY20 Operating Plan and Budget
The following are our comments on relevant aspects from the different documents:
There are several significant undertakings which have not found adequate support in this budget, chief among them being the implementation of the ICANN Workstream 2 recommendations on Accountability. The budget accounts for any expenses that arise from WS2 as emanating from its contingency fund which is a mere 4%. Totalling more than 100 recommendations across 8 sub groups, execution of these would require significant expenditure. Ideally, this should have been budgeted for in the FY20 budget considering the final report was submitted in June, 2018 and conversations about its implementation have been carried out ever since. It is wondered if this is because the second Workstream does not have the effectuation of its recommendations in its mandate and hence it is easier for ICANN to be slow on it.[1] As a member of the community deeply interested in integrating human rights better in ICANN’s various processes, it is concerning to note the glacial pace of the approval of the aforementioned recommendations especially coupled with the lack of funds allocated to it. Further, there is 1 one person assigned to work on the WS2 implementation work which seems insufficient for the magnitude of work involved.[2]
A topical issue with ICANN currently is its tussle with the implementation of the General Data Protection Regulation (GDPR) and despite the prominence and extent of the legal burden involved, resources to complying with it have not been allocated. Again, it is within the umbrella of the contingency budget.
The Cross Community Working Group on New gTLD Auction Proceeds is also, presently, developing recommendations on how to distribute the proceeds. It is unclear where these will be funded from since their work is funded by the core ICANN budget yet it is assumed that the recommendations will be funded by the auction proceeds. Almost 7 years after the new gTLD round was open, it is alarming that ICANN has not formulated a plan for the proceeds and are still debating the merits of the entity which would resolve this question, as recently as the last ICANN meeting in October, 2018.
Another important policy development process being undertaken right now is the Working Group who is reviewing the current new gTLD policies to improve the process by proposing changes or new policies. There are no resources in the FY20 budget to implement the changes that will arise from this but only those to support the Working Group activities.
Lastly, the budgets lack information on how much each individual RIR contributes.
Staff costs
ICANN’s internal costs on their personnel have been rising for years and slated to account for more than half their annual budget with an estimated 56% or $76.3 million in the next financial year. The community has been consistent in calling upon them to revise their staff costs with many questioning if the growth in staff is justified.[3] There was criticism from all quarters such as the GNSO Council who stated that it is “not convinced that the proposed budget funds the policy work it needs to do over the coming year”.[4] The excessive use of professional service consultants has come under fire too.
As pointed out in a mailing list, in comments on the FY19 budget, every single constituency and stakeholder group remarked that personnel costs presented too high a burden on the budget. One of the suggestions presented by the NCSG was to relocate positions from from the LA headquarters to less expensive countries such as those in Asia. This can be seen from the high increase this budget of $200,000 in operational costs though no clear breakdown of that entails was given.
The view seems to be that ICANN repeatedly chooses to retain higher salaries while reducing funding for the community. This is even more of an issue since there employment remuneration scheme is opaque. In a DIDP I filed enquiring about the average salary across designations, gender, regions and the frequency of bonuses, the response was either to refer to their earlier documents which do not have concrete information or that the relevant documents were not in their possession.[5]
ICANN Fellowship
The budget of the fellowship has been reduced which is an important initiative to involve individuals in ICANN who cannot afford the cost of flying to the global ICANN meetings. The focus should be not only be on arriving at a suitable figure for the funding but also to ensure that people who either actively contribute or are likely to are supported as opposed to individuals who are already known in this circle.
Again, our attempts at understanding the Fellowship selection were met with resistance from ICANN. In a DIDP filed regarding it with questions such as if anyone had received it more than the maximum limit of thrice and details on the selection criteria, no clarity was provided.[6]
Lobbying and Sponsorship
At ICANN 63 in Barcelona, I enquired about ICANN’s sponsorship strategies and how the decision making is done with respect to which all events in each region to sponsor and for a comprehensive list of all sponsorship ICANN undertakes and receives. I was told such a document would be published soon but in the 4 months since then, none can be found. It is difficult to comment on the budget for such a team where there is not much information on the work it specifically carries out and the impact of such sponsoring activities. When questioned to someone on their team, I was told that it depends on the needs of each region and events that are significant in such regions. However without public accountability and transparency about these, sponsorship can be seen as a vague heading which could be better spent on community initiatives.
Talking of Transparency, it has also been pointed out that the Information Transparency Initiative has 3 million dollars set aside for its activities in this budget. It sounds positive yet with no deliverables to show in the past 2 years, it is difficult to ascertain the value of the investment in this initiative.
Lobbying activities do not find any mention in the budget and neither do the nature of sponsorship from other entities in terms of whether it is travel and accommodation of personnel or any other kind of institutional sponsorship.
[1] https://cis-india.org/internet-governance/blog/icann-work-stream-2-recommendations-on-accountability
[2] https://www.icann.org/en/system/files/files/proposed-opplan-fy20-17dec18-en.pdf
[3] http://domainincite.com/22680-community-calls-on-icann-to-cut-staff-spending
[4] Ibid
[5]https://cis-india.org/internet-governance/blog/didp-request-30-enquiry-about-the-employee-pay-structure-at-icann
[6] https://cis-india.org/internet-governance/blog/didp-31-on-icanns-fellowship-program
Intermediary liability law needs updating
The article was published in Business Standard on February 9, 2019.
Intermediaries get immunity from liability emerging from user-generated and third-party content because they have no “actual knowledge” until it is brought to their notice using “take down” requests or orders.
Since some of the harm caused is immediate, irreparable and irreversible, it is the preferred alternative to approaching courts for each case. When intermediary liability regimes were first enacted, most intermediaries were acting as common carriers — ie they did not curate the experience of users in a substantial fashion. While some intermediaries like Wikipedia continue this common carrier tradition, others driven by advertising revenue no longer treat all parties and all pieces of content neutrally. Facebook, Google and Twitter do everything they can to raise advertising revenues. They make you depressed. And if they like you, they get you to go out and vote. There is an urgent need to update intermediary liability law.
In response to being summoned by multiple governments, Facebook has announced the establishment of an independent oversight board. A global free speech court for the world’s biggest online country. The time has come for India to exert its foreign policy muscle. The amendments to our intermediary liability regime can have global repercussions, and shape the structure and functioning of this and other global courts.
While with one hand Facebook dealt the oversight board, with the other hand it took down APIs that would enable press and civil society to monitor political advertising in real time. How could they do that with no legal consequences? The answer is simple — those APIs were provided on a voluntary basis. There was no law requiring them to do so.
There are two approaches that could be followed. One, as scholar of regulatory theory Amba Kak puts it, is to “disincentivise the black box”. Most transparency reports produced by intermediaries today are on a voluntary basis; there is no requirement for this under law. Our new law could require a extensive transparency with appropriate privacy safeguards for the government, affected parties and the general public in terms of revenues, content production and consumption, policy development, contracts, service-level agreements, enforcement, adjudication and appeal. User empowerment measures in the user interface and algorithm explainability could be required. The key word in this approach is transparency.
The alternative is to incentivise the black box. Here faith is placed in technological solutions like artificial intelligence. To be fair, technological solutions may be desirable for battling child pornography, where pre-censorship (or deletion before content is published) is required. Fingerprinting technology is used to determine if the content exists in a global database maintained by organisations like the Internet Watch Foundation. A similar technology called Content ID is used pre-censor copyright infringement. Unfortunately, this is done by ignoring the flexibilities that exist in Indian copyright law to promote education, protect access knowledge by the disabled, etc. Even within such narrow application of technologies, there have been false positives. Recently, a video of a blogger testing his microphone was identified as a pre-existing copyrighted work.
The goal of a policy-maker working on this amendment should be to prevent repeats of the Shreya Singhal judgment where sections of the IT Act were read down or struck down. To avoid similar constitution challenges in the future, the rules should not specify any new categories of illegal content, because that would be outside the scope of the parent clause. The fifth ground in the list is sufficient — “violates any law for the time being in force”. Additional grounds, such as “harms minors in anyway”, is vague and cannot apply to all categories of intermediaries — for example, a dating site for sexual minorities. The rights of children need to be protected. But that is best done within the ongoing amendment to the POCSO Act.
As an engineer, I vote to eliminate redundancy. If there are specific offences that cannot fit in other parts of the law, those offences can be added as separate sections in the IT Act. For example, even though voyeurism is criminalised in the IT Act, the non-consensual distribution of intimate content could be criminalised, as it has been done in the Philippines.
Provisions that have to do with data retention and government access to that data for the purposes of national security, law enforcement and also anonymised datasets for the public interest should be in the upcoming Data Protection law. The rules for intermediary liability is not the correct place to deal with it, because data retention may also be required of those intermediaries that don’t handle any third-party information or user generated content. Finally, there have to be clear procedures in place for reinstatement of content that has been taken down.
Disclosure: The Centre for Internet and Society receives grants from Facebook, Google and Wikimedia Foundation
Data Infrastructures and Inequities: Why Does Reproductive Health Surveillance in India Need Our Urgent Attention?
The article was first published by EPW Engage, Vol. 54, Issue No. 6, on 9 February 2019.
Framing Reproductive Health as a Surveillance Question
The approach of the postcolonial Indian state to healthcare has been Malthusian, with the prioritisation of family planning and birth control (Hodges 2004). Supported by the notion of socio-economic development arising out of a “modernisation” paradigm, the target-based approach to achieving reduced fertility rates has shaped India’s reproductive and child health (RCH) programme (Simon-Kumar 2006).
This is also the context in which India’s abortion law, the Medical Termination of Pregnancy (MTP) Act, was framed in 1971, placing the decisional privacy of women seeking abortions in the hands of registered medical practitioners. The framing of the MTP act invisibilises females seeking abortions for non-medical reasons within the legal framework. The exclusionary provisions only exacerbated existing gaps in health provisioning, as access to safe and legal abortions had already been curtailed by severe geographic inequalities in funding, infrastructure, and human resources. The state has concomitantly been unable to meet contraceptive needs of married couples or reduce maternal and infant mortality rates in large parts of the country, mediating access along the lines of class, social status, education, and age (Sanneving et al 2013).
While the official narrative around the RCH programme transitioned to focus on universal access to healthcare in the 1990s, the target-based approach continues to shape the reality on the ground. The provision of reproductive healthcare has been deeply unequal and, in some cases, in hospitals. These targets have been known to be met through the practice of forced, and often unsafe, sterilisation, in conditions of absence of adequate provisions or trained professionals, pre-sterilisation counselling, or alternative forms of contraception (Sama and PLD 2018). Further, patients have regularly been provided cash incentives, foreclosing the notion of free consent, especially given that the target population of these camps has been women from marginalised economic classes in rural India.
Placing surveillance studies within a feminist praxis allows us to frame the reproductive health landscape as more than just an ill-conceived, benign monitoring structure. The critical lens becomes useful for highlighting that taken-for-granted structures of monitoring are wedded with power differentials: genetic screening in fertility clinics, identification documents such as birth certificates, and full-body screeners are just some of the manifestations of this (Adrejevic 2015). Emerging conversations around feminist surveillance studies highlight that these data systems are neither benign nor free of gendered implications (Andrejevic 2015). In continual remaking of the social, corporeal body as a data actor in society, such practices render some bodies normative and obfuscate others, based on categorisations put in place by the surveiller.
In fact, the history of surveillance can be traced back to the colonial state where it took the form of systematic sexual and gendered violence enacted upon indigenous populations in order to render them compliant (Rifkin 2011; Morgensen 2011). Surveillance, then, manifests as a “scientific” rationalisation of complex social hieroglyphs (such as reproductive health) into formats enabling administrative interventions by the modern state. Lyon (2001) has also emphasised how the body emerged as the site of surveillance in order for the disciplining of the “irrational, sensual body”—essential to the functioning of the modern nation-state—to effectively happen.
Questioning the Information and Communications Technology for Development (ICT4D) and Big Data for Development (BD4D) Rhetoric
Information and Communications Technology (ICT) and data-driven approaches to the development of a robust health information system, and by extension, welfare, have been offered as solutions to these inequities and exclusions in access to maternal and reproductive healthcare in the country.
The move towards data-driven development in the country commenced with the introduction of the Health Management Information System in Andhra Pradesh in 2008, and the Mother and Child Tracking System (MCTS) nationally in 2011. These are reproductive health information systems (HIS) that collect granular data about each pregnancy from the antenatal to the post-natal period, at the level of each sub-centre as well as primary and community health centre. The introduction of HIS comprised cross-sectoral digitisation measures that were a part of the larger national push towards e-governance; along with health, thirty other distinct areas of governance, from land records to banking to employment, were identified for this move towards the digitalised provisioning of services (MeitY 2015).
The HIS have been seen as playing a critical role in the ecosystem of health service provision globally. HIS-based interventions in reproductive health programming have been envisioned as a means of: (i) improving access to services in the context of a healthcare system ridden with inequalities; (ii) improving the quality of services provided, and (iii) producing better quality data to facilitate the objectives of India’s RCH programme, including family planning and population control. Accordingly, starting 2018, the MCTS is being replaced by the RCH portal in a phased manner. The RCH portal, in areas where the ANMOL (ANM Online) application has been introduced, captures data real-time through tablets provided to health workers (MoHFW 2015).
A proposal to mandatorily link the Aadhaar with data on pregnancies and abortions through the MCTS/RCH has been made by the union minister for Women and Child Development as a deterrent to gender-biased sex selection (Tembhekar 2016). The proposal stems from the prohibition of gender-biased sex selection provided under the Pre-Conception and Pre-Natal Diagnostics Techniques (PCPNDT) Act, 1994. The approach taken so far under the PCPNDT Act, 2014 has been to regulate the use of technologies involved in sex determination. However, the steady decline in the national sex ratio since the passage of the PCPNDT Act provides a clear indication that the regulation of such technology has been largely ineffective. A national policy linking Aadhaar with abortions would be aimed at discouraging gender-biased sex selection through state surveillance, in direct violation of a female’s right to decisional privacy with regards to their own body.
Linking Aadhaar would also be used as a mechanism to enable direct benefit transfer (DBT) to the beneficiaries of the national maternal benefits scheme. Linking reproductive health services to the Aadhaar ecosystem has been critiqued because it is exclusionary towards women with legitimate claims towards abortions and other reproductive services and benefits, and it heightens the risk of data breaches in a cultural fabric that already stigmatises abortions. The bodies on which this stigma is disproportionately placed, unmarried or disabled females, for instance, experience the harms of visibility through centralised surveillance mechanisms more acutely than others by being penalised for their deviance from cultural expectations. This is in accordance with the theory of "data extremes,” wherein marginalised communities are seen as living on the extremes of data capture, leading to a data regime that either refuses to recognise them as legitimate entities or subjects them to overpolicing in order to discipline deviance (Arora 2016). In both developed and developing contexts, the broader purpose of identity management has largely been to demarcate legitimate and illegitimate actors within a population, either within the framework of security or welfare.
Potential Harms of the Data Model of Reproductive Health Provisioning
Informational privacy and decisional privacy are critically shaped by data flows and security within the MCTS/RCH. No standards for data sharing and storage, or anonymisation and encryption of data have been implemented despite role-based authentication (NHSRC and Taurus Glocal 2011). The risks of this architectural design are further amplified in the context of the RCH/ANMOL where data is captured real-time. In the absence of adequate safeguards against data leaks, real-time data capture risks the publicising of reproductive health choices in an already stigmatised environment. This opens up avenues for further dilution of autonomy in making future reproductive health choices.
Several core principles of informational privacy, such as limitations regarding data collection and usage, or informed consent, also need to be reworked within this context.[1] For instance, the centrality of the requirement of “free, informed consent” by an individual would need to be replaced by other models, especially in the context of reproductive health of rape survivors who are vulnerable and therefore unable to exercise full agency. The ability to make a free and informed choice, already dismantled in the context of contemporary data regimes, gets further precluded in such contexts. The constraints on privacy in decisions regarding the body are then replicated in the domain of reproductive data collection.
What is uniform across these digitisation initiatives is their treatment of maternal and reproductive health as solely a medical event, framed as a data scarcity problem. In doing so, they tend to amplify the understanding of reproductive health through measurable indicators that ignore social determinants of health. For instance, several studies conducted in the rural Indian context have shown that the degree of women’s autonomy influences the degree of usage of pregnancy care, and that the uptake of pregnancy care was associated with village-level indicators such as economic development, provisioning of basic infrastructure and social cohesion. These contextual factors get overridden in pervasive surveillance systems that treat reproductive healthcare as comprising only of measurable indicators and behaviours, that are dependent on individual behaviour of practitioners and women themselves, rather than structural gaps within the system.
While traditionally associated with state governance, the contemporary surveillance regime is experienced as distinct from its earlier forms due to its reliance on a nexus between surveillance by the state and private institutions and actors, with both legal frameworks and material apparatuses for data collection and sharing (Shepherd 2017). As with historical forms of surveillance, the harms of contemporary data regimes accrue disproportionately among already marginalised and dissenting communities and individuals. Data-driven surveillance has been critiqued for its excesses in multiple contexts globally, including in the domains of predictive policing, health management, and targeted advertising (Mason 2015). In the attempts to achieve these objectives, surveillance systems have been criticised for their reliance on replicating past patterns, reifying proximity to a hetero-patriarchal norm (Haggerty and Ericson 2000). Under data-driven surveillance systems, this proximity informs the preexisting boxes of identity for which algorithmic representations of the individual are formed. The boxes are defined contingent on the distinct objectives of the particular surveillance project, collating disparate pieces of data flows and resulting in the recasting of the singular offline self into various 'data doubles' (Haggerty and Ericson 2000). Refractive, rather than reflective, the data doubles have implications for the physical, embodied life of individual with an increasing number of service provisioning relying on the data doubles (Lyon 2001). Consider, for instance, apps on menstruation, fertility, and health, and wearables such as fitness trackers and pacers, that support corporate agendas around what a woman’s healthy body should look, be or behave like (Lupton 2014). Once viewed through the lens of power relations, the fetishised, apolitical notion of the data “revolution” gives way to what we may better understand as “dataveillance.”
Towards a Networked State and a Neo-liberal Citizen
Following in this tradition of ICT being treated as the solution to problems plaguing India’s public health information system, a larger, all-pervasive healthcare ecosystem is now being proposed by the Indian state (NITI Aayog 2018). Termed the National Health Stack, it seeks to create a centralised electronic repository of health records of Indian citizens with the aim of capturing every instance of healthcare service usage. Among other functions, it also envisions a platform for the provisioning of health and wellness-based services that may be dispensed by public or private actors in an attempt to achieve universal health coverage. By allowing private parties to utilise the data collected through pullable open application program interfaces (APIs), it also fits within the larger framework of the National Health Policy 2017 that envisions the private sector playing a significant role in the provision of healthcare in India. It also then fits within the state–private sector nexus that characterises dataveillance. This, in turn, follows broader trends towards market-driven solutions and private financing of health sector reform measures that have already had profound consequences on the political economy of healthcare worldwide (Joe et al 2018).
These initiatives are, in many ways, emblematic of the growing adoption of network governance reform by the Indian state (Newman 2001). This is a stark shift from its traditional posturing as the hegemonic sovereign nation state. This shift entails the delayering from large, hierarchical and unitary government systems to horizontally arranged, more flexible, relatively dispersed systems.[2] The former govern through the power of rules and law, while the latter take the shape of self-regulating networks such as public–private contractual arrangements (Snellen 2005). ICTs have been posited as an effective tool in enabling the transition to network governance by enhancing local governance and interactive policymaking enabling the co-production of knowledge (Ferlie et al 2011). The development of these capabilities is also critical to addressing “wicked problems” such as healthcare (Rittel and Webber 1973).[3] The application of the techno-deterministic, data-driven model to reproductive healthcare provision, then, resembles a fetishised approach to technological change. The NHSRC describes this as the collection of data without an objective, leading to a disproportional burden on data collection over use (NHSRC and Taurus Glocal 2011).
The blurring of the functions of state and private actors is reflective of the neo-liberal ethic, which produces new practices of governmentality. Within the neo-liberal framework of reproductive healthcare, the citizen is constructed as an individual actor, with agency over and responsibility for their own health and well-being (Maturo et al 2016).
“Quantified Self” of the Neo-liberal Citizen
Nowhere can the manifestation of this neo-liberal citizen can be seen as clearly as in the “quantified self” movement. The quantified self movement refers to the emergence of a whole range of apps that enable the user to track bodily functions and record data to achieve wellness and health goals, including menstruation, fertility, pregnancies, and health indicators in the mother and baby. Lupton (2015) labels this as the emergence of the “digitised reproductive citizen,” who is expected to be attentive to her fertility and sexual behaviour to achieve better reproductive health goals. The practice of collecting data around reproductive health is not new to the individual or the state, as has been demonstrated by the discussion above. What is new in this regime of datafication under the self-tracking movement is the monetisation of reproductive health data by private actors, the labour for which is performed by the user. Focusing on embodiment draws attention to different kinds of exploitation engendered by reproductive health apps. Not only is data about the body collected and sold, the unpaid labour for collection is extracted from the user. The reproductive body can then be understood as a cyborg, or a woman-machine hybrid, systematically digitising its bodily functions for profit-making within the capitalist (re)production machine (Fotoloulou 2016). Accordingly, all major reproductive health tracking apps have a business model that relies on selling information about users for direct marketing of products around reproductive health and well-being (Felizi and Varon nd).
As has been pointed out in the case of big data more broadly, reproductive health applications (apps) facilitate the visibility of the female reproductive body in the public domain. Supplying anonymised data sets to medical researchers and universities fills some of the historical gaps in research around the female body and reproductive health. Reproductive and sexual health tracking apps globally provide their users a platform to engage with biomedical information around sexual and reproductive health. Through group chats on the platform, they are also able to engage with experiential knowledge of sexual and reproductive health. This could also help form transnational networks of solidarity around the body and health (Fotopoulou 2016).
This radical potential of network-building around reproductive and sexual health is, however, tempered to a large extent by the reconfiguration of gendered stereotypes through these apps. In a study on reproductive health apps on Google Play Store, Lupton (2014) finds that products targeted towards female users are marketed through the discourse of risk and vulnerability, while those targeted towards male users are framed within that of virility. Apart from reiterating gendered stereotypes around the male and female body, such a discourse assumes that the entire labour of family planning is performed by females. This same is the case with the MCTS/RCH.
Technological interventions such as reproductive health apps as well as HIS are based on the assumption that females have perfect control over decisions regarding their own bodies and reproductive health, despite this being disproved in India. The Guttmacher Institute (2014) has found that 60% of women in India report not having control over decisions regarding their own healthcare. The failure to account for the husband or the family as stakeholder in decision-making around reproductive health has been a historical failure of the family planning programme in India, and is now being replicated in other modalities. This notion of an autonomous citizen who is able to take responsibility of their own reproductive health and well-being does not hold true in the Indian context. It can even be seen as marginalising females who have already been excluded from the reproductive health system, as they are held responsible for their own inability to access healthcare.
Concluding Remarks
The interplay that emerges between reproductive health surveillance and data infrastructures is a complex one. It requires the careful positioning of the political nature of data collection and processing as well as its hetero-patriarchal and colonial legacies, within the need for effective utilisation of data for achieving developmental goals. Assessing this discourse through a feminist lens identifies the web of power relations in data regimes. This problematises narratives of technological solutions for welfare provision.
The reproductive healthcare framework in India then offers up a useful case study to assess these concerns. The growing adoption of ICT-based surveillance tools to equalise access to healthcare needs to be understood in the socio-economic, legal, and cultural context where these tools are being implemented. Increased surveillance has historically been associated with causing the structural gendered violence that it is now being offered as a solution to. This is a function of normative standards being constructed for reproductive behaviour that necessarily leave out broader definitions of reproductive health and welfare when viewed through a feminist lens. Within the larger context of health policymaking in India, moves towards privatisation then demonstrate the peculiarity of dataveillance as it functions through an unaccountable and pervasive overlapping of state and private surveillance practises. It remains to be seen how these trends in ICT-driven health policies affect access to reproductive rights and decisional privacy for millions of females in India and other parts of the global South.
CIS Submission to UN High Level Panel on Digital Co-operation
Download the submission here
CIS Submission to the UN Special Rapporteur on Freedom of Speech and Expression: Surveillance Industry and Human Rights
CIS is grateful for the opportunity to submit the United Nations (UN) Special Rapporteur on call for submissions on the surveillance industry and human rights.1 Over the last decade, CIS has worked extensively on research around state and private surveillance around the world. In this response, individuals working at CIS wish to highlight these programs, with a special focus on India.
The response can be accessed here.
Resurrecting the marketplace of ideas
The article by Arindrajit Basu was published in Hindu Businessline on February 19, 2019.
A century after the ‘marketplace of ideas’ first found its way into a US Supreme Court judgment through the dissenting opinion of Justice Oliver Wendell Holmes Jr (Abrams v United States, 1919), the oft-cited rationale for free speech is arguably under siege.
The increasing quantity and range of online speech hosted by internet platforms coupled with the shock waves sent by revelations of rampant abuse through the spread of misinformation has lead to a growing inclination among governments across the globe to demand more aggressive intervention by internet platforms in filtering the content they host.
Rule 3(9) of the Draft of the Information Technology [Intermediary Guidelines (Amendment) Rules] 2018 released by the Ministry of Electronics and Information Technology (MeiTy) last December follows the interventionist regulatory footsteps of countries like Germany and France by mandating that platforms use “automated tools or appropriate mechanisms, with appropriate controls, for proactively identifying and removing or disabling public access to unlawful information or content.”
Like its global counterparts, this rule, which serves as a pre-condition for granting immunity to the intermediary from legal claims arising out of user-generated communications, might not only have an undue ‘chilling effect’ on free speech but is also a thoroughly uncooked policy intervention.
Censorship by proxy
Rule 3(9) and its global counterparts might not be in line with the guarantees enmeshed in the right to freedom of speech and expression for three reasons. First, the vague wording of the law and the abstruse guidelines for implementation do not provide clarity, accessibility and predictability — which are key requirements for any law restricting free speech .The NetzDG-the German law, aimed at combating agitation and fake news, has attracted immense criticism from civil society activists and the UN Special Rapporteur David Kaye on similar grounds.
Second, as proved by multiple empirical studies across the globe, including one conducted by CIS on the Indian context, it is likely that legal requirements mandating that private sector actors make determinations on content restrictions can lead to over-compliance as the intermediary would be incentivised to err on the side of removal to avoid expensive litigation.
Finally, by shifting the burden of determining and removing ‘unlawful’ content onto a private actor, the state is effectively engaging in ‘censorship by proxy’. As per Article 12 of the Constitution, whenever a government body performs a ‘public function’, it must comply with all the enshrined fundamental rights.
Any individual has the right to file a writ petition against the state for violation of a fundamental right, including the right to free speech.
However, judicial precedent on the horizontal application of fundamental rights, which might enable an individual to enforce a similar claim against a private actor has not yet been cemented in Indian constitutional jurisprudence.
This means that any individual whose content has been wrongfully removed by the platform may have no recourse in law — either against the state or against the platform.
Algorithmic governmentality
Using automated technologies comes with its own set of technical challenges even though they enable the monitoring of greater swathes of content. The main challenge to automated filtering is the incomplete or inaccurate training data as labelled data sets are expensive to curate and difficult to acquire, particularly for smaller players.
Further, an algorithmically driven solution is an amorphous process.
Through it is hidden layers and without clear oversight and accountability mechanisms, the machine generates an output, which corresponds to assessing the risk value of certain forms of speech, thereby reducing it to quantifiable values — sacrificing inherent facets of dignity such as the speaker’s unique singularities, personal psychological motivations and intentions.
Possible policy prescriptions
The first step towards framing an adequate policy response would be to segregate the content needing moderation based on the reason for them being problematic.
Detecting and removing information that is false might require the crafting of mechanisms that are different from those intended to tackle content that is true but unlawful, such as child pornography.
Any policy prescription needs to be adequately piloted and tested before implementation. It is also likely that the best placed prescription might be a hybrid amalgamation of the methods outlined below.
Second, it is imperative that the nature of intermediaries to which a policy applies are clearly delineated. For example, Whatsapp, which offers end-to-end encrypted services would not be able to filter content in the same way internet platforms like Twitter can.
The first option going forward is user-filtering, which as per a recent paper written by Ivar Hartmann, is a decentralised process, through which the users of an online platform collectively endeavour to regulate the flow of information.
Users collectively agree on a set of standards and general guidelines for filtering. This method combined with an oversight and grievance redressal mechanism to address any potential violation may be a plausible one.
The second model is enhancing the present model of self-regulation. Ghonim and Rashbass recommend that the platform must publish all data related to public posts and the processes followed in a certain post attaining ‘viral’ or ‘trending’ status or conversely, being removed.
This, combined with Application Programme Interfaces (APIs) or ‘Public Interest Algorithms’, which enables the user to keep track of the data-driven process that results in them being exposed to a certain post, might be workable if effective pilots for scaling are devised.
The final model that operates outside the confines of technology are community driven social mechanisms. An example of this is Telengana Police Officer Remi Rajeswari’s efforts to combat fake news in rural areas by using Janapedam — an ancient form of story-telling — to raise awareness about these issues.
Given the complex nature of the legal, social and political questions involved here, the quest for a ‘silver-bullet’ might be counter-productive.
Instead, it is essential for us to take a step back, frame the right questions to understand the intricacies in the problems involved and then, through a mix of empirical and legal analysis, calibrate a set of policy interventions that may work for India today.
Comments on the Draft Second Protocol to the Convention on Cybercrime (Budapest Convention)
The Centre for Internet and Society, (“CIS”), is a non-profit organisation that undertakes interdisciplinary research on internet and digital technologies from policy and academic perspectives. The areas of focus include digital accessibility for persons with diverse abilities, access to knowledge, intellectual property rights, openness (including open data, free and open source software, open standards, and open access), internet governance, telecommunication reform, digital privacy, artificial intelligence, freedom of expression, and cyber-security. This submission is consistent with CIS’ commitment to safeguarding general public interest, and the rights of stakeholders. CIS is thankful to the Cybercrime Convention Committee for this opportunity to provide feedback to the Draft.
The draft text addresses three issues viz. language of requests, emergency multilateral cooperation and taking statements through video conferencing. Click to download the entire submission here.
Unbox Festival 2019: CIS organizes two Workshops
'What is your Feminist Infrastructure Wishlist?
The first workshop 'What is your Feminist Infrastructure Wishlist?' was on Feminist Infrastructure Wishlists that was conducted by P.P. Sneha and Saumyaa Naidu on 15 February 2019. The objective of the workshop was to explore what it means to have infrastructure that is feminist. How do we build spaces, networks, and systems that are equal, inclusive, diverse, and accessible? We will also reflect on questions of network configurations, expertise, labour and visibility. For reading material click here.
AI for Good
With a backdrop of AI for social good, we explore existing applications of artificial intelligence, how we interact and engage with this technology on a daily basis. A discussion led by Saumyaa Naidu and Shweta Mohandas invited participants to examine current narratives around AI and imagine how these may transform with time. Questions around how we can build an AI for the future will become the starting point to trace its implications relating to social impact, policy, gender, design, and privacy. For reading materials see AI Now Report 2018, Machine Bias, and Why Do So Many Digital Assistants Have Feminine Names?
For info on Unbox Festival, click here
The Localisation Gambit: Unpacking policy moves for the sovereign control of data in India
The full paper can be accessed here.
Executive Summary
The vision of a borderless internet that functions as an open distributed network is slowly ceding ground to a space that is greatly political, and at risk of fragmentation due to cultural, economic, and geo-political differences. A variety of measures for asserting sovereign control over data within national territories is a manifestation of this trend. Over the past year, the Indian government has drafted and introduced multiple policy instruments which dictate that certain types of data must be stored in servers located physically within the territory of India. These localization gambits have triggered virulent debate among corporations, civil society actors, foreign stakeholders, business guilds, politicians, and governments. This White Paper seeks to serve as a resource for stakeholders attempting to intervene in this debate and arrive at a workable solution where the objectives of data localisation are met through measures that have the least negative impact on India’s economic, political, and legal interests. We begin this paper by studying the pro-localisation policies in India. We have defined data localisation as 'any legal limitation on the ability for data to move globally and remain locally.' These policies can take a variety of forms. This could include a specific requirement to locally store copies of data, local content production requirements, or imposing conditions on cross border data transfers that in effect act as a localization mandate.Presently, India has four sectoral policies that deal with localization requirements based on type of data, for sectors including banking, telecom, and health - these include the RBI Notification on ‘Storage of Payment System Data’, the FDI Policy 2017, the Unified Access License, and the Companies Act, 2013 and its Rules, The IRDAI (Outsourcing of Activities by Indian Insurers) Regulations, 2017, and the National M2M Roadmap.
At the same time, 2017 and 2018 has seen three separate proposals for comprehensive and sectoral localization requirements based on type of data across sectors including the draft Personal Data Protection Bill 2018, draft e-commerce policy, and the draft e-pharmacy regulations. The policies discussed reflect objectives such as enabling innovation, improving cyber security and privacy, enhancing national security, and protecting against foreign surveillance. The subsequent section reflects on the objectives of such policy measures, and the challenges and implications for individual rights, markets, and international relations. We then go on to discuss the impacts of these policies on India’s global and regional trade agreements. We look at the General Agreement on Trade in Services (GATS) and its implications for digital trade and point out the significance of localisation as a point of concern in bilateral trade negotiations with the US and the EU. We then analyse the responses of fifty-two stakeholders on India’s data localisation provisions using publicly available statements and submissions. Most civil society groups - both in India and abroad are ostensibly against blanket data localisation, the form which is mandated by the Srikrishna Bill. Foreign stakeholders including companies such as Google and Facebook, politicians including US Senators, and transnational advocacy groups such as the US-India Strategic Partnership Forum, were against localisation citing it as a grave trade restriction and an impediment to a global digital economy which relies on the cross-border flow of data. The stance taken by companies such as Google and Facebook comes as no surprise, since they would likely incur huge costs in setting up data centres in India if the localisation mandate was implemented.
Stakeholders arguing for data localisation included politicians and some academic and civil society voices that view this measure as a remedy for ‘data colonialism’ by western companies and governments. Large Indian corporations, such as Reliance, that have the capacity to build their own data centres or pay for their consumer data to be stored on data servers support this measure citing the importance of ‘information sovereignty.’ However, industry associations such as NASSCOM and Internet and Mobile Association of Indian (IAMAI) are against the mandate citing a negative impact on start-ups that may not have the financial capacity to fulfil the compliance costs required. Leading private players in the digital economy, such as Phone Pe and Paytm support the mandate on locally storing payments data as they believe it might improve the condition of financial security services. As noted earlier, various countries have begun to implement restrictions on the cross-border flow of data. We studied 18 countries that have such mandates and found that models can differ on the basis of the strength and type of mandate, as well as the type of data to which the restriction applies, and sectors to which the mandate extends to. These models can be used by india to think think through potential means of pushing through a localisation mandate. Our research suggests that the various proposed data localization measures, serve the primary objective of ensuring sovereign control over Indian data. Various stakeholders have argued that data localisation is a way of asserting Indian sovereignty over citizens’ data and that the data generated by Indian individuals must be owned by Indian corporations. It has been argued that Indian citizens’ data must be governed my Indian laws, security standards and protocols.
However, given the complexity of technology, the interconnectedness of global data flows, and the potential economic and political implications of localization requirements - approaches to data sovereignty and localization should be nuanced. In this section we seek to posit the building blocks which can propel research around these crucial issues. We have organized these questions into the broader headings of prerequisites, considerations, and approaches:
PRE-REQUISITES
From our research, we find that any thinking on data localisation requirements must be preceded with the following prerequisites, in order to protect fundamental rights, and promote innovation.
-
Is the national, legal infrastructure and security safeguards adequate to support localization requirements?
-
Are human rights, including privacy and freedom of expression online and offline, adequately protected and upheld in practice?
-
Do domestic surveillance regimes have adequate safeguards and checks and balances?
-
Does the private and public sector adhere to robust privacy and security standards and what should be the measure to ensure protection of data?
CONSIDERATIONS
-
What are the objectives of localization?
-
Innovation and Local ecosystem
-
The Srikrishna Committee Report specifically refers to the value in developing an indigenous Artificial Intelligence ecosystem. Much like the other AI strategies produced by the NITI Aayog and the Task Force set up by the Commerce Department, it states that AI can be a key driver in all areas of economic growth, and cites developments in China and the USA as instances of reference.
-
National Security, Law Enforcement and Protection from Foreign Surveillance
-
As recognised by the Srikrishna White Paper, a disproportionate amount of data belonging to Indian citizens is stored in the United States, and the presently existing Mutual Legal Assistance Treaties process (MLATs) through which Indian law enforcement authorities gain access to data stored in the US is excessively slow and cumbersome.
-
The Srikrishna Committee report also states that undersea cable networks that transmit data from one country to another are vulnerable to attack.
-
The report suggests that localisation might help protect Indian citizens against foreign surveillance.
-
What are the potential spill-overs and risks of a localisation mandate?
-
Diplomatic and political: Localisation could impact India’s trade relationships with its partners.
-
Security risks (“Regulatory stretching of the attack surface”): Storing data in multiple physical centres naturally increases the physical exposure to exploitation by individuals physically obtaining data or accessing the data remotely. So, the infrastructure needs to be backed up with robust security safeguards and significant costs to that effect.
-
Economic impact: Restrictions on cross-border data flow may harm overall economic growth by increasing compliance costs and entry barriers for foreign service providers and thereby reducing investment or passing on these costs to the consumers. The major compliance issue is the significant cost of setting up a data centre in India combined with the unsuitability of weather conditions. Further, for start-ups looking to attain global stature, reciprocal restrictions slapped by other countries may prevent access to the data in several other jurisdictions.
-
What are the existing alternatives to attain the same objectives?
The objective and potential alternatives are listed below:
|
OBJECTIVE |
ALTERNATE |
|
Law enforcement access to data |
Pursuing international consensus through negotiations rooted in international law |
|
Widening tax base by taxing entities that do not have an economic presence in India |
Equalisation levy/Taxing entities with a Significant Economic Presence in India (although an enforcement mechanism still needs to be considered). |
|
Threat to fibre-optic cables |
Building of strong defense alliances with partners to protect key choke points from adversaries and threats |
|
Boost to US based advertisement revenue driven companies like Facebook and Google (‘data colonisation’) |
Developing robust standards and paradigms of enforcement for competition law |
APPROACH
-
What data might be beneficial to store locally for ensuring national interest? What data could be mandated to stay within the borders of the country? What are the various models that can be adopted?
-
Mandatory Sectoral Localisation: Instead of imposing a generalized mandate, it may be more useful to first identify sectors or categories of data that may benefit most from local storage.
b. ‘Conditional (‘Soft’) Localisation: For all data not covered within the localisation mandate, India should look to develop conditional prerequisites for transfer of all kinds of data to any jurisdiction, like the Latin American countries, or the EU. This could be conditional on two key factors:
- Equivalent privacy and security safeguards: Transfers should only be allowed to countries which uphold the same standards. In order to do this, India must first develop and incorporate robust privacy and security protections.
-
Agreement to share data with law enforcement officials when needed: India should allow cross-border transfer only to countries that agree toshare data with Indian authorities based on standards set by Indian law.
Improving the Processes for Disclosing Security Vulnerabilities to Government Entities in India
The ubiquitous adoption and integration of information and communication technologies in almost all aspects of modern life raises with it the importance of being able to ensure the security and integrity of the systems and resources that we rely on. This importance is even more pressing for the Government, which is increasing its push of efforts towards digitising the operational infrastructure it relies on, both at the State as well as the Central level.
This policy brief draws from knowledge that has been gathered from various sources, including information sourced from newspaper and journal articles, current law and policy, as well as from interviews that we conducted with various members of the Indian security community. This policy brief touches upon the issue of vulnerability disclosures, specifically those that are made by individuals to the Government, while exploring prevalent challenges with the same and making recommendations as to how the Government’s vulnerability disclosure processes could potentially be improved.
Key learnings from the research include:
-
There is a noticeable shortcoming in the availability of information with regard to current vulnerability disclosure programmes and process of Indian Government entities, which is only exacerbated further by a lack of transparency;
-
There is an observable gap in the amount and quality of interaction between security researchers and the Government, which is supported by the lack of proper channels for mediating such communication and cooperation;
-
There are several sections and provisions within the Information Technology Act, 2000, which have the potential to disincentivise legitimate security research, even if the same has been carried out in good faith.
CIS Response to Draft E-Commerce Policy
Access our response to the draft policy here: Download (PDF)
The E-Commerce Policy is a much needed and timely document that seeks to enable the growth of India's digital ecosystem. Crucially, it backs up India's stance at the WTO, which has been a robust pushback against digital trade policies that would benefit the developed world at the cost of emerging economies. However, in order to ensure that the benefits of the digital economy are truly shared, focus must not only be on the sellers but also on the consumers, which automatically brings in individual rights into the question. No right is absolute but there needs to be a fair trade-off between the mercantilist aspirations of a burgeoning digital economy and the civil and political rights of the individuals who are spurring the economy on. We also appreciate the recognition that the regulation of e-commerce must be an inter-disciplinary effort and the assertion of the roles of various other departments and ministries. However, we also caution against over-reach and encroaching into policy domains that fall within the mandate of existing laws.
DIDP #33 On ICANN's 2012 gTLD round auction fund
In 2012, after years of deliberation ICANN opened the application round for new top level domains and saw over 1930 applications. Since October 2013, delegation of these extensions commenced with it still going on. However, 7 years since the round was open there has been no consensus on how to utilize the funds obtained from the auctions. ICANN until its last meeting was debating on the legal mechanisms/ entities to be created who will decide on the disbursement of these funds. There is no clear information on how those funds have been maintained over the years or its treatments in terms of whether they have been set aside or invested etc. Thus, our DIDP questions ICANN on the status of these funds and can be found here.
The response to the DIDP received on 24th April, 2019 states that that even though the request asked for information, rather than documentation, our question was answered. Reiterating that the DIDP mechanism was developed to provide documentation rather than information. It stated that on 25 October 2018, Resolution 2018.10.25.23 was passed that compels the President and CEO to allocate $36 million to the Reserve Fund. The gTLD auction proceeds were allocated to separate investment accounts, and the interest accruing from the proceedings was in accordance with the new gTLD Investment Policy.
CIS Response to Call for Stakeholder Comments: Draft E-Commerce Policy
The Department of Industrial Policy and Promotion released a draft e-commerce policy in February for which stakeholder comments were sought. CIS responded to the request for comments.
The full text can be accessed here.
To preserve freedoms online, amend the IT Act
In the absence of transparency, we have to rely on a mix of user reports and media reports that carry leaked government documents to get a glimpse into what websites the government is blocking(Getty Images)
The article by Gurshabad Grover was published in the Hindustan Times on April 16, 2019.
The issue of blocking of websites and online services in India has gained much deserved traction after internet users reported that popular services like Reddit and Telegram were inaccessible on certain Internet Service Providers (ISPs). The befuddlement of users calls for a look into the mechanisms that allow the government and ISPs to carry out online censorship without accountability.
Among other things, Section 69A of the Information Technology (IT) Act, which regulates takedown and blocking of online content, allows both government departments and courts to issue directions to ISPs to block websites. Since court orders are in the public domain, it is possible to know this set of blocked websites and URLs. However, the process is much more opaque when it comes to government orders.
The Information Technology (Procedure and Safeguards for Blocking for Access of Information by Public) Rules, 2009, issued under the Act, detail a process entirely driven through decisions made by executive-appointed officers. Although some scrutiny of such orders is required normally, it can be waived in cases of emergencies. The process does not require judicial sanction, and does not present an opportunity of a fair hearing to the website owner. Notably, the rules also mandate ISPs to maintain all such government requests as confidential, thus making the process and complete list of blocked websites unavailable to the general public.
In the absence of transparency, we have to rely on a mix of user reports and media reports that carry leaked government documents to get a glimpse into what websites the government is blocking. Civil society efforts to get the entire list of blocked websites have repeatedly failed. In response to the Right to Information (RTI) request filed by the Software Freedom Law Centre India in August 2017, the Ministry of Electronics and IT refused to provide the entire of list of blocked websites citing national security and public order, but only revealed the number of blocked websites: 11,422.
Unsurprisingly, ISPs do not share this information because of the confidentiality provision in the rules. A 2017 study by the Centre for Internet and Society (CIS) found all five ISPs surveyed refused to share information about website blocking requests. In July 2018, the Bharat Sanchar Nagam Limited rejected the RTI request by CIS which asked for the list of blocked websites.
The lack of transparency, clear guidelines, and a monitoring mechanism means that there are various forms of arbitrary behaviour by ISPs. First and most importantly, there is no way to ascertain whether a website block has legal backing through a government order because of the aforementioned confidentiality clause. Second, the rules define no technical method for the ISPs to follow to block the website. This results in some ISPs suppressing Domain Name System queries (which translate human-parseable addresses like ‘example.com’ to their network address, ‘93.184.216.34’), or using the Hypertext Transfer Protocol (HTTP) headers to block requests. Third, as has been made clear with recent user reports, users in different regions and telecom circles, but serviced by the same ISP, may be facing a different list of blocked websites. Fourth, when blocking orders are rescinded, there is no way to make sure that ISPs have unblocked the websites. These factors mean that two Indians can have wildly different experiences with online censorship.
Organisations like the Internet Freedom Foundation have also been pointing out how, if ISPs block websites in a non-transparent way (for example, when there is no information page mentioning a government order presented to users when they attempt to access a blocked website), it constitutes a violation of the net neutrality rules that ISPs are bound to since July 2018.
While the Supreme Court upheld the legality of the rules in 2015 in Shreya Singhal vs. Union of India, recent events highlight how the opaque processes can have arbitrary and unfair outcomes for users and website owners. The right to access to information and freedom of expression are essential to a liberal democratic order. To preserve these freedoms online, there is a need to amend the rules under the IT Act to replace the current regime with a transparent and fair process that makes the government accountable for its decisions that aim to censor speech on the internet.
CIS Response to ICANN's proposed renewal of .org Registry
Presumption of Renewal
CIS has, in the past, questioned the need for a presumption of renewal in registry contracts and it is important to emphasize this within the context of this comment as well. We had, also, asked ICANN for their rationale on having such a practice with reference to their contract with Verisign to which they responded saying:
“Absent countervailing reasons, there is little public benefit, and some significant potential for disruption, in regular changes of a registry operator. In addition, a significant chance of losing the right to operate the registry after a short period creates adverse incentives to favor short term gain over long term investment.”
This logic can presumably be applied to the .org registry, as well, yet a re-auction of ,even, legacy top-level domains can only serve to further a fair market, promote competition and ensure that existing registries do not become complacent.
These views were supported in the course of the PDP on Contractual Conditions - Existing Registries in 2006 wherein competition was seen useful for better pricing, operational performance and contributions to registry infrastructure. It was also noted that most service industries incorporate a presumption of competition as opposed to one of renewal.
Download the file to access our full response.
International Cooperation in Cybercrime: The Budapest Convention
Click to download the file here
However, the global nature of the internet challenges traditional methods of law enforcement by forcing states to cooperate with each other for a greater variety and number of cases than ever before in the past. The challenges associated with accessing data across borders in order to be able to fully investigate crimes which may otherwise have no international connection forces states to think of easier and more efficient ways of international cooperation in criminal investigations. One such mechanism for international cooperation is the Convention on Cybercrime adopted in Budapest (“Budapest Convention”). Drafted by the Council of Europe along with Canada, Japan, South Africa and the United States of America it is the first and one of the most important multilateral treaties addressing the issue of cybercrime and international cooperation.[1]
Extradition
Article 24 of the Budapest Convention deals with the issue of extradition of individuals for offences specified in Articles 2 to 11 of the Convention. Since the Convention allows Parties to prescribe different penalties for the contraventions contained in Articles 2-11, it specifies that extradition cannot be asked for unless the crime committed by the individual carries a maximum punishment of deprivation of liberty for atleast one year.[2] In order to not complicate issues for Parties which may already have extradition treaties in place, the Convention clearly mentions that in cases where such treaties exist, extradition will be subject to the conditions provided for in such extradition treaties.[3] Although extradition is also subject to the laws of the requested Party, if the laws provide for the existence of an extradition treaty, such a requirement shall be deemed to be satisfied by considering the Convention as the legal basis for the extradition.[4] The Convention also specifies that the offences mentioned in Articles 2 to 11 shall be deemed to be included in existing extradition treaties and Parties shall include them in future extradition treaties to be executed.[5]
The Convention also recognises the principle of "aut dedere aut judicare" (extradite or prosecute) and provides that if a Party refuses to extradite an offender solely on the basis that it shall not extradite their own citizens,[6] then, if so requested, such Party shall prosecute the offender for the offences alleged in the same manner as if the person had committed a similar offence in the requested Party itself.[7] The Convention also requires the Secretary General of the Council of Europe to maintain an updated register containing the authorities designated by each of the Parties for making or receiving requests for extradition or provisional arrest in the absence of a treaty.[8]
Mutual Assistance Requests
The Convention imposes an obligation upon the Parties to provide mutual assistance “to the widest extent possible” for investigations or proceedings of criminal offences related to computer systems and data.[9] Just as in the case of extradition, the mutual assistance to be provided is also subject to the conditions prescribed by the domestic law of the Parties as well as mutual assistance treaties between the Parties.[10] However, it is in cases where no mutual assistance treaties exist between the Parties that the Convention tries to fill the lacuna and provide for a mechanism for mutual assistance.
The Convention requires each Party to designate an authority for the purpose of sending and answering mutual assistance requests from other Parties as well as transmitting the same to the relevant authority in their home country. Similar to the case of authorities for extradition, the Secretary General is required to maintain an updated register of the central authorities designated by each Party.[11] Recognising the fact that admissibility of the evidence obtained through mutual assistance in the domestic courts of the requesting Party is a major concern, the Convention provides that the mutual assistance requests are to be executed in accordance with the procedures prescribed by the requesting Party unless such procedures are incompatible with the laws of the requested Party.[12]
Parties are allowed to refuse a request for mutual assistance on the grounds that (i) the domestic laws of the requested party do not allow it to carry out the request;[13] (ii) the request concerns an offence considered as a political offence by the requested Party;[14] or (iii) in the opinion of the requested Party such a request is likely to prejudice its sovereignty, security, ordre public or other essential interests.[15] The requested Party is also allowed to postpone any action on the request if it thinks that acting on the request would prejudice criminal investigations or proceedings by its own authorities.[16] In cases where assistance would be refused or postponed, the requested Party may consult with the other Party and consider whether partial or conditional assistance may be provided.[17]
In practice it has been found that though States refuse requests on a number of grounds,[18] some states even refuse cooperation in the event that the case is minor but requires an excessive burden on the requested state.[19] A case study of a true instance recounted below gives an idea of the effort and resources it may take for a requested state to carry out a mutual assistance request:
“In the beginning of 2005, a Norwegian citizen (let’s call him A.T.) attacked a bank in Oslo. He intended to steal money and he did so effectively. During his action, a police officer was killed. A.T. ran away and could not be found in Norway. Some days later, police found and searched his home and computer and discovered that A.T. was the owner of an email account from a provider in the United Kingdom. International co-operation was required from British authorities which asked the provider to put his email account under surveillance. One day, A.T. used his email account to send an email message. In the United Kingdom, police asked the ISP information about the IP address where the communication came from and it was found that it came from Spain.
British and Spanish authorities installed an alert system whose objective was to know, each time that A.T. used his email account, where he was. Thus, each time A.T. used his account, British police obtained the IP address of the computer in the origin of the communication and provided it immediately to Spanish police. Then, Spanish police asked the Spanish ISPs about the owner or user of the IP address. All the connexions were made from cybercafés in Madrid. Even proceeding to that area very quickly, during a long period of time it was not possible to arrive at those places before A.T. was gone.
Later, A.T. began to use his email account from a cybercafé in Malaga. This is a smaller town than Madrid and there it was possible to put all the cybercafés from a certain area permanently under physical surveillance. After some days of surveillance, British police announced that A.T. was online, using his email account, and provided the IP address. Very rapidly, the Spanish ISP informed Spanish police from the concrete location of the cybercafé what allowed the officers in the street to identify and arrest A.T. in place.
A.T. was extradited to Norway and prosecuted.”[20]
It is clear from the above that although the crime occurred in Norway, a lot of work was actually done by the authorities in the United Kingdom and Spain. In a serious case such as this where there was a bank robbery as well as a murder involved, the amount of effort expended by authorities from other states may be appropriate but it is unlikely that the authorities in Britain and Spain would have allocated such resources for a petty crime.
In sensitive cases where the requests have to be kept secret or confidential for any reason, the requesting Party has to specify that the request should be kept confidential except to the extent required to execute the request (such as disclosure in front of appropriate authorities to obtain the necessary permissions). In case confidentiality cannot be maintained the requested Party shall inform the requesting Party of this fact, which shall then take a decision regarding whether to withdraw the request or not.[21] On the other hand the requested Party may also make its supply of information conditional to it being kept confidential and that it not be used in proceedings or investigations other than those stated in the request.[22] If the requesting Party cannot comply with these conditions it shall inform the requested Party which will then decide whether to supply the information or not.[23]
In the normal course the Convention envisages requests being made and executed through the respective designated central authorities, however it also makes a provision, in urgent cases, for requests being made directly by the judicial authorities or even the Interpol.[24] Even in non urgent cases, if the authority of the requested Party is able to comply with the request without making use of coercive action, requests may be transmitted directly to the competent authority without the intervention of the central authority.[25]
The Convention clarifies that through these mutual assistance requests a Party may ask another to (i) either search, seize or disclose computer data within its territory,[26] (ii) provide real time collection of traffic data with specified communications in its territory;[27] and (iii) provide real time collection or recording of content data of specified communications.[28] The provision of mutual assistance specified above has to be in accordance with the domestic laws of the requested Party.
The procedure for sending mutual assistance requests under the Convention is usually the following:
- Preparation of a request for mutual assistance by the prosecutor or enforcement agency which is responsible for an investigation.
- Sending the request by the prosecutor or enforcement agency to the Central Authority for verification (and translation, if necessary).
- The Central Authority then submits the request either, (i) to the foreign central authority, or (ii) directly to the requested judicial authority.
The following procedure is then followed in the corresponding receiving Party:
- Receipt of the request by the Central Authority.
- Central Authority then examines the request against formal and legal requirements (and translates it, if necessary).
- Central Authority then transmits the request to the competent prosecutor or enforcement agency to obtain court order (if needed).
- Issuance of a court order (if needed).
- Prosecutor orders law enforcement (e.g. cybercrime unit) to obtain the requested data.
- Data obtained is examined against the MLA request, which may entail translation or
using a specialist in the language.
- The information is then transmitted to requesting State via MLA channels.[29]
In practice, the MLA process has generally been found to be inefficient and this inefficiency is even more pronounced with respect to electronic evidence. The general response times range from six months to two years and many requests (and consequently) investigations are often abandoned.[30] Further, the lack of awareness regarding procedure and applicable legislation of the requested State lead to formal requirements not being met. Requests are often incomplete or too broad; do not meet legal thresholds or the dual criminality requirement.[31]
Preservation Requests
The Budapest Convention recognises the fact that computer data is highly volatile and may be deleted, altered or moved, rendering it impossible to trace a crime to its perpetrator or destroying critical proof of guilt. The Convention therefore envisioned the concept of preservation orders which is a limited, provisional measure intended to take place much more rapidly than the execution of a traditional mutual assistance. Thus the Convention gives the Parties the legal ability to obtain the expeditious preservation of data stored in the territory of another (requested) Party, so that the data is not altered, removed or deleted during the time taken to prepare, transmit and execute a request for mutual assistance to obtain the data.
The Convention therefore provides that a Party may request another Party to obtain the expeditious preservation of specified computer data in respect of which such Party intends to submit a mutual assistance request. Once such a request is received the other Party has to take all appropriate measures to ensure compliance with such a request. The Convention also specifies that dual criminality is not a condition to comply with such requests for preservation of data since these are considered to be less intrusive than other measures such as seizure, etc.[32] However in cases where parties have a dual criminality requirement for providing mutual assistance they may refuse a preservation request on the ground that at the time of providing the data the dual criminality condition would not be met, although in regard to the offences covered under Articles 2 to 11 of the Convention, the requirement of dual criminality will be deemed to have been satisfied.[33] In addition to dual criminality a preservation request may also be refused on the grounds that (i) the offence alleged is a political offence; and (ii) execution of the request would likely to prejudice the sovereignty, security, ordre public or other essential interests of the requested Party.[34]
In case the requested Party feels that preservation will not ensure the future availability of the data or will otherwise prejudice the investigation, it shall promptly inform the requesting Party which shall then take a decision as to whether to ask for the preservation irrespective.[35] Preservation of the data pursuant to a request will be for a minimum period of 60 days and upon receipt of a mutual assistance request will continue to be preserved till a decision is taken on the mutual assistance request.[36] If the requested Party finds out in the course of executing the preservation request that the data has been transmitted through a third state or the requesting Party itself, it has a duty to inform the requesting Party of such facts as well as provide it with sufficient traffic data in order for it to be able to identify the service provider in the other state.[37]
Jurisdiction and Access to Stored Data
The problem of accessing data across international borders stems from the international law principle which provides that the authority to enforce (an action) on the territory of another State is permitted only if the latter provides consent for such behaviour. States that do not acquire such consent may therefore be acting contrary to the principle of non-intervention and may be in violation of the sovereignty of the other State.[38] The Convention specifies two situations in which a Party may access computer data stored in another Party’s jurisdiction; (i) when such data is publicly available; and (ii) when the Party has accessed such data located in another state through a computer system located in its own territory provided it has obtained the “lawful and voluntary consent of the person who has the lawful authority to disclose the data to the Party through that computer system”.[39] These are two fairly obvious situations where a state should be allowed to use the computer data without asking another state, infact if a state was required to take the permission of the state in the territory of which the data was physically located even in these situations, then it would likely delay a large number of regular investigations where the data would otherwise be available but could not be legally used unless the other country provided it under the terms of the Convention or some other legal instrument. At the time of drafting the Convention it appears that Parties could not agree upon any other situations where it would be universally acceptable for a state to unilaterally access data located in another state, however it must be noted that other situations for unilaterally accessing data are neither authorized, nor precluded.[40]
Since the language of the Budapest Convention stopped shy of addressing other situations law enforcement agencies had been engaged in unilateral access to data stored in other jurisdictions on an uncertain legal basis risking the privacy rights of individuals raising concerns regarding national sovereignty.[41] It was to address this problem that the Cybercrime Committee established the “ad-hoc sub-group of the T-CY on jurisdiction and transborder access to data and data flows” (the “Transborder Group”) in November 2011 which came out with a Guidance Note clarigying the legal position under Article 32.
The Guidance Note # 3 on Article 32 by the Cybercrime Committee specifies that Article 32(b) would not cover situations where the data is not stored in another Party or where it is uncertain where the data is located. A Party is also not allowed to use Article 32(b) to obtain disclosure of data that is stored domestically. Since the Convention neither authorizes nor precludes other situations, therefore if it is unknown or uncertain that data is stored in another Party, Parties may need to evaluate themselves the legitimacy of a search or other type of access in the light of domestic law, relevant international law principles or considerations of international relations.[42] The Budapest Convention does not require notification to the other Party but parties are free to notify the other Party if they deem it appropriate.[43] The “voluntary and lawful consent” of the person means that the consent must be obtained without force or deception. Giving consent in order to avoid or reduce criminal charges would also constitute lawful and voluntary consent. If cooperation in a criminal investigation requires explicit consent in a Party, this requirement would not be fulfilled by agreeing to the general terms and conditions of an online service, even if the terms and conditions indicate that data would be shared with criminal justice authorities.[44]
The person who is lawfully authorized to give consent is unlikely to include service providers with respect to their users’ data. This is because normally service providers would only be holders of the data, they would not own or control the data and therefore cannot give valid consent to share the data.[45] The Guidance Note also specifies that with respect to the location of the person providing access or consent, while the standard assumption is that the person would be physically located in the requesting Party however there may be other situations, “It is conceivable that the physical or legal person is located in the territory of the requesting law enforcement authority when agreeing to disclose or actually providing access, or only when agreeing to disclose but not when providing access, or the person is located in the country where the data is stored when agreeing to disclose and/or providing access. The person may also be physically located in a third country when agreeing to cooperate or when actually providing access. If the person is a legal person (such as a private sector entity), this person may be represented in the territory of the requesting law enforcement authority, the territory hosting the data or even a third country at the same time.” Parties are also required to take into account the fact that third Parties may object (and some even consider it a criminal offence) if a person physically located in their territory is directly approached by a foreign law enforcement authority to seek his or her cooperation.[46]
Production Order
A similar problem arises in case of Article 18 of the Convention which requires Parties to put in place procedural provisions to compel a person in their territory to provide specified stored computer data, or a service provider offering services in their territory to submit subscriber information.[47] It must be noted here, that the data in question must be already stored or existing data, which implies that this provision does not cover data that has not yet come into existence such as traffic data or content data related to future communications.[48] Since the term used in this provision is that the data must be within the “possession or control” of the person or the service provider, therefore this provision is also capable of being used to access data stored in the territory of a third party as long as the data is within the possession and control of the person on whom the Production Order has been served. In this regard it must be noted that the Article makes a distinction between computer data and subscriber information and specifies that computer data can only be asked for from a person (including a service provider) located within the territory of the ordering Party even if the data is stored in the territory of a third Party.[49] However subscriber information[50] can be ordered only from a service provider even if the service provider is not located within the territory of the ordering Party as long as it is offering its services in the territory of that Party and the subscriber information relates to the service offered in the ordering Party’s territory.[51]
Since the power under Article 18 is a domestic power which potentially can be used to access subscriber data located in another State, the use of this Article may raise complicated jurisdictional issues. This combined with the growth of cloud computing and remote data storage also raises concerns regarding privacy and data protection, the jurisdictional basis pertaining to services offered without the service provider being established in that territory, as well as access to data stored in foreign jurisdictions or in unknown or multiple locations “within the cloud”.[52] Even though some of these issues require further discussions and a more nuanced treatment, the Cybercrime Committee felt the need to issue a Guidance Note to Article 18 in order to avoid some of the confusion regarding the implementation of this provision.
Article 18(1)(b) may include a situation where a service provider is located in one jurisdiction, but stores the data in another jurisdiction. Data may also be mirrored in several jurisdictions or move between jurisdictions without the knowledge or control of the subscriber. In this regard the Guidance Note points out that legal regimes increasingly recognize that, both in the criminal justice sphere and in the privacy and data protection sphere, the location of the data is not the determining factor for establishing jurisdiction.[53]
The Guidance Note further tries to clarify the term “offering services in its territory” by saying that Parties may consider that a service provider is offering services if: (i) the service provider enables people in the territory of the Party to subscribe to its services (and does not, for example, block access to such services); and (ii) the service provider has established a real and substantial connection that Party. Relevant factors to determine whether such a connection has been established include “the extent to which a service provider orients its activities toward such subscribers (for example, by providing local advertising or advertising in the language of the territory of the Party), makes use of the subscriber information (or associated traffic data) in the course of its activities, interacts with subscribers in the Party, and may otherwise be considered established in the territory of a Party”.[54] A service provider will not be presumed to be offering services within the territory of a Party just because it uses a domain name or email address connected to that country.[55] The Guidance Note provides a very elegant tabular illustration of its requirements to serve a valid Production Order on a service provider:[56]
|
PRODUCTION ORDER CAN BE SERVED |
||
|
IF The criminal justice authority has jurisdiction over the offence |
||
|
AND The service provider is in possession or control of the subscriber information |
||
|
AND |
||
|
The service provider is in the territory of the Party (Article 18(1)(a)) |
Or |
A Party considers that a service provider is “offering its services in the territory of the Party” when, for example: - the service provider enables persons in the territory of the Party to subscribe to its services (and does not, for example, block access to such services); and - the service provider has established a real and substantial connection to a Party. Relevant factors include the extent to which a service provider orients its activities toward such subscribers (for example, by providing local advertising or advertising in the language of the territory of the Party), makes use of the subscriber information (or associated traffic data) in the course of its activities, interacts with subscribers in the Party, and may otherwise be considered established in the territory of a Party. (Article 18(1)(b)) |
|
AND |
||
|
|
the subscriber information to be submitted is relating to services of a provider offered in the territory of the Party. |
|
The existing processes for accessing data across international borders, whether through MLATs or through the mechanism established under the Budapest Convention are clearly too slow to be a satisfactory long term solution. It is precisely for that reason that the Cybercrime Committee has suggested alternatives to the existing mechanism such as granting access to data without consent in certain specific emergency situations;[57] or access to data stored in another country through a computer in its own territory provided the credentials for such access are obtained through lawful investigative activities.[58] Another option suggested by the Cybercrime Committee is to look beyond the principle of territoriality, specially in light of the recent developments in cloud computing where the location of the data may not be certain or data may be located in multiple locations,[59] and look at a connecting legal factor as an alternative such as the “power of disposal”. This option implies that even if the location of the data cannot be determined it can be connected to the person having the power to “alter, delete, suppress or render unusable as well as the right to exclude other from access and any usage whatsoever”.[60]
Language of Requests
It was found from practice that the question of the language in which the mutual assistance requests were made was a big issue in most States since it created problems such as delays due to translations, costly translations, quality of translations, etc. The Cybercrime Committee therefore suggested that an additional protocol be added to the Budapest Convention to stipulate that requests sent by Parties should be accepted in English atleast in urgent cases since most States accepted a request in English.[61] Due to these problems associated with the language of assistance requests, the Cybercrime Convention Committee has already released a provisional draft Additional Protocol to address the issue of language of mutual assistance requests for public comments.[62]
24/7 Network
Parties are required to designate a point of contact available on a twenty-four hour, seven-day-a week basis, in order to ensure the provision of immediate assistance for the purpose of investigations or proceedings concerning criminal offences related to computer systems and data, or for the collection of evidence, in electronic form, of a criminal offence. The point of contact for each Party is required to have the capacity to carry out communications with the points of contact for any other Party on an expedited basis. It is the duty of the Parties to ensure that trained and properly equipped personnel are available in order to facilitate the operation of the network.[63] The Parties recognized that establishment of this network is among the most important means provided by the Convention of ensuring that Parties can respond effectively to the law enforcement challenges posed by computer-or computer-related crimes.[64] In practice however it has been found that in a number of Parties there seems to be a disconnect between the 24/7 point of contact and the MLA request authorities leading to situations where the contact points may not be informed about whether preservation requests are followed up by MLA authorities or not.[65]
Drawbacks and Improvements
The Budapest Convention, whilst being the most comprehensive and widely accepted document on international cooperation in the field of cybercrime, has its own share of limitations and drawbacks. Some of the major limitations which can be gleaned from the discussion above (and potential recommendations for the same) are listed below:
Weakness and Delays in Mutual Assistance: In practice it has been found that though States refuse requests on a number of grounds,[66] some states even refuse cooperation in the event that the case is minor but requires an excessive burden on the requested state. Further, the delays associated with the mutual assistance process are another major hurdle, and are perhaps the reason by police-to-police cooperation for the sharing of data related to cybercrime and e-evidence is much more frequent than mutual legal assistance.[67] The lack of regulatory and legal awareness often leads to procedural lapses due to which requests do not meet legal thresholds. More training, more information on requirements to be met and standardised and multilingual templates for requests may be a useful tool to address this concern.
Access to data stored outside the territory: Access to data located in another country without consent of the authorities in that country poses another challenge. The age of cloud computing with processes of data duplication and delocalisation of data have added a new dimension to this problem.[68] It is precisely for that reason that the Cybercrime Committee has suggested alternatives to the existing mechanism such as granting access to data without consent in certain specific emergency situations;[69] or access to data stored in another country through a computer in its own territory provided the credentials for such access are obtained through lawful investigative activities.[70] Another option suggested by the Cybercrime Committee is to look beyond the principle of territoriality and look at a connecting legal factor as an alternative such as the “power of disposal”.
Language of requests: Language of requests create a number of problems such as delays due to translations, cost of translations, quality of translations, etc. Due to these problems, the Cybercrime Convention Committee has already released for public comment, a provisional draft Additional Protocol to address the issue.[71]
Bypassing of 24/7 points of contact: Although 24/7 points have been set up in most States, it has been found that there is often a disconnect between the 24/7 point of contact and the MLA request authorities leading to situations where the contact points may not be informed about whether preservation requests are followed up by MLA authorities or not.[72]
India and the Budapest Convention
Although countries outside the European Union have the option on signing the Budapest Convention and getting onboard the international cooperation mechanism envisaged therein, India has so far refrained from signing the Budapest Convention. The reasons for this refusal appear to be as follows:
- India did not participate in the drafting of the treaty and therefore should not sign. This concern, while valid is not a consistent foreign policy stand that India has taken for all treaties, since India has signed other treaties, where it had no hand in the initial drafting and negotiations.[73]
- Article 32(b) of the Budapest Convention involves tricky issues of national sovereignty since it allows for cross border access to data without the consent of the other party. Although, as discussed above, the Guidance Note on Article 32 clarified this issue to an extent, it appears that arguments have been raised in some quarters of the government that the options provided by Article 32 are too limited and additional means may be needed to deal with cross border data access.[74]
- The mutual legal assistance framework under the Convention is not effective enough and the promise of cooperation is not firm enough since States can refuse to cooperate on a number of grounds.[75]
- It is a criminal justice treaty and does not cover state actors; further the states from which most attacks affecting India are likely to emanate are not signatories to the Convention either.[76]
- Instead of joining the Budapest Convention, India should work for and promote a treaty at the UN level.[77]
Although in January 2018 there were a number of news reports indicating that India is seriously considering signing the Budapest Convention and joining the international cooperation mechanism under it, there have been no updates on the status of this proposal.[78]
Conclusion
The Budapest Convention has faced a number of challenges over the years as far as provisions regarding international cooperation are concerned. These include delays in getting responses from other states, requests not being responded to due to various reasons (language, costs, etc.), requests being overridden by mutual agreements, etc. The only other alternative which is the MLAT system is no better due to delays in providing access to requested data.[79] This however does not mean that international cooperation through the Budapest Convention is always late and inefficient, as was evident from the example of the Norwegian bank robber-murderer given above. There is no doubt that the current mechanisms are woefully inadequate to deal with the challenges of cyber crime and even regular crimes (specially in the financial sector) which may involve examination of electronic evidence. However that does not mean the end of the road for the Budapest Convention, one has to recognize the fact that it is the pre-eminent document on international cooperation on electronic evidence with 62 State Parties as well as another 10 Observer States. Any mechanism which offers a solution to the thorny issues of international cooperation in the field of cyber crime would require most of the nations of the world to sign up to it; till such time that happens, expanding the scope of the Budapest Convention to address atleast some of the issues discussed above by leveraging the work already done by the Cybercrime Committee through various reports and Guidance Notes (some of which have been referenced in this paper itself) may be a good option as this could be an incentive for non signatories to become parties to a better and more efficient Budapest Convention providing a more robust international cooperation regime.
[1] Council of Europe, Explanatory Report to the Convention on Cybercrime, https://rm.coe.int/16800cce5b, para 304.
[2] Council of Europe, Convention on Cybercrime, 23 November 2001, Article 24(1)(a). Except in cases where a different minimum threshold has been provided by a mutual arrangement, in which case such other minimum threshold shall be applied.
[3] Council of Europe, Convention on Cybercrime, 23 November 2001, Article 24(5).
[4] Council of Europe, Convention on Cybercrime, 23 November 2001, Article 24(3).
[5] Council of Europe, Convention on Cybercrime, 23 November 2001, Article 24(2).
[6] Council of Europe, Explanatory Report to the Convention on Cybercrime, Para 304, https://rm.coe.int/16800cce5b, para 251.
[7] Council of Europe, Convention on Cybercrime, 23 November 2001, Article 24(6).
[8] Council of Europe, Convention on Cybercrime, 23 November 2001, Article 24(7).
[9] Council of Europe, Convention on Cybercrime, 23 November 2001, Article 25(1).
[10] Council of Europe, Convention on Cybercrime, 23 November 2001, Article 25(4).
[11] Council of Europe, Convention on Cybercrime, 23 November 2001, Article 27(2).
[12] Council of Europe, Convention on Cybercrime, 23 November 2001, Article 27(3) read with para 267 of the Explanatory Note to the Budapest Convention.
[13] Council of Europe, Convention on Cybercrime, 23 November 2001, Article 25(4).
[14] Council of Europe, Convention on Cybercrime, 23 November 2001, Article 27(4)(a).
[15] Council of Europe, Convention on Cybercrime, 23 November 2001, Article 27(4)(b).
[16] Council of Europe, Convention on Cybercrime, 23 November 2001, Article 27(5).
[17] Council of Europe, Convention on Cybercrime, 23 November 2001, Article 27(6).
[18] Some of the grounds listed by Parties for refusal are: (i) grounds listed in Article 27 of the Convention, (ii) the request does not meet formal or other requirements, (iii) the request is motivated by race, religion, sexual orientation, political opinion or similar, (iv) the request concerns a political or military offence, (v) Cooperation may lead to torture or death penalty, (vi) Granting the request would prejudice sovereignty, security, public order or national interest or other essential interests, (vii) the person has already been punished or acquitted or pardoned for the same offence “Ne bis in idem”, (viii) the investigation would impose an excessive burden on the requested State or create practical difficulties, (ix) Granting the request would interfere in an ongoing investigation (in which case the execution of the request may be postponed). Council of Europe, Cybercrime Convention Committee assessment report: The mutual legal assistance provisions of the Budapest Convention on Cybercrime, December 2014, pg. 34.
[19] Council of Europe, Cybercrime Convention Committee assessment report: The mutual legal assistance provisions of the Budapest Convention on Cybercrime, December 2014, pg. 34.
[20] Pedro Verdelho, Discussion Paper: The effectiveness of international cooperation against cybercrime: examples of good practice, 2008, pg. 5, https://www.coe.int/t/dg1/legalcooperation/economiccrime/cybercrime/T-CY/DOC-567study4-Version7_en.PDF, accessed on March 28, 2019.
[21] Council of Europe, Convention on Cybercrime, 23 November 2001, Article 27(8).
[22] However, disclosure of the material to the defence and the judicial authorities is an implicit exception to this rule. Further the ability to use the material in a trial (which is generally a public proceeding) is also a recognised exception to the right to limit usage of the material. See para 278 of the the Explanatory Note to the Budapest Convention.
[23] Council of Europe, Convention on Cybercrime, 23 November 2001, Article 28.
[24] Council of Europe, Convention on Cybercrime, 23 November 2001, Article 27(9)(a) and (b).
[25] Council of Europe, Convention on Cybercrime, 23 November 2001, Article 27(9)(d) read with para 274 of the Explanatory Note to the Budapest Convention.
[26] Council of Europe, Convention on Cybercrime, 23 November 2001, Article 31.
[27] Council of Europe, Convention on Cybercrime, 23 November 2001, Article 33.
[28] Council of Europe, Convention on Cybercrime, 23 November 2001, Article 34.
[29] Council of Europe, Cybercrime Convention Committee assessment report: The mutual legal assistance provisions of the Budapest Convention on Cybercrime, December 2014, pg. 37.
[30] Council of Europe, Cybercrime Convention Committee assessment report: The mutual legal assistance provisions of the Budapest Convention on Cybercrime, December 2014, pg. 123.
[31] Ibid at 124.
[32] Council of Europe, Convention on Cybercrime, 23 November 2001, Article 29(3) read with para 285 of the Explanatory Note to the Budapest Convention.
[33] Council of Europe, Convention on Cybercrime, 23 November 2001, Article 29(4).
[34] Council of Europe, Convention on Cybercrime, 23 November 2001, Article 29(5).
[35] Council of Europe, Convention on Cybercrime, 23 November 2001, Article 29(6).
[36] Council of Europe, Convention on Cybercrime, 23 November 2001, Article 29(7).
[37] Council of Europe, Convention on Cybercrime, 23 November 2001, Article 30.
[38] Anna-Maria Osula, Accessing Extraterritorially Located Data: Options for States, http://ccdcoe.eu/uploads/2018/10/Accessing-extraterritorially-located-data-options-for-States_Anna-Maria_Osula.pdf, accessed on March 28, 2019.
[39] Council of Europe, Convention on Cybercrime, 23 November 2001, Article 32.
[40] Council of Europe, Explanatory Report to the Convention on Cybercrime, Para 304, https://rm.coe.int/16800cce5b, para 293.
[41] Council of Europe, Cybercrime Convention Committee, Report of the Transborder Group, Transborder access and jurisdiction: What are the options?, December 2012, para 310.
[42] Council of Europe, Cybercrime Convention Committee Guidance Note # 3, Transborder access to data (Article 32), para 3.2.
[43] Council of Europe, Cybercrime Convention Committee Guidance Note # 3, Transborder access to data (Article 32), para 3.3.
[44] Council of Europe, Cybercrime Convention Committee Guidance Note # 3, Transborder access to data (Article 32), para 3.4.
[45] Council of Europe, Cybercrime Convention Committee Guidance Note # 3, Transborder access to data (Article 32), para 3.6.
[46] Council of Europe, Cybercrime Convention Committee Guidance Note # 3, Transborder access to data (Article 32), para 3.8.
[47] Council of Europe, Convention on Cybercrime, 23 November 2001, Article 18.
[48] Council of Europe, Explanatory Report to the Convention on Cybercrime, Para 304, https://rm.coe.int/16800cce5b, para 170.
[49] Council of Europe, Explanatory Report to the Convention on Cybercrime, Para 304, https://rm.coe.int/16800cce5b, para 173.
[50] Defined in Article 18(3) as “any information contained in the form of computer data or any other form that is held by a service provider, relating to subscribers of its services other than traffic or content data and by which can be established:
a. the type of communication service used, the technical provisions taken thereto and the period of service;
b. the subscriber’s identity, postal or geographic address, telephone and other access number, billing and payment information, available on the basis of the service agreement or arrangement;
c. any other information on the site of the installation of communication equipment, available on the basis of the service agreement or arrangement.
[51] Council of Europe, Explanatory Report to the Convention on Cybercrime, Para 304, https://rm.coe.int/16800cce5b, para 173.
[52] Council of Europe, Cybercrime Convention Committee Guidance Note #10, Production orders for subscriber information (Article 18 Budapest Convention), at pg.3.
[53] Council of Europe, Cybercrime Convention Committee Guidance Note #10, Production orders for subscriber information (Article 18 Budapest Convention), para 3.5 at pg. 7.
[54] Council of Europe, Cybercrime Convention Committee Guidance Note #10, Production orders for subscriber information (Article 18 Budapest Convention), para 3.6 at pg. 8.
[55] Id.
[56] Council of Europe, Cybercrime Convention Committee Guidance Note #10, Production orders for subscriber information (Article 18 Budapest Convention), para 3.8 at pg. 9.
[57] Situations such as preventions of imminent danger, physical harm, the escape of a suspect or similar situations including risk of destruction of relevant evidence.
[58] Council of Europe, Cybercrime Convention Committee, Subgroup on Transborder Access, (Draft) Elements of an Additional Protocol to the Budapest Convention on Cybercrime Regarding Transborder Access to Data, April 2013, pg. 49.
[59] Council of Europe, Cybercrime Convention Committee Cloud Evidence Group, Criminal justice access to data in the cloud: challenges (Discussion paper), May 2015, pgs 10-14.
[60] Council of Europe, Cybercrime Convention Committee, Subgroup on Transborder Access, (Draft) Elements of an Additional Protocol to the Budapest Convention on Cybercrime Regarding Transborder Access to Data, April 9, 2013, pg. 50.
[61] Council of Europe, Cybercrime Convention Committee assessment report: The mutual legal assistance provisions of the Budapest Convention on Cybercrime, December 2014, pg. 35.
[62] https://www.coe.int/en/web/cybercrime/-/towards-a-protocol-to-the-budapest-convention-further-consultatio-1
[63] Council of Europe, Convention on Cybercrime, 23 November 2001, Article 35.
[64] Council of Europe, Explanatory Report to the Convention on Cybercrime, Para 304, https://rm.coe.int/16800cce5b, para 298.
[65] Council of Europe, Cybercrime Convention Committee assessment report: The mutual legal assistance provisions of the Budapest Convention on Cybercrime, December 2014, pg. 86.
[66] Some of the grounds listed by Parties for refusal are: (i) grounds listed in Article 27 of the Convention, (ii) the request does not meet formal or other requirements, (iii) the request is motivated by race, religion, sexual orientation, political opinion or similar, (iv) the request concerns a political or military offence, (v) Cooperation may lead to torture or death penalty, (vi) Granting the request would prejudice sovereignty, security, public order or national interest or other essential interests, (vii) the person has already been punished or acquitted or pardoned for the same offence “Ne bis in idem”, (viii) the investigation would impose an excessive burden on the requested State or create practical difficulties, (ix) Granting the request would interfere in an ongoing investigation (in which case the execution of the request may be postponed). Council of Europe, Cybercrime Convention Committee assessment report: The mutual legal assistance provisions of the Budapest Convention on Cybercrime, December 2014, pg. 34.
[67] Council of Europe, Cybercrime Convention Committee assessment report: The mutual legal assistance provisions of the Budapest Convention on Cybercrime, December 2014, pg. 7.
[68] Giovanni Buttarelli, Fundamental Legal Principles for a Balanced Approach, Selected papers and contributions from the International Conference on “Cybercrime: Global Phenomenon and its Challenges”, Courmayeur Mont Blanc, Italy available at ispac.cnpds.org/download.php?fld=pub_files&f=ispacottobre2012bassa.pdf
[69] Situations such as preventions of imminent danger, physical harm, the escape of a suspect or similar situations including risk of destruction of relevant evidence.
[70] Council of Europe, Cybercrime Convention Committee, Subgroup on Transborder Access, (Draft) Elements of an Additional Protocol to the Budapest Convention on Cybercrime Regarding Transborder Access to Data, April 2013, pg. 49.
[71] https://www.coe.int/en/web/cybercrime/-/towards-a-protocol-to-the-budapest-convention-further-consultatio-1
[72] Council of Europe, Cybercrime Convention Committee assessment report: The mutual legal assistance provisions of the Budapest Convention on Cybercrime, December 2014, pg. 86.
[73] Dr. Anja Kovaks, India and the Budapest Convention - To Sign or not? Considerations for Indian Stakeholders, available at https://internetdemocracy.in/reports/india-and-the-budapest-convention-to-sign-or-not-considerations-for-indian-stakeholders/
[74] Alexander Seger, India and the Budapest Convention: Why not?, Digital Debates: The CyFy Journal, Vol III, available at https://www.orfonline.org/expert-speak/india-and-the-budapest-convention-why-not/
[75] Id.
[76] Id.
[77] Id.
[78] https://indianexpress.com/article/india/home-ministry-pitches-for-budapest-convention-on-cyber-security-rajnath-singh-5029314/
[79] Elonnai Hickok and Vipul Kharbanda, Cross Border Cooperation on Criminal Matters - A perspective from India, available at https://cis-india.org/internet-governance/blog/cross-border-cooperation-on-criminal-matters
FinTech in India: A Study of Privacy and Security Commitments
Access the full report: Download (PDF)
The report by Aayush Rathi and Shweta Mohandas was edited by Elonnai Hickok. Privacy policy testing was done by Anupriya Nair and visualisations were done by Saumyaa Naidu. The project is supported by the William and Flora Hewlett Foundation.
In India, the Information Technology (Reasonable Security Practices and Procedures and Sensitive Personal Data or Information) Rules, 2011 (subsequently referred to as SPD/I Rules) framed under the Information Technology Act, 2000 make privacy policies a ubiquitous feature of websites and mobile applications of firms operating in India. Privacy policies are drafted in order to allow consumers to make an informed choice about the privacy commitments being made vis-à-vis their information, and is often the sole document that lays down a companies’ privacy and security practices.In India, the Information Technology (Reasonable Security Practices andProcedures and Sensitive Personal Data or Information) Rules, 2011 (subsequently referred to as SPD/I Rules) framed under the Information Technology Act, 2000 make privacy policies a ubiquitous feature of websites and mobile applications of firms operating in India. Privacy policies are drafted in order to allow consumers to make an informed choice about the privacy commitments being made vis-à-vis their information, and is often the sole document that lays down a companies’ privacy and security practices.
The objective of this study is to understand privacy commitments undertaken by fintech companies operating in India as documented in their public facing privacy policies. This exercise will be useful to understand what standards of privacy and security protection fintech companies are committing to via their organisational privacy policies. The research will do so by aiming to understand the alignment of the privacy policies with the requirements mandated under the SPD/I Rules. Contingent on the learnings from this exercise, trends observed in fintech companies’ privacy and security commitments will be culled out.
How privacy fares in the 2019 election manifestos | Opinion
The article by Aayush Rathi and Ambika Tandon was published in the Hindustan Times on May 1, 2019.
In August 2017, the Supreme Court, in Puttaswamy vs Union of India, unanimously recognised privacy as a fundamental right guaranteed by the Constitution. Before the historic judgment, the right to privacy had remained contested and was determined on a case-by-case basis. By understanding privacy as the preservation of individual dignity and autonomy, the judgment laid the groundwork to accommodate subsequent landmark legislative moves — varying from decriminalising homosexuality to limiting the use of the Aadhaar by private actors.
Reflecting the importance gained by privacy within public imagination, the 2019 elections are the first time it finds mention across major party manifestos. In 2014, the Communist Party of India (Marxist) was the only political party to have made commitments to safeguarding privacy, albeit in a limited fashion. For the 2019 election, both the Congress and the CPI(M) promise to protect the right to privacy if elected to power. The Congress promises to “pass a law to protect the personal data of all persons and uphold the right to privacy”. However, it primarily focuses on informational privacy and its application to data protection, limited to the right of citizens to control access and use of information about themselves.
The CPI(M) focuses on privacy more broadly while promising to protect against “intrusion into the fundamental right to privacy of every Indian”. In a similar vein, both the Congress and the CPI(M) also commit to bringing about surveillance reform by incorporating layers of oversight. The CPI(M) manifesto further promises to support the curtailment of mass surveillance globally. It promises to enact a data privacy law to protect against “appropriation/misuse of private data for commercial use”, albeit without any reference to misuse by government agencies.
On the other hand, the Samajwadi Party manifesto proposes the reintroduction of the controversial NATGRID, an overarching surveillance tool proposed by the Congress in the aftermath of the 26/11 Mumbai attacks. In this backdrop, digital rights for individuals are conspicuous by their absence from the Bharatiya Janata Party’s manifesto. Data protection is only seen in a limited sense as being required in conjunction with increasing digital financialisation.
The favourable articulation of privacy in some of the manifestos should be read along with other commitments across parties around achieving development goals through the digital economy. Central to the operation of this is aggregating citizen data. Utilising this aggregated data for predictive abilities is key to initiatives being proposed in the manifestos —digitising health records, a focus on sunrise technologies, such as machine learning and big data, and readiness for “Industry 5.0” are some examples.
The right is then operationalised in a manner that leads data subjects to pick between their privacy and accessing services being provided by the data collector. Relinquishing privacy becomes the only option especially when access to welfare services is at stake.
The discourse around privacy in India has historically been used to restrict individual freedoms. In the Puttaswamy case, Justice DY Chandrachud, in his plurality opinion, acknowledges feminist scholarship to broaden the understanding of the right to privacy to one that protects bodily integrity and decisional privacy for marginalised communities. This implies protection against any manner of State interference with decisions regarding the self, and, more broadly, the right to create a private space to allow the personality to develop without interference. This includes protection from undue violations of bodily integrity such as protecting the freedom to use public spaces without fear of harassment, and criminalising marital rape.
While the articulation of privacy in the manifestos is a good start, it should be much more. Governance must implement the right to look beyond the individualised conception of privacy so as to allow it to support a whole range of freedoms, rather than limiting it to data protection. This could take the shape of modifying traditional legal codes. Family law, for instance, could be reshaped to allow for greater exercise of agency by women in marriage, guardianship, succession etc. Criminal law, too, could render inadmissible evidence obtained through unjustified privacy violations. The manifestos do mark the entry of a rights-based language around privacy and bodily integrity into mainstream political discourse. However, there appears to be a lack of imagination of the extent to which these protections can be used to further individual liberty collectively.
Why the TikTok ban is worrying
The article by Gurshabad Grover was published in Hindustan Times on May 2, 2019.
In a span of less than two weeks, the Madras High Court has imposed and lifted a ban on the TikTok mobile application, an increasingly popular video and social platform. While rescinding the ban is welcome, the events tell a worrying tale of how the courts can arbitrarily censor online expression with little accountability.
On April 3, the Madras High Court heard a public interest litigation petitioning for the TikTok mobile app to be banned in India because it was “encouraging pornography”, “degrading culture”, “causing paedophiles”, spreading “explicit disturbing content” and causing health problems for teenagers. It is difficult to establish the truth of these extreme claims about content on the platform that has user generated content, but the court was confident enough to pass wide ranging interim orders on the same day without hearing ByteDance, the company that operates the Tik Tok app.
The interim order had three directives. First, the Madras High Court ordered the government to prohibit the downloading of the app. Second, it restricted the media from broadcasting videos made using the app. Third, it asked the government to respond about whether it plans to enact legislation that would protect children’s online privacy. While the third directive poses an important question to the government that merits a larger discussion, the first two completely lacked a legal rationale. The court order also implied that the availability of pornography on the platform was problematic, even though it is not illegal to access pornography in India.
Appallingly, the order makes no mention at all of the most pertinent legal provision: Section 79 of the Information Technology (IT) Act and the rules issued under it, which form the liability regime applicable to intermediaries (online services). The intermediary liability rules in India generally shield online platforms from liability for the content uploaded to their platform as long as the company operating is primarily involved in transmitting the content, complies with government and court orders, and is not abetting illegal activity. It is this regime that has ensured that online platforms are not hyperactively censoring expression to avoid liability, and has directly supported the proliferation of speech online.
The courts do have some powers of online censorship under the provision, which they have used many times in the past. They have the authority to decide on questions of whether certain content violates law and then direct intermediaries to disable access to that specific content. Such a legal scenario was certainly not the case before the Madras High Court. We can also be sure that the app stores run by Apple and Google, on which TikTok is available, were not the intermediaries under consideration here (which would also be problematic in its own ways) since the interim order makes no mention of them. So, despite the fact that the court’s order had no clear jurisdiction and legal basis, Apple and Google were ordered by the government to remove TikTok from their respective mobile app stores for India.
ByteDance Technology appealed to the Supreme Court of India to rescind the ban, arguing that they qualify as intermediaries under the IT Act and should not face a blanket ban as a repercussion of allegedly problematic content on their platform. The Supreme Court refrained from staying the problematic Madras High Court interim order, but decided that the ban on the app will be lifted by April 24 if the case wasn’t decided by then. On April 24, sense finally prevailed when the High Court decided to take the interim directive back.
Admittedly, popular online platforms can create certain social problems. TikTok has faced bans elsewhere and was fined by the Federal Trade Commission in the United Sates for collecting information on its users who were below the age of 13. There is no debate that the company is legally bound to follow the rules issued under the IT Act, be responsive to legally valid government and court orders, and should strictly enforce their community guidelines that aim to create a safe environment for the young demographic that forms a part of its user base. However, a ban is a disproportionate move that sends signals of regulatory uncertainty, especially for technology companies trying to break into an increasingly consolidated market. The failure of the government to enact a law that protects children’s privacy also cannot be considered a legitimate ground for a ban on a mobile app.
Perhaps most importantly, the interim court order adds yet another example to the increasing number of times the judiciary has responded to petitions by passing censorship orders that have no basis in law. As constitutional scholar Gautam Bhatia has pointed out, we are faced with the trend of “judicial censorship” wherein the judiciary is exercising power without accountability in ways not envisioned by the Constitution. Rather than critically examining the infringement of liberties by the political executive, the Indian courts are becoming an additional threat to the right to freedom of expression, which we must be increasingly wary of.
An Analysis of the RBI’s Draft Framework on Regulatory Sandbox for Fintech
Click here to download the file.
It originated as a term referring to the back-end technology used by large financial institutions, but has expanded to include technological innovation in the financial sector, including innovations in financial literacy and education, retail banking, investments, etc. Entities engaged in FinTech offer an array of services ranging from peer-to-peer lending platforms and mobile payment solutions to online portfolio management tools and international money transfers.
Regulation and supervision of the Fintech industry raises some unique challenges for regulatory authorities as they have to strike a balance between financial inclusion, stability, integrity, consumer protection, and competition. One of the methods that have been adopted by regulators in certain jurisdictions to tackle the complexities of this sector is to establish a “regulatory sandbox” which could nurture innovative fintech enterprises while at the same time ensuring that the risk associated with any regulatory relaxations is contained within specified boundaries. It was precisely for this reason that establishment of a regulatory sandbox was one of the options put forward by the Working Group on Fintech and Digital Banking established by the Reserve Bank of India in its report of November, 2017 which was released for public comments on February 8, 2018. Acting on this recommendation the Reserve Bank has proposed a Draft Enabling Framework for Regulatory Sandbox, dated April 18, 2019, (“RBI Framework”) which is analysed and discussed below.
Regulatory Sandbox and its benefits
While the basic concept of a regulatory sandbox is to ensure that there is regulatory encouragement and incentive for fledgling Fintech enterprises in a contained environment to mitigate risks, different regulatory authorities have adopted varied methods of achieving this objective. While the Australian Securities and Exchange Commission (ASIC) uses a method where the eligible enterprises notify the ASIC and commence testing without an individual application process, the Financial Conduct Authority, UK (FCA) uses a cohort approach wherein eligible enterprises have to apply to the FCA which then selects the best options based on criteria laid down in the policy. The RBI has, not surprisingly, adopted an approach similar to the FCA wherein applicants will be selected by the RBI based on pre-defined eligibility criterion and start the regulatory sandbox in cohorts containing a few entities at a time.
A regulatory sandbox offers the users the opportunity to test the product’s viability without a larger and more expensive roll out involving heavy investment and regulatory authorizations. If the product appears to have the potential to be successful, it might then be authorized and brought to the broader market more quickly. If there are any problems with the product the limited nature of the sandbox ensures that the consequences of the problems are contained and do not affect the broader market. It also allows regulators to obtain first-hand empirical evidence on the benefits and risks of emerging technologies and business models, and their implications, which allows them to take a considered (and perhaps more nuanced) view on the regulatory requirements that may be needed to support useful innovation, while mitigating the attendant risks. A regulatory sandbox initiative also sends a clear signal to the market that innovation is on the agenda of the regulator.
RBI Draft Framework
Since the RBI has adopted a cohort approach for its regulatory sandbox process (“RS”), it implies that fintech entities will have to apply to the RBI to be selected in the RS. The eligibility criterion provides that the applicants will have to meet the eligibility conditions prescribed by the government for start-ups as per the Government of India, Department of Industrial Policy and Promotion, Notification GSR 364(E) April 11, 2018. The RS will focus on areas where (i) there is an absence of regulations, (ii) regulations need to be eased to encourage innovation, and (iii) the innovation/product shows promise of easing/effecting delivery of financial services in a significant way. The Framework also provides an indicative list of innovative products and technologies which could be considered for RS testing, and at the same time prohibits certain products and technologies from being considered for this programme such as credit registry, crypto currencies, ICOs, etc.
The RBI Framework also lays down specific conditions that the entity has to satisfy in order to be considered for the RS such as satisfaction of the conditions to be considered a start-up, minimum net worth requirements, fit and proper criteria for Directors and Promoters, satisfactory conduct of bank accounts of promoters/directors, satisfactory credit score, technological readiness of the product for deployment in the broader market, ensuring compliance with existing laws and regulations on consumer data and privacy, adequate safeguards in its IT systems for protection against unauthorised access etc. and a robust IT infrastructure and managerial resources. The fit and proper criteria for Directors and Promoters which requires elements of credit history along with the minimum net worth requirements in the RBI Framework are conditions which may be too difficult for some of the smaller and newer start-ups to satisfy even though the technology and products they offer might be sound. The applicants are also required to: (i) highlight an existing gap in the financial ecosystem and how they intend to address that, (ii) show a regulatory barrier or gap that prevents the implementation of the solution on a large scale, (iii) clearly define the test scenarios, expected outcomes, boundary conditions, exit or transition strategy, assessment and mitigation of risks, etc.
The RBI Framework specifies that the focus of the RS should be narrow in terms of areas of innovation and limited in terms of intake. While limits on the number of entities per cohort may be justified based on paucity of resources, limiting the focus of the RS by narrow areas of innovation is a lost opportunity in terms of sharing of ideas and learning from the mistakes of their colleagues who may be employing technologies and principles which could be useful in fields other than those where they are currently being applied.
The RBI Framework specifies that the boundaries of the RS have to be well defined so that any consequences of failure can be contained. These boundary conditions include a specific start and end date, target customer type and limits on number of customers, cash holdings, transaction amounts and customer losses. The Framework does not put in place any hard numbers on the boundary conditions which ensures that the RS process can be customised to the needs of specific entities since the sample sizes and data needed to determine the viability of fintech entities and products may vary from product to product. However a major dampener is the hard limit of 12 weeks imposed on the testing phase of the RS, which is the most important phase since all the data from the operations is generated during this phase and 12 weeks may not be enough time to generate enough reliable data so as to reach a determination of the viability of the product.
Although the RBI has shown a willingness to relax regulatory requirements for RS participants on a case to case basis, it has specified that there shall be no relaxation on issues of customer privacy and data protection, security of payment data, transaction security, KYC requirements and statutory restrictions. Since this is only an initiative by the RBI the RS participants dealing with the insurance or securities sector would not be entitled to any relaxations from the IRDA or the SEBI even if they are found eligible for relaxations from RBI regulations. This would severely limit the efficacy of the RS process and is an issue that could have been addressed if all three regulators had collaborated thereby encouraging innovative start-ups offering a broader spectrum of services.
Once the RS is finished, the regulatory relaxations provided by the RBI will expire and the fintech entity will have to either stop operations or comply with the relevant regulations. In case the entity requires an extension of the RS period, it would apply to the RBI atleast one month prior to the expiry of the RS period with reasons for the extension. The RBI also has the option of prematurely terminating the sandbox process in case the entity does not achieve its intended purpose or if it cannot comply with the regulatory requirements and other conditions specified at the relevant stage of the sandbox process. The fintech entity is also entitled to quit the RS process prematurely by giving one week’s notice to the RBI, provided it ensures that all its existing obligations to its customers are fully addressed before such discontinuance. Infact customer obligations have to be met by the fintech entities irrespective of whether the operations are prematurely ended by the entity or it continues through the entire RS process; no waiver of the legal liability towards consumers is provided by the RS process. In addition, customers are required to be notified upfront about the potential risks and their explicit consent is to be taken in this regard.
The RBI Framework itself lists out some of the risks associated with the regulatory sandbox model such as (i) loss of flexibility in going through the RS process, (ii) case by case determinations involve time and discretional judgements, (iii) no legal waivers, (iv) requirement of regulatory approvals after the RS process is over, (iv) legal issues such as consumer complaints, challenges from rejected candidates, etc. While acknowledging the above risks the Framework also mentions that atleast some of them may be mitigated by following a time bound and transparent process thus reducing risks of arbitrary discretion and loss of flexibility.
Conclusions
While there are some who are sceptical of the entire concept of a regulatory sandbox for the reason that it loosens regulation too much while at the same time putting customers at risk, the cohort model adopted by the RBI would reduce that risk to an extent since it ensures comprehensive screening and supervision by the RBI with clear exit strategies and an emphasis on consumer interests. On the other hand the eligibility criterion for applicants prescribes minimum net worth requirements as well as credit history, etc. which may impose conditions too onerous for some start ups which may be their infancy. Further the clear emphasis on protection of customer privacy and consumer interests also ensures that the RBI will not put the interests of ordinary citizens at risk in order to promote new and untested technologies. That said, the regulatory sandbox process is a welcome initiative by the RBI which may send a signal to the financial community that it is aware of the potential advantages as well as risks of Fintech and is willing to play a proactive role in encouraging new technologies to improve the financial sector in India.
Report of Working Group on Fintech and Digital Banking, Reserve Bank of India, November, 2017, available at https://www.rbi.org.in/Scripts/PublicationReportDetails.aspx?UrlPage=&ID=892
Jenik, Ivo, and Kate Lauer. 2017. “Regulatory Sandboxes and Financial Inclusion.” Working Paper. Washington, D.C.: CGAP, available at https://www.cgap.org/sites/default/files/Working-Paper-Regulatory-Sandboxes-Oct-2017.pdf
Other countries which have regulatory sandboxes are Netherlands, Bahrain, Abu Dhabi, Saudi Arabia, etc.
Report of Working Group on Fintech and Digital Banking, Reserve Bank of India, November, 2017, available at https://www.rbi.org.in/Scripts/PublicationReportDetails.aspx?UrlPage=&ID=892
Jenik, Ivo, and Kate Lauer. 2017. “Regulatory Sandboxes and Financial Inclusion.” Working Paper. Washington, D.C.: CGAP, available at https://www.cgap.org/sites/default/files/Working-Paper-Regulatory-Sandboxes-Oct-2017.pdf
These conditions are fairly liberal in that they require that the entity should be less than 7 years old; should not have a turnover of more than 25 crores, and should be working for innovation, development or improvement of products or processes or services, or if it is a scalable business model with a high potential of employment generation or wealth creation.
Clause 5 of the RBI Framework.
Clause 6.1 of the RBI Framework.
Clause 6.3 of the RBI Framework.
Clause 6.5 of the RBI Framework.
Clause 6.4 of the RBI Framework.
Clause 6.7 of the RBI Framework.
Clauses 6.2 and 8 of the RBI Framework.
Clause 6.6 of the RBI Framework.
Clause 6.9 of the RBI Framework.
Jemima Kelly, A “fintech sandbox” might sound like a harmless idea. It's not, Financial Times, Aplphaville, https://ftalphaville.ft.com/2018/12/05/1543986004000/A--fintech-sandbox--might-sound-like-a-harmless-idea--It-s-not/
Will the WTO Finally Tackle the ‘Trump’ Card of National Security?
The article by Arindrajit Basu was published in the Wire on May 8, 2019.
From stonewalling appointments at the appellate body of the WTO’s dispute settlement body (DSB) to slapping exorbitant steel and aluminium tariffs on a variety of countries, Trump has attempted to desecrate an institution that he views as being historically unfair to America’s national interests.
Given this potentially cataclysmic state of affairs, a WTO panel report adopted last month regarding a transport restriction dispute between the Russia and Ukraine would ordinarily have attracted limited attention. In reality, this widely celebrated ruling was the first instance of the WTO mechanism mounting a substantive legal resistance to Trump’s blitzkrieg.
The opportunity arose from the Russian Federation’s invocation of the ‘national security exception’ carved into the Article XXI of the General Agreement on Tariffs and Trade (GATT-the primary WTO covered agreement dealing with trade in goods.)
This clause has rarely been invoked by a litigating party at the DSB and never been interpreted by the panel or appellate body due to the belief among WTO member states that the exception is ‘self-judging’ i.e. beyond the purview of WTO jurisdiction sovereign prerogative to use as they see fit.
Over the past couple of years, the provision has taken on a new avatar with trade restrictions being increasingly used as a strategic tool to accomplish national security objectives. In addition to the Russian Federation, in this case, it was used by the UAE to justify sanctions against Qatar in 2017and notably by the US administration in response to the commencement of WTO proceedings by nine countries (including India) against its steel and aluminum tariffs.
India itself has also cited the clause in its diplomatic statements when justifying revocation of the Most Favoured Nation Status to Pakistan, although this has not yet resulted in proceedings at the WTO.
Even though the panel held in favour of Russia, this report lays down the edifice for dismantling the Trump Administration’s present strategy. By explicitly stating that Article XXI is not entirely beyond review of the WTO, the panel report gives a cause de celebre for all countries attempting to legally battle Trump’s arbitrary protectionist cause disguised as genuine national security concerns.
At the same time, it might act as a source of comfort for Huawei and China as it allows them to challenge the legality of banning Huawei (as some countries have chosen to do) at the WTO.
History of Article XXI
Article XXI had an uncertain presence in the legal architecture of the WTO from its very inception. It had its origins in the US proposal to establish the International Trade Organisation. The members of the delegation themselves were divided between those who wanted to preserve the sovereign right of the United States to interpret the extent of the exception as it saw fit and others who felt that this provision would be abused to further arbitrary protectionism. The delegate of Australia was also skeptical about the possible exclusion of dispute resolution through a mere invocation of the security exception.
Given this divergence, the drafters of the provision thus sought to create a specific set of exceptions in order to arrive at a compromise that “would take care of real security interests” while limiting “the exception so as to prevent the adoption of protection for maintaining industries under every conceivable circumstances”.
To attain that objective, the provision in the ITO Charter, which was reflected in Article XXI of GATT 1947 was worded thus:
Nothing in this Agreement shall be construed
to require any contracting party to furnish any information the disclosure of which it considers contrary to its essential security interests;
or to prevent any contracting party from taking any action which it considers necessary for the protection of its essential security interests (i) relating to fissionable materials or the materials from which they are derived; (ii) relating to the traffic in arms, ammunition and implements of war and to such traffic in other goods and materials as is carried on directly or indirectly for the purpose of supplying a military establishment; (iii) taken in time of war or other emergency in international relations; or
to prevent any contracting party from taking any action in pursuance of its obligations under the United Nations Charter for the maintenance of international peace and security
Article XXI has been historically invoked in cases where national security is devised as a smokescreen for protectionism. For example, in 1975, Sweden cited Article XXI to justify global import restrictions it had had slapped on certain types of footwear. It argued that a decrease in domestic production of said kinds of footwear represented ” a critical threat to the emergency planning of its economic defense.” There was sustained criticism from some states, who questioned Sweden’s juxtaposition of a national security threat with economic strife, claiming that they too were suffering from severe unemployment at the time and the Swedish restrictions would be devastating for their economic position.
The Swedish problem dissipated when Sweden withdrew the restrictions but the uncertain peril of Article XXI remained.
In another instance, the US themselves had previously relied on the security exception to justify measures prohibiting all imports of goods and services of Nicaraguan origin to the US in addition to all U.S. exports to Nicaragua.It argued that Article XXI was self-judging and each party could enact measures it considered necessary for the protection of its essential security interests. In fact, it was successful in keeping its Article XXI invocation outside the terms of reference (which establishes the scope of the Panel’s report), which precluded the Panel from asserting its jurisdiction and examining the provision. It is worth noting, though, that the Panel was critical of the US for utilising the provision in this case and emphasised the need for balancing this exception against the need to preserve the stability of global trade.
The recent spate of national security driven justifications to subvert the adjudicatory powers of the WTO provided a necessary opportunity for the panel to clarify its stance on this issue.
The findings of the panel
The findings of the panel can be divided into three broad clusters:
1) The WTO tribunals’ jurisdiction over the security exception: Right from the outset, the panel clearly stated that it had jurisdiction to adjudicate the matter at hand. It rebutted Russia’s claim that any country invoking the exception had unfettered discretion in the matter
2) The ambit of the self-judging nature of the security clause: Both the Russian Federation and the United States, which had filed a third party submission, re-emphasised the supposed self-judging nature of the security clause due to the incorporation of the words “ which it[the WTO member] considers necessary for the protection of its essential security interests” in clause (2) of the provision.
However, the panel argued that the sub-paragraphs (i)-(iii) require an objective review by the Panel to determine whether the state of affairs indicated in the sub-paragraphs do, in fact, exist. In this way, the Panel added,the three sub-clauses act as “limiting qualifying clauses.” The determination of the measures that may be ‘necessary’ for protecting their ‘essential security interests’ are then left to each WTO member. By interpreting the clause in this manner,the Panel deftly preserved the sovereign autonomy of member states while preventing the bestowing of carte blanche’ ability to take shelter behind the provision.
3) Determination of emergency in international relations: The use of the term “other emergency in international relations” as used in the provision is an amorphous one because the term ‘emergency’ is not clearly defined in international law. Therefore, the Panel relied on UN General Assembly Resolutions and the fact that multiple states had imposed sanctions on Russia to conclude that there was, in fact, an ‘emergency’ in international relations in this case. In doing so, the Panel upheld the transport restrictions imposed by Russia. However, the implications extend far beyond the immediate impact on the two parties.
Implications of the ruling
Before considering the implications of this report, we must consider that, like in other avenues of international law, the municipal legal principle of stare decisis does not apply to Panel or Appellate Body decisions. This means that future panels are not bound by law to follow the finding in this report.
However, WTO tribunals have often used the reasoning put forward in previous panel or Appellate Body reports to support their findings.
Steel and aluminium tariffs
The US, whose third party submission failed to sway the panel has recognised the potential implications of the report and disparaged it as being “seriously flawed”. They have also discouraged the WTO tribunals deciding the steel and aluminium tariff disputes from using it as precedent.
However, Australia, Brazil, Canada, China, European Union, Japan, Moldova, Singapore and Turkey had all filed third party submissions which encouraged the panel to assert its jurisdiction in the matter and have openly supported the panel’s approach – which would be a boost for the panels set up to adjudicate the Trump sanctions.
Given the groundwork laid out by the panel in this dispute, it would be difficult for the US to satisfy the panel’s understanding of ‘emergency in international relations’ as the Panel clearly stated that “political or economic differences between Members are not sufficient, of themselves, to constitute an emergency in international relations for purposes of subparagraph (iii)”.
Huawei and cybersecurity
In addition to steel and aluminium tariffs, the panel’s decision also has an impact on the rapidly unfolding Huawei saga. Huawei, which is the world’s largest telecom equipment company and is now taken the lead in the race to develop one of the world’s most critical emerging technologies: fifth generation mobile telephony.
However, Huawei has recently fallen out of favour with the US and other western countries amidst suspicions of them enabling the Chinese government to spy on other countries by incorporating backdoors into their infrastructure.
Various countries, including Australia, Japan, New Zealand have effectively banned Huawei from public participation while the US has prevented government agencies from buying Huawei infrastructure-triggering litigation by Huawei seeking to prevent the move.India has adopted an independent approach by allowing Huawei to participate in field trials of 5G equipment despite Indian agencies flagging concerns over the use of Chinese made telecom equipment.
On April 11, China complained about the Australian decision at the formal meeting of the WTO’s Council for Trade in Goods by highlighting its discriminatory impact on China. To defend itself, Australia may need to invoke Article XXI and argue that the ban fits in under one of the sub-paragraphs (i)-(iii) of clause (2) The report by this panel, may, therefore propel the WTO’s first big foray into cybersecurity and enable it to act as a multi-lateral adjudicator of the critical geo-political issues discussed in this piece.
The history of international law has been a history of powerful nations manipulating its tenets for strategic gain. At the same time, it has been a history of institutional resilience, evolution and change. The World Trade Organisation is no exception. Despite several aspects of the WTO ecosystem being severely flawed with a disparate impact on vulnerable groups in weaker nations, it has been the bulwark of the modern geo-economic order.
By taking the ‘national security’ exception head on, the panel has undertaken a brave act of self-preservation and foiled the utilisation of a dangerous trump card.
RTI Application to BSNL for the list of websites blocked in India
Background
The Government of India draws powers from Section 69A of the Information Technology (IT) Act and the rules issued under it to order Internet Service Providers (ISPs) to block websites and URLs for users. Several experts have questioned the constitutionality of the process laid out in the Information Technology (Procedure and Safeguards for Blocking for Access of Information by Public) Rules, 2009 (hereinafter, “the rules”) [1] since Rule 16 in the regulations allows blocking of websites by the Government and ISPs in secrecy, as it mandates all such orders to be maintained confidentially.
Thus, the law sets up a structure where it is impossible to know the complete list of websites blocked in India and the reasons thereof. Civil society and individual efforts have repeatedly failed to obtain this list. For instance, the Software Freedom Law Centre (SFLC), in August 2017, asked the Ministry of Electronics and Information Technology (MeitY) for the number and list of websites and URLs that are blocked in India. In response, MeitY revealed the number of blocked websites and URLs: 11,422. MeitY refused to share the list of websites blocked by Government orders citing the aforementioned confidentiality provision in the rules (and subsequently citing national security when MeitY’s reply was appealed against by SFLC). In 2017, researchers at the Centre for Internet and Society (CIS) contacted five ISPs, all of which refused to share information about website blocking requests.
Application under the Right to Information (RTI) Act
To
Manohar Lal, DGM(Cordn), Bharat Sanchar Nigam Limited
Room No. 306, Bharat Sanchar Bhawan, H.C.Mathur Lane
Janpath, New Delhi, PIN 110001
Subject: Seeking of Information under RTI Act 2005
Sir,
Kindly arrange to provide the following information under the provisions of RTI Act:
- What are the names and URLs of websites currently blocked by government notification in India?
- Please provide copies of blocking orders issued by the Department of Telecommunications, Ministry of Communications and other competent authorities to block such websites.
Thanking you
Yours faithfully
Akash Sriram
Centre for Internet and Society
The Information sought vide above reference cannot be disclosed vide clause 8(e) and 8(g) of the RTI act which states.
"8(e) - Information, available to a person in his fiduciary relationship, unless the competent authority is satisfied that the larger public interest warrants the disclosure of such information"
“8(g) - Information, the disclosure of which would endanger the life or physical safety of any person or identify the source of information or assistance given in confidence for law enforcement or security purposes"
This is issued with the approval of competent authority.
Workshop on Feminist Information Infrastructure
A group of five researchers, one from Blank Noise and four from Sangama, presented their research on different aspects of feminist infrastructure. The workshop was attended by a diverse group of participants, including activists, academics, and representatives from civil society organisations and trade unions.
Feminist infrastructure is a broadly conceptualised term referring to infrastructure that is designed by, and keeping in mind the needs of, diverse social groups with different kinds of marginality. In the field of technology, efforts to conceptualise feminist infrastructure have ranged from rethinking basic technological infrastructure, such as feminist spectrum , to community networks and tools for mobilisation . This project aimed to explore the imagination of feminist infrastructure in the context of different marginalities and lived experiences. Rather than limiting intersectionality to the subject of the research, as with most other feminist projects, this project aimed to produce knowledge from the ‘standpoint’ of those with the lived experience of marginalisation.
This report by Ambika Tandon was edited by Gurshabad Grover and designed by Saumyaa Naidu. The full report can be downloaded here.
Announcement of a Three-Region Research Alliance on the Appropriate Use of Digital Identity
As governments across the globe are implementing new, digital foundational identification systems or modernizing existing ID programs, there is a dire need for greater research and discussion about appropriate design choices for a digital identity framework. There is significant momentum on digital ID, especially after the adoption of UN Sustainable Development Goal 16.9, which calls for legal identity for all by 2030. Given the importance of this subject, its implications for both the development agenda as well its impact on civil, social and economic rights, there is a need for more focused research that can enable policymakers to take better decisions, guide civil society in different jurisdictions to comment on and raise questions about digital identity schemes, and provide actionable material to the industry to create identity solutions that are privacy enhancing and inclusive.
Excerpt from the blog post by Subhashish Bhadra announcing this new research alliance
...In the absence of any widely-accepted thinking on this issue, we run the risk of digital identity systems suffering from mission creep, that is being made mandatory or being used for an ever-expanding set of services. We believe this creates several risks. First, people may be excluded from services if they do not have a digital identity or because it malfunctions. Second, this approach creates a wider digital footprint that can be used to create a profile of an individual, sometimes without consent. This can increase privacy risk. Third, this approach increases the power of institutions versus individuals and can be used as rationale to intentionally deny services, especially to vulnerable or persecuted groups.
Three exceptional research groups have undertaken the effort of answering this complex and important question. Over the next six months, these think tanks will conduct independent research, as well as involve experts from across the globe. Based in South America, Africa, and Asia, these institutions represent the collective wisdom and experiences of three very distinct geographies in emerging markets. While drawing on their local context, this research effort is globally oriented. The think tanks will create a set of recommendations and tools that can be used by stakeholders to engage with digital identity systems in any part of the world...
This research will use a collaborative and iterative process. The researchers will put out some ideas every few weeks, with the objective of seeking thoughts, questions, and feedback from various stakeholders. They will participate in several digital rights and identity events across the globe over the next several months. They will also organize webinars to seek input from and present their interim findings to interested communities from across the globe. Each of these provide an opportunity for you to provide your thoughts and help this research program provide an independent, rigorous, transparent, and holistic answer to the question of when it’s appropriate for digital identity to be used. We need a diversity of viewpoints and collaborative dissent to help solve the most pressing issues of our times.
Picking ‘Wholes’ - Thinking in Systems Workshop
It was organised as part of the Digital Identity project to explore the use of system’s thinking approach in a digital identity system, and addressing questions of policy choices and uses, while creating such a system. The workshop was attended by Amber Sinha, Ambika Tandon, Anubha Sinha, Pooja Saxena, Radhika Radhakrishnan, Saumyaa Naidu, Shruti Trikanad, Shyam Ponappa, Sumandro Chattapadhyay, Sunil Abraham, Swati Gautam, and Yesha Paul.
Dinesh Korjan is a proponent of the strategic use of design for the larger good. He is a product designer and co-founder of Studio Korjan in Ahmedabad. He complements his practice with active engagement in academics and teaches at many leading design schools including NID, Ahmedabad, Indian Institute of Technology (IIT), Gandhinagar, Srishti School of Art Design & Technology, Bangalore, and CEPT University, Ahmedabad.
The masterclass was aimed at learning to address complex problems using systems thinking approach. It involved experiential and collaborative learning through discussions, and doing and making activities. The workshop began with identifying different actors, processes, institutions, and other entities involved in a complex problem. The method of role-playing was introduced to learn to detail out and map the problem. Concepts such as synergy/ emergence, relationships, and flows were introduced through examples and case studies. These concepts were applied while mapping complex problems to find insights such as patterns, purposes, feedback loops, and finally a leverage. The workshop also introduced the idea of ephemeralization. Participants were prompted to find solutions that require least input but have greatest impact.
For further reading click here
The Impact of Consolidation in the Internet Economy on the Evolution of the Internet
Edited by Swaraj Barooah, Elonnai Hickok and Vishnu Ramachandran. Inputs by Swagam Dasgupta
This report is a summary of the proceedings of the roundtables organized by the Centre for Internet and Society in partnership with the Internet Society on the impact of consolidation in the Internet economy. It was conducted under the Chatham House Rule, at The Energy and Resource Institute, Bangalore on the 29 June 2018 from 11AM to 4PM. This report was authored on 29 June 2018, and subsequently edited for readability on 25 June 2019. This report contributed to the Internet Society’s 2019 Global Internet Report on Consolidation in the Internet Economy.
The roundtables aimed to analyze how growing forces of consolidation, including concentration, vertical and horizontal integration, and barriers to market entry and competition would influence the Internet in the next 3 to 5 years.
To provide for sufficient investigation, the discussions were divided across two sessions. The focus of the first group was the impact of consolidation on applicable regulatory andpolicy norms including regulation of internet services, the potential to secure or undermine people’s ability to choose services, and the overall impact on the political economy. Thesecond discussion delved into the effect of consolidation on the technical evolution of the internet (in terms of standards, tools and software practices) and consumer choices (interms of standards of privacy, security, other human rights).
The sessions had participants from the private sector (2), research (4), government (1), technical community (3) and civil society organizations (6). Five women and eleven men constituted the participant list.
DIDP #34 On granular detail on ICANN's budget for policy development process
The ICANN budgets are published for public comment yet the community does not have supporting documents to illustrate how the numbers were estimated or the rationale for allocation of the resources. There is a lack of transparency when it comes to the internal budgeting.
This DIDP is concerned with the policy development budget which, as Stephanie Perrin of the Non-Commercial Stakeholder Group pointed out, was merely 5% of ICANN’s total budget, a number significantly low for a policy making organization. Thus, the information we request is a detailed breakdown for the budgets for every Advisory Council as well as Supporting Organizations for the previous fiscal year. You can find the attached request here.
Old Isn't Always Gold: FaceApp and Its Privacy Policies
The article by Mira Swaminathan and Shweta Reddy was published in the Wire on July 20, 2019.
If you, much like a large number of celebrities, have spammed your followers with the images of ‘how you may look in your old age’, you have successfully been a part of the FaceApp fad that has gone viral this week.
The problem with the FaceApp trend isn’t that it has penetrated most social circles, but rather, the fact that it has gone viral with minimal scrutiny of its vaguely worded privacy policy guidelines. We click ‘I agree’ without understanding that our so called ‘explicit consent’ gives the app permission to use our likeness, name and username, for any purpose, without our knowledge and consent, even after we delete the app. FaceApp is currently the most downloaded free app on the Apple Store due to a large number of people downloading the app to ‘turn their old selfies grey’.
There are many things that the app could do. It could process the images on your device, rather than take submitted photos to an outside server. It could also upload your photos to the cloud without making it clear to you that processing is not taking place locally on their device.
Further, if you have an Apple product, the iOS app appears to be overriding your settings even if you have denied access to their camera roll. People have reported that they could still select and upload a photo despite the app not having permission to access their photos. This ‘allowed behaviour’ in iOS is quite concerning, especially when we have apps with loosely worded terms and conditions.
FaceApp responded to these privacy concerns by issuing a statement with a list of defences. The statement clarified that FaceApp performs most of the photo processing in the cloud, that they only upload a photo selected by a user for editing and also confirmed that they never transfer any other images from the phone to the cloud. However, even in their clarificatory statement, they stated that they ‘might’ store an uploaded photo in the cloud and explained that the main reason for that is “performance and traffic”. They also stated that ‘most’ images are deleted from their servers within 48 hours from the upload date.
Further, the statement ends by saying that “all pictures from the gallery are uploaded to our servers after a user grants access to the photos”. This is highly problematic.
We have explained the concerns arising out of the privacy policy with reference to the global gold standards: the OECD Guidelines on the Protection of Privacy and Transborder Flows of Personal Data, APEC Privacy Framework, Report of the Group of Experts on Privacy chaired by Justice A.P. Shah and the General Data Protection Regulation in the table below:
| Privacy Domain | OECD Guidelines | APEC Privacy Framework | Report of the Group of Experts on Privacy | General Data Protection Regulation | FaceApp Privacy Policy |
| Transparency | There should be a general policy of openness about developments, practices and policies with respect to personal data. | Personal information controllers should provide clear and easily accessible statements about their practices and policies with respect to personal data. | A data controller shall give a notice that is understood simply of its information practices to all individuals, in clear and concise language, before any personal information is collected from them. | Transparency:
The controller shall take appropriate measures to provide information relating to processing to the data subject in a concise, transparent, intelligible and easily accessible form, using clear and plain language. Article 29 working party guidelines on Transparency: The information should be concrete and definitive, it should not be phrased in abstract or ambivalent terms or leave room for different interpretations. Example: “We may use your personal data to develop new services” (as it is unclear what the services are or how the data will help develop them); |
Information we collect
“When you visit the Service, we may use cookies and similar technologies”……. provide features to you. We may ask advertisers or other partners to serve ads or services to your devices, which may use cookies or similar technologies placed by us or the third party. “We may also collect similar information from emails sent to our Users..” Sharing your information “We may share User Content and your information with businesses…” “We also may share your information as well as information from tools like cookies, log files..” “We may also combine your information with other information..” |
| A simple reading of the guidelines in comparison with the privacy policy of FaceApp can help us understand that the terms used by the latter are ambiguous and vague. The possibility of a ‘may not’ can have a huge impact on the privacy concerns of the user.
The entire point of ‘transparency’ in a privacy policy is for the user to understand the extent of processing undertaken by the organisation and then have the choice to provide consent. Vague phrases do not adequately provide a clear indication of the extent of processing of personal data of the individual. |
|||||
| Privacy Domain | OECD Guidelines | APEC Privacy Framework | Report of the Group of Experts on Privacy | General Data Protection Regulation | FaceApp Privacy Policy |
| Security Safeguards | Personal data should be protected by reasonable security safeguards against such risks as loss or unauthorised access, destruction, use, modification or disclosure of data | Personal information controllers should protect personal information that they hold with appropriate safeguards against risks, such as loss or unauthorised access to personal information or unauthorised destruction, use, modification or disclosure of information or other misuses. | A data controller shall secure personal information that they have either collected or have in their custody by reasonable security safeguards against loss, unauthorised access, destruction, use, processing, storage, modification, deanonymization, unauthorised disclosure or other reasonably foreseeable risks | The controller and processor shall implement appropriate technical and organisational measures to ensure a level of security appropriate to the risk. | How we store your information
“We use commercially reasonable safeguards to help keep the information collected through the Service secure and take reasonable steps… However, FaceApp cannot ensure the security of any information you transmit to FaceApp or guarantee that information on the Service may not be accessed, disclosed, altered, or destroyed.” |
The obligation of implementing reasonable security measures to prevent unauthorised access and misuse of personal data is placed on the organisations processing such data. FaceApp’s privacy policy assures that reasonable security measures according to commercially accepted standards have been implemented. Despite such assurances, FaceApp’s waiver of the liability by stating that it cannot ensure the security of the information against it being accessed, disclosed, altered or destroyed itself says that the policy is faltered in nature.
The privacy concerns and the issue of transparency (or the lack thereof) in FaceApp are not isolated. After all, as a Buzzfeed analysis of the app noted, while there appeared to be no data going back to Russia, this could change at any time due to its overly broad privacy policy.
The business model of most mobile applications being developed currently relies heavily on personal data collection of the user. The users’ awareness regarding the type of information accessed based on the permissions granted to the mobile application is questionable.
In May 2018, Symantec tested the top 100 free Android and iOS apps with the primary aim of identifying cases where the apps were requesting ‘excessive’ access to information of the user in relation to the functions being performed. The study identified that 89% of Android apps and 39% of the iOS app request for what can be classified as ‘risky’ permissions, which the study defines as permissions where the app requests data or resources which involve the user’s private information, or, could potentially affect the user’s locally stored data or the operation of other apps.
Requesting risky permissions may not on its own be objectionable, provided clear and transparent information regarding the processing, which takes place upon granting permission, is provided to the individuals in the form of a clear and concise privacy notice. The study concluded that 4% of the Android apps and 3% of the iOS apps seeking risky permissions didn’t even have a privacy policy.
The lack of clarity with respect to potentially sensitive user data being siphoned off by mobile applications became even more apparent with the case of a Hyderabad based fintech company that gained access to sensitive user data by embedding a backdoor inside popular apps.
In the case of the Hyderabad-based fintech company, the user data which was affected included GPS locations, business SMS text messages from e-commerce websites and banks, personal contacts, etc. This data was used to power the company’s self-learning algorithms which helped organisations determine the creditworthiness of loan applicants. It is pertinent to note that even when apps have privacy policies, users can still find it difficult to navigate through the long content-heavy documents.
The New York Times, as part of its Privacy Project, analysed the length and readability of privacy policies of around 150 popular websites and apps. It was concluded that the vast majority of the privacy policies that were analysed exceeded the college reading level. Usage of vague language like “adequate performance” and “legitimate interest” and wide interpretation of such phrases allows organisations to use data in extensive ways while providing limited clarity on the processing activity to the individuals.
The Data Protection Authorities operating under the General Data Protection Regulation are paying close attention to openness and transparency of processing activities by organisations. The French Data Protection Authority fined Google for violating their obligations of transparency and information. The UK’s Information Commissioner’s office issued an enforcement notice to a Canadian data analytics firm for failing to provide information in a transparent manner to the data subject.
Thus, in the age of digital transformation, the unwelcome panic caused by FaceApp should be channelled towards a broader discussion on the information paradox currently existing between individuals and organisations. Organisations need to stop viewing ambiguous and opaque privacy policies as a get-out-of-jail-free card. On the contrary, a clear and concise privacy policy outlining the details related to processing activity in simple language can go a long way in gaining consumer trust.
The next time an “AI-based Selfie App” goes viral, let’s take a step back and analyse how it makes use of user-provided data and information both over and under the hood, since if data is the new gold, we can easily say that we’re in the midst of a gold rush.
What is the problem with ‘Ethical AI’? An Indian Perspective
The article by Arindrajit Basu and Pranav M.B. was published by cyberBRICS on July 17, 2019.
This was followed by the G20 adopted human-centred AI Principles on June 9th. These are the latest in a slew of (at least 32!) public, and private ‘Ethical AI’ initiatives that seek to use ethics to guide the development, deployment and use of AI in a variety of use cases. They were conceived as a response to a range of concerns around algorithmic decision-making, including discrimination, privacy, and transparency in the decision-making process.
In India, a noteworthy recent document that attempts to address these concerns is the National Strategy for Artificial Intelligence published by the National Institution for Transforming India, also called NITI Aayog, in June 2018. As the NITI Aayog Discussion paper acknowledges, India is the fastest growing economy with the second largest population in the world and has a significant stake in understanding and taking advantage of the AI revolution. For these reasons the goal pursued by the strategy is to establish the National Program on AI, with a view to guiding the research and development in new and emerging technologies, while addressing questions on ethics, privacy and security.
While such initiatives and policy measures are critical to promulgating discourse and focussing awareness on the broad socio-economic impacts of AI, we fear that they are dangerously conflating tenets of existing legal principles and frameworks, such as human rights and constitutional law, with ethical principles – thereby diluting the scope of the former. While we agree that ethics and law can co-exist, ‘Ethical AI’ principles are often drafted in a manner that posits as voluntary positive obligations various actors have taken upon themselves as opposed to legal codes they necessarily have to comply with.
To have optimal impact, ‘Ethical AI’ should serve as a decision-making framework only in specific instances when human rights and constitutional law do not provide a ready and available answer.
Vague and unactionable
Conceptually, ‘Ethical AI’ is a vague set of principles that are often difficult to define objectively. In this perspective, academics like Brett Mittelstadt of the Oxford Internet Institute argues that unlike in the field of medicine – where ethics has been used to design a professional code, ethics in AI suffers from four core flaws. First, developers lack a common aim or fiduciary duty to a consumer, which in the case of medicine is the health and well-being of the patient. Their primary duty lies to the company or institution that pays their bills, which often prevents them from realizing the extent of the moral obligation they owe to the consumer.
The second is a lack of professional history which can help clarify the contours of well-defined norms of ‘good behaviour.’ In medicine, ethical principles can be applied to specific contexts by considering what similarly placed medical practitioners did in analogous past scenarios. Given the relative nascent emergence of AI solutions, similar professional codes are yet to develop.
Third is the absence of workable methods or sustained discourse on how these principles may be translated into practice. Fourth, and we believe most importantly, in addition to ethical codes, medicine is governed by a robust and stringent legal framework and strict legal and accountability mechanisms, which are absent in the case of ‘Ethical AI’. This absence gives both developers and policy-makers large room for manoeuvre.
However, such focus on ethics may be a means of avoiding government regulation and the arm of the law. Indeed, due to its inherent flexibility and non-binding nature, ethics can be exploited as a piecemeal red herring solution to the problems posed by AI. Controllers of AI development are often profit-driven private entities, that gain reputational mileage by using the opportunity to extensively deliberate on broad ethical notions.
Under the guise of meaningful ‘self-regulation’, several organisations publish internal ‘Ethical AI’ guidelines and principles, and fund ethics research across the globe. In doing so, they occlude the shackles of binding obligation and deflect from attempts at tangible regulation.
Comparing Law to Ethics
This is in contrast to the well-defined jurisprudence that human rights and constitutional law offer, which should serve as the edifice of data-driven decision making in any context.
In the table below, we try to explain this point by looking at how three core fundamental rights enshrined both in our constitution and human rights instruments across the globe-right to privacy, right to equality/right against discrimination and due process-find themselves captured in three different sets of ‘Ethical AI frameworks.’ One of these inter-governmental (OECD), one devised by a private sector actor (‘Google AI’) and one by our very own, NITI AAYOG.
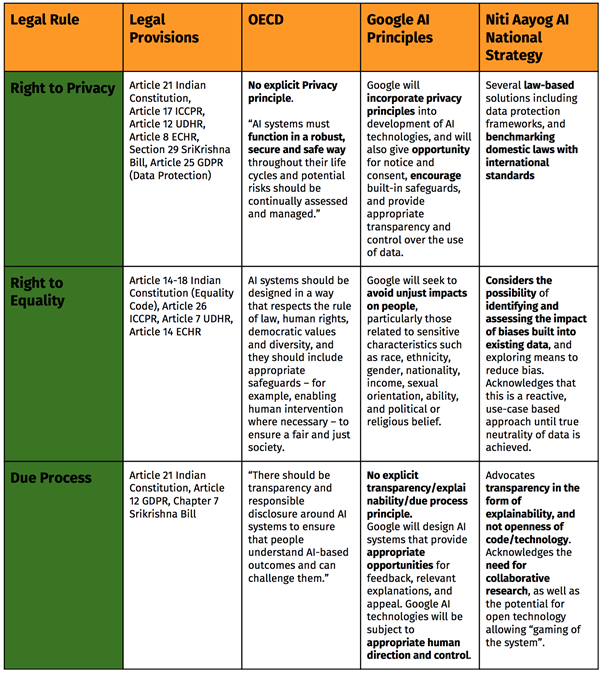
With the exception of certain principles,most ‘Ethical AI’ principles are loosely worded as ‘‘seek to avoid’, ‘give opportunity for’, or ‘encourage’. A notable exception is the NITI AAYOG’s approach to protecting privacy in the context of AI. The document explicitly recommends the establishment of a national data protection framework for data protection, sectoral regulations that apply to specific contexts with the consideration of international standards such as GDPR as benchmarks. However, it fails to reference available constitutional standards when it discusses bias or explainability.
Several similar legal rules that have been enshrined in legal provisions -outlined and elucidated through years of case law and academic discourse – can be utilised to underscore and guide AI principles. However, existing AI principles do not adequately articulate how the legal rule can actually be applied to various scenarios by multiple organisations.
We do not need a new “Law of Artificial Intelligence” to regulate this space. Judge Frank Easterbrook’s famous 1996 proclamation on the ‘Law of the Horse’ through which he opposed the creation of a niche field of ‘cyberspace law’ comes to mind. He argued that a multitude of legal rules deal with ‘horses’, including the sale of horses, individuals kicked by horses, and with the licensing and racing of horses. Like with cyberspace, any attempt to arrive at a corpus of specialised ‘law of the horse’ would be shallow and ineffective.
Instead of fidgeting around for the next shiny regulatory tool, industry, practitioners, civil society and policy makers need to get back to the drawing board and think about applying the rich corpus of existing jurisprudence to AI governance.
What is the role for ‘Ethical AI?’
What role can ‘ethical AI’ then play in forging robust and equitable governance of Artificial Intelligence? As it does in all other societal avenues, ‘ethical AI’ should serve as a framework for making legitimate algorithmic decisions in instances where law might not have an answer. An example of such a scenario is the Project Maven saga – where 3,000 Google employees signed a petition opposing Google’s involvement with a US Department of Defense project by claiming that Google should not be involved in “the business of war.” There is no law-international or domestic that suggests that Project Maven-which was designed to study battlefield imagery using AI, was illegal. However, the debate at Google proceeded on ethical grounds and on the application of the ‘Ethical AI’ principles to this present context.
We realise the importance of social norms and mores in carving out any regulatory space. We also appreciate the role of ethics in framing these norms for responsible behaviour. However, discourse across civil society, academic, industry and government circles all across the globe needs to bring law back into the discussion as a framing device. Not doing so risks diluting the debate and potential progress to a set of broad, unactionable principles that can easily be manipulated for private gain at the cost of public welfare.
India is falling down the facial recognition rabbit hole
The article by Prem Sylvester and Karan Saini was published in the Wire on July 23, 2019.
In a discomfiting reminder of how far technology can be used to intrude on the lives of individuals in the name of security, the Ministry of Home Affairs, through the National Crime Records Bureau, recently put out a tender for a new Automated Facial Recognition System (AFRS).
The stated objective of this system is to “act as a foundation for a national level searchable platform of facial images,” and to “[improve] outcomes in the area of criminal identification and verification by facilitating easy recording, analysis, retrieval and sharing of Information between different organizations.”
The system will pull facial image data from CCTV feeds and compare these images with existing records in a number of databases, including (but not limited to) the Crime and Criminal Tracking Networks and Systems (or CCTNS), Interoperable Criminal Justice System (or ICJS), Immigration Visa Foreigner Registration Tracking (or IVFRT), Passport, Prisons, Ministry of Women and Child Development (KhoyaPaya), and state police records.
Furthermore, this system of facial recognition will be integrated with the yet-to-be-deployed National Automated Fingerprint Identification System (NAFIS) as well as other biometric databases to create what is effectively a multi-faceted system of biometric surveillance.
It is rather unfortunate, then, that the government has called for bids on the AFRS tender without any form of utilitarian calculus that might justify its existence. The tender simply states that this system would be “a great investigation enhancer.”
This confidence is misplaced at best. There is significant evidence that not only is a facial recognition system, as has been proposed, ineffective in its application as a crime-fighting tool, but it is a significant threat to the privacy rights and dignity of citizens. Notwithstanding the question of whether such a system would ultimately pass the test of constitutionality – on the grounds that it affects various freedoms and rights guaranteed within the constitution – there are a number of faults in the issued tender.
Let us first consider the mechanics of a facial recognition system itself. Facial recognition systems chain together a number of algorithms to identify and pick out specific, distinctive details about a person’s face – such as the distance between the eyes, or shape of the chin, along with distinguishable ‘facial landmarks’. These details are then converted into a mathematical representation known as a face template for comparison with similar data on other faces collected in a face recognition database. There are, however, several problems with facial recognition technology that employs such methods.
Facial recognition technology depends on machine learning – the tender itself mentions that the AFRS is expected to work on neural networks “or similar technology” – which is far from perfect. At a relatively trivial level, there are several ways to fool facial recognition systems, including wearing eyewear, or specific types of makeup. The training sets for the algorithm itself can be deliberately poisoned to recognise objects incorrectly, as observed by students at MIT.
More consequentially, these systems often throw up false positives, such as when the face recognition system incorrectly matches a person’s face (say, from CCTV footage) to an image in a database (say, a mugshot), which might result in innocent citizens being identified as criminals. In a real-time experiment set in a train station in Mainz, Germany, facial recognition accuracy ranged from 17-29% – and that too only for faces seen from the front – and was at 60% during the day but 10-20% at night, indicating that environmental conditions play a significant role in this technology.
Facial recognition software used by the UK’s Metropolitan Police has returned false positives in more than 98% of match alerts generated.
When the American Civil Liberties Union (ACLU) used Amazon’s face recognition system, Rekognition, to compare images of legislative members of the American Congress with a database of mugshots, the results included 28 incorrect matches.
There is another uncomfortable reason for these inaccuracies – facial recognition systems often reflect the biases of the society they are deployed in, leading to problematic face-matching results. Technological objectivity is largely a myth, and facial recognition offers a stark example of this.
An MIT study shows that existing facial recognition technology routinely misidentifies people of darker skin tone, women and young people at high rates, performing better on male faces than female faces (8.1% to 20.6% difference in error rate), lighter faces than darker faces (11.8% to 19.2% difference in error rate) and worst on darker female faces (20.8% to 34.7% error rate). In the aforementioned ACLU study, the false matches were disproportionately people of colour, particularly African-Americans. The bias rears its head when the parameters of machine-learning algorithms, derived from labelled data during a “supervised learning” phase, adhere to socially-prejudiced ideas of who might commit crimes.
The implications for facial recognition are chilling. In an era of pervasive cameras and big data, such prejudice can be applied at unprecedented scale through facial recognition systems. By replacing biased human judgment with a machine learning technique that embeds the same bias, and more reliably, we defeat any claims of technological neutrality. Worse, because humans will assume that the machine’s “judgment” is not only consistently fair on average but independent of their personal biases, they will read agreement of its conclusions with their intuition as independent corroboration.
In the Indian context, consider that Muslims, Dalits, Adivasis and other SC/STs are disproportionately targeted by law enforcement. The NCRB in its 2015 report on prison statistics in India recorded that over 55% of the undertrials prisoners in India are either Dalits, Adivasis or Muslims, a number grossly disproportionate to the combined population of Dalits, Adivasis and Muslims, which amounts to just 39% of the total population according to the 2011 Census.
If the AFRS is thus trained on these records, it would clearly reinforce socially-held prejudices against these communities, as inaccurately representative as they may be of those who actually carry out crimes. The tender gives no indication that the developed system would need to eliminate or even minimise these biases, nor if the results of the system would be human-verifiable.
This could lead to a runaway effect if subsequent versions of the machine-learning algorithm are trained with criminal convictions in which the algorithm itself played a causal role. Taking such a feedback loop to its logical conclusion, law enforcement may use machine learning to allocate police resources to likely crime spots – which would often be in low income or otherwise vulnerable communities.
Adam Greenfield writes in Radical Machines on the idea of ‘over transparency,’ that combines “bias” of the system’s designers as well of the training sets – based as these systems are on machine learning – and “legibility” of the data from which patterns may be extracted. The “meaningful question,” then, isn’t limited to whether facial recognition technology works in identification – “[i]t’s whether someone believes that they do, and acts on that belief.”
The question thus arises as to why the MHA/NCRB believes this is an effective tool for law enforcement. We’re led, then, to another, larger concern with the AFRS – that it deploys a system of surveillance that oversteps its mandate of law enforcement. The AFRS ostensibly circumvents the fundamental right to privacy, as ratified by the Supreme Court in 2018, through sourcing its facial images from CCTV cameras installed in public locations, where the citizen may expect to be observed.
The extent of this surveillance is made even clearer when one observes the range of databases mentioned in the tender for the purposes of matching with suspects’ faces extends to “any other image database available with police/other entity” besides the previously mentioned CCTNS, ICJS et al. The choice of these databases makes overreach extremely viable.
This is compounded when we note that the tender expects the system to “[m]atch suspected criminal face[sic] from pre-recorded video feeds obtained from CCTVs deployed in various critical identified locations, or with the video feeds received from private or other public organization’s video feeds.” There further arises a concern with regard to the process of identification of such “critical […] locations,” and if there would be any mechanisms in place to prevent this from being turned into an unrestrained system of surveillance, particularly with the stated access to private organisations’ feeds.
The Perpetual Lineup report by Georgetown Law’s Center on Privacy & Technology identifies real-time (and historic) video surveillance as posing a very high risk to privacy, civil liberties and civil rights, especially owing to the high-risk factors of the system using real-time dragnet searches that are more or less invisible to the subjects of surveillance.
It is also designated a “Novel Use” system of criminal identification, i.e., with little to no precedent as compared to fingerprint or DNA analysis, the latter of which was responsible for countless wrongful convictions during its nascent application in the science of forensic identification, which have since then been overturned.
In the Handbook of Face Recognition, Andrew W. Senior and Sharathchandra Pankanti identify a more serious threat that may be born out of automated facial recognition, assessing that “these systems also have the potential […] to make judgments about [subjects’] actions and behaviours, as well as aggregating this data across days, or even lifetimes,” making video surveillance “an efficient, automated system that observes everything in front of any of its cameras, and allows all that data to be reviewed instantly, and mined in new ways” that allow constant tracking of subjects.
Such “blanket, omnivident surveillance networks” are a serious possibility through the proposed AFRS. Ye et al, in their paper on “Anonymous biometric access control”, show how automatically captured location and facial image data obtained from cameras designed to track the same can be used to learn graphs of social networks in groups of people.
Consider those charged with sedition or similar crimes, given that the CCTNS records the details as noted in FIRs across the country. Through correlating the facial image data obtained from CCTVs across the country – the tender itself indicates that the system must be able to match faces obtained from two (or more) CCTVs – this system could easily be used to target the movements of dissidents moving across locations.
Constantly watched
Further, something which has not been touched upon in the tender – and which may ultimately allow for a broader set of images for carrying out facial recognition – is the definition of what exactly constitutes a ‘criminal’. Is it when an FIR is registered against an individual, or when s/he is arrested and a chargesheet is filed? Or is it only when an individual is convicted by a court that they are considered a criminal?
Additionally, does a person cease to be recognised by the tag of a criminal once s/he has served their prison sentence and paid their dues to society? Or are they instead marked as higher-risk individuals who may potentially commit crimes again? It could be argued that such a definition is not warranted in a tender document, however, these are legitimate questions which should be answered prior to commissioning and building a criminal facial recognition system.
Senior and Pankanti note the generalised metaphysical consequences of pervasive video surveillance in the Handbook of Face Recognition:
“the feeling of disquiet remains [even if one hasn’t committed a major crime], perhaps because everyone has done something “wrong”, whether in the personal or legal sense (speeding, parking, jaywalking…) and few people wish to live in a society where all its laws are enforced absolutely rigidly, never mind arbitrarily, and there is always the possibility that a government to which we give such powers may begin to move towards authoritarianism and apply them towards ends that we do not endorse.”
Such a seemingly apocalyptic scenario isn’t far-fetched. In the section on ‘Mandatory Features of the AFRS’, the system goes a step further and is expected to integrate “with other biometric solution[sic] deployed at police department system like Automatic Fingerprint identification system (AFIS)[sic]” and “Iris.” This form of linking of biometric databases opens up possibilities of a dangerous extent of profiling.
While the Aadhaar Act, 2016, disallows Aadhaar data from being handed over to law enforcement agencies, the AFRS and its linking with biometric systems (such as the NAFIS) effectively bypasses the minimal protections from biometric surveillance the prior unavailability of Aadhaar databases might have afforded. The fact that India does not have a data protection law yet – and the Bill makes no references to protection against surveillance either – deepens the concern with the usage of these integrated databases.
The Perpetual Lineup report warns that the government could use biometric technology “to identify multiple people in a continuous, ongoing manner [..] from afar, in public spaces,” allowing identification “to be done in secret”. Senior and Pankanti warn of “function creep,” where the public grows uneasy as “silos of information, collected for an authorized process […] start being used for purposes not originally intended, especially when several such databases are linked together to enable searches across multiple domains.”
This, as Adam Greenfield points out, could very well erode “the effectiveness of something that has historically furnished an effective brake on power: the permanent possibility that an enraged populace might take to the streets in pursuit of justice.”
What the NCRB’s AFRS amounts to, then, is a system of public surveillance that offers little demonstrable advantage to crime-fighting, especially as compared with its costs to fundamental human rights of privacy and the freedom of assembly and association. This, without even delving into its implications with regard to procedural law. To press on with this system, then, would be indicative of the government’s lackadaisical attitude towards protecting citizens’ freedoms.
The views expressed by the authors in this article are personal.
The Digital Identification Parade
The article by Aayush Rathi and Ambika Tandon was published in the Indian Express on July 29, 2019. The authors acknowledge Sumandro Chattapadhyay, Amber Sinha and Arindrajit Basu for their edits and Karan Saini for his inputs.
The National Crime Records Bureau recently issued a request for proposals for the procurement of an Automated Facial Recognition System (AFRS). The stated objective of the AFRS is to “identify criminals, missing persons/children, unidentified dead bodies and unknown traced children/persons”. It will be designed to compare images against a “watchlist” curated using images from “any […] image database available with police/other entity”, and “newspapers, raids, sent by people, sketches, etc.” The integration of diverse databases indicates the lack of a specific purpose, with potential for ad hoc use at later stages. Data sharing arrangements with the vendor are unclear, raising privacy concerns around corporate access to sensitive information of crores of individuals.
While a senior government official clarified that the AFRS will only be used against the integrated police database in India — the Crime and Criminal Tracking Network and Systems (CCTNS) — the tender explicitly states the integration of several other databases, including the passport database, and the National Automated Fingerprint Identification System. This is hardly reassuring. Even a targeted database like the CCTNS risks over-representation of marginalised communities, as has already been witnessed in other countries. The databases that the CCTNS links together have racial and colonial origins, recording details of unconvicted persons if they are found to be “suspicious”, based on their tribe, caste or appearance. However, including other databases puts millions of innocent individuals on the AFRS’s watchlist. The objective then becomes to identify “potential criminals” — instead of being “presumed innocent”, we are all persons-who-haven’t-been-convicted-yet.
The AFRS may allow indiscriminate searching by tapping into publicly and privately installed CCTVs pan-India. While facial recognition technology (FRT) has proliferated globally, only a few countries have systems that use footage from CCTVs installed in public areas. This is the most excessive use of FRT, building on its more common implementation as border technology. CCTV cameras are already rife with cybersecurity issues, and integration with the AFRS will expand the “attack surface” for exploiting vulnerabilities in the AFRS. Additionally, the AFRS will allow real-time querying, enabling “continuous” mass surveillance. Misuse of continuous surveillance has been seen in China, with the Uighurs being persecuted as an ethnic minority.
FRT differs from other biometric forms of identification (such as fingerprints, DNA samples) in the degree and pervasiveness of surveillance that it enables. It is designed to operate at a distance, without any knowledge of the targeted individual(s). It is far more difficult to prevent an image of one’s face from being captured, and allows for the targeting of multiple persons at a time. By its very nature, it is a non-consensual and covert surveillance technology.
Potential infringements on the right to privacy, a fundamental right, could be enormous as FRT allows for continuous and ongoing identification. Further, the AFRS violates the legal test of proportionality that was articulated in the landmark Puttaswamy judgment, with constant surveillance being used as a strategy for crime detection. Other civil liberties such as free speech and the right to assemble peacefully could be implicated as well, as specific groups of people such as dissidents and protests can be targeted.
Moreover, facial recognition technology has not performed well as a crime detection technology. Challenges arise at the stage of input itself. Variations in pose, illumination, and expression, among other factors, adversely impact the accuracy of automated facial analysis. In the US, law enforcement has been using images from low-quality surveillance feed as probe photos, leading to erroneous matches. A matter of concern is that several arrests have been made solely on the basis of likely matches returned by FRT.
Research indicates that default camera settings better expose light skin than dark, which affects results for FRT across racial groups. Moreover, the software could be tested on certain groups more often than others, and could consequently be more accurate in identifying individuals from that group. The AFRS is envisioned as having both functionalities of an FRT — identification of an individual, and social classification — with the latter holding significant potential to misclassify minority communities.
In the UK, after accounting for a host of the issues outlined above, the Science and Technology Committee, comprising 14 sitting MPs, recently called for a moratorium on deploying live FRT. It will be prudent to pay heed to this directive in India, in the absence of any framework around data protection, or the use of biometric technologies by law enforcement.
The experience of law enforcement’s use of FRT globally, and the unique challenges posed by the usage of live FRT demand closer scrutiny into how it can be regulated. One approach may be to use a technology-neutral regulatory framework that identifies gradations of harms. However, given the history of political surveillance by the Indian state, a complete prohibition on FRT may not be too far-fetched.
In India, Privacy Policies of Fintech Companies Pay Lip Service to User Rights
The article by Shweta Mohandas highlighting the key observations in Fintech study conducted by CIS was published in the Wire on July 30, 2019.
Earlier this month, an investigation revealed that a Hyderabad-based fintech company called CreditVidya was sneakily collecting user data through their devotional and music apps to assess people’s creditworthiness.
This should be unsurprising as the privacy policies of most Indian fintech companies do not specify who they will be sharing the information with. Instead, they employ vague terminology to identify sharing arrangements such as ‘third-party’, ‘affiliates’ etc.
This is one of the many findings that we came across while analysing the privacy policies of 48 fintech companies that operate in India.
The study looked at how the privacy policies complied with the requirements of the existing data protection regime in India – the Information Technology (Reasonable Security Practices and Procedures and Sensitive Personal Data or Information) Rules, 2011.
The IT Rules, among other things, require that privacy policies specify the type of data being used, the purpose of collection, the third parties the data will be shared with, the option to withdraw consent and the grievance redressal mechanism.
The rules also require the privacy policy to be easily accessible as well as easy to understand. The problem is that they are not as comprehensive and specific as, say, the draft Personal Data Protection Bill, which is awaiting passage through parliament, and hence require the companies to do much less than privacy and data protection practices emerging globally.
Nevertheless, despite the limited requirements, none of the companies in our sample of 48 were fully compliant with the parameters set by the IT Rules.
While 95% of the companies did fulfil the basic requirement of actually formulating and having a privacy policy, two major players stood out as defaulters: Airtel Payments Bank and Bhim UPI, for which we were not able to locate a privacy policy.
Though a majority of the privacy policies contained the statement “we take your privacy and security seriously”, 43% of the companies did not provide adequate details of the reasonable security practices and procedures followed.
The requirement in which most companies did not provide information for was regarding a grievance redressal mechanism, where only 10% of the companies comply.
While 31% of the companies provided the contact of a grievance redressal officer (some without even mentioning the redressal mechanism), 37% of the companies provided contact details of a representative but did not specify if this person could be contacted in case of any grievance.
Throughout the study, it was noted that the wording of the IT Rules allowed companies to use ambiguous terms to ensure compliance without exposing their actual data practices. For example, Rule 5 (7) requires a fintech company to provide an option to withdraw consent. Twenty three percent of the companies allowed the user to opt out or withdraw from certain services such as mailing list, direct marketing and in app public forums but they did not allow the user to withdraw their consent completely. While several of 17 companies did provide the option to withdraw consent, they did not clarify whether the withdrawal also meant that the user’s data was no processed or shared.
However, when it came to data retention, most of the 27 companies that provided some degree of information about the retention policy stated that some data would be stored for perpetuity either for analytics or for complying with law enforcement. The remaining 21 companies say nothing about their data retention policy.
In local languages
The issue of ambiguity most clearly arises when the user is actually able to cross the first hurdle – reading an app’s privacy policy.
With fintech often projected as one of the drivers of greater financial inclusion in India, it is telling that only one company (PhonePe) had the option to read the privacy policy in a language other than English. With respect to readability, we noted that the privacy policies were difficult to follow not just because of legalese and length, but also because of fonts and formatting – smaller and lighter texts, no distinction between paragraphs etc. added to the disincentive to read the privacy policy.
Privacy policies act as a notice to individuals about the terms on which their data will be treated by the entity collecting data. However, they are a monologue in terms of consent where the user only has the option to either agree to it or decline and not avail the services. Moreover, even the notice function is not served when the user is unable to read the privacy policy.
They, thus, serve as mere symbols of compliance, where they are drafted to ensure bare minimum conformity to legal requirements. However, the responsibility of these companies lies in giving the user the autonomy to provide an informed consent as well as to be notified in case of any change in how the data is being handled (this could be when and whom the data is being shared with, if there has been a breach etc).
With the growth of fintech companies and the promise of financial inclusion, it is imperative that the people using these services make informed decisions about their data. The draft Personal Data Protection Bill – in its current form – would encumber companies processing sensitive personal data with greater responsibility and accountability than before. However, the Bill, similar to the IT Rules, endorses the view of blanket consent, where the requirement for change in data processing is only of periodic notice (Section 30 (2)), a lesson that needs to be learnt from the CreditVidya story.
In addition to blanket consent, the SPD/I Rules and well as the PDP Bill does not require the user to be notified in all cases of a breach. While the information that is provided to data subjects is necessary to be designed keeping the user in mind, neither the SPD/I Rules, nor the PDP Bill take into account the manner in which data flows operate in the context of ‘disruptive’ business models that are a hallmark of the ‘fintech revolution’.
Event Report: Community Discussion on Open Standards
Open standards are important for the growth and evolution of technology and practices for consumers and industries. They provide a range of tangible benefits, including, for instance, a reduction in cost of development for small businesses and organizations, facilitation of interoperability across different technologies in certain cases, and encouragement of competitiveness in the software and services market. Open standardization also encourages innovation, expansion in market access, transparency — along with a decrease in regulatory rigidity, as well as volatility in the market, and subsequently the surrounding economy, as well.
The importance of open standards is perhaps most strikingly evident when considering the ardent growth and impact the Internet — and the World Wide Web in particular — have been able to enjoy. The modern Internet has arguably been governed, at least for the most part, by the continuous development and maintenance of an array of inventive protocols and technical standards. Open standards are usually developed in a public-consultancy process, where the standards development organizations (“SDOs”) involved follow a multi-stakeholder model of decision-making. Multi-stakeholder models like this ensure equity to groups with varying interests, and also ensures that any resulting technology, protocol or standard which is developed is in accordance with the general consensus of those involved.
This event report highlights a community discussion on the state of open standardization in the age where immediately accessible cloud computing services are readily available to consumers — along with an imagined roadmap for the future; one which ensures steady ground for users as well as the open standards and open source software communities. Participants in the discussion focused on what they believed to be the key areas of open standardization, establishing a requirement for regulatory action in the open standards domain, while also touching upon the effects of market forces on stakeholders within the ecosystem, which ultimately guide the actions of software companies, service providers, users, and other consumers.
The event report can be accessed here.
Comments on the National Digital Health Blueprint
This submission presents comments by the Centre for Internet and Society (CIS), on the National Digital Health Blueprint (NDHB) Report, released on 15th July 2019 for publicconsulations. It must be noted at the outset that the time given for comments was less than three weeks, and such a short window of time is inadequate for all stakeholdersinvolved to comprehensively address the various aspects of the Report. Accordingly, on behalf of all other interested parties, we request more time for consultations.
We also note that the nature of data which would be subject to processing in the proposed digital framework pre-supposes a robust data protection regime in India, onewhich is currently absent. Accordingly, we also urge ceasing the implementation of the framework until the Personal Data Protection Bill is passed by the parliament. We wouldbe explaining our reasonings on this particular point below.
Click to download the full submission here.
Private Sector and the cultivation of cyber norms in India
The article by Arindrajit Basu was published by Nextrends India on August 5, 2019.
While the United Nations ‘Group of Governmental experts’ (GGE), tried and failed to establish a common law for governing the behavior of states in cyberspace, it is Big Tech who led the discussions on cyberspace regulations. Microsoft’s Digital Geneva Convention which devised a set of rules to protect civilian use of the internet was a notable initiative on that front. Microsoft was also a major driver of the Tech Accords — a public commitment made by over 100 companies “agreeing to defend all customers everywhere from malicious attacks by cyber-criminal enterprises and nation-states.” The Paris Call for Trust and Security in Cyberspace was a joint effort between the French government and Microsoft that brought in (as of today) 66 states, 347 private sector entities, including Indian business guilds such as FICCI and the Mobile Association of India and 139 organisations from civil society and academia from all over the globe.
However, the entry of Big tech into the business of framing regulation has raised eyeballs across jurisdictions. In India, the government has attempted to push back on the global private sector due to arguably extractive economic policies adopted by them, alongside the threats they pose to India’s democratic fabric. The Indian government has taken various steps to constrain Big Tech, although some of these policies have been hastily rolled out and fail to address the root of the problem.
I have identified two regulatory interventions that illustrate this trend. First, on intermediary liability, Rule 3(9) of the Draft of the Information Technology 2018 released by the Ministry of Electronics and Information Technology (MeiTy) last December. The rule follows the footsteps of countries like Germany and France by mandating that platforms use “automated tools or appropriate mechanisms, with appropriate controls, for proactively identifying and removing or disabling public access to unlawful information or content.” These regulations have resulted in criticism from both the private sector and civil society as they fail to address concerns around algorithmic discrimination, excessive censorship and gives the government undue power. Further, the regulations paint all the intermediaries with the same brush, thus not differentiating between platforms such as Whatsapp who thrive on end-to-end encryption and public platforms like Facebook.
Another source of discord between the government and the private sector has been the government’s localisation mandate, featuring in a slew of policies. Over the past year, the Indian government has introduced a range of policy instruments which
demand that certain kinds of data must be stored in servers located physically within India — termed “data localization.”
While this serves a number of policy objectives, the two which stand out are (1) the presently complex process for Indian law enforcement agencies to access data stored in the U.S. during criminal investigations, and (2) extractive economic models used by U.S. companies operating in India.
A study I co-authored earlier this year on the issue found that foreign players and smaller Indian private sector players were against this move due to the high compliance costs in setting up data centres.
On this question, we recommended a dual approach that involves mandatory sectoral localisation for critical sectors such as defense or payments data while adopting ‘conditional’ localisation for all other data. Under ‘conditional localisation,’
data should only be transferred to countries that (1)Agree to share the personal data of Indian citizens with law enforcement authorities based on Indian criminal procedure laws and (2) Have equivalent privacy and security safeguards.
These two instances demonstrate that it is important for the Indian government to engage with both the domestic and foreign private sector to carve out optimal regulatory interventions that benefit the Indian consumer and the private sector as a whole rather than a few select big players. At the same time, it is important for the private sector to be a responsible stakeholder and comply both with existing laws and accepted norms of ‘good behaviour.’
Going forward, there is no denying the role of the private sector in the development of emerging technologies. However, a balance must be struck through continued engagement and mutual respect to create a regulatory ecosystem that fosters innovation while respecting the rule of law with every stakeholder – government, private sector and civil society. India’s position could set the trend for other emerging economies coming online and foster a strategic digital ecosystem that works for all
stakeholders.
Comments to the ID4D Practitioners’ Guide
This post presents our comments to the ID4D Practitioners’ Guide: Draft For Consultation released by ID4D in June, 2019. CIS has conducted research on issues related to digital identity since 2012. This submission is divided into three main parts. The first part (General Comments) contains the high-level comments on the Practitioners’ Guide, while the second part (Specific Comments) addresses individual sections in the Guide. The third and final part (Additional Comments) does not relate to particulars in the Practitioners' Guide but other documents that it relies upon. We submitted these comments to ID4D on August 5, 2019. Read our comments here.
Document Actions

